mlm scoring
1.0.0
Dieses Paket verwendet maskierte LMS wie Bert, Roberta und XLM, um Sätze zu erzielen und N-BEST-Listen über Pseudo-Log-Likelihood-Scores zu ermitteln, die durch Maskieren einzelner Wörter berechnet werden. Wir unterstützen auch autoregressive LMs wie GPT-2. Beispiel verwendet: einschließlich:
Papier: Julian Salazar, Davis Liang, Toan Q. Nguyen, Katrin Kirchhoff. "Masked Language Model Scoring", ACL 2020.
Python 3.6+ ist erforderlich. Klonen Sie dieses Repository und installieren Sie:
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.Einige Modelle sind über Gluonnlp und andere über? Transformatoren, also benötigen wir vorerst sowohl mxnet als auch pytorch. Sie können jetzt die Bibliothek direkt importieren:
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](MXNET- und Pytorch -Schnittstellen werden bald einheitlich sein!)
mlm score --help , um unterstützte Modelle usw. anzuzeigen, siehe examples/demo/format.json für das Dateiformat. Für Eingänge ist "Score" optional. Ausgänge fügen "Score" -Felder hinzu, die PLL -Scores enthalten.
Abhängig vom Modell gibt es drei Punktestypen:
--no-mask ) Wir erzielen Hypothesen für 3 Äußerungen von Librispeech dev-other auf GPU 0 mit Bert Base (ungezogen):
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json Man kann die N-BEST-Listen über logarithmisch-lineare Interpolation neu erfüllen. mlm rescore --help Führen Sie alle Optionen durch. Eingabe ist eine Datei mit Originalwerten. Input Zwei sind Bewertungen aus mlm score .
Wir werden die akustischen Bewertungen (von dev-other.am.json ) unter Verwendung der Bewertungen von Bert (aus dem vorherigen Abschnitt) unter verschiedenen LM-Gewichten neu erkennen:
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
doneDas ursprüngliche WER beträgt 12,2%, während die erneuten Were 8,5% beträgt.
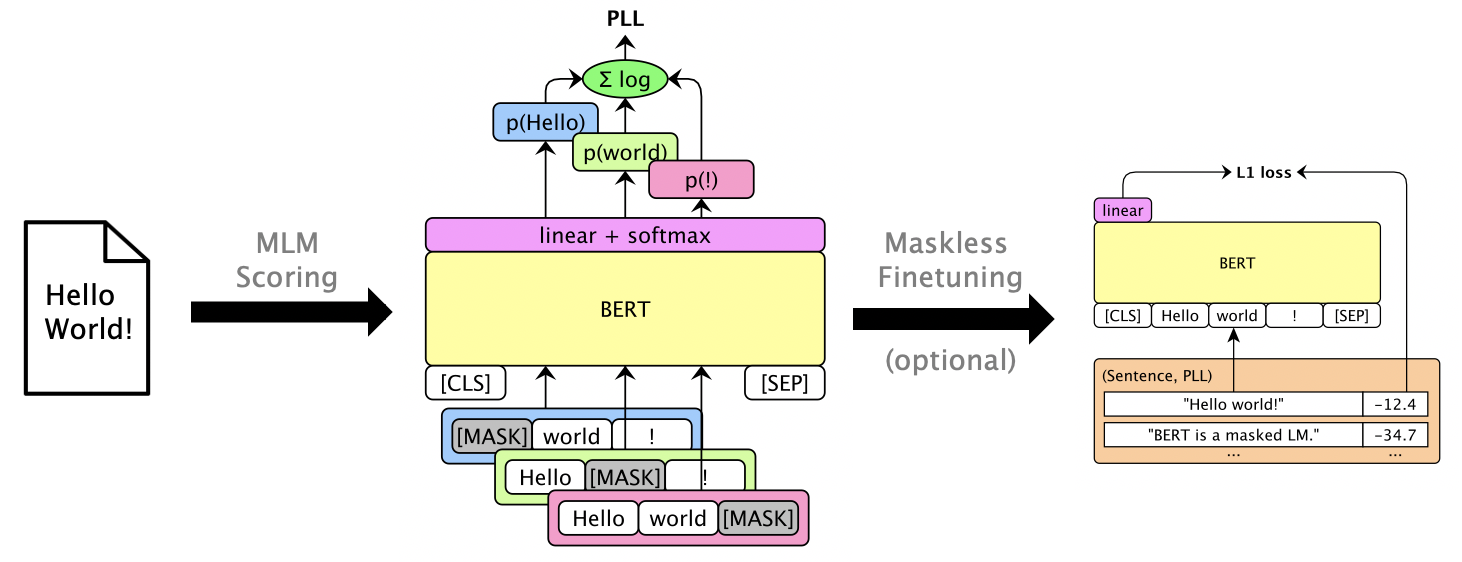
Man kann maskierte LMs mit dem Finetune -Funkle -PLL -Werten ohne Maskierung finanzieren. Siehe librispeech maskless Fonetuning.
Führen Sie pip install -e .[dev] aus, um zusätzliche Testpakete zu installieren. Dann:
pytest --cov=src/mlm im Stammverzeichnis aus.

