mlm scoring
1.0.0
تستخدم هذه الحزمة LMS المقنعة مثل Bert و Roberta و XLM لتسجيل الجمل وإنقاذ قوائم N-Best عبر درجات الاحتمالية الزائفة ، والتي يتم حسابها عن طريق إخفاء الكلمات الفردية. كما ندعم LMS Autoregressed LMS مثل GPT-2. يشمل استخدامات مثال:
ورقة: جوليان سالازار ، ديفيس ليانغ ، توان ك. نغوين ، كاترين كيرشوف. "تسجيل اللغة المقنعة" ، ACL 2020.
Python 3.6+ مطلوب. استنساخ هذا المستودع والتثبيت:
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.بعض النماذج عبر Gluonnlp والبعض الآخر عبر؟ المحولات ، لذلك في الوقت الحالي نطلب كل من MXNET و PYTORCH. يمكنك الآن استيراد المكتبة مباشرة:
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](سيتم توحيد واجهات Mxnet و Pytorch قريبًا!)
Run mlm score --help لمشاهدة النماذج المدعومة ، وما إلى ذلك. انظر examples/demo/format.json لتنسيق الملف. بالنسبة للمدخلات ، "النتيجة" اختيارية. ستضيف المخرجات حقول "نقاط" تحتوي على درجات PLL.
هناك ثلاثة أنواع نقاط ، اعتمادًا على النموذج:
--no-mask ) نقوم بتسجيل فرضيات لثلاثة كلمات من Librispeech dev-other على GPU 0 باستخدام Bert Base (غير معتمد):
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json يمكن للمرء أن ينقذ قوائم N أفضل عن طريق الاستيفاء الخطي. Run mlm rescore --help لرؤية جميع الخيارات. الإدخال واحد هو ملف له درجات أصلية. المدخلات اثنين هي عشرات من mlm score .
نقوم بإنقاذ الدرجات الصوتية (من dev-other.am.json ) باستخدام درجات Bert (من القسم السابق) ، تحت أوزان LM مختلفة:
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
doneالأصل WER هو 12.2 ٪ بينما تم إنقاذ WER هو 8.5 ٪.
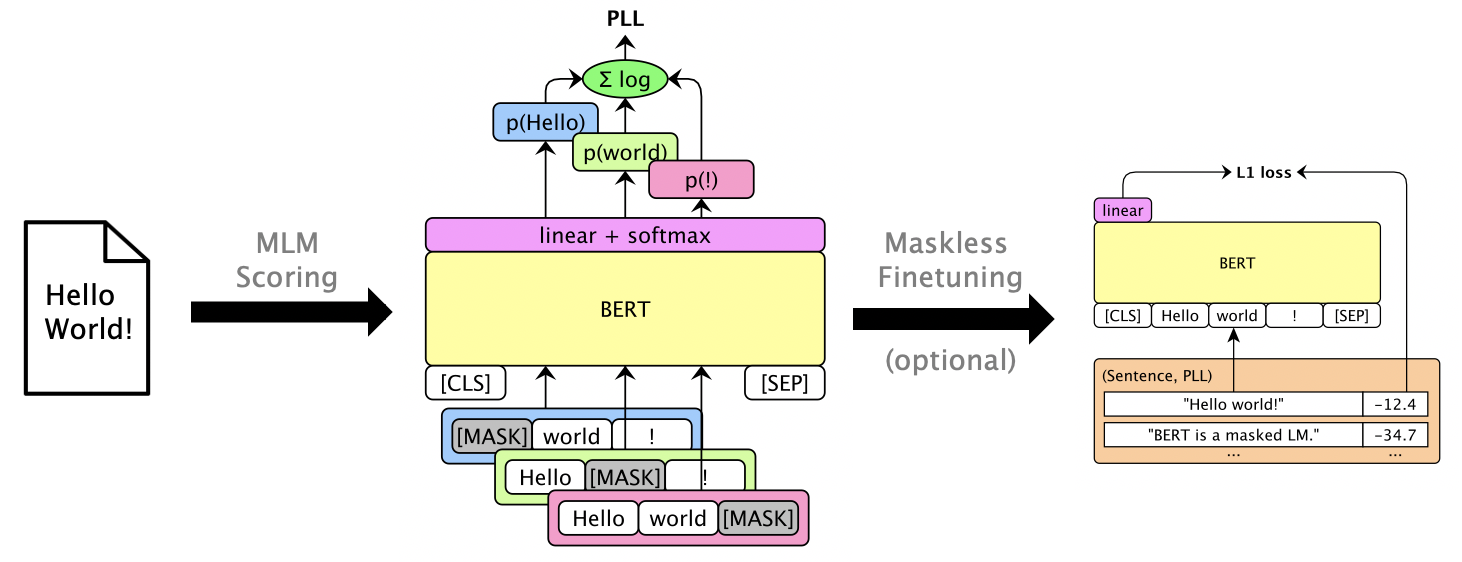
يمكن للمرء أن يحمل Finetune LMS لإعطاء درجات PLL قابلة للاستخدام دون إخفاء. انظر Librispeech Maskless Finetuning.
قم بتشغيل pip install -e .[dev] لتثبيت حزم اختبار إضافية. ثم:
pytest --cov=src/mlm في دليل الجذر.

