mlm scoring
1.0.0
В этом пакете используются маскированные LMS, такие как Bert, Roberta и XLM, для оценки предложений и спасения N-лучших списков с помощью псевдо-лог-ликелистических показателей , которые рассчитываются путем маскировки отдельных слов. Мы также поддерживаем авторегрессивные LMS, такие как GPT-2. Пример использования включает:
Бумага: Джулиан Салазар, Дэвис Лян, Тоан К. Нгуен, Катрин Кирххофф. «Модель маскированного языка», ACL 2020.
Требуется Python 3.6+. Клонировать это хранилище и установить:
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.Некоторые модели через Gluonnlp, а другие - через? Трансформеры, поэтому нам требуется как MXNET, так и Pytorch. Теперь вы можете импортировать библиотеку напрямую:
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](Интерфейсы MXNET и Pytorch скоро будут объединены!)
Запустите mlm score --help для просмотра поддерживаемых моделей и т. Д. См. examples/demo/format.json для формата файла. Для входных данных «оценка» является необязательным. Выходы добавят поля «оценка», содержащие баллы PLL.
Есть три типа оценки, в зависимости от модели:
--no-mask ) Мы набираем гипотезы за 3 высказывания Librispeech dev-other на GPU 0 с использованием BERT BASE (UNCASED):
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json Можно спасти N-лучшие списки через логарифмическую интерполяцию. Запустите mlm rescore --help чтобы увидеть все варианты. Вход - это файл с исходными оценками; Входные два оценки из mlm score .
Мы спасаем акустические оценки (от dev-other.am.json ), используя баллы Bert (из предыдущего раздела), под разными весами LM:
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
doneПервоначальный WER составляет 12,2%, в то время как Rescored WER составляет 8,5%.
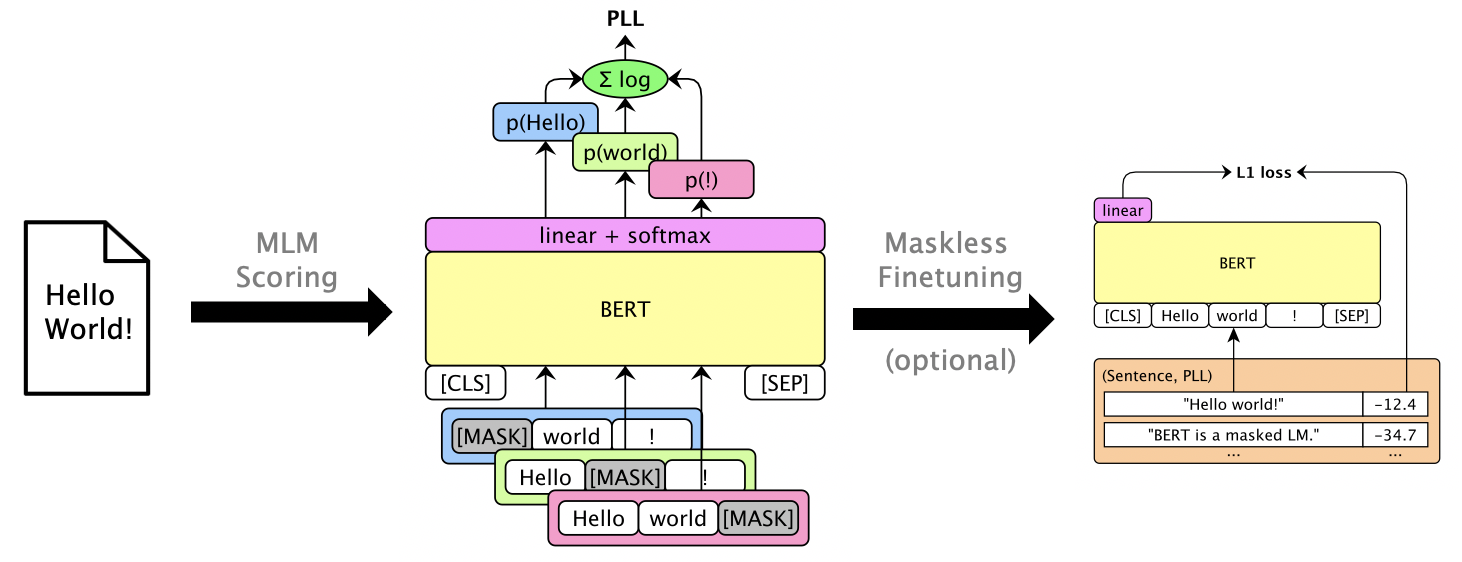
Можно маскировать LMS, чтобы дать полезные результаты PLL без маскировки. См. Зарецвету без маски.
Запустите pip install -e .[dev] , чтобы установить дополнительные пакеты тестирования. Затем:
pytest --cov=src/mlm в корневом каталоге.

