SimCSE
0.4
このリポジトリには、ペーパーSIMCSEのコードと事前に訓練されたモデルが含まれています。文の埋め込みの単純な対照学習。
************************更新************************
非標識データとラベル付きデータの両方で機能する単純な対照学習フレームワークを提案します。監視されていないSimcseは、単に入力文を取得し、対照的な学習フレームワークでそれ自体を予測し、標準ドロップアウトのみがノイズとして使用されます。当社の監視されたSimcseは、 entailmentペアをポジティブとcontradictionペアを硬いネガとして使用することにより、NLIデータセットからの注釈付きペアをコントラスト学習に組み込みます。次の図は、モデルの図です。
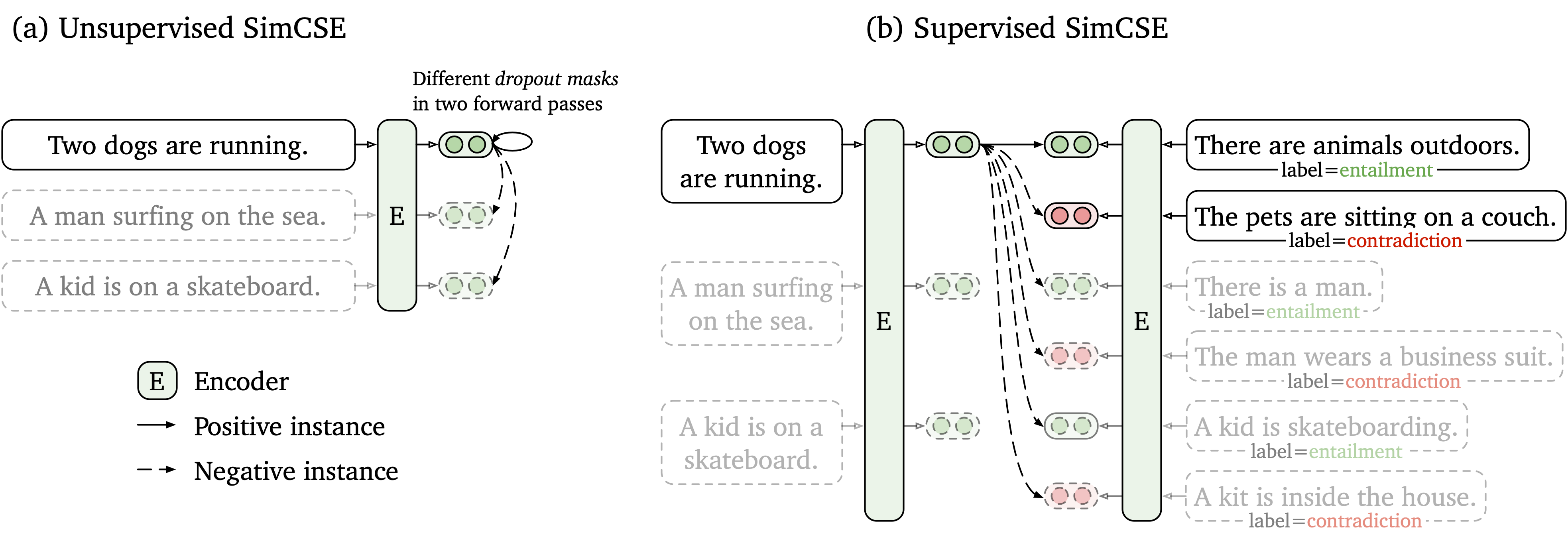
SIMCSEモデルに基づいて使いやすい文の組み込みツールを提供します(詳細な使用については、Wikiを参照してください)。ツールを使用するには、最初にPypiからsimcseパッケージをインストールします
pip install simcseまたは、コードから直接インストールします
python setup.py installGPUエンコードを有効にする場合は、CUDAをサポートするPytorchの正しいバージョンをインストールする必要があることに注意してください。指示については、Pytorchの公式Webサイトを参照してください。
パッケージをインストールした後、モデルを2行のコードでロードできます
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )利用可能なモデルの完全なリストについては、モデルリストを参照してください。
次に、文章をエンボディングにエンコードするためにモデルを使用できます
embeddings = model . encode ( "A woman is reading." )2つの文のグループ間でコサインの類似性を計算します
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )または、文のグループのインデックスを作成し、それらの間で検索する
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." )また、効率的な類似性検索ライブラリであるFaissもサポートしています。ここに次の手順に従ってパッケージをインストールするだけで、 simcse faiss使用して効率的な検索を自動的に使用します。
警告: faiss Nvidia Ampere GPU(3090およびA100)を十分にサポートしていないことがわかりました。その場合、他のGPUに変更するか、 faissパッケージのCPUバージョンをインストールする必要があります。
また、Simcseを文の取得でどのように使用できるかを示すために、簡単に構築できるデモWebサイトも提供しています。このコードは、DensePhrasesのレポとデモに基づいています(濃度の著者に感謝します)。
リリースされたモデルは以下としてリストされています。これらのモデルは、 simcseパッケージを使用するか、Huggingfaceのトランスを使用してインポートできます。
| モデル | 平均。 sts |
|---|---|
| Princeton-NLP/Unsup-Simcse-Bert-Base-Uncased | 76.25 |
| プリンストン-NLP/USUP-SIMCSE-BERTE-LARGE-UNCASED | 78.41 |
| Princeton-NLP/Unsup-Simcse-Roberta-Base | 76.57 |
| プリンストン-NLP/Unsup-Simcse-Roberta-Large | 78.90 |
| Princeton-NLP/Sup-Simcse-Bert-Base-Uncased | 81.57 |
| Princeton-NLP/Sup-Simcse-Bert-Large-Uncased | 82.21 |
| Princeton-NLP/Sup-Simcse-Roberta-Base | 82.52 |
| Princeton-NLP/Sup-Simcse-Roberta-Large | 83.76 |
結果は、ハイパーパラメーターの新しいセットを採用した後、現在のペーパーのバージョンで報告したものよりもわずかに優れていることに注意してください(ハイパーパランターについては、トレーニングセクションを参照)。
命名規則: unsupとsup 、それぞれ「監視なし」(ウィキペディアコーパスで訓練されている)と「監督」(NLIデータセットで訓練された)を表します。
提供された文の埋め込みツールを使用することに加えて、Huggingfaceのtransformersでモデルを簡単にインポートすることもできます。
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) HuggingfaceのAPIでモデルを直接読み込むときに問題が発生した場合、上記のテーブルからモデルを手動でダウンロードして、 model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL})を使用することもできます。
次のセクションでは、コードを使用してSIMCSEモデルをトレーニングする方法について説明します。
まず、公式Webサイトからの指示に従ってPytorchをインストールします。結果を忠実に再現するには、プラットフォーム/CUDAバージョンに対応する正しい1.7.1バージョンを使用してください。 1.7.1を超えるPytorchバージョンも機能するはずです。たとえば、LinuxとCUDA11 (CUDAバージョンの確認方法)を使用する場合は、次のコマンドでPytorchをインストールします。
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html代わりにCUDA <11またはCPUを使用する場合は、次のコマンドでPytorchをインストールします。
pip install torch==1.7.1次に、次のスクリプトを実行して、残りの依存関係をインストールします。
pip install -r requirements.txt文の埋め込みの評価コードは、Sentevalの修正バージョンに基づいています。セマンティックテキストの類似性(STS)タスクとダウンストリーム転送タスクの文の埋め込みを評価します。 STSタスクの場合、私たちの評価は「すべて」の設定を取り、スピアマンの相関を報告します。評価の詳細については、私たちの論文(付録B)を参照してください。
評価の前に、実行して評価データセットをダウンロードしてください
cd SentEval/data/downstream/
bash download_dataset.sh次に、ルートディレクトリに戻って、評価コードを使用してtransformersベースの事前訓練モデルを評価できます。例えば、
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode test結果を表形式で出力すると予想されます。
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
評価スクリプトの引数は次のとおりです。
--model_name_or_path : transformersベースの事前訓練のチェックポイントの名前またはパス。上記の表にモデルを直接使用できます。たとえば、 princeton-nlp/sup-simcse-bert-base-uncased 。--pooler :プーリング方法。今、私たちはサポートしていますcls (デフォルト): [CLS]トークンの表現を使用します。線形+アクティベーション層が表現後に適用されます(標準のBERT実装にあります)。監視されたSIMCSEを使用する場合は、このオプションを使用する必要があります。cls_before_pooler :追加の線形+アクティベーションなしで[CLS]トークンの表現を使用します。監視されていないSimcseを使用する場合は、このオプションを取得する必要があります。avg :最後のレイヤーの平均埋め込み。 Sbert/Sroberta(Paper)のチェックポイントを使用する場合は、このオプションを使用する必要があります。avg_top2 :最後の2つの層の平均埋め込み。avg_first_last :最初と最後のレイヤーの平均埋め込み。 Vanilla BertまたはRobertaを使用する場合、これは最適です。論文では、最後の層の平均と静的単語の埋め込みを報告したことに注意してください。これを最後と最初の層の平均に修正し、パフォーマンスが向上しました。詳細な議論については、この問題を参照してください。--mode :評価モードtest (デフォルト):デフォルトのテストモード。結果を忠実に再現するには、このオプションを使用する必要があります。dev :開発セットの結果を報告します。 STSタスクでは、 STS-BとSICK-Rのみが開発セットを持っているため、数のみを報告することに注意してください。また、転送タスクに高速モードが必要なため、実行時間はtestモードよりもはるかに短くなります(ただし、数字はわずかに低くなります)。fasttest : testと同じですが、高速モードでは実行時間がはるかに短くなりますが、報告された数値は低い場合があります(転送タスクのみ)。--task_set :評価するタスクのセット(設定されている場合、それはオーバーライドします--tasks )sts (デフォルト): STS 12~16 、 STS-B 、 SICK-Rを含むSTSタスクで評価します。これは、文の埋め込みの品質を評価するための最も一般的に使用される一連のタスクです。transfer :転送タスクで評価します。full :両方のSTSと転送タスクで評価します。na : --tasksによってタスクを手動で設定します。--tasks :評価するデータセットを指定します。 --task_set naではない場合、オーバーライドされます。タスクの完全なリストについては、コードを参照してください。データ
監視されていないSimcseについては、英語のウィキペディアから100万文をサンプリングします。監視されたSIMCSEには、SNLIおよびMNLIデータセットを使用します。 data/download_wiki.shとdata/download_nli.shを実行して、2つのデータセットをダウンロードできます。
トレーニングスクリプト
監視されていない監視と監督の両方のSimcseの両方のトレーニングスクリプトを提供します。 run_unsup_example.shでは、監視されていないバージョンのシングルGPU(またはCPU)の例を提供し、 run_sup_example.shでは、監視バージョンの複数GPUの例を示します。両方のスクリプトは、トレーニングのためにtrain.pyを呼び出します。以下で議論を説明します。
--train_file :トレーニングファイルパス。 「TXT」ファイル(1つの文の1行)および「CSV」ファイル(2コラム:ハードネガティブなしのペアデータ、3コラム:対応するハードネガティブインスタンスのペアデータ)をサポートします。提供されたWikipediaまたはNLIデータを使用することも、同じ形式で独自のデータを使用することもできます。--model_name_or_path :開始する事前に訓練されたチェックポイント。今のところ、Bertベースのモデル( bert-base-uncased 、 bert-large-uncasedなど)およびRobertaベースのモデル( RoBERTa-base 、 RoBERTa-largeなど)をサポートしています。--temp :対照的な損失の温度。--pooler_type :プーリング方法。評価部分の--pooler_typeと同じです。--mlp_only_train :監視されていないSIMCSEの場合、MLPレイヤーでモデルをトレーニングしますが、それなしでモデルをテストする方が適切に機能することがわかりました。監視されていないSIMCSEモデルをトレーニングするときは、この引数を使用する必要があります。--hard_negative_weight :ハードネガを使用している場合(つまり、トレーニングファイルに3つの列があります)、これは重みの対数です。たとえば、重みが1の場合、この引数は0(デフォルト値)として設定する必要があります。--do_mlm :MLM補助目標を使用するかどうか。真実の場合:--mlm_weight :MLM目標の重量。--mlm_probability :MLM目標のマスキングレート。他のすべての議論は、標準的なハギングフェイスのtransformersトレーニングの議論です。よく使用されている引数のいくつかは次のとおりです。 --output_dir 、 --learning_rate 、 --per_device_train_batch_size 。また、サンプルスクリプトでは、STS-B開発セットのモデルを評価し(評価セクションに従ってデータセットをダウンロードする必要があります)、最適なチェックポイントを保存するように設定します。
論文の結果については、CUDA 11を使用したNVIDIA 3090 GPUを使用します。さまざまな種類のデバイスまたはCUDA/その他のソフトウェアの異なるバージョンを使用すると、パフォーマンスがわずかに異なる場合があります。
ハイパーパラメーター
SIMCSEのトレーニングには、次のハイパーパランターを使用します。
| 出てくる。バート | 出てくる。ロベルタ | すする。 | |
|---|---|---|---|
| バッチサイズ | 64 | 512 | 512 |
| 学習率(ベース) | 3E-5 | 1E-5 | 5E-5 |
| 学習率(大) | 1E-5 | 3E-5 | 1E-5 |
モデルを変換します
保存されたチェックポイントは、Huggingfaceの事前に訓練されたチェックポイントとはわずかに異なります。 python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER}を実行して変換します。その後、評価コードで評価するか、箱から出して直接使用できます。
コードまたは論文に関連する質問がある場合は、Tianyu( [email protected] )とxingcheng( [email protected] )にメールを送信してください。コードを使用するときに問題が発生した場合、またはバグを報告する場合は、問題を開くことができます。私たちがあなたをより良く、より迅速に助けることができるように、詳細とともに問題を指定してみてください!
あなたの仕事でSimcseを使用している場合は、私たちの論文を引用してください:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}Simcseを拡大してくれたコミュニティの努力に感謝します!
sentence-transformersにベースのトレーニングコードを実装しました。

