SimCSE
0.4
該存儲庫包含我們的紙張SIMCSE的代碼和預訓練的模型:簡單的對比度學習句子嵌入。
**************************************************************
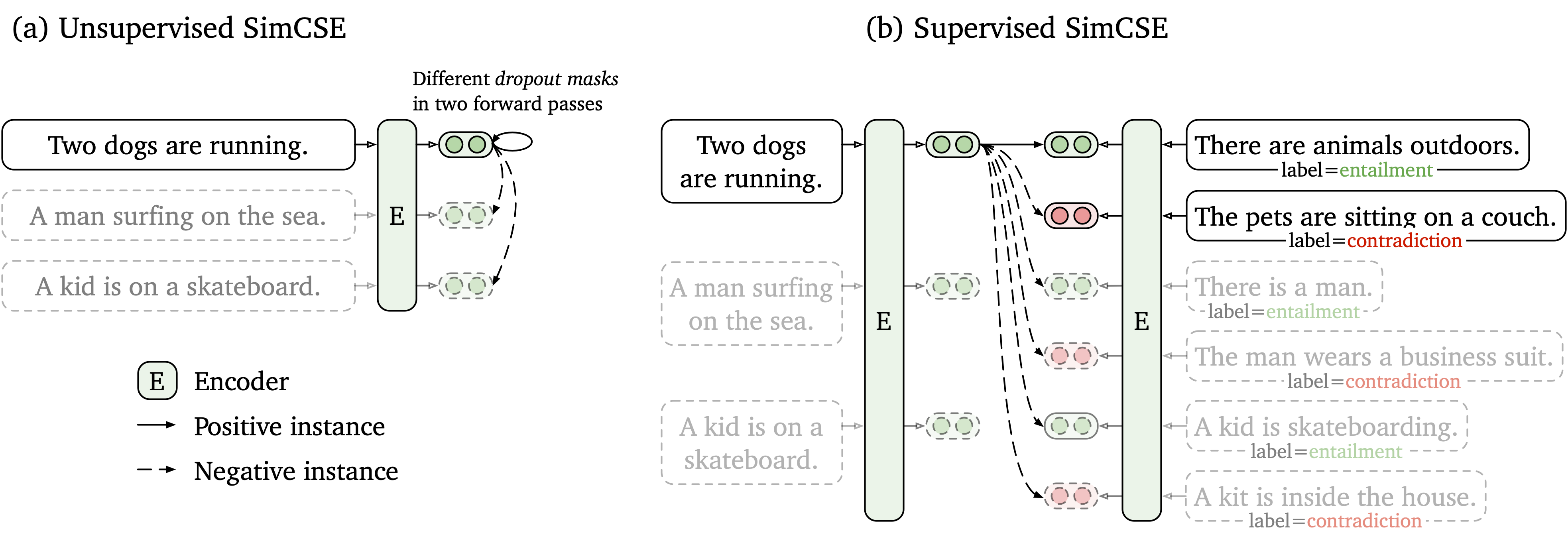
我們提出了一個簡單的對比學習框架,該框架與未標記和標記的數據一起使用。無監督的SIMCSE只是採用輸入句子,並在對比度學習框架中預測自己,僅將標準輟學用作噪聲。我們有監督的SIMCSE通過使用entailment對作為肯定和contradiction對作為硬否負面因素,將NLI數據集的帶註釋的對對比度學習。下圖是我們模型的例證。
我們根據SIMCSE模型提供了易於使用的句子嵌入工具(有關詳細用法,請參見我們的Wiki)。要使用該工具,請先從PYPI安裝simcse軟件包
pip install simcse或直接從我們的代碼安裝
python setup.py install請注意,如果要啟用GPU編碼,則應安裝支持CUDA的Pytorch的正確版本。有關說明,請參見Pytorch官方網站。
安裝軟件包後,您只需兩行代碼加載我們的模型
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )有關可用型號的完整列表,請參見模型列表。
然後,您可以使用我們的模型將句子編碼為嵌入
embeddings = model . encode ( "A woman is reading." )計算兩組句子之間的餘弦相似性
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )或為一組句子構建索引並在其中搜索
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." )我們還支持有效的相似性搜索庫Faiss。只需在此處安裝包裝按照說明即可, simcse將自動使用faiss進行有效的搜索。
警告:我們發現faiss不能很好地支持Nvidia Ampere GPU(3090和A100)。在這種情況下,您應該更改為其他GPU或安裝CPU版本的faiss軟件包。
我們還提供一個易於構建的演示網站,以顯示如何在句子檢索中使用SIMCSE。該代碼基於密碼和演示(非常感謝緻密詞的作者)。
我們發布的模型如下。您可以使用simcse軟件包或使用HuggingFace的變壓器導入這些模型。
| 模型 | avg。 sts |
|---|---|
| Princeton-NLP/Unsup-Simcse-Bert-Base-Base-Base-unc. | 76.25 |
| Princeton-NLP/Unsup-Simcse-Bert-large-unge | 78.41 |
| 普林斯頓-NLP/Unsup-Simcse-Roberta基礎 | 76.57 |
| 普林斯頓-NLP/Unsup-Simcse-Roberta-large | 78.90 |
| Princeton-NLP/SUP-SIMCSE-BERT-BASE不合格 | 81.57 |
| 普林斯頓-NLP/sup-simcse-bert-large-large | 82.21 |
| 普林斯頓-NLP/SUP-SIMCSE-ROBERTA-BASE | 82.52 |
| 普林斯頓-NLP/SUP-SIMCSE-ROBERTA-LARGE | 83.76 |
請注意,在採用了一組新的超參數(有關超參數,請參見培訓部分)後,結果比我們在本文當前版本中報告的結果稍好一些。
命名規則: unsup和sup分別代表“無監督”(在Wikipedia語料庫中訓練)和“監督”(在NLI數據集中受過培訓)。
除了使用我們提供的句子嵌入工具外,您還可以輕鬆地使用HuggingFace的transformers導入我們的模型:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 ))如果您通過HuggingFace的API直接加載模型時會遇到任何問題,則還可以從上表手動下載模型,並使用model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) 。
在下一節中,我們描述瞭如何使用我們的代碼訓練SIMCSE模型。
首先,按照官方網站的說明安裝Pytorch。為了忠實地重現我們的結果,請使用與您的平台/CUDA版本相對應的正確的1.7.1版本。 pytorch版本高於1.7.1也應起作用。例如,如果您使用Linux和CUDA11 (如何檢查CUDA版本),請按以下命令安裝Pytorch,
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html如果您使用CUDA <11或CPU ,請按以下命令安裝Pytorch,
pip install torch==1.7.1然後運行以下腳本以安裝剩餘的依賴項,
pip install -r requirements.txt我們針對句子嵌入的評估代碼基於Senteval的修改版本。它評估句子嵌入語義文本相似性(STS)任務和下游傳輸任務。對於STS任務,我們的評估採用“所有”設置,並報告Spearman的相關性。有關評估詳細信息,請參見我們的論文(附錄B)。
在評估之前,請通過運行下載評估數據集
cd SentEval/data/downstream/
bash download_dataset.sh然後回到根目錄,您可以使用我們的評估代碼評估任何基於transformers的預訓練模型。例如,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode test預計將以表格格式輸出結果:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
評估腳本的論點如下,
--model_name_or_path :基於transformers的預訓練檢查點的名稱或路徑。您可以直接使用上表中的模型,例如, princeton-nlp/sup-simcse-bert-base-uncased 。--pooler :合併方法。現在我們支持cls (默認):使用[CLS]令牌的表示。表示在表示後(標準BERT實施中)應用線性+激活層。如果您使用監督的SIMCSE ,則應使用此選項。cls_before_pooler :使用[CLS]令牌的表示,而無需額外的線性+激活。如果您使用無監督的SIMCSE ,則應採用此選項。avg :最後一層的平均嵌入。如果您使用Sbert/Sroberta(紙)的檢查站,則應使用此選項。avg_top2 :最後兩層的平均嵌入。avg_first_last :第一層和最後一層的平均嵌入。如果您使用Vanilla Bert或Roberta,則最好。請注意,在論文中,我們報告了最後一層的平均值和靜態單詞嵌入;我們將其定義為最後一層和第一層的平均值,並帶來了更好的性能。請參閱此問題以進行詳細討論。--mode :評估模式test (默認):默認測試模式。為了忠實地重現我們的結果,您應該使用此選項。dev :報告開發集結果。請注意,在STS任務中,只有STS-B和SICK-R具有開發集,因此我們只報告其數字。它還需要快速的傳輸任務模式,因此運行時間比test模式短得多(儘管數字略低)。fasttest :它與test相同,但是使用快速模式,因此運行時間要短得多,但是報告的數字可能較低(僅適用於轉移任務)。--task_set :要評估的一組任務集(如果設置,它將覆蓋--tasks )sts (默認):在STS任務上進行評估,包括STS 12~16 , STS-B和SICK-R 。這是評估句子嵌入質量的最常用的任務集。transfer :評估轉移任務。full :對兩個ST和轉移任務進行評估。na :按--tasks手動設置任務。--tasks :指定要評估的數據集。如果--task_set不是na ,將被覆蓋。請參閱代碼以獲取完整的任務列表。數據
對於無監督的Simcse,我們從英語Wikipedia中進行了100萬句話;對於受監督的SIMCSE,我們使用SNLI和MNLI數據集。您可以運行data/download_wiki.sh和data/download_nli.sh下載兩個數據集。
培訓腳本
我們為無監督和監督的SIMCSE提供示例培訓腳本。在run_unsup_example.sh中,我們為無監督版提供了一個單GPU(或CPU)示例,在run_sup_example.sh中,我們為監督版提供了一個多GPU示例。兩個腳本都致電train.py進行培訓。我們在以下內容中解釋了以下論點:
--train_file :培訓文件路徑。我們支持“ txt”文件(一個句子的一行)和“ csv”文件(2個列:沒有硬性負面的數據; 3列:配對數據與一個相應的硬否實例)。您可以使用我們提供的Wikipedia或NLI數據,也可以使用自己的數據以相同的格式使用。--model_name_or_path :首先進行的預訓練檢查點。目前,我們支持基於BERT的模型(基於bert-base-uncased , bert-large-uncased等)和基於Roberta的模型( RoBERTa-base , RoBERTa-large等)。--temp :對比度損失的溫度。--pooler_type :池化方法。它與評估部分中的--pooler_type相同。--mlp_only_train :我們發現,對於無監督的SIMCSE,使用MLP層訓練模型卻更好,但沒有它測試模型。在訓練無監督的SIMCSE模型時,您應該使用此參數。--hard_negative_weight :如果使用硬負元(即,培訓文件中有3列),則是重量的對數。例如,如果權重為1,則應將此參數設置為0(默認值)。--do_mlm :是否使用MLM輔助目標。如果是真的:--mlm_weight :MLM目標的重量。--mlm_probability :MLM目標的掩蔽率。所有其他論點都是標準的Huggingface的transformers培訓論點。一些經常使用的參數是: --output_dir , --learning_rate , --per_device_train_batch_size 。在我們的示例腳本中,我們還設置了在STS-B開發集中評估模型(在評估部分之後需要下載數據集)並保存最佳檢查點。
對於本文中的結果,我們將NVIDIA 3090 GPU與CUDA 11一起使用。使用不同類型的設備或不同版本的CUDA/其他軟件可能會導致性能略有不同。
超參數
我們使用以下Hybreparamter進行培訓SIMCSE:
| 解開。伯特 | 解開。羅伯塔 | sup。 | |
|---|---|---|---|
| 批量大小 | 64 | 512 | 512 |
| 學習率(基礎) | 3E-5 | 1E-5 | 5E-5 |
| 學習率(大) | 1E-5 | 3E-5 | 1E-5 |
轉換模型
我們保存的檢查點與HuggingFace的預訓練檢查點略有不同。運行python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER}將其轉換。之後,您可以通過我們的評估代碼對其進行評估,也可以將其直接使用。
如果您有與代碼或論文有關的任何疑問,請隨時發送電子郵件至Tianyu( [email protected] )和Xingcheng( [email protected] )。如果使用代碼時遇到任何問題或想報告錯誤,則可以打開問題。請嘗試使用詳細信息指定問題,以便我們可以更好,更快地幫助您!
如果您在工作中使用Simcse,請引用我們的論文:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}我們感謝社區為擴展Simcse的努力!
sentence-transformers的培訓代碼。

