mlm scoring
1.0.0
이 패키지는 Bert, Roberta 및 XLM과 같은 가면을 쓴 LM을 사용하여 개별 단어를 마스킹하여 계산되는 의사 로그와 같은 점수를 통해 문장 및 Rescore N-Best 목록을 득점합니다. 우리는 또한 GPT-2와 같은자가 회귀 LM을 지원합니다. 예제 용도는 다음과 같습니다.
종이 : Julian Salazar, Davis Liang, Toan Q. Nguyen, Katrin Kirchhoff. "마스크 언어 모델 스코어링", ACL 2020.
파이썬 3.6+가 필요합니다. 이 저장소를 복제하고 설치하십시오.
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.일부 모델은 gluonnlp를 통해이고 다른 모델은이를 통해 이루어 집니까? 트랜스포머, 따라서 현재 MXNET과 Pytorch가 모두 필요합니다. 이제 라이브러리를 직접 가져올 수 있습니다.
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](MXNET 및 Pytorch 인터페이스가 곧 통합 될 것입니다!)
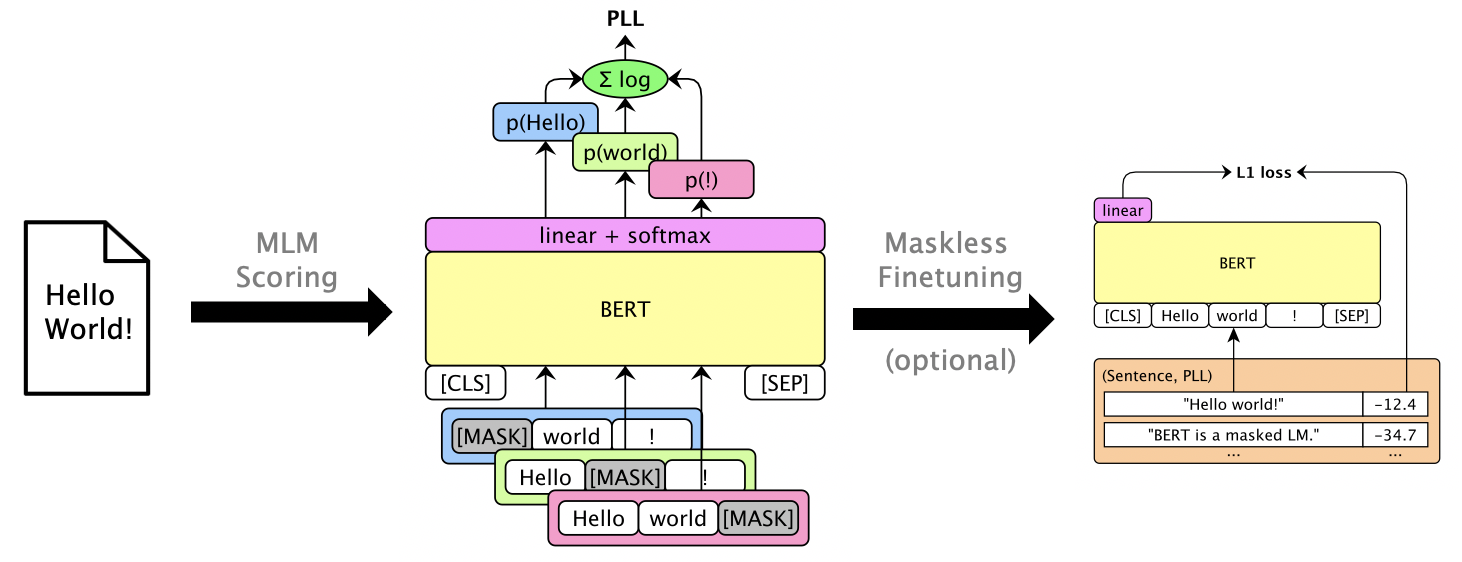
mlm score --help 실행하여 지원되는 모델 등을보십시오. 파일 형식은 examples/demo/format.json 참조하십시오. 입력의 경우 "점수"는 선택 사항입니다. 출력은 PLL 점수를 포함하는 "점수"필드를 추가합니다.
모델에 따라 세 가지 점수 유형이 있습니다.
--no-mask ) 우리는 Bert Base를 사용하여 GPU 0에서 Librispeech dev-other 의 3 발언에 대한 가설을 점수를 얻습니다.
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json 로그 라이너 보간을 통해 N- 최고 목록을 구제 할 수 있습니다. mlm rescore --help 실행하여 모든 옵션을 볼 수 있습니다. 입력 1은 원래 점수가있는 파일입니다. 입력 2는 mlm score 의 점수입니다.
우리는 다른 LM 가중치에서 Bert의 점수 (이전 섹션에서)를 사용하여 음향 점수 ( dev-other.am.json )를 구제합니다.
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
done원래 WER은 12.2%이고 구조 된 WER은 8.5%입니다.
마스킹 LM을 마스킹하지 않고 사용할 수있는 PLL 점수를 제공 할 수 있습니다. librispeech maskless finetuning을 참조하십시오.
추가 테스트 패키지를 설치하려면 pip install -e .[dev] 실행하십시오. 그 다음에:
pytest --cov=src/mlm 실행하십시오.

