SimCSE
0.4
이 저장소에는 논문 Simcse의 코드 및 미리 훈련 된 모델이 포함되어 있습니다 : 문장 임베드에 대한 간단한 대조 학습.
******************************** 업데이트 **********************
우리는 표지되지 않은 데이터와 레이블이 지정된 데이터와 함께 작동하는 간단한 대조 학습 프레임 워크를 제안합니다. 감독되지 않은 SIMCSE는 단순히 입력 문장을 취하고 대조적 인 학습 프레임 워크에서 스스로를 예측하며 표준 드롭 아웃 만 노이즈로 사용합니다. 우리의 감독 된 SIMCSE는 NLI 데이터 세트의 주석이 달린 쌍을 entailment 쌍으로 사용하여 긍정적 및 contradiction 쌍을 단단한 네거티브로 사용하여 대조적 인 학습으로 통합합니다. 다음 그림은 우리 모델의 그림입니다.
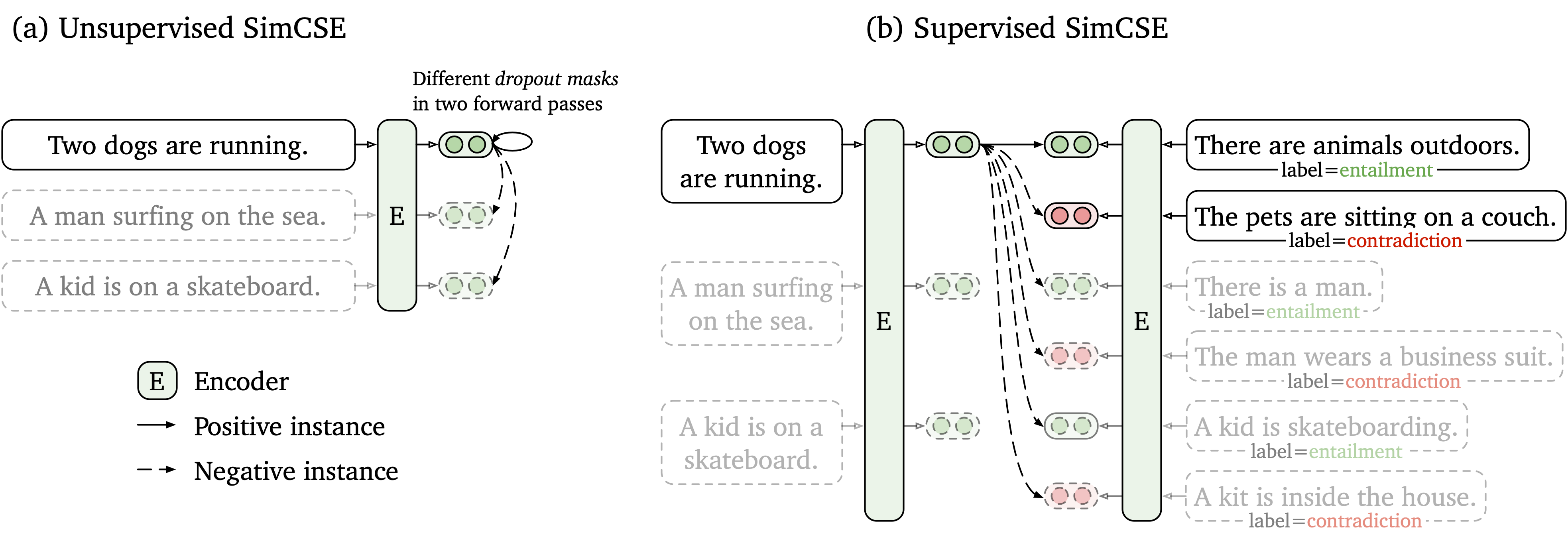
우리는 SIMCSE 모델을 기반으로 사용하기 쉬운 문장 임베딩 도구를 제공합니다 (자세한 사용은 Wiki 참조). 도구를 사용하려면 먼저 PYPI에서 simcse 패키지를 설치하십시오.
pip install simcse또는 코드에서 직접 설치하십시오
python setup.py installGPU 인코딩을 활성화하려면 CUDA를 지원하는 올바른 Pytorch 버전을 설치해야합니다. 지침은 Pytorch 공식 웹 사이트를 참조하십시오.
패키지를 설치 한 후 두 줄의 코드로 모델을로드 할 수 있습니다.
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )사용 가능한 모델의 전체 목록은 모델 목록을 참조하십시오.
그러면 우리의 모델을 사용하여 문장을 내장으로 인코딩 할 수 있습니다.
embeddings = model . encode ( "A woman is reading." )두 문장 그룹 사이의 코사인 유사성을 계산합니다
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )또는 문장 그룹에 대한 색인을 구축하고 그 중에서 검색하십시오 .
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) 또한 효율적인 유사성 검색 라이브러리 인 Faiss도 지원합니다. 여기에 패키지를 설치하면 여기에 다음 지침을 설치하면 simcse 자동으로 faiss 사용하여 효율적으로 검색합니다.
경고 : 우리는 faiss Nvidia Ampere GPU (3090 및 A100)를 잘 지원하지 않았다는 것을 발견했습니다. 이 경우 다른 GPU로 변경하거나 CPU 버전의 faiss 패키지를 설치해야합니다.
또한 건축하기 쉬운 데모 웹 사이트를 제공하여 Simcse가 문장 검색에서 어떻게 사용되는지 보여줍니다. 이 코드는 DensePhrases 'Repo and Demo (DensePhrases의 저자들에게 많은 감사)를 기반으로합니다.
출시 된 모델은 다음으로 나열됩니다. simcse 패키지를 사용하거나 Huggingface의 변압기를 사용하여 이러한 모델을 가져올 수 있습니다.
| 모델 | avg. STS |
|---|---|
| Princeton-NLP/Unsup-Simcse-Bert-Base-incased | 76.25 |
| Princeton-NLP/Unsup-SIMCSE-BERT-LARGE-ANCESIVES | 78.41 |
| Princeton-NLP/Unsup-Simcse-Roberta-Base | 76.57 |
| Princeton-NLP/Unsup-Simcse-Roberta-Large | 78.90 |
| Princeton-NLP/SUP-SIMCSE-BERT-BASE-ANCESIVES | 81.57 |
| Princeton-NLP/SUP-SIMCSE-BERT-LARGE-ANCESIVES | 82.21 |
| Princeton-NLP/SUP-SIMCSE-ROBERTA-BASE | 82.52 |
| Princeton-NLP/SUP-SIMCSE-ROBERTA-LARGE | 83.76 |
결과는 새로운 하이퍼 파라미터 세트를 채택한 후 현재 논문의 현재 버전에서보고 한 것보다 약간 우수합니다 (초 파라터의 경우 훈련 섹션 참조).
이름 지정 규칙 : unsup 및 sup "감독되지 않은"(Wikipedia Corpus에서 훈련) 및 "감독"(NLI 데이터 세트에 대한 교육)을 나타냅니다.
제공된 문장 임베딩 도구를 사용하는 것 외에도 Huggingface의 transformers 로 모델을 쉽게 가져올 수도 있습니다.
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL})
다음 섹션에서는 코드를 사용하여 SIMCSE 모델을 교육하는 방법을 설명합니다.
먼저 공식 웹 사이트의 지침에 따라 Pytorch를 설치하십시오. 우리의 결과를 충실히 재현하려면 플랫폼/CUDA 버전에 해당하는 올바른 1.7.1 버전을 사용하십시오. 1.7.1 보다 높은 Pytorch 버전도 작동해야합니다. 예를 들어 Linux 및 CUDA11 (CUDA 버전 확인 방법)을 사용하는 경우 다음 명령으로 PyTorch를 설치하십시오.
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html 대신 Cuda <11 또는 CPU를 사용하는 경우 다음 명령으로 Pytorch를 설치하십시오.
pip install torch==1.7.1그런 다음 다음 스크립트를 실행하여 나머지 종속성을 설치하십시오.
pip install -r requirements.txt문장 임베딩에 대한 우리의 평가 코드는 수정 된 버전의 senteval을 기반으로합니다. 시맨틱 텍스트 유사성 (STS) 작업 및 다운 스트림 전송 작업에 대한 문장 임베딩을 평가합니다. STS 작업의 경우, 우리의 평가는 "모든"설정을 취하고 Spearman의 상관 관계를보고합니다. 평가 세부 정보는 당사 논문 (부록 B)을 참조하십시오.
평가하기 전에 실행하여 평가 데이터 세트를 다운로드하십시오
cd SentEval/data/downstream/
bash download_dataset.sh 그런 다음 루트 디렉토리로 돌아와서 평가 코드를 사용하여 transformers 기반 미리 훈련 된 모델을 평가할 수 있습니다. 예를 들어,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode test결과를 표 형식으로 출력 할 것으로 예상됩니다.
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
평가 스크립트에 대한 인수는 다음과 같습니다.
--model_name_or_path : transformers 의 이름 또는 경로-기반 예비 훈련 된 체크 포인트. 위 표에서 모델을 직접 사용할 수 있습니다 princeton-nlp/sup-simcse-bert-base-uncased--pooler : 풀링 방법. 이제 우리는 지원합니다cls (기본값) : [CLS] 토큰의 표현을 사용하십시오. 표현 후 선형+활성화 층이 적용됩니다 (표준 BERT 구현에 있습니다). 감독 된 SIMCSE를 사용하는 경우이 옵션을 사용해야합니다.cls_before_pooler : 추가 선형+활성화없이 [CLS] 토큰의 표현을 사용하십시오. 감독되지 않은 SIMCSE를 사용하는 경우이 옵션을 사용해야합니다.avg : 마지막 층의 평균 임베딩. SBERT/SROBERTA (종이)의 체크 포인트를 사용하는 경우이 옵션을 사용해야합니다.avg_top2 : 마지막 두 층의 평균 임베딩.avg_first_last : 첫 번째 및 마지막 레이어의 평균 임베딩. 바닐라 버트 또는 로베르타를 사용하는 경우 가장 잘 작동합니다. 논문에서 우리는 마지막 층의 평균과 정적 단어 임베딩을보고했다. 우리는 이것을 마지막 및 첫 번째 레이어 평균으로 고정했으며 더 나은 성능을 이끌어 냈습니다. 자세한 토론은이 문제를 참조하십시오.--mode : 평가 모드test (기본값) : 기본 테스트 모드. 우리의 결과를 충실하게 재현하려면이 옵션을 사용해야합니다.dev : 개발 세트 결과를보고하십시오. STS 작업에서는 STS-B 와 SICK-R 만 개발 세트를 가지고 있으므로 숫자 만보고합니다. 전송 작업의 경우 빠른 모드가 필요하므로 실행 시간이 test 모드보다 훨씬 짧습니다 (숫자가 약간 낮 으면).fasttest : test 와 동일하지만 빠른 모드의 경우 실행 시간이 훨씬 짧지 만보고 된 숫자는 더 낮을 수 있습니다 (전송 작업의 경우에만).--task_set : 평가할 작업 세트 (세트가있는 경우 --tasks )sts (기본값) : STS 12~16 , STS-B 및 SICK-R 포함한 STS 작업에 대한 평가. 이것은 문장 임베딩의 품질을 평가하기위한 가장 일반적으로 사용되는 작업 세트입니다.transfer : 전송 작업에 대한 평가.full : ST와 전송 작업을 모두 평가하십시오.na : --tasks 로 작업을 수동으로 설정합니다.--tasks : 평가할 데이터 세트를 지정하십시오. --task_set na 아닌 경우 재정의됩니다. 전체 작업 목록은 코드를 참조하십시오.데이터
감독되지 않은 Simcse의 경우, 우리는 영어 Wikipedia에서 백만 문장을 샘플링합니다. 감독 된 SIMCSE의 경우 SNLI 및 MNLI 데이터 세트를 사용합니다. data/download_wiki.sh 및 data/download_nli.sh 를 실행하여 두 데이터 세트를 다운로드 할 수 있습니다.
훈련 스크립트
우리는 감독되지 않은 및 감독 된 SIMCSE에 대한 예제 교육 스크립트를 제공합니다. run_unsup_example.sh 에서는 감독되지 않은 버전에 대한 단일 GPU (또는 CPU) 예제를 제공하고 run_sup_example.sh 에서는 감독 된 버전에 대한 다중 GPU 예제를 제공합니다. 두 스크립트는 훈련을 위해 train.py 에 전화합니다. 다음의 주장을 설명합니다.
--train_file : 훈련 파일 경로. 우리는 "txt"파일 (한 문장의 한 줄) 및 "CSV"파일 (2 열 : 하드 네거티브가없는 쌍 데이터; 3 열 : 해당 하드 네거티브 인스턴스와 쌍 데이터)을 지원합니다. 제공된 Wikipedia 또는 NLI 데이터를 사용할 수 있거나 동일한 형식으로 자체 데이터를 사용할 수 있습니다.--model_name_or_path : 미리 훈련 된 체크 포인트로 시작합니다. 현재 우리는 BERT 기반 모델 ( bert-base-uncased , bert-large-uncased 등) 및 Roberta 기반 모델 ( RoBERTa-base , RoBERTa-large 등)을 지원합니다.--temp : 대조적 손실을위한 온도.--pooler_type : 풀링 방법. 평가 부품의 --pooler_type 와 동일합니다.--mlp_only_train : 감독되지 않은 SIMCSE의 경우 MLP 레이어로 모델을 훈련시키는 것이 더 잘 작동하지만 모델없이 모델을 테스트하는 것이 좋습니다. 감독되지 않은 SIMCSE 모델을 교육 할 때이 인수를 사용해야합니다.--hard_negative_weight : 하드 네거티브를 사용하는 경우 (예 : 훈련 파일에 3 개의 열이 있습니다) 이것은 가중치의 로그입니다. 예를 들어, 무게가 1 인 경우이 인수는 0 (기본값)으로 설정해야합니다.--do_mlm : MLM 보조 목표 사용 여부. 사실이라면 :--mlm_weight : MLM 목표를위한 무게.--mlm_probability : MLM 목표에 대한 마스킹 속도. 다른 모든 주장은 표준 Huggingface의 transformers 훈련 주장입니다. 자주 사용되는 인수 중 일부는 다음과 같습니다. --output_dir , --learning_rate , --per_device_train_batch_size 입니다. 이 예제 스크립트에서는 STS-B 개발 세트의 모델을 평가하고 (평가 섹션에 따라 데이터 세트를 다운로드해야 함) 최상의 체크 포인트를 저장하도록 설정했습니다.
결과적으로 논문의 경우 CUDA 11과 함께 NVIDIA 3090 GPU를 사용합니다. 다른 유형의 장치 또는 다른 버전의 CUDA/기타 소프트웨어를 사용하면 성능이 약간 다를 수 있습니다.
초 파라미터
우리는 Simcse를 훈련시키기 위해 다음과 같은 하이퍼 파 램터를 사용합니다.
| Unsup. 버트 | Unsup. 로베르타 | 한모금. | |
|---|---|---|---|
| 배치 크기 | 64 | 512 | 512 |
| 학습 속도 (기본) | 3E-5 | 1E-5 | 5E-5 |
| 학습 속도 (큰) | 1E-5 | 3E-5 | 1E-5 |
모델 변환
저장된 체크 포인트는 Huggingface의 미리 훈련 된 체크 포인트와 약간 다릅니다. python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} 실행하여 변환하십시오. 그런 다음 평가 코드로 평가하거나 상자에서 직접 사용할 수 있습니다.
코드 나 논문과 관련된 질문이 있으시면 tianyu ( [email protected] ) 및 Xingcheng ( [email protected] )에게 이메일을 보내주십시오. 코드를 사용할 때 문제가 발생하거나 버그를보고하려면 문제를 열 수 있습니다. 세부 사항으로 문제를 지정하여 더 나은 시간을 더 빨리 도와 줄 수 있습니다!
작업에서 Simcse를 사용하는 경우 신문을 인용하십시오.
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}우리는 Simcse를 확장하기위한 커뮤니티의 노력에 감사드립니다!
sentence-transformers 기반 교육 코드를 구현했습니다.

