mlm scoring
1.0.0
Este pacote usa LMS mascarado como Bert, Roberta e XLM para marcar frases e resgatar listas N-Best por meio de pontuações de pseudo-log-probabilidade , que são calculadas mascarando palavras individuais. Também apoiamos LMs autoregressivos como o GPT-2. Os usos de exemplo incluem:
Papel: Julian Salazar, Davis Liang, Toan Q. Nguyen, Katrin Kirchhoff. "Pontuação do modelo de linguagem mascarada", ACL 2020.
Python 3.6+ é necessário. Clone este repositório e instale:
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.Alguns modelos são via gluonnlp e outros são via? Transformadores, por enquanto, exigimos MXNET e Pytorch. Agora você pode importar a biblioteca diretamente:
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](As interfaces mxnet e pytorch serão unificadas em breve!)
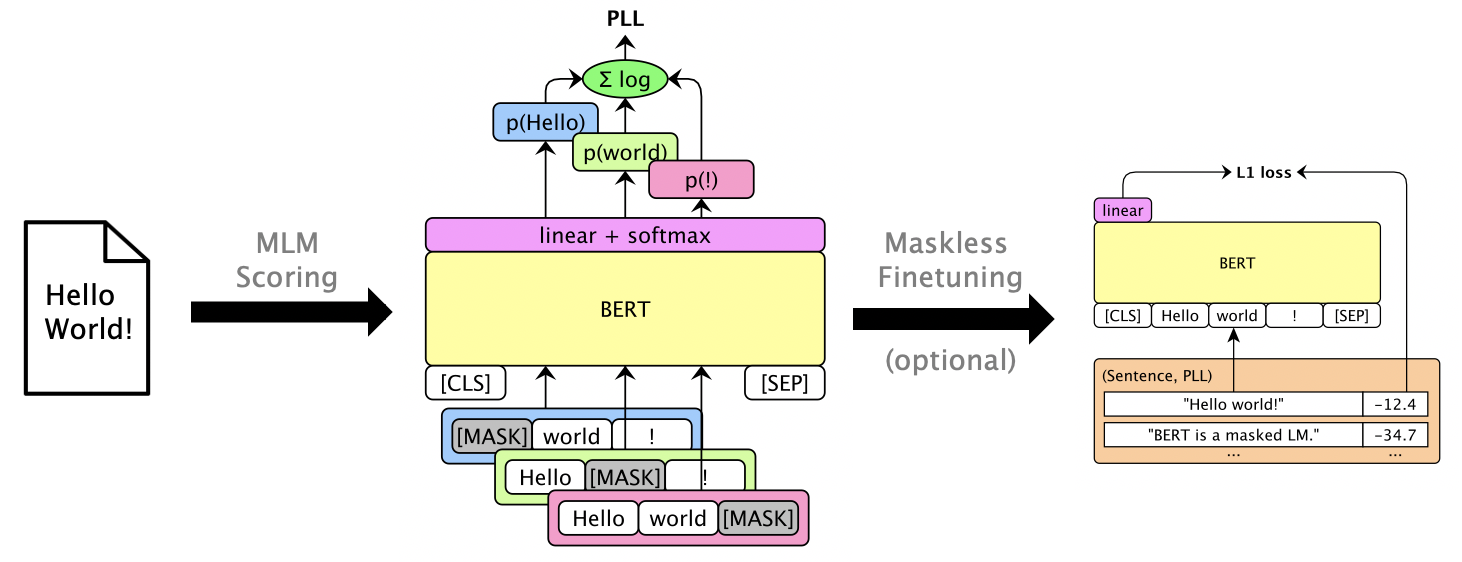
Execute mlm score --help para ver modelos suportados, etc. Consulte examples/demo/format.json para o formato do arquivo. Para entradas, "Score" é opcional. As saídas adicionarão campos "pontuação" contendo pontuações PLL.
Existem três tipos de pontuação, dependendo do modelo:
--no-mask ) Nós pontuamos hipóteses para 3 enunciados do LibreSpeech dev-other na GPU 0 usando a base Bert (não baseada):
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json Pode-se resgatar listas N-Best por meio de interpolação log-linear. Execute mlm rescore --help para ver todas as opções. A entrada um é um arquivo com pontuações originais; A entrada dois são pontuações da mlm score .
Rescoramos as pontuações acústicas (de dev-other.am.json ) usando as pontuações de Bert (da seção anterior), sob diferentes pesos LM:
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
doneO WER original é de 12,2%, enquanto o WER resgatado é de 8,5%.
Pode -se mascarado LMS mascarado para fornecer pontuações PLL utilizáveis sem mascarar. Consulte Finetuning sem máscara do LibreseChech.
Execute pip install -e .[dev] para instalar pacotes de testes extras. Então:
pytest --cov=src/mlm no diretório raiz.

