SimCSE
0.4
Dieses Repository enthält den Code und die vorgeschriebenen Modelle für unser Papier-Simcse: Einfach kontrastives Lernen von Satzeinbettungen.
********************************
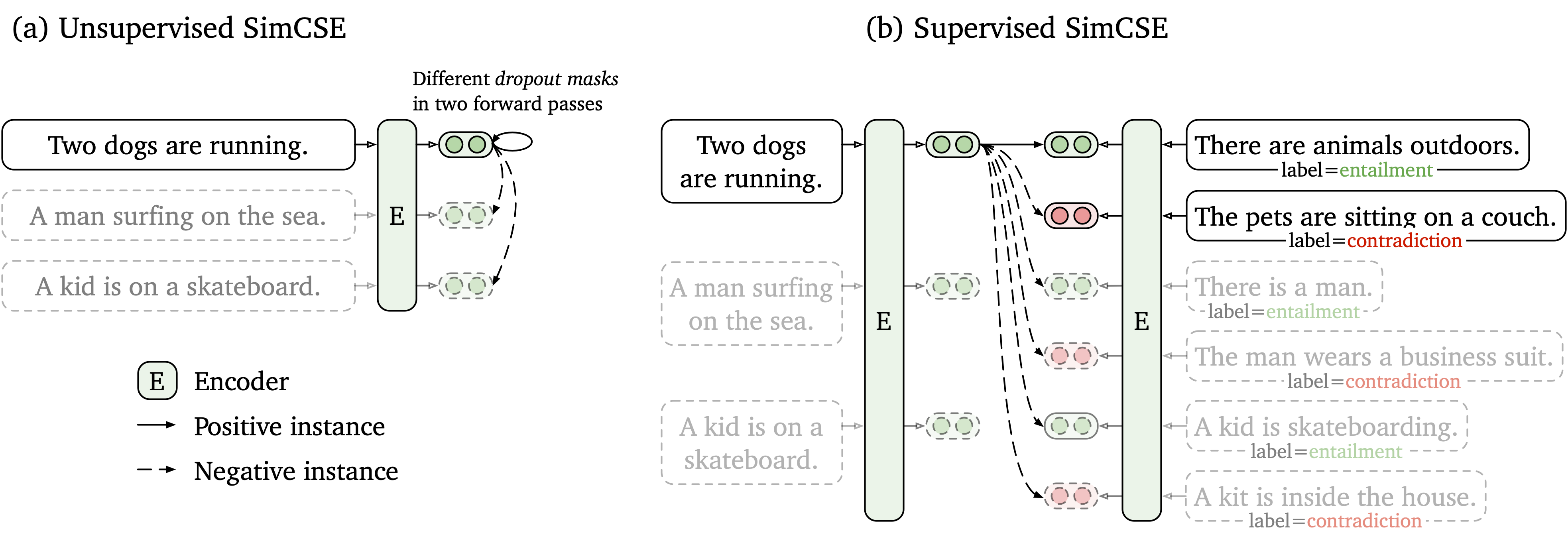
Wir schlagen einen einfachen kontrastiven Lernrahmen vor, der sowohl mit nicht markierten als auch mit beschrifteten Daten funktioniert. Unüberwachter Simcse nimmt einfach einen Eingabersatz an und prognostiziert sich in einem kontrastiven Lerngerüst, wobei nur Standard -Tropfen als Rauschen verwendet werden. Unsere beaufsichtigte SIMCSE enthält annotierte Paare von NLI -Datensätzen in kontrastives Lernen, indem sie mit entailment als positive und contradiction als harte Negative verwendet werden. Die folgende Abbildung ist eine Darstellung unserer Modelle.
Wir bieten ein benutzerfreundliches Satz-Einbettungs-Tool an, das auf unserem SIMCSE-Modell basiert (siehe Wiki für detaillierte Verwendung). Um das Tool zu verwenden, installieren Sie zuerst das simcse -Paket von PYPI von PYPI
pip install simcseOder installieren Sie es direkt aus unserem Code
python setup.py installBeachten Sie, dass Sie die richtige Version von Pytorch installieren sollten, die CUDA unterstützt, wenn Sie die GPU -Codierung aktivieren möchten. Anweisungen finden Sie unter der offiziellen Pytorch -Website.
Nach dem Installieren des Pakets können Sie unser Modell nur um zwei Codezeilen laden
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )Eine vollständige Liste der verfügbaren Modelle finden Sie in der Modellliste.
Dann können Sie unser Modell verwenden, um Sätze in Einbettungen zu kodieren
embeddings = model . encode ( "A woman is reading." )Berechnen Sie die Ähnlichkeiten der Cosinus zwischen zwei Gruppen von Sätzen
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )Oder Index für eine Gruppe von Sätzen erstellen und unter ihnen suchen
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) Wir unterstützen auch Faiss, eine effiziente Suchbibliothek der Ähnlichkeit. Installieren Sie einfach das Paket für die folgenden Anweisungen hier, und simcse verwendet faiss automatisch für eine effiziente Suche.
Warnung : Wir haben festgestellt, dass faiss den Nvidia -Ampere -GPUs (3090 und A100) nicht gut unterstützt hat. In diesem Fall sollten Sie an andere GPUs wechseln oder die CPU -Version des faiss -Pakets installieren.
Wir bieten auch eine einfach zu bauende Demo-Website, um zu zeigen, wie Simcse im Satzabruf verwendet werden kann. Der Code basiert auf dem Repo und der Demo von Denphrasen (dank der Autoren von Denphrasen).
Unsere veröffentlichten Modelle sind wie folgt aufgeführt. Sie können diese Modelle mithilfe des simcse -Pakets oder mithilfe des Transformers von Huggingface importieren.
| Modell | Avg. Sts |
|---|---|
| Princeton-NLP/UNSUP-SIMCSE-BERT-BASE-OCKUDED | 76,25 |
| Princeton-NLP/UNSUP-SIMCSE-BERT-LARGE-OKUDED | 78,41 |
| Princeton-NLP/UNSUP-SIMCSE-Roberta-Base | 76,57 |
| Princeton-NLP/UNSUP-SIMCSE-ROBERTA-LARGE | 78,90 |
| Princeton-NLP/Sup-Simcse-Bert-Base-Unbekannter | 81.57 |
| Princeton-NLP/Sup-Simcse-Bert-Large-Ocnased | 82.21 |
| Princeton-NLP/Sup-Simcse-Roberta-Base | 82,52 |
| Princeton-NLP/Sup-Simcse-Roberta-Large | 83.76 |
Beachten Sie, dass die Ergebnisse etwas besser sind als das, was wir in der aktuellen Version des Papiers gemeldet haben, nachdem sie einen neuen Satz von Hyperparametern angenommen haben (für Hyperparamter siehe Abschnitt Training).
Benennungsregeln : unsup und sup stellen "unbeaufsichtigt" (auf Wikipedia Corpus ausgebildet) und "beaufsichtigt" (auf NLI -Datensätze ausgebildet) dar.
Neben unserem bereitgestellten Satzeinbettungswerkzeug können Sie unsere Modelle auch mit transformers von Huggingface problemlos importieren:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) Wenn Sie auf ein Problem stoßen, wenn Sie die Modelle direkt durch die API von SuggingFace laden, können Sie die Modelle auch manuell aus der obigen Tabelle herunterladen und model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) verwenden.
Im folgenden Abschnitt beschreiben wir, wie ein SIMCSE -Modell mit unserem Code trainiert wird.
Installieren Sie zunächst Pytorch, indem Sie die Anweisungen von der offiziellen Website befolgen. Um unsere Ergebnisse treu zu reproduzieren, verwenden Sie bitte die richtige Version 1.7.1 die Ihren Plattformen/CUDA -Versionen entspricht. Die Pytorch -Version über 1.7.1 sollte ebenfalls funktionieren. Wenn Sie beispielsweise Linux und CUDA11 verwenden (So überprüfen Sie die CUDA -Version), installieren Sie Pytorch mit dem folgenden Befehl.
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html Wenn Sie stattdessen CUDA <11 oder CPU verwenden, installieren Sie Pytorch mit dem folgenden Befehl.
pip install torch==1.7.1Führen Sie dann das folgende Skript aus, um die verbleibenden Abhängigkeiten zu installieren.
pip install -r requirements.txtUnser Evaluierungscode für Satzeinbettungen basiert auf einer geänderten Version von Sental. Es bewertet Satzeinbettungen zu Semantic Textual Eyeficity (STS) -Tasks und nachgeschaltete Übertragungsaufgaben. Bei STS -Aufgaben übernimmt unsere Bewertung die "All" -Einstellung und meldet die Korrelation von Spearman. Bewertungsdetails finden Sie in unserem Artikel (Anhang B).
Bitte laden Sie vor der Bewertung die Bewertungsdatensätze durch Ausführen herunter
cd SentEval/data/downstream/
bash download_dataset.sh Kommen Sie dann zum Stammverzeichnis zurück, Sie können alle vorhandenen transformers -Basis -Modelle mit unserem Bewertungscode bewerten. Zum Beispiel,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode testDies wird erwartet, dass die Ergebnisse in einem tabellarischen Format ausgegeben werden:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
Argumente für das Bewertungsskript sind wie folgt.
--model_name_or_path : Der Name oder Pfad eines vorgebildeten Checkpoint mit transformers . Sie können die Modelle in der obigen Tabelle direkt verwenden, z princeton-nlp/sup-simcse-bert-base-uncased--pooler : Pooling-Methode. Jetzt unterstützen wircls (Standard): Verwenden Sie die Darstellung von [CLS] Token. Eine lineare+Aktivierungsschicht wird nach der Darstellung angewendet (sie befindet sich in der Standard -Bert -Implementierung). Wenn Sie beaufsichtigte SIMCSE verwenden, sollten Sie diese Option verwenden.cls_before_pooler : Verwenden Sie die Darstellung von [CLS] -Token ohne zusätzliche lineare+Aktivierung. Wenn Sie unbeaufsichtigte SIMCSE verwenden, sollten Sie diese Option übernehmen.avg : Durchschnittliche Einbettungen der letzten Schicht. Wenn Sie Kontrollpunkte von Sbert/Sroberta (Papier) verwenden, sollten Sie diese Option verwenden.avg_top2 : Durchschnittliche Einbettungen der letzten beiden Schichten.avg_first_last : Durchschnittliche Einbettungen der ersten und letzten Schichten. Wenn Sie Vanilla Bert oder Roberta verwenden, funktioniert dies am besten. Beachten Sie, dass wir in der Arbeit den Durchschnitt der letzten Schicht und der statischen Worteinbettung gemeldet haben; Wir haben dies als letztes und erster Schicht durchschnittlich behoben und es führte zu einer besseren Leistung. In dieser Ausgabe finden Sie eine detaillierte Diskussion.--mode : Bewertungsmodustest (Standard): Der Standard -Testmodus. Um unsere Ergebnisse treu zu reproduzieren, sollten Sie diese Option verwenden.dev : Melden Sie die Entwicklungsset -Ergebnisse. Beachten Sie, dass bei STS-Aufgaben nur STS-B und SICK-R Entwicklungssätze haben, sodass wir nur ihre Zahlen melden. Es dauert auch einen schnellen Modus für Übertragungsaufgaben, sodass die Laufzeit viel kürzer ist als der test (obwohl die Zahlen etwas niedriger sind).fasttest : Es ist das gleiche wie test , aber mit einem schnellen Modus, sodass die Laufzeit viel kürzer ist, aber die gemeldeten Zahlen sind möglicherweise niedriger (nur für Übertragungsaufgaben).--task_set : Auf welchen Aufgaben können Sie bewertet werden (falls festgelegt wird es überschreiben --tasks ))sts (Standard): Bewerten Sie STS-Aufgaben, einschließlich STS 12~16 , STS-B und SICK-R . Dies ist die am häufigsten verwendete Aufgaben, um die Qualität der Satz Einbettungen zu bewerten.transfer : Bewerten Sie bei Übertragungsaufgaben.full : Bewerten Sie sowohl STS- als auch Übertragungsaufgaben.na : Manuell Aufgaben nach --tasks .--tasks : Geben Sie an, auf welchen Datensatz (en) bewertet werden sollen. Wird überschrieben, wenn --task_set nicht na ist. Eine vollständige Liste von Aufgaben finden Sie im Code.Daten
Für unbeaufsichtigte SIMCSE probieren wir 1 Million Sätze aus englischen Wikipedia; Für überwachte SIMCSE verwenden wir die SNLI- und MNLI -Datensätze. Sie können data/download_wiki.sh und data/download_nli.sh ausführen, um die beiden Datensätze herunterzuladen.
Trainingsskripte
Wir bieten Beispiel -Schulungsskripte für unbeaufsichtigte und überwachte SIMCSE. In run_unsup_example.sh geben wir ein Beispiel für die unbeaufsichtigte Version für die unbeaufsichtigte Version und in run_sup_example.sh . Beide Skripte rufen train.py für das Training an. Wir erklären die Argumente in Follow:
--train_file : Trainingsdateipfad. Wir unterstützen "TXT" -Dateien (eine Zeile für einen Satz) und "CSV" -Dateien (2-Spalte: Paardaten ohne harte Negative; 3-Spalte: Paardaten mit einer entsprechenden harten negativen Instanz). Sie können unsere bereitgestellten Wikipedia- oder NLI -Daten verwenden oder Ihre eigenen Daten mit demselben Format verwenden.--model_name_or_path : Vorausgebildete Checkpoints zu Beginn. Im Moment unterstützen wir mit Bert-basierte Modelle ( bert-base-uncased , bert-large-uncased -usw.) und Roberta-basierte Modelle ( RoBERTa-base , RoBERTa-large usw.).--temp : Temperatur für den kontrastiven Verlust.--pooler_type : Pooling-Methode. Es ist dasselbe wie der --pooler_type im Bewertungsteil.--mlp_only_train : Wir haben festgestellt, dass es für unbeaufsichtigte SIMCSE besser funktioniert, das Modell mit MLP-Schicht zu trainieren, aber das Modell ohne es testen. Sie sollten dieses Argument verwenden, wenn Sie unbeaufsichtigte SIMCSE -Modelle trainieren.--hard_negative_weight : Wenn Sie harte Negative verwenden (dh in der Trainingsdatei befinden sich 3 Spalten), ist dies der Logarithmus des Gewichts. Wenn das Gewicht beispielsweise 1 ist, sollte dieses Argument als 0 festgelegt werden (Standardwert).--do_mlm : Ob das MLM-Hilfsziel verwendet wird. Wenn wahr:--mlm_weight : Gewicht für das MLM-Ziel.--mlm_probability : Maskierungsrate für das MLM-Ziel. Alle anderen Argumente sind transformers -Trainingsargumente von Standard -Huggingface. Einige der häufig verwendeten Argumente sind: --output_dir , --learning_rate , --per_device_train_batch_size . In unseren Beispielskripten haben wir auch festgelegt, dass das Modell auf dem STS-B-Entwicklungssatz bewertet wird (müssen den Datensatz nach dem Bewertungsabschnitt herunterladen und den besten Kontrollpunkt speichern.
Für die Ergebnisse des Papiers verwenden wir NVIDIA 3090 GPUs mit CUDA 11. Verwenden verschiedener Arten von Geräten oder verschiedenen Versionen von CUDA/anderen Software können zu einer leicht unterschiedlichen Leistung führen.
Hyperparameter
Wir verwenden die folgenden Hyperparamter für das Trainings -SIMCSE:
| UNSUSP. Bert | UNSUSP. Roberta | Sup. | |
|---|---|---|---|
| Chargengröße | 64 | 512 | 512 |
| Lernrate (Basis) | 3e-5 | 1e-5 | 5e-5 |
| Lernrate (groß) | 1e-5 | 3e-5 | 1e-5 |
Modelle konvertieren
Unsere gespeicherten Kontrollpunkte unterscheiden sich geringfügig von den vorgeborenen Checkpoints von Huggingface. Führen Sie python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} aus, um es zu konvertieren. Danach können Sie es nach unserem Bewertungscode bewerten oder ihn direkt über die Box verwenden.
Wenn Sie Fragen zu dem Code oder dem Papier haben, können Sie Tianyu ( [email protected] ) und Xingcheng ( [email protected] ) per E -Mail senden. Wenn Sie bei der Verwendung des Code auf Probleme stoßen oder einen Fehler melden möchten, können Sie ein Problem öffnen. Bitte versuchen Sie, das Problem mit Details anzugeben, damit wir Ihnen besser und schneller helfen können!
Bitte zitieren Sie unser Papier, wenn Sie SIMCSE in Ihrer Arbeit verwenden:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}Wir danken den Bemühungen der Community, Simcse zu erweitern!
sentence-transformers implementiert.

