SimCSE
0.4
Ce référentiel contient le code et les modèles pré-formés pour notre papier SIMCSE: apprentissage contrastif simple des incorporations de phrases.
************************** Mises à jour **************************
Nous proposons un cadre d'apprentissage contrastif simple qui fonctionne avec des données non marquées et étiquetées. SimcSe non supervisé prend simplement une phrase d'entrée et se prédit dans un cadre d'apprentissage contrasté, avec seulement un abandon standard utilisé comme bruit. Notre SIMCSE supervisé intègre des paires annotées des ensembles de données NLI dans l'apprentissage contrasté en utilisant des paires entailment comme positifs et paires contradiction comme négatifs durs. La figure suivante est une illustration de nos modèles.
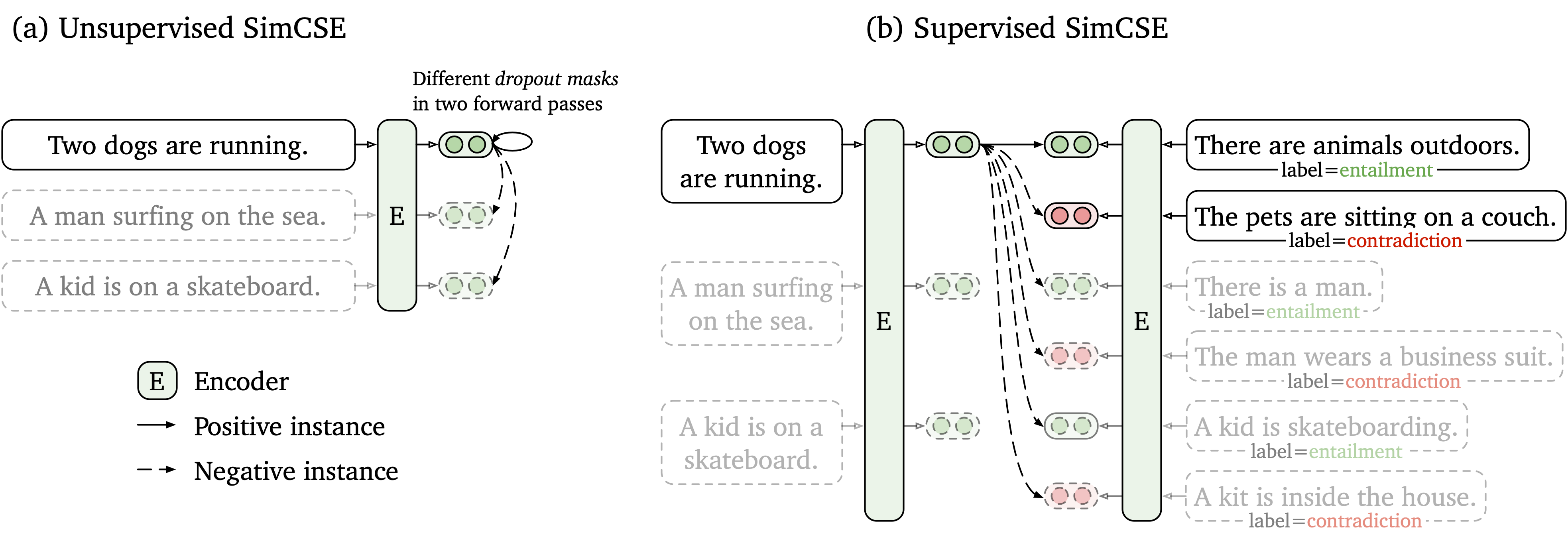
Nous fournissons un outil d'incorporation de phrase facile à utiliser basé sur notre modèle SIMCSE (voir notre wiki pour une utilisation détaillée). Pour utiliser l'outil, installez d'abord le package simcse à partir de PYPI
pip install simcseOu l'installez directement à partir de notre code
python setup.py installNotez que si vous souhaitez activer l'encodage GPU, vous devez installer la version correcte de Pytorch qui prend en charge CUDA. Voir le site officiel de Pytorch pour les instructions.
Après avoir installé le package, vous pouvez charger notre modèle par seulement deux lignes de code
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )Voir la liste des modèles pour une liste complète des modèles disponibles.
Ensuite, vous pouvez utiliser notre modèle pour encoder des phrases dans des intégres
embeddings = model . encode ( "A woman is reading." )Calculez les similitudes cosinus entre deux groupes de phrases
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )Ou construire un index pour un groupe de phrases et une recherche parmi eux
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) Nous soutenons également FAISS, une bibliothèque de recherche de similitudes efficace. Installez simplement le package suivant les instructions ici et simcse utilisera automatiquement faiss pour une recherche efficace.
AVERTISSEMENT : Nous avons constaté que faiss ne soutenait pas bien les GPU nvidia ampère (3090 et A100). Dans ce cas, vous devez passer à d'autres GPU ou installer la version CPU du package faiss .
Nous fournissons également un site Web de démonstration facile à construire pour montrer comment SimcSe peut être utilisé dans la récupération des phrases. Le code est basé sur le référentiel et la démo de DensePhrases (beaucoup de remerciements aux auteurs de DensePhrases).
Nos modèles publiés sont répertoriés comme suit. Vous pouvez importer ces modèles en utilisant le package simcse ou à l'aide de Transformers de HuggingFace.
| Modèle | Avg. STS |
|---|---|
| Princeton-NLP / unpup-simcse-bert-base-basé | 76.25 |
| Princeton-nlp / unpup-simcse-bert-large-incasé | 78.41 |
| Princeton-NLP / Unsup-Simcse-Roberta-base | 76.57 |
| Princeton-NLP / Unsup-simcse-Roberta-Garn | 78,90 |
| Princeton-nlp / sup-simcse-bert-bask | 81.57 |
| Princeton-nlp / sup-simcse-bert-Large-onlenced | 82.21 |
| Princeton-nlp / sup-simcse-robert-bassin | 82,52 |
| Princeton-nlp / sup-simcse-roberta-large | 83,76 |
Notez que les résultats sont légèrement meilleurs que ce que nous avons signalé dans la version actuelle de l'article après avoir adopté un nouvel ensemble d'hyperparamètres (pour les hyperparamtres, voir la section de formation).
Règles de dénomination : unsup et sup représentent respectivement "non supervisé" (formé sur le corpus Wikipedia) et "supervisé" (formé sur les ensembles de données NLI).
En plus d'utiliser notre outil d'incorporation de phrase fourni, vous pouvez également importer facilement nos modèles avec transformers de HuggingFace:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) Si vous rencontrez un problème lorsque vous chargez directement les modèles en étreignant l'API de HuggingFace, vous pouvez également télécharger les modèles manuellement à partir du tableau ci-dessus et utiliser model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) .
Dans la section suivante, nous décrivons comment former un modèle SIMCSE en utilisant notre code.
Tout d'abord, installez Pytorch en suivant les instructions du site officiel. Pour reproduire fidèlement nos résultats, veuillez utiliser la version 1.7.1 correcte correspondant à vos plateformes / versions CUDA. La version Pytorch supérieure à 1.7.1 devrait également fonctionner. Par exemple, si vous utilisez Linux et CUDA11 (comment vérifier la version CUDA), installez Pytorch par la commande suivante,
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html Si vous utilisez plutôt Cuda <11 ou CPU , installez Pytorch par la commande suivante,
pip install torch==1.7.1Ensuite, exécutez le script suivant pour installer les dépendances restantes,
pip install -r requirements.txtNotre code d'évaluation pour les incorporations de phrases est basé sur une version modifiée de Senteval. Il évalue les intérêts des phrases sur les tâches de similitude textuelle sémantique (STS) et les tâches de transfert en aval. Pour les tâches STS, notre évaluation prend le réglage "tout" et signale la corrélation de Spearman. Voir notre article (annexe B) pour les détails de l'évaluation.
Avant l'évaluation, veuillez télécharger les ensembles de données d'évaluation en exécutant
cd SentEval/data/downstream/
bash download_dataset.sh Revenez ensuite au répertoire racine, vous pouvez évaluer tous les modèles pré-entraînés basés sur transformers en utilisant notre code d'évaluation. Par exemple,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode testqui devrait produire les résultats dans un format tabulaire:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
Les arguments pour le script d'évaluation sont les suivants,
--model_name_or_path : le nom ou le chemin d'un point de contrôle prélevé basé sur transformers . Vous pouvez utiliser directement les modèles dans le tableau ci-dessus, par exemple, princeton-nlp/sup-simcse-bert-base-uncased .--pooler : Méthode de mise en commun. Maintenant nous soutenonscls (par défaut): Utilisez la représentation du jeton [CLS] . Une couche d'activation linéaire + est appliquée après la représentation (c'est dans l'implémentation standard de Bert). Si vous utilisez SIMCSE supervisé , vous devez utiliser cette option.cls_before_pooler : Utilisez la représentation du jeton [CLS] sans l'activation linéaire + supplémentaire. Si vous utilisez SIMCSE non supervisé , vous devez prendre cette option.avg : incorporations moyennes de la dernière couche. Si vous utilisez des points de contrôle de SBERT / SROBERTA (papier), vous devez utiliser cette option.avg_top2 : intégres moyens des deux dernières couches.avg_first_last : ENREGISTRATIONS MAINS DES PREMIÈRES ET DERNIERS COMPRESS. Si vous utilisez Vanilla Bert ou Roberta, cela fonctionne le mieux. Notez que dans l'article, nous avons signalé la moyenne de la dernière couche et le mot statique incorporant; Nous avons corrigé cela pour être la dernière et la première moyenne de couche et cela a conduit à de meilleures performances. Voir ce problème pour une discussion détaillée.--mode : mode d'évaluationtest (par défaut): le mode de test par défaut. Pour reproduire fidèlement nos résultats, vous devez utiliser cette option.dev : Signaler les résultats de l'ensemble de développement. Notez que dans les tâches STS, seuls STS-B et SICK-R ont des ensembles de développement, nous ne rapportons donc que leurs chiffres. Il faut également un mode rapide pour les tâches de transfert, donc le temps d'exécution est beaucoup plus court que le mode test (bien que les nombres soient légèrement inférieurs).fasttest : c'est la même chose que test , mais avec un mode rapide, donc le temps d'exécution est beaucoup plus court, mais les nombres signalés peuvent être plus bas (uniquement pour les tâches de transfert).--task_set : quel ensemble de tâches à évaluer sur (si définie, il remplacera --tasks )sts (par défaut): Évaluer les tâches STS, y compris STS 12~16 , STS-B et SICK-R . Il s'agit de l'ensemble de tâches le plus couramment utilisé pour évaluer la qualité des intérêts des phrases.transfer : évaluer les tâches de transfert.full : Évaluez les deux ST et les tâches de transfert.na : régler manuellement les tâches par --tasks .--tasks : Spécifiez quel (s) ensemble de données à évaluer. Sera remplacé si --task_set n'est pas na . Voir le code pour une liste complète des tâches.Données
Pour SIMCSE non supervisé, nous échantillons 1 million de phrases de l'anglais Wikipedia; Pour SIMCSE supervisé, nous utilisons les ensembles de données SNLI et MNLI. Vous pouvez exécuter data/download_wiki.sh et data/download_nli.sh pour télécharger les deux ensembles de données.
Scripts de formation
Nous fournissons des exemples de scripts de formation pour SIMCSE non supervisés et supervisés. Dans run_unsup_example.sh , nous fournissons un exemple unique-GPU (ou CPU) pour la version non supervisée, et dans run_sup_example.sh nous donnons un exemple de gpu multiple pour la version supervisée. Les deux scripts appellent train.py pour la formation. Nous expliquons les arguments en suivant:
--train_file : chemin de fichier de formation. Nous prenons en charge les fichiers "TXT" (une ligne pour une phrase) et les fichiers "CSV" (2 colonnes: paire les données sans négativement; 3 colonnes: paire les données avec une instance négative dure correspondante). Vous pouvez utiliser nos données Wikipedia ou NLI fournies, ou vous pouvez utiliser vos propres données avec le même format.--model_name_or_path : points de contrôle pré-formés pour commencer. Pour l'instant, nous prenons en charge les modèles basés sur Bert ( bert-base-uncased , les modèles bert-large-uncased , etc.) et basés sur Roberta ( RoBERTa-base , RoBERTa-large , etc.).--temp : température pour la perte contrastée.--pooler_type : Méthode de mise en commun. C'est la même chose que le --pooler_type dans la partie d'évaluation.--mlp_only_train : Nous avons constaté que pour SIMCSE non supervisé, il fonctionne mieux pour former le modèle avec la couche MLP mais tester le modèle sans lui. Vous devez utiliser cet argument lors de la formation de modèles SIMCSE non supervisés.--hard_negative_weight : Si vous utilisez des négatifs durs (c'est-à-dire, il y a 3 colonnes dans le fichier de formation), c'est le logarithme du poids. Par exemple, si le poids est 1, cet argument doit être défini comme 0 (valeur par défaut).--do_mlm : Il faut utiliser l'objectif auxiliaire MLM. Si c'est vrai:--mlm_weight : poids pour l'objectif MLM.--mlm_probability : taux de masquage pour l'objectif MLM. Tous les autres arguments sont les arguments de formation des transformers de Huggingface standard. Certains des arguments souvent utilisés sont: --output_dir , --learning_rate , --per_device_train_batch_size . Dans notre exemple de scripts, nous avons également défini pour évaluer le modèle sur l'ensemble de développement STS-B (besoin de télécharger l'ensemble de données suivant la section d'évaluation) et enregistrer le meilleur point de contrôle.
Pour les résultats dans l'article, nous utilisons des GPU NVIDIA 3090 avec CUDA 11. En utilisant différents types d'appareils ou différentes versions de CUDA / d'autres logiciels peut conduire à des performances légèrement différentes.
Hyperparamètres
Nous utilisons les hyperparamters suivants pour la formation SIMCSE:
| Unpup. Bert | Unpup. Roberta | Souper. | |
|---|---|---|---|
| Taille de lot | 64 | 512 | 512 |
| Taux d'apprentissage (base) | 3E-5 | 1E-5 | 5E-5 |
| Taux d'apprentissage (grand) | 1E-5 | 3E-5 | 1E-5 |
Convertir des modèles
Nos points de contrôle enregistrés sont légèrement différents des points de contrôle pré-formés de HuggingFace. Exécutez python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} pour le convertir. Après cela, vous pouvez l'évaluer par notre code d'évaluation ou l'utiliser directement hors de la boîte.
Si vous avez des questions liées au code ou au journal, n'hésitez pas à envoyer un courriel à Tianyu ( [email protected] ) et xingcheng ( [email protected] ). Si vous rencontrez des problèmes lorsque vous utilisez le code ou souhaitez signaler un bogue, vous pouvez ouvrir un problème. Veuillez essayer de spécifier le problème avec les détails afin que nous puissions vous aider mieux et plus rapidement!
Veuillez citer notre article si vous utilisez SIMCSE dans votre travail:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}Nous remercions les efforts de la communauté pour l'extension de SimcSe!
sentence-transformers pour SIMCSE.

