SimCSE
0.4
Este repositório contém o código e os modelos pré-treinados para o nosso artigo SIMCSE: aprendizado simples contrastivo de incorporações de sentença.
**************************** Atualizações ***************************
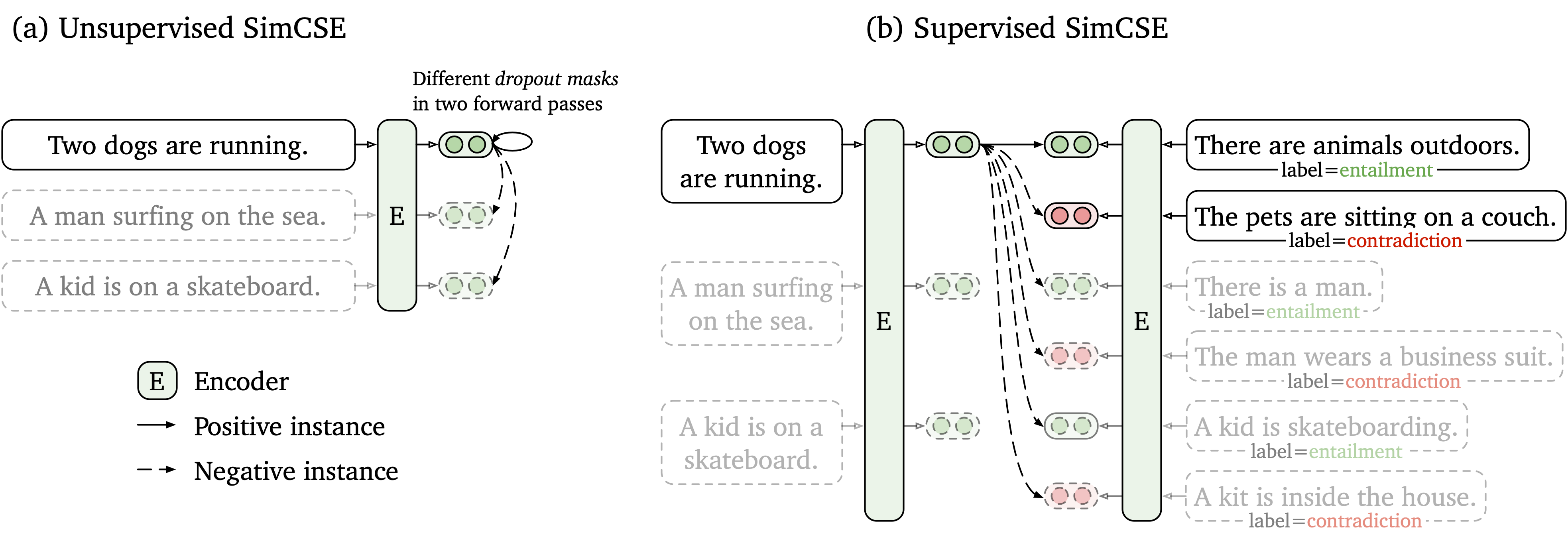
Propomos uma estrutura de aprendizado contrastiva simples que funcione com dados não marcados e rotulados. O SIMCSE não supervisionado simplesmente pega uma frase de entrada e se prevê em uma estrutura de aprendizado contrastante, com apenas o abandono padrão usado como ruído. Nosso SIMCSE supervisionado incorpora pares anotados dos conjuntos de dados da NLI em aprendizado contrastante usando pares entailment como pares positivos e contradiction como negativos difíceis. A figura a seguir é uma ilustração de nossos modelos.
Fornecemos uma ferramenta de incorporação de sentença fácil de usar com base em nosso modelo SIMCSE (consulte nosso wiki para uso detalhado). Para usar a ferramenta, primeiro instale o pacote simcse da Pypi
pip install simcseOu instale -o diretamente do nosso código
python setup.py installObserve que, se você deseja ativar a codificação da GPU, instale a versão correta do Pytorch que suporta CUDA. Consulte o site oficial da Pytorch para obter instruções.
Depois de instalar o pacote, você pode carregar nosso modelo por apenas duas linhas de código
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )Consulte a lista de modelos para uma lista completa dos modelos disponíveis.
Então você pode usar nosso modelo para codificar frases em incorporação
embeddings = model . encode ( "A woman is reading." )Calcule as semelhanças de cosseno entre dois grupos de frases
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )Ou construir índice para um grupo de frases e pesquisar entre eles
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) Também apoiamos o FAISS, uma biblioteca de pesquisa de similaridade eficiente. Basta instalar o pacote seguindo as instruções aqui e simcse usará automaticamente faiss para pesquisa eficiente.
AVISO : Descobrimos que faiss não apoiava muito bem a NVIDIA Ampere GPUs (3090 e A100). Nesse caso, você deve mudar para outras GPUs ou instalar a versão da CPU do pacote faiss .
Também fornecemos um site de demonstração fácil de construir para mostrar como o SIMCSE pode ser usado na recuperação de frases. O código é baseado no repo e na demonstração de Densefrases (muito agradecimento aos autores de densefrases).
Nossos modelos lançados estão listados como seguintes. Você pode importar esses modelos usando o pacote simcse ou usando Transformers do HuggingFace.
| Modelo | Avg. Sts |
|---|---|
| Princeton-NLP/UNSUP-SIMCSE-BERT-BASE-ACED | 76.25 |
| Princeton-NLP/UNSUP-SIMCSE-BERT-LARGE-ACED | 78.41 |
| Princeton-NLP/UNSUP-SIMCSE-ROBERTA-BASE | 76.57 |
| Princeton-NLP/UNSUP-SIMCSE-ROBERTA-LARGE | 78.90 |
| Princeton-NLP/Sup-Simcse-Bert-Base-Base | 81.57 |
| Princeton-NLP/Sup-Simcse-Bert-Large-Baseado | 82.21 |
| Princeton-NLP/Sup-Simcse-Roberta-Base | 82.52 |
| Princeton-NLP/Sup-Simcse-Roberta-Large | 83.76 |
Observe que os resultados são um pouco melhores do que o que relatamos na versão atual do artigo após a adoção de um novo conjunto de hiperparâmetro (para hiperparamters, consulte a seção de treinamento).
As regras de nomeação : unsup e sup representam "sem supervisão" (treinado no Wikipedia corpus) e "supervisionado" (treinado em conjuntos de dados NLI), respectivamente.
Além de usar nossa ferramenta de incorporação de sentença fornecida, você também pode importar facilmente nossos modelos com transformers da Huggingface:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) Se você encontrar algum problema ao carregar diretamente os modelos pela API do HuggingFace, também poderá baixar os modelos manualmente na tabela acima e usar model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) .
Na seção a seguir, descrevemos como treinar um modelo SIMCSE usando nosso código.
Primeiro, instale o Pytorch seguindo as instruções do site oficial. Para reproduzir fielmente nossos resultados, use a versão correta 1.7.1 correspondente às suas plataformas/versões CUDA. A versão pytorch superior a 1.7.1 também deve funcionar. Por exemplo, se você usar Linux e Cuda11 (como verificar a versão CUDA), instale o Pytorch pelo seguinte comando,
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html Se você usar CUDA <11 ou CPU , instale o Pytorch pelo seguinte comando,
pip install torch==1.7.1Em seguida, execute o script a seguir para instalar as dependências restantes,
pip install -r requirements.txtNosso código de avaliação para incorporação de sentença é baseado em uma versão modificada do SRENEVAL. Ele avalia incorporações de sentença em tarefas de similaridade textual semântica (STS) e tarefas de transferência a jusante. Para tarefas do STS, nossa avaliação leva a configuração "All" e relata a correlação de Spearman. Consulte nosso artigo (Apêndice B) para obter detalhes da avaliação.
Antes da avaliação, faça o download dos conjuntos de dados de avaliação executando
cd SentEval/data/downstream/
bash download_dataset.sh Em seguida, volte ao diretório raiz, você pode avaliar os modelos pré -treinados baseados em transformers usando nosso código de avaliação. Por exemplo,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode testque deve gerar os resultados em um formato tabular:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
Os argumentos para o script de avaliação são os seguintes,
--model_name_or_path : o nome ou caminho de um ponto de verificação pré-treinado baseado em transformers . Você pode usar diretamente os modelos na tabela acima, por exemplo, princeton-nlp/sup-simcse-bert-base-uncased .--pooler : método de agrupamento. Agora apoiamoscls (padrão): use a representação do token [CLS] . Uma camada de ativação linear+é aplicada após a representação (está na implementação padrão do BERT). Se você usar o SIMCSE supervisionado , use esta opção.cls_before_pooler : Use a representação do token [CLS] sem a ativação linear+extra. Se você usar o SIMCSE não supervisionado , deve tomar essa opção.avg : incorporações médias da última camada. Se você usar pontos de verificação de sbert/sroberta (papel), você deve usar esta opção.avg_top2 : incorporações médias das duas últimas camadas.avg_first_last : incorporações médias das primeiras e últimas camadas. Se você usar a baunilha Bert ou Roberta, isso funciona melhor. Observe que no artigo relatamos a média da última camada e a palavra estática incorporando; Corrigimos isso como a última e a média da primeira camada e levou a um melhor desempenho. Veja esta questão para uma discussão detalhada.--mode : modo de avaliaçãotest (padrão): o modo de teste padrão. Para reproduzir fielmente nossos resultados, você deve usar esta opção.dev : relate os resultados do conjunto de desenvolvimento. Observe que, nas tarefas do STS, apenas STS-B e SICK-R têm conjuntos de desenvolvimento, por isso apenas relatamos seus números. Também é necessário um modo rápido para tarefas de transferência; portanto, o tempo de execução é muito mais curto que o modo test (embora os números sejam um pouco mais baixos).fasttest : é o mesmo que test , mas com um modo rápido, de modo que o tempo de execução é muito mais curto, mas os números relatados podem ser mais baixos (apenas para tarefas de transferência).--task_set : Em que conjunto de tarefas a avaliar (se definido, ele substituirá --tasks )sts (padrão): Avalie as tarefas do STS, incluindo STS 12~16 , STS-B e SICK-R . Este é o conjunto de tarefas mais comumente usado para avaliar a qualidade das incorporações de sentença.transfer : Avalie as tarefas de transferência.full : Avalie as Tases do STS e transfira.na : Defina manualmente tarefas --tasks .--tasks : especifique em quais conjuntos de dados avaliarem. Será substituído se --task_set não for na . Consulte o código para obter uma lista completa de tarefas.Dados
Para o Simcse não supervisionado, provamos 1 milhão de frases da Wikipedia inglesa; Para o SIMCSE supervisionado, usamos os conjuntos de dados SNLI e MNLI. Você pode executar data/download_wiki.sh e data/download_nli.sh para baixar os dois conjuntos de dados.
Scripts de treinamento
Fornecemos exemplos de scripts de treinamento para Simcse não supervisionado e supervisionado. Em run_unsup_example.sh , fornecemos um exemplo de GPU único (ou CPU) para a versão não supervisionada e, em run_sup_example.sh fornecemos um exemplo de GPU múltiplo para a versão supervisionada. Ambos os scripts chamam train.py para treinamento. Nós explicamos os argumentos seguintes:
--train_file : Caminho do arquivo de treinamento. Suportamos arquivos "txt" (uma linha para uma frase) e arquivos "CSV" (2 colunas: dados pares sem negativo duro; 3 colunas: pares de dados com uma instância negativa dura correspondente). Você pode usar nossos dados da Wikipedia ou NLI fornecidos ou pode usar seus próprios dados com o mesmo formato.--model_name_or_path : pontos de verificação pré-treinados para começar. Por enquanto, apoiamos os modelos baseados em Bert (modelos baseados bert-base-uncased , bert-large-uncased , etc.) e Roberta ( RoBERTa-base , RoBERTa-large , etc.).--temp : Temperatura para a perda contrastiva.--pooler_type : método de pool. É o mesmo que o --pooler_type na parte de avaliação.--mlp_only_train : Descobrimos que, para o SIMCSE não supervisionado, funciona melhor treinar o modelo com a camada MLP, mas testar o modelo sem ele. Você deve usar esse argumento ao treinar modelos SIMCSE não supervisionados.--hard_negative_weight : Se estiver usando negativos fortes (ou seja, existem 3 colunas no arquivo de treinamento), este é o logaritmo do peso. Por exemplo, se o peso for 1, esse argumento deve ser definido como 0 (valor padrão).--do_mlm : se deve usar o objetivo auxiliar MLM. Se for verdade:--mlm_weight : peso para o objetivo MLM.--mlm_probability : taxa de mascaramento para o objetivo MLM. Todos os outros argumentos são os argumentos de treinamento transformers do Huggingface padrão. Alguns dos argumentos frequentemente usados são: --output_dir , --learning_rate , --per_device_train_batch_size . Em nossos scripts de exemplo, também configuramos para avaliar o modelo no conjunto de desenvolvimento STS-B (precisamos baixar o conjunto de dados após a seção de avaliação) e salvar o melhor ponto de verificação.
Para obter resultados no artigo, usamos o NVIDIA 3090 GPUS com CUDA 11. O uso de diferentes tipos de dispositivos ou versões diferentes de CUDA/outros softwares pode levar a um desempenho ligeiramente diferente.
Hyperparameters
Usamos os seguintes hiperparamters para treinar Simcse:
| Upspup. Bert | Upspup. Roberta | E aí. | |
|---|---|---|---|
| Tamanho do lote | 64 | 512 | 512 |
| Taxa de aprendizado (base) | 3E-5 | 1e-5 | 5E-5 |
| Taxa de aprendizado (grande) | 1e-5 | 3E-5 | 1e-5 |
Converter modelos
Nossos pontos de verificação salvos são ligeiramente diferentes dos pontos de verificação pré-treinados do HuggingFace. Execute python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} para convertê -lo. Depois disso, você pode avaliá -lo por nosso código de avaliação ou usá -lo diretamente fora da caixa.
Se você tiver alguma dúvida relacionada ao código ou ao artigo, sinta -se à vontade para enviar um e -mail para Tianyu ( [email protected] ) e xingcheng ( [email protected] ). Se você encontrar algum problema ao usar o código ou deseja relatar um bug, poderá abrir um problema. Tente especificar o problema com detalhes para que possamos ajudá -lo melhor e mais rápido!
Cite nosso artigo se você usar o SIMCSE em seu trabalho:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}Agradecemos aos esforços da comunidade por estender o Simcse!
sentence-transformers para SIMCSE.

