mlm scoring
1.0.0
Paket ini menggunakan LMS bertopeng seperti Bert, Roberta, dan XLM untuk mencetak kalimat dan menukar daftar N-terbaik melalui skor pseudo-log-likelihood , yang dihitung dengan menutupi kata-kata individual. Kami juga mendukung Autoregressive LMS seperti GPT-2. Contoh penggunaan termasuk:
Kertas: Julian Salazar, Davis Liang, Toan Q. Nguyen, Katrin Kirchhoff. "Penilaian model bahasa bertopeng", ACL 2020.
Diperlukan Python 3.6+. Kloning repositori ini dan instal:
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.Beberapa model melalui Gluonnlp dan yang lainnya melalui? Transformers, jadi untuk saat ini kita membutuhkan MXNet dan Pytorch. Anda sekarang dapat mengimpor perpustakaan secara langsung:
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](Antarmuka MXNet dan Pytorch akan segera disatukan!)
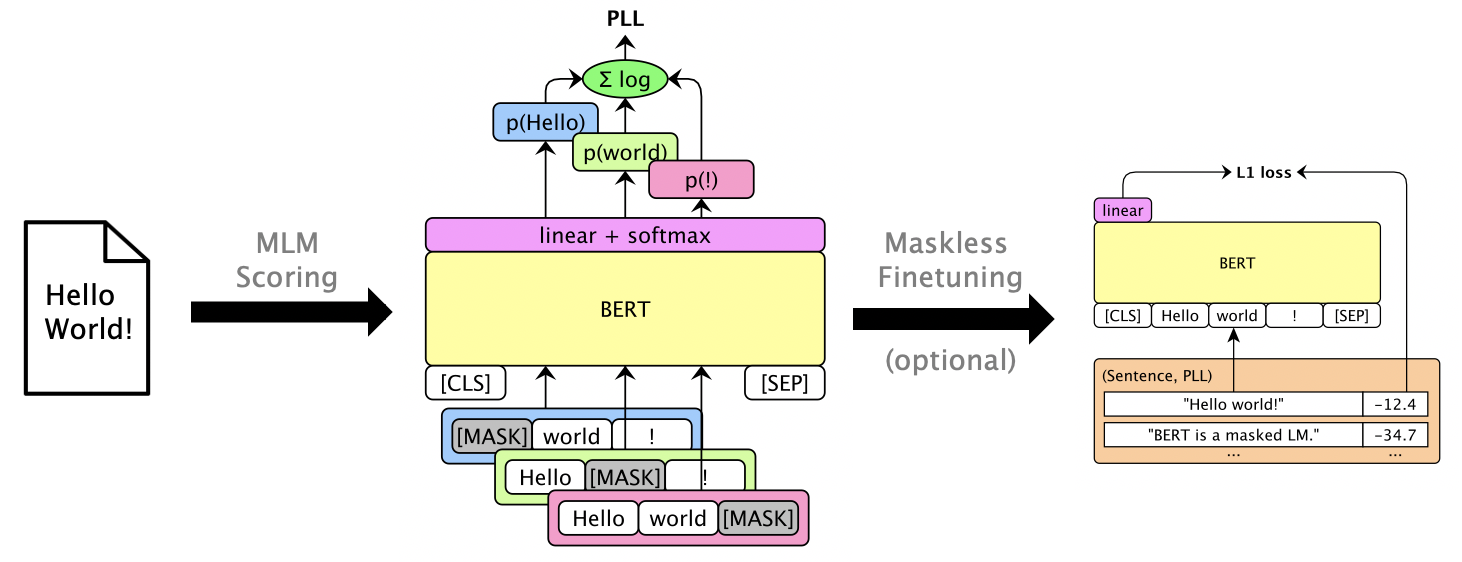
Jalankan mlm score --help untuk melihat model yang didukung, dll. Lihat examples/demo/format.json untuk format file. Untuk input, "skor" adalah opsional. Output akan menambah bidang "skor" yang berisi skor PLL.
Ada tiga jenis skor, tergantung pada modelnya:
--no-mask ) Kami mencetak hipotesis untuk 3 ucapan librispeech dev-other pada GPU 0 menggunakan Base Bert (tidak dibagi):
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json Seseorang dapat mengubah daftar n-best melalui interpolasi log-linear. Jalankan mlm rescore --help untuk melihat semua opsi. Input satu adalah file dengan skor asli; Input dua adalah skor dari mlm score .
Kami menukar skor akustik (dari dev-other.am.json ) menggunakan skor Bert (dari bagian sebelumnya), di bawah bobot LM yang berbeda:
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
doneYang asli WER adalah 12,2% sedangkan yang disimpulkan adalah 8,5%.
Seseorang dapat Finetune bertopeng LMS untuk memberikan skor PLL yang dapat digunakan tanpa menutupi. Lihat finetuning tanpa masker librispeech.
Jalankan pip install -e .[dev] untuk menginstal paket pengujian tambahan. Kemudian:
pytest --cov=src/mlm di direktori root.

