SimCSE
0.4
يحتوي هذا المستودع على الكود والنماذج المدربة مسبقًا لورق SIMCSE: التعلم التباين البسيط لتضمينات الجملة.
**************************** تحديثات ******************************
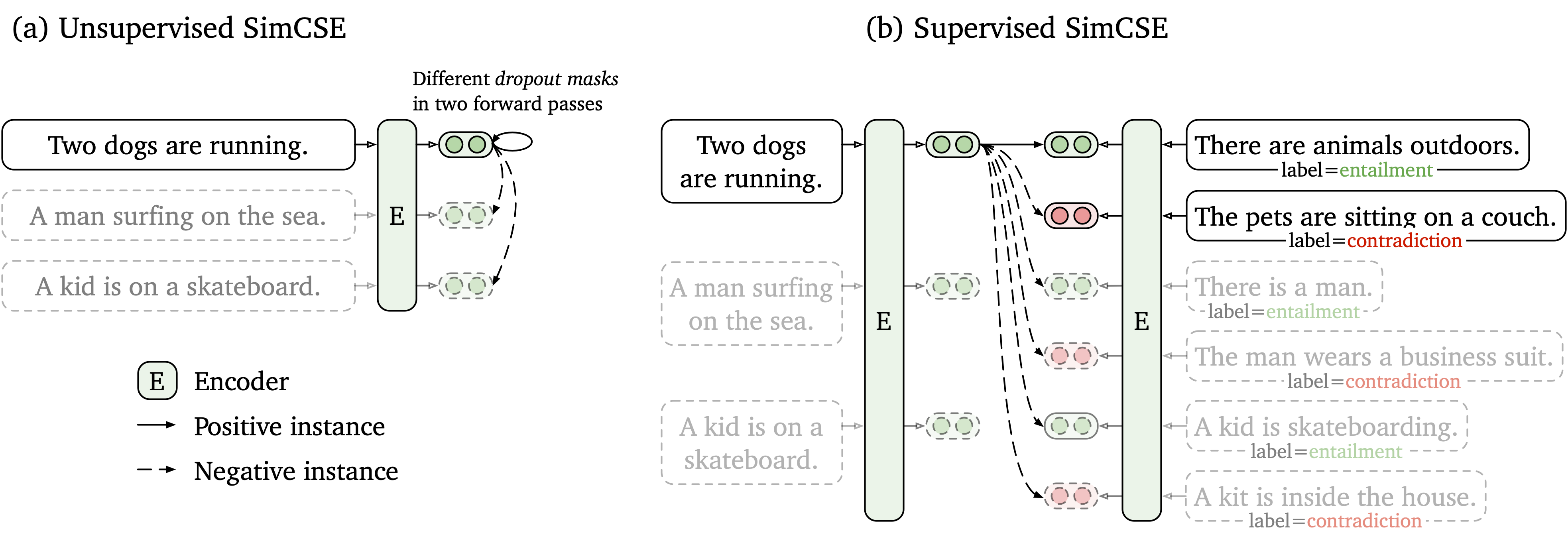
نقترح إطار عمل تعليمي تباين بسيط يعمل مع كل من البيانات غير المسماة والمسمى. يأخذ SIMCSE غير الخاضعة للإشراف ببساطة جملة إدخال ويتوقع نفسه في إطار تعليمي تباين ، مع استخدام التسرب القياسي فقط كضوضاء. يشتمل SIMCSE الخاضع للإشراف على أزواج مشروحة من مجموعات بيانات NLI إلى التعلم التباين باستخدام أزواج entailment كإيجابيات وأزواج contradiction كسلبيات صلبة. الشكل التالي هو توضيح لنماذجنا.
نحن نقدم أداة تضمين جملة سهلة الاستخدام استنادًا إلى نموذج SIMCSE الخاص بنا (انظر WIKI للحصول على استخدام مفصل). لاستخدام الأداة ، قم أولاً بتثبيت حزمة simcse من Pypi
pip install simcseأو تثبيته مباشرة من الكود لدينا
python setup.py installلاحظ أنه إذا كنت ترغب في تمكين ترميز GPU ، فيجب عليك تثبيت الإصدار الصحيح من Pytorch الذي يدعم CUDA. انظر موقع Pytorch الرسمي للحصول على التعليمات.
بعد تثبيت الحزمة ، يمكنك تحميل طرازنا من خلال سطرين فقط من التعليمات البرمجية
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )انظر قائمة النماذج للحصول على قائمة كاملة من النماذج المتاحة.
ثم يمكنك استخدام نموذجنا لتشفير الجمل في التضمين
embeddings = model . encode ( "A woman is reading." )حساب أوجه تشابه جيب التمام بين مجموعتين من الجمل
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )أو فهرس بناء لمجموعة من الجمل والبحث فيما بينها
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) نحن ندعم أيضًا Faiss ، مكتبة بحث فعالة للتشابه. ما عليك سوى تثبيت الحزمة التالية هنا وسيستخدم simcse تلقائيًا faiss للبحث الفعال.
تحذير : لقد وجدنا أن faiss لم يدعم جيدًا Nvidia Ampere GPU (3090 و A100). في هذه الحالة ، يجب عليك التغيير إلى وحدات معالجة الرسومات الأخرى أو تثبيت إصدار وحدة المعالجة المركزية من حزمة faiss .
نقدم أيضًا موقعًا تجريبيًا سهل الاستخدام لإظهار كيف يمكن استخدام Simcse في استرجاع الجملة. يعتمد الرمز على عبارات الكثافة والعروض التجريبية (شكر كبير لمؤلفي العبارات الكثيفة).
يتم سرد النماذج التي تم إصدارها على النحو التالي. يمكنك استيراد هذه النماذج باستخدام حزمة simcse أو استخدام محولات Huggingface.
| نموذج | متوسط. STS |
|---|---|
| Princeton-NLP/unsup-simcse-bert-base | 76.25 |
| Princeton-NLP/unsup-simcse-bert-large | 78.41 |
| Princeton-NLP/Unsup-Simcse-Roberta-Base | 76.57 |
| Princeton-NLP/Unsup-Simcse-Roberta-Large | 78.90 |
| Princeton-NLP/SUP-SIMCSE-BERT-BASE | 81.57 |
| Princeton-NLP/SUP-SIMCSE-BERT-LARGE | 82.21 |
| Princeton-NLP/SUP-SIMCSE-ROBERTA-BASE | 82.52 |
| Princeton-NLP/SUP-SIMCSE-ROBERTA-LARGE | 83.76 |
لاحظ أن النتائج أفضل قليلاً مما أبلغنا عنه في الإصدار الحالي من الورقة بعد اعتماد مجموعة جديدة من المقاييس المفرطة (للاطلاع على الفائقين ، انظر قسم التدريب).
قواعد التسمية : تمثل " unsup " و sup "غير خاضعة للإشراف" (المدربة على ويكيبيديا كوربوس) و "إشراف" (مدربة على مجموعات بيانات NLI) على التوالي.
إلى جانب استخدام أداة تضمين الجملة الخاصة بنا ، يمكنك أيضًا استيراد نماذجنا بسهولة transformers Huggingface:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) إذا واجهت أي مشكلة عند تحميل النماذج مباشرة عن طريق واجهة برمجة تطبيقات HuggingFace ، فيمكنك أيضًا تنزيل النماذج يدويًا من الجدول أعلاه واستخدام model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) .
في القسم التالي ، نصف كيفية تدريب نموذج SIMCSE باستخدام الكود الخاص بنا.
أولاً ، قم بتثبيت Pytorch باتباع الإرشادات من الموقع الرسمي. لإعادة إنتاج نتائجنا بأمانة ، يرجى استخدام الإصدار 1.7.1 الصحيح الذي يتوافق مع إصدارات المنصات/CUDA الخاصة بك. يجب أن يعمل إصدار Pytorch أعلى من 1.7.1 . على سبيل المثال ، إذا كنت تستخدم Linux و CUDA11 (كيفية التحقق من إصدار CUDA) ، فقم بتثبيت Pytorch حسب الأمر التالي ،
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html إذا استخدمت بدلاً من ذلك CUDA <11 أو وحدة المعالجة المركزية ، فقم بتثبيت pytorch حسب الأمر التالي ،
pip install torch==1.7.1ثم قم بتشغيل البرنامج النصي التالي لتثبيت التبعيات المتبقية ،
pip install -r requirements.txtيعتمد رمز التقييم الخاص بنا للتضمينات الجملة على نسخة معدلة من SentVal. ويقيم التضمينات الجملة على مهام التشابه النصي الدلالي (STS) ومهام نقل المصب. بالنسبة لمهام STS ، يأخذ تقييمنا إعداد "الكل" ، والإبلاغ عن ارتباط سبيرمان. انظر ورقتنا (التذييل ب) للحصول على تفاصيل التقييم.
قبل التقييم ، يرجى تنزيل مجموعات بيانات التقييم عن طريق التشغيل
cd SentEval/data/downstream/
bash download_dataset.sh ثم عد إلى دليل الجذر ، يمكنك تقييم أي نماذج تم تدريبها مسبقًا على أساس transformers باستخدام رمز التقييم الخاص بنا. على سبيل المثال،
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode testالذي من المتوقع أن يخرج النتائج بتنسيق جدولي:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
حجج البرنامج النصي للتقييم هي كما يلي ،
--model_name_or_path : اسم أو مسار نقطة تفتيش مستند إلى transformers . يمكنك استخدام النماذج مباشرة في الجدول أعلاه ، على سبيل المثال ، princeton-nlp/sup-simcse-bert-base-uncased .--pooler : طريقة التجميع. الآن نحن ندعمcls (افتراضي): استخدم تمثيل الرمز المميز [CLS] . يتم تطبيق طبقة التنشيط الخطية+بعد التمثيل (في تطبيق Bert القياسي). إذا كنت تستخدم SIMCSE الخاضعة للإشراف ، فيجب عليك استخدام هذا الخيار.cls_before_pooler : استخدم تمثيل الرمز المميز [CLS] بدون تنشيط خطي إضافي+. إذا كنت تستخدم SIMCSE غير الخاضع للإشراف ، فيجب عليك اتخاذ هذا الخيار.avg : متوسط التضمينات للطبقة الأخيرة. إذا كنت تستخدم نقاط التفتيش من Sbert/Sroberta (ورقة) ، فيجب عليك استخدام هذا الخيار.avg_top2 : متوسط التضمينات للطبقتين الأخيرتين.avg_first_last : متوسط التضمينات للطبقات الأولى والأخيرة. إذا كنت تستخدم Vanilla Bert أو Roberta ، فهذا يعمل بشكل أفضل. لاحظ أنه في الورقة أبلغنا عن متوسط الطبقة الأخيرة والكلمة الثابتة ؛ قمنا بإصلاح هذا ليكون متوسط الطبقة الأخيرة والأول وأدى إلى أداء أفضل. شاهد هذه المسألة للحصول على مناقشة مفصلة.--mode : وضع التقييمtest (افتراضي): وضع الاختبار الافتراضي. لإعادة إنتاج نتائجنا بأمانة ، يجب عليك استخدام هذا الخيار.dev : أبلغ عن نتائج مجموعة التطوير. لاحظ أنه في مهام STS ، يتمتع فقط STS-B و SICK-R بمجموعات التطوير ، لذلك نحن نقوم بإبلاغ أعدادهم فقط. يتطلب الأمر أيضًا وضعًا سريعًا لمهام النقل ، وبالتالي فإن وقت التشغيل أقصر بكثير من وضع test (على الرغم من أن الأرقام أقل قليلاً).fasttest : إنه نفس test ، ولكن مع وضع سريع بحيث يكون وقت التشغيل أقصر بكثير ، ولكن قد تكون الأرقام المبلغ عنها أقل (فقط لمهام النقل).--task_set : ما هي مجموعة المهام التي يجب تقييمها (إذا تم تعيينها ، فسيتم تجاوزها --tasks )sts (افتراضي): تقييم مهام STS ، بما في ذلك STS 12~16 ، STS-B و SICK-R . هذه هي المجموعة الأكثر استخدامًا من المهام لتقييم جودة التضمينات.transfer : تقييم على مهام النقل.full : تقييم على كل من STS ومهام النقل.na : تعيين المهام يدويًا بواسطة --tasks .--tasks : حدد مجموعة (مجموعات) البيانات التي يجب تقييمها على. سيتم تجاوزه إذا لم يكن --task_set na . انظر الرمز للحصول على قائمة كاملة من المهام.بيانات
بالنسبة إلى SIMCSE غير الخاضع للإشراف ، نقوم بتجربة مليون جملة من ويكيبيديا الإنجليزية ؛ ل SIMCSE الخاضعة للإشراف ، نستخدم مجموعات بيانات SNLI و MNLI. يمكنك تشغيل data/download_wiki.sh و data/download_nli.sh لتنزيل مجموعتي البيانات.
البرامج النصية التدريبية
نحن نقدم مثال على البرامج النصية التدريبية لكل من SIMCSE غير الخاضع للإشراف والمشرف. في run_unsup_example.sh ، نقدم مثالًا واحدًا (أو وحدة المعالجة المركزية) على الإصدار غير الخاضع للإشراف ، وفي run_sup_example.sh نقدم مثالًا متعدد GPU للإصدار الخاضع للإشراف. كلا البرامج النصية Call train.py للتدريب. نوضح الحجج في المتابعة:
--train_file : مسار ملف التدريب. نحن ندعم ملفات "TXT" (سطر واحد لجمل واحدة) و "CSV" ملفات (عمود 2: بيانات الزوج بدون سلبية صلبة ؛ 3 عمود: بيانات الزوج مع مثيل سلبي صلب واحد). يمكنك استخدام بيانات Wikipedia أو NLI المقدمة ، أو يمكنك استخدام بياناتك بنفس التنسيق.--model_name_or_path : نقاط تفتيش تدرب مسبقًا للبدء بها. في الوقت الحالي ، ندعم النماذج المستندة إلى Bert ( bert-base-uncased ، bert-large-uncased ، وما إلى ذلك) ونماذج مقرها روبرتا ( RoBERTa-base ، RoBERTa-large ، إلخ).--temp : درجة حرارة الخسارة المتناقضة.--pooler_type : طريقة التجميع. إنه نفس --pooler_type في جزء التقييم.--mlp_only_train : لقد وجدنا أنه من أجل SIMCSE غير الخاضع للإشراف ، يعمل بشكل أفضل لتدريب النموذج باستخدام طبقة MLP ولكن اختبار النموذج بدونه. يجب عليك استخدام هذه الحجة عند تدريب نماذج SIMCSE غير الخاضعة للإشراف.--hard_negative_weight : إذا كان استخدام السلبيات الصلبة (أي ، هناك 3 أعمدة في ملف التدريب) ، فهذه هي اللوغاريتم على الوزن. على سبيل المثال ، إذا كان الوزن هو 1 ، فيجب تعيين هذه الوسيطة على أنها 0 (القيمة الافتراضية).--do_mlm : ما إذا كان يجب استخدام الهدف المساعدة MLM. إذا كان صحيحا:--mlm_weight : وزن الهدف MLM.--mlm_probability : معدل التقنيع للهدف MLM. جميع الحجج الأخرى هي حجج تدريب transformers . بعض الوسائط التي يتم استخدامها في كثير من الأحيان هي: --output_dir ، --learning_rate ، --per_device_train_batch_size . في مثالنا البرامج النصية ، قمنا أيضًا بتعيين لتقييم النموذج على مجموعة تطوير STS-B (بحاجة إلى تنزيل مجموعة البيانات بعد قسم التقييم) وحفظ أفضل نقطة تفتيش.
للنتائج في الورقة ، نستخدم NVIDIA 3090 GPU مع CUDA 11. قد يؤدي استخدام أنواع مختلفة من الأجهزة أو الإصدارات المختلفة من CUDA/برامج أخرى إلى أداء مختلف قليلاً.
فرطاميرات
نستخدم المتقاعدين التاليين لتدريب Simcse:
| غير مبال. بيرت | غير مبال. روبرتا | رشفة. | |
|---|---|---|---|
| حجم الدُفعة | 64 | 512 | 512 |
| معدل التعلم (قاعدة) | 3e-5 | 1E-5 | 5e-5 |
| معدل التعلم (كبير) | 1E-5 | 3e-5 | 1E-5 |
تحويل النماذج
تختلف نقاط التفتيش المحفوظة لدينا قليلاً عن نقاط التفتيش التي تم تدريبها مسبقًا في Huggingface. قم بتشغيل python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} لتحويله. بعد ذلك ، يمكنك تقييمه حسب رمز التقييم الخاص بنا أو استخدامه مباشرة خارج المربع.
إذا كان لديك أي أسئلة تتعلق بالرمز أو الورقة ، فلا تتردد في إرسال بريد إلكتروني إلى Tianyu ( [email protected] ) و Xingcheng ( [email protected] ). إذا واجهت أي مشاكل عند استخدام الرمز ، أو ترغب في الإبلاغ عن خطأ ، فيمكنك فتح مشكلة. يرجى محاولة تحديد المشكلة مع التفاصيل حتى نتمكن من مساعدتك بشكل أفضل وأسرع!
يرجى الاستشهاد بالورقة إذا كنت تستخدم Simcse في عملك:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}نشكر جهود المجتمع لتمديد Simcse!
sentence-transformers على SIMCSE.

