mlm scoring
1.0.0
Este paquete utiliza LMS enmascarados como Bert, Roberta y XLM para obtener oraciones y rescorar las mejores listas a través de puntajes de pseudo-log-probilitud , que se calculan enmascarando palabras individuales. También apoyamos LMS autorregresivos como GPT-2. Los usos de ejemplo incluyen:
Documento: Julian Salazar, Davis Liang, Toan Q. Nguyen, Katrin Kirchhoff. "Modelo de lenguaje enmascarado", ACL 2020.
Se requiere Python 3.6+. Clon este repositorio e instalación:
pip install -e .
pip install torch mxnet-cu102mkl # Replace w/ your CUDA version; mxnet-mkl if CPU only.¿Algunos modelos son a través de Gluonnlp y otros son a través de? Transformadores, por lo que por ahora requerimos MXNET y Pytorch. Ahora puede importar la biblioteca directamente:
from mlm . scorers import MLMScorer , MLMScorerPT , LMScorer
from mlm . models import get_pretrained
import mxnet as mx
ctxs = [ mx . cpu ()] # or, e.g., [mx.gpu(0), mx.gpu(1)]
# MXNet MLMs (use names from mlm.models.SUPPORTED_MLMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-en-cased' )
scorer = MLMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.410664200782776]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126736640930176, -5.501412391662598, -0.7825151681900024, None]]
# EXPERIMENTAL: PyTorch MLMs (use names from https://huggingface.co/transformers/pretrained_models.html)
model , vocab , tokenizer = get_pretrained ( ctxs , 'bert-base-cased' )
scorer = MLMScorerPT ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-12.411025047302246]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[None, -6.126738548278809, -5.501765727996826, -0.782496988773346, None]]
# MXNet LMs (use names from mlm.models.SUPPORTED_LMS)
model , vocab , tokenizer = get_pretrained ( ctxs , 'gpt2-117m-en-cased' )
scorer = LMScorer ( model , vocab , tokenizer , ctxs )
print ( scorer . score_sentences ([ "Hello world!" ]))
# >> [-15.995375633239746]
print ( scorer . score_sentences ([ "Hello world!" ], per_token = True ))
# >> [[-8.293947219848633, -6.387561798095703, -1.3138668537139893]](¡Las interfaces MXNet y Pytorch se unificarán pronto!)
Ejecute mlm score --help para ver modelos compatibles, etc. Consulte examples/demo/format.json para el formato de archivo. Para las entradas, "Score" es opcional. Las salidas agregarán campos de "puntuación" que contienen puntajes PLL.
Hay tres tipos de puntaje, dependiendo del modelo:
--no-mask ) Puntuamos hipótesis para 3 enunciados de Librispeech dev-other en GPU 0 usando Bert Base (no basado):
mlm score
--mode hyp
--model bert-base-en-uncased
--max-utts 3
--gpus 0
examples/asr-librispeech-espnet/data/dev-other.am.json
> examples/demo/dev-other-3.lm.json Uno puede rescorar las listas N-Best a través de la interpolación lineal log. Ejecute mlm rescore --help para ver todas las opciones. La entrada uno es un archivo con puntajes originales; La entrada dos son puntajes de mlm score .
Respetamos las puntuaciones acústicas (de dev-other.am.json ) utilizando las puntuaciones de Bert (de la sección anterior), bajo diferentes pesos de LM:
for weight in 0 0.5 ; do
echo " lambda= ${weight} " ;
mlm rescore
--model bert-base-en-uncased
--weight ${weight}
examples/asr-librispeech-espnet/data/dev-other.am.json
examples/demo/dev-other-3.lm.json
> examples/demo/dev-other-3.lambda- ${weight} .json
doneEl WER original es del 12,2%, mientras que el WER rescorado es del 8,5%.
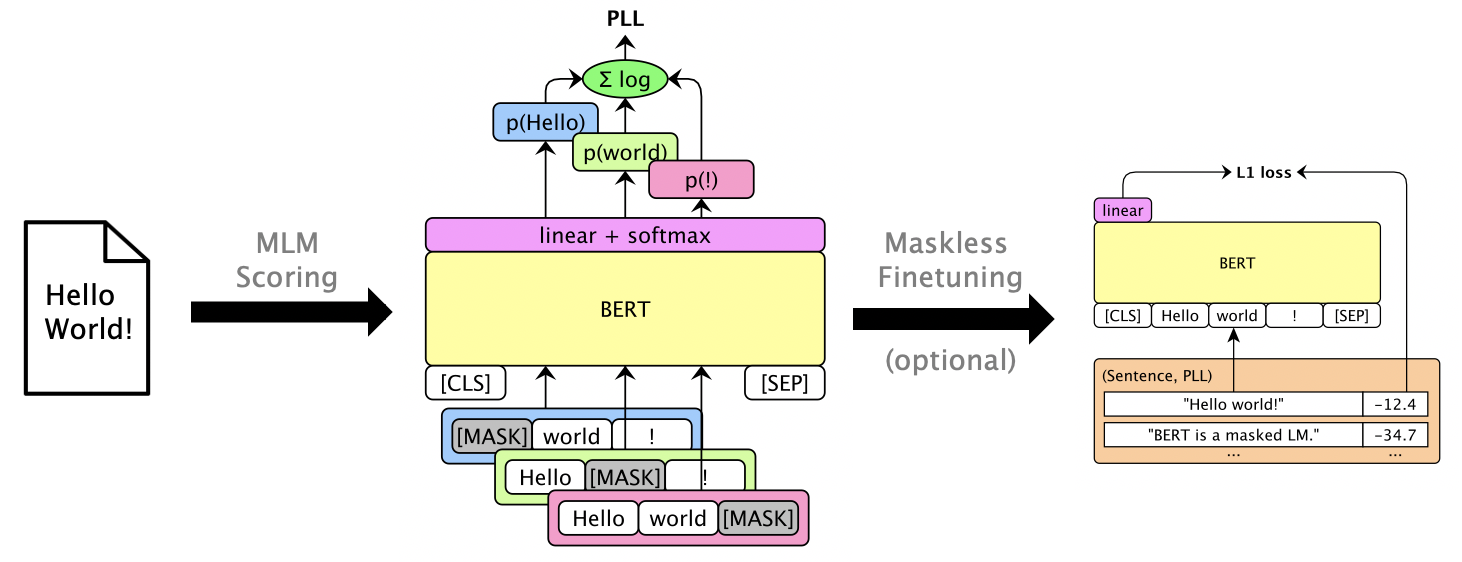
Uno puede Finetune enmascarado LMS para dar puntajes PLL utilizables sin enmascarar. Ver Librispeech Finetuning sin máscara.
Ejecute pip install -e .[dev] para instalar paquetes de prueba adicionales. Entonces:
pytest --cov=src/mlm en el directorio raíz.

