SimCSE
0.4
Этот репозиторий содержит код и предварительно обученные модели для нашей бумаги SIMCSE: простое контрастное обучение встроенных предложений.
**************************
Мы предлагаем простую контрастную структуру обучения, которая работает как с немечеными, так и с маркированными данными. Неконтролируемый Simcse просто принимает входное предложение и предсказывает себя в контрастной структуре обучения, с использованием только стандартного отсева в качестве шума. Наш контролируемый SIMCSE включает аннотированные пары из наборов данных NLI в контрастное обучение, используя пары entailment в качестве положительных и contradiction пар в качестве жестких негативов. Следующая цифра является иллюстрацией наших моделей.
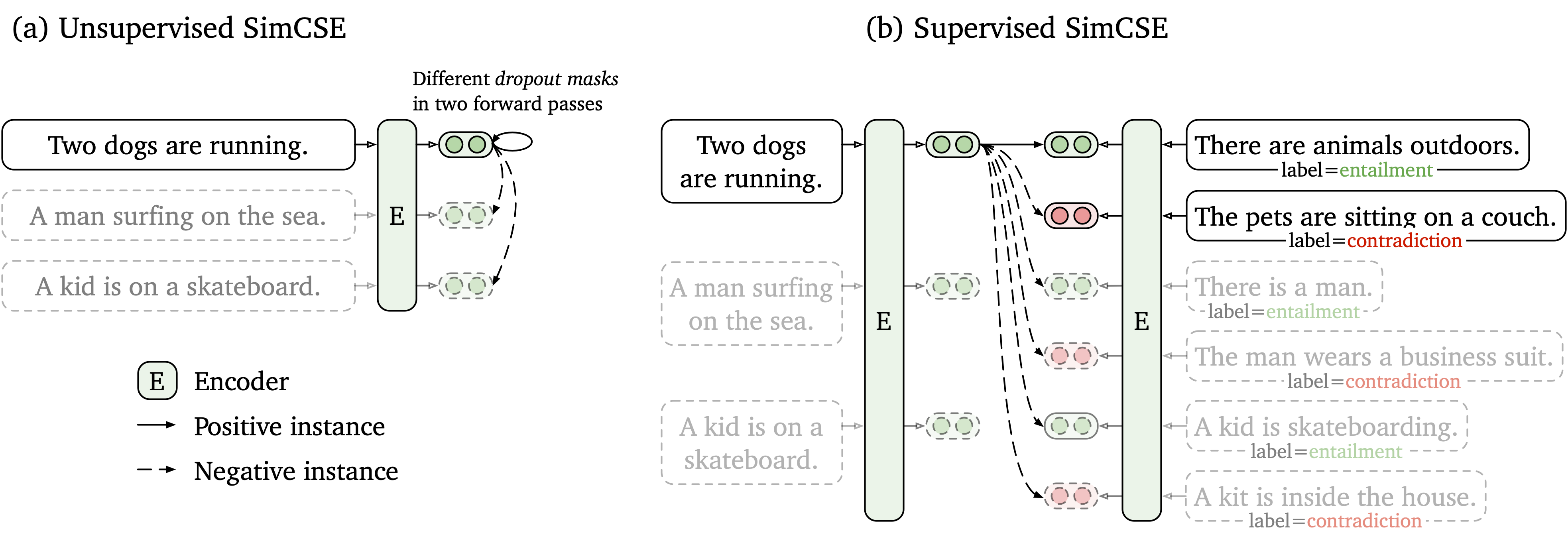
Мы предоставляем простой в использовании инструмент для встраивания предложений, основанный на нашей модели SIMCSE (см. Наш вики для подробного использования). Чтобы использовать инструмент, сначала установите пакет simcse от PYPI
pip install simcseИли напрямую установите его из нашего кода
python setup.py installОбратите внимание, что если вы хотите включить кодирование GPU, вам следует установить правильную версию Pytorch, которая поддерживает CUDA. Смотрите официальный сайт Pytorch для инструкций.
После установки пакета вы можете загрузить нашу модель только на две строки кода
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )См. Список моделей для полного списка доступных моделей.
Тогда вы можете использовать нашу модель для кодирования предложений в встраивание
embeddings = model . encode ( "A woman is reading." )Вычислить сходство косинуса между двумя группами предложений
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )Или индекс создания для группы предложений и поиска среди них
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) Мы также поддерживаем Faiss, эффективную библиотеку поиска сходства. Просто установите пакет следующие инструкции здесь, и simcse автоматически использует faiss для эффективного поиска.
Предупреждение : мы обнаружили, что faiss не очень хорошо поддерживает графические процессоры NVIDIA AMPERE (3090 и A100). В этом случае вам следует изменить другие графические процессоры или установить версию CPU faiss Package.
Мы также предоставляем простой демонстрационный веб-сайт, чтобы показать, как Simcse можно использовать в поиске предложений. Код основан на репо и демонстрации DensePhrase (большое спасибо авторам DensePhrase).
Наши выпущенные модели перечислены следующими. Вы можете импортировать эти модели, используя пакет simcse или используя трансформаторы HuggingFace.
| Модель | Ав. Стр |
|---|---|
| Принстон-NLP/UNSUP-SIMCSE-BERT-BASE-UPDASED | 76.25 |
| Принстон-NLP/UNSUP-SIMCSE-BERT-LARGE-INDED | 78.41 |
| Принстон-NLP/UNSUP-SIMCSE-ROBERTA-BASE | 76.57 |
| Принстон-NLP/UNSUP-SIMCSE-ROBERTA-LARGE | 78.90 |
| Принстон-NLP/SUP-SIMCSE-BERT-BASE-UPDASED | 81.57 |
| Принстон-NLP/SUP-SIMCSE-BERT-LARGE-UPSADED | 82,21 |
| Принстон-NLP/SUP-SIMCSE-ROBERTA-BASE | 82,52 |
| Принстон-NLP/SUP-SIMCSE-ROBERTA-LARGE | 83,76 |
Обратите внимание, что результаты немного лучше, чем мы сообщили в текущей версии статьи после принятия нового набора гиперпараметров (для гиперпарамтеров см. В разделе обучения).
Правила именования : unsup и sup представляют «неконтролируемые» (обученные на Wikipedia Corpus) и «контролируемый» (обученные наборам данных NLI) соответственно.
Помимо использования нашего предоставленного инструмента для встраивания предложений, вы также можете легко импортировать наши модели с помощью transformers Huggingface:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) Если вы столкнетесь с какой -либо проблемой при непосредственной загрузке моделей с помощью API Huggingface, вы также можете загрузить модели вручную из приведенной выше таблицы и использовать model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) .
В следующем разделе мы опишем, как обучить модель SIMCSE, используя наш код.
Во -первых, установите Pytorch, следуя инструкциям с официального сайта. Чтобы верно воспроизвести наши результаты, используйте правильную версию 1.7.1 , соответствующую вашим платформам/версиям CUDA. Версия Pytorch выше 1.7.1 должна также работать. Например, если вы используете Linux и CUDA11 (как проверить версию CUDA), установите Pytorch по следующей команде,
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html Если вы вместо этого используете CUDA <11 или CPU , установите Pytorch по следующей команде,
pip install torch==1.7.1Затем запустите следующий скрипт для установки оставшихся зависимостей,
pip install -r requirements.txtНаш код оценки для предложений Entgeddings основан на модифицированной версии Senteval. Он оценивает встраиваемые предложения по задачам семантического текстового сходства (STS) и задачах переноса вниз по течению. Для задач STS наша оценка принимает настройку «все» и сообщает о корреляции Спирмена. Смотрите нашу статью (Приложение B) для деталей оценки.
Перед оценкой, пожалуйста, загрузите наборы данных оценки, запустив
cd SentEval/data/downstream/
bash download_dataset.sh Затем вернитесь к корневому каталогу, вы можете оценить любые предварительно обученные модели, основанные на transformers , используя наш код оценки. Например,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode testкоторый, как ожидается, выведет результаты в табличном формате:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
Аргументы для сценария оценки следующие,
--model_name_or_path : имя или путь предварительно обученной контрольной точки на основе transformers . Вы можете напрямую использовать модели в приведенной выше таблице, например, princeton-nlp/sup-simcse-bert-base-uncased .--pooler : метод объединения. Теперь мы поддерживаемcls (по умолчанию): используйте представление токена [CLS] . Линейный уровень активации+применяется после представления (он находится в стандартной реализации BERT). Если вы используете контролируемый Simcse , вы должны использовать эту опцию.cls_before_pooler : Используйте представление токена [CLS] без линейной+активации. Если вы используете неконтролируемый Simcse , вы должны принять эту опцию.avg : Средние встроения последнего слоя. Если вы используете контрольные точки Sbert/Sroberta (Paper), вам следует использовать эту опцию.avg_top2 : Средние встраивания последних двух слоев.avg_first_last : Средние встраивания первого и последнего слоев. Если вы используете Vanilla Bert или Roberta, это работает лучше всего. Обратите внимание, что в статье мы сообщили о среднем уровне последнего слоя и статическом встраивании слова; Мы исправили, чтобы это было последним и первым средним уровнем, и это привело к лучшей производительности. Смотрите этот вопрос для подробного обсуждения.--mode : режим оценкиtest (по умолчанию): режим тестирования по умолчанию. Чтобы верно воспроизвести наши результаты, вы должны использовать эту опцию.dev : Сообщите о результатах разработки. Обратите внимание, что в задачах STS только STS-B и SICK-R имеют наборы разработки, поэтому мы сообщаем только об их числах. Он также занимает быстрый режим для передачи задач, поэтому время выполнения намного короче, чем test режим (хотя числа немного ниже).fasttest : он такой же, как и test , но с быстрым режимом, поэтому время выполнения намного короче, но сообщаемые числа могут быть ниже (только для задач переноса).--task_set : какой набор задач для оценки (если установлен, он будет переопределять --tasks )sts (по умолчанию): оцените задачи STS, включая STS 12~16 , STS-B и SICK-R . Это наиболее часто используемый набор задач для оценки качества встроенных предложений.transfer : Оцените задачи передачи.full : оценить как на STS, так и на передачу задач.na : вручную задавайте задачи --tasks .--tasks : укажите, какой набор данных (ы) для оценки. Будет переопределен, если --task_set не na . Смотрите код для полного списка задач.Данные
Для неконтролируемого Simcse мы выбираем 1 миллион предложений из английской Википедии; Для контролируемого SIMCSE мы используем наборы данных SNLI и MNLI. Вы можете запустить data/download_wiki.sh и data/download_nli.sh для загрузки двух наборов данных.
Обучающие сценарии
Мы приводим пример учебных сценариев как для неконтролируемого, так и для контролируемого SIMCSE. В run_unsup_example.sh мы приводим пример одного-GPU (или CPU) для неконтролируемой версии, а в run_sup_example.sh мы даем пример с несколькими GPU для контролируемой версии. Оба сценария звонят на train.py для обучения. Мы объясняем аргументы следующим образом:
--train_file : Путь файла обучения. Мы поддерживаем файлы «txt» (одна строка для одного предложения) и файлы «CSV» (2-Column: пара данных без жесткого отрицания; 3-Column: пара данных с одним соответствующим жестким отрицательным экземпляром). Вы можете использовать наши предоставленные данные Wikipedia или NLI, или вы можете использовать свои собственные данные с тем же форматом.--model_name_or_path : предварительно обученные контрольные точки для начала. На данный момент мы поддерживаем модели на основе BERT ( bert-base-uncased , bert-large-uncased и т. Д.) и модели на основе Роберты ( RoBERTa-base , RoBERTa-large и т. Д.).--temp : температура для контрастных потерь.--pooler_type : метод объединения. Это то же самое, что и --pooler_type в оценке.--mlp_only_train : Мы обнаружили, что для неконтролируемого Simcse он работает лучше для обучения модели с слоем MLP, но тестируйте модель без нее. Вы должны использовать этот аргумент при обучении неконтролируемых моделей Simcse.--hard_negative_weight : если использование жестких негативов (т.е. в файле обучения есть 3 столбца), это логарифм веса. Например, если вес равен 1, то этот аргумент должен быть установлен как 0 (значение по умолчанию).--do_mlm : использовать ли вспомогательную цель MLM. Если правда:--mlm_weight : вес для объектива MLM.--mlm_probability : скорость маскировки для цели MLM. Все остальные аргументы являются стандартными аргументами transformers . Некоторые из часто используемых аргументов: --output_dir , --learning_rate , --per_device_train_batch_size . В наших примерах сценариев мы также настроились на оценку модели на наборе разработки STS-B (необходимо загрузить набор данных после разделения оценки) и сохранить лучшую контрольную точку.
Для получения результатов в статье мы используем графические процессоры NVIDIA 3090 с CUDA 11. Использование различных типов устройств или различных версий CUDA/других программных материалов может привести к немного различной производительности.
Гиперпараметры
Мы используем следующие Hyperparamters для обучения Simcse:
| Непредвзятый БЕРТ | Непредвзятый Роберта | Как дела. | |
|---|---|---|---|
| Размер партии | 64 | 512 | 512 |
| Скорость обучения (база) | 3e-5 | 1e-5 | 5e-5 |
| Уровень обучения (большой) | 1e-5 | 3e-5 | 1e-5 |
Конвертировать модели
Наши сохраненные контрольно-пропускные пункты немного отличаются от предварительно обученных контрольных точек Huggingface. Запустите python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} , чтобы преобразовать его. После этого вы можете оценить его с помощью нашего кода оценки или напрямую использовать его из коробки.
Если у вас есть какие -либо вопросы, связанные с кодом или статьей, не стесняйтесь написать по электронной почте tianyu ( [email protected] ) и Синченг ( [email protected] ). Если вы сталкиваетесь с какими -либо проблемами при использовании кода или хотите сообщить об ошибке, вы можете открыть проблему. Пожалуйста, попробуйте указать проблему с деталями, чтобы мы могли помочь вам лучше и быстрее!
Пожалуйста, цитируйте нашу бумагу, если вы используете Simcse в своей работе:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}Мы благодарим усилия сообщества по расширению Simcse!
sentence-transformers для Simcse.

