mlm scoring
1.0.0
Ce package utilise des LM masqués comme Bert, Roberta et XLM pour marquer des phrases et sauver les listes de n-belles via des scores de pseudo-log-likelihood , qui sont calculés en masquant des mots individuels. Nous prenons également en charge les LMS autorégressives comme GPT-2. Exemple d'utilisations inclut:
Papier: Julian Salazar, Davis Liang, Toan Q. Nguyen, Katrin Kirchhoff. "Masked Language Model Scoring", ACL 2020.
Python 3.6+ est requis. Cloner ce référentiel et installer:
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.Certains modèles sont via Gluonnlp et d'autres sont via? Transformers, donc pour l'instant nous avons besoin de MXNET et de Pytorch. Vous pouvez désormais importer directement la bibliothèque:
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](Les interfaces MXNET et PYTORCH seront bientôt unifiées!)
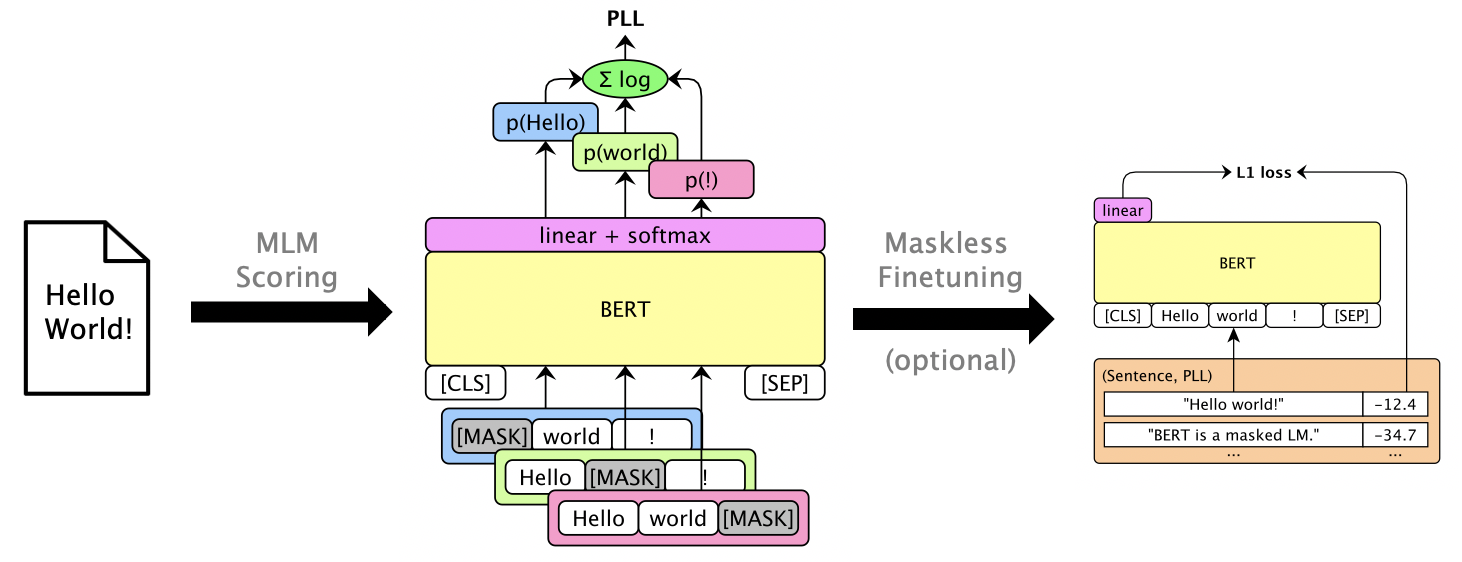
Exécutez mlm score --help pour voir les modèles pris en charge, etc. Voir examples/demo/format.json pour le format de fichier. Pour les entrées, le "score" est facultatif. Les sorties ajouteront des champs "Score" contenant des scores PLL.
Il existe trois types de score, selon le modèle:
--no-mask ) Nous marquons des hypothèses pour 3 énoncés de libispenech dev-other sur GPU 0 en utilisant Bert Base (Unleased):
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json On peut annuler les listes de n plus nuls via une interpolation log-linéaire. Exécutez mlm rescore --help pour voir toutes les options. La saisie est un fichier avec des scores d'origine; L'entrée deux sont des scores du mlm score .
Nous attaquons les scores acoustiques (de dev-other.am.json ) en utilisant les scores de Bert (de la section précédente), sous différents poids LM:
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
doneL'original Wer est de 12,2% tandis que le Wer attoré est de 8,5%.
On peut Finetune a masqué LMS pour donner des scores PLL utilisables sans masquage. Voir Finetuning sans masque LibrishePeleeCH.
Exécutez pip install -e .[dev] pour installer des packages de test supplémentaires. Alors:
pytest --cov=src/mlm dans le répertoire racine.

