SimCSE
0.4
Repositori ini berisi kode dan model pra-terlatih untuk makalah kami Simcse: Pembelajaran Kontras Sederhana dari Embeddings Kalimat.
**************************** Pembaruan **************************
Kami mengusulkan kerangka pembelajaran kontras sederhana yang bekerja dengan data yang tidak berlabel dan berlabel. SimCSE tanpa pengawasan hanya mengambil kalimat input dan memprediksi dirinya dalam kerangka pembelajaran yang kontras, dengan hanya putus standar yang digunakan sebagai kebisingan. SimCSE kami yang diawasi menggabungkan pasangan beranotasi dari kumpulan data NLI ke dalam pembelajaran yang kontras dengan menggunakan pasangan entailment sebagai pasangan positif dan contradiction sebagai negatif keras. Gambar berikut adalah ilustrasi model kami.
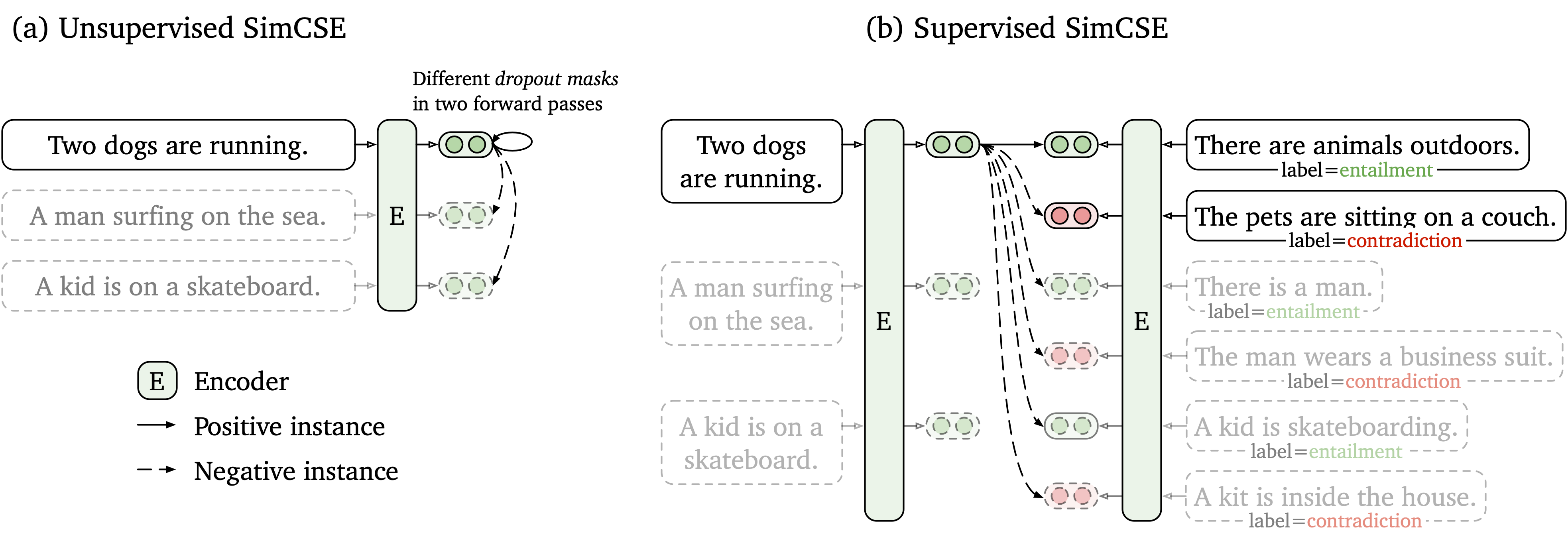
Kami menyediakan alat penyematan kalimat yang mudah digunakan berdasarkan model SimCSE kami (lihat wiki kami untuk penggunaan terperinci). Untuk menggunakan alat ini, pertama instal paket simcse dari PYPI
pip install simcseAtau secara langsung menginstalnya dari kode kami
python setup.py installPerhatikan bahwa jika Anda ingin mengaktifkan pengkodean GPU, Anda harus menginstal versi Pytorch yang benar yang mendukung CUDA. Lihat situs web resmi Pytorch untuk instruksi.
Setelah menginstal paket, Anda dapat memuat model kami hanya dengan dua baris kode
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )Lihat Daftar Model untuk daftar lengkap model yang tersedia.
Maka Anda dapat menggunakan model kami untuk menyandikan kalimat ke dalam embeddings
embeddings = model . encode ( "A woman is reading." )Hitung kesamaan kosinus antara dua kelompok kalimat
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )Atau membangun indeks untuk sekelompok kalimat dan mencari di antara mereka
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) Kami juga mendukung FAISS, perpustakaan pencarian kesamaan yang efisien. Cukup instal paket berikut instruksi di sini dan simcse akan secara otomatis menggunakan faiss untuk pencarian yang efisien.
Peringatan : Kami telah menemukan bahwa faiss tidak mendukung NVIDIA Ampere GPU (3090 dan A100). Dalam hal ini, Anda harus mengubah ke GPU lain atau menginstal Paket faiss versi CPU.
Kami juga menyediakan situs web demo yang mudah dibangun untuk menunjukkan bagaimana simcse dapat digunakan dalam pengambilan kalimat. Kode ini didasarkan pada repo dan demo densephrases (terima kasih banyak kepada penulis densefrases).
Model kami yang dirilis terdaftar sebagai berikut. Anda dapat mengimpor model ini dengan menggunakan paket simcse atau menggunakan Transformers HuggingFace.
| Model | Rata -rata. STS |
|---|---|
| Princeton-NLP/Unsup-Simcse-Bert-Base-Base-NaCased | 76.25 |
| Princeton-NLP/Unsup-Simcse-Bert-Large-Incased | 78.41 |
| Princeton-NLP/Unsup-Simcse-Roberta-Base | 76.57 |
| Princeton-NLP/Unsup-Simcse-Roberta-Large | 78.90 |
| Princeton-NLP/SUP-SIMCSE-BERT-BASE-BASE-ONCASE | 81.57 |
| Princeton-NLP/SUP-SIMCSE-BERT-LARGE-LUAR | 82.21 |
| Princeton-NLP/SUP-SIMCSE-ROBERTA-BASE | 82.52 |
| Princeton-NLP/Sup-Simcse-Roberta-Large | 83.76 |
Perhatikan bahwa hasilnya sedikit lebih baik daripada apa yang telah kami laporkan dalam versi makalah saat ini setelah mengadopsi satu set hyperparameters baru (untuk hyperparamters, lihat bagian pelatihan).
Aturan penamaan : unsup dan sup mewakili "tanpa pengawasan" (dilatih di wikipedia corpus) dan "diawasi" (dilatih masing -masing pada dataset NLI).
Selain menggunakan alat embedding kalimat yang disediakan, Anda juga dapat dengan mudah mengimpor model kami dengan transformers Huggingface:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) Jika Anda menghadapi masalah ketika secara langsung memuat model dengan API HuggingFace, Anda juga dapat mengunduh model secara manual dari tabel di atas dan menggunakan model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) .
Di bagian berikut, kami menjelaskan cara melatih model SIMCSE dengan menggunakan kode kami.
Pertama, instal Pytorch dengan mengikuti instruksi dari situs web resmi. Untuk mereproduksi hasil kami dengan setia, silakan gunakan versi 1.7.1 yang benar sesuai dengan versi platform/CUDA Anda. Versi Pytorch lebih tinggi dari 1.7.1 juga harus berfungsi. Misalnya, jika Anda menggunakan Linux dan Cuda11 (cara memeriksa versi CUDA), instal Pytorch dengan perintah berikut,
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html Jika Anda malah menggunakan CUDA <11 atau CPU , instal Pytorch dengan perintah berikut,
pip install torch==1.7.1Kemudian jalankan skrip berikut untuk menginstal dependensi yang tersisa,
pip install -r requirements.txtKode evaluasi kami untuk embeddings kalimat didasarkan pada versi SentEval yang dimodifikasi. Ini mengevaluasi embeddings kalimat pada tugas kesamaan tekstual semantik (STS) dan tugas transfer hilir. Untuk tugas STS, evaluasi kami mengambil pengaturan "semua", dan laporkan korelasi Spearman. Lihat makalah kami (Lampiran B) untuk detail evaluasi.
Sebelum evaluasi, silakan unduh dataset evaluasi dengan berjalan
cd SentEval/data/downstream/
bash download_dataset.sh Kemudian kembalilah ke direktori root, Anda dapat mengevaluasi model pra -terlatih berbasis transformers menggunakan kode evaluasi kami. Misalnya,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode testyang diharapkan menghasilkan hasil dalam format tabel:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
Argumen untuk skrip evaluasi adalah sebagai berikut,
--model_name_or_path : Nama atau jalur pos pemeriksaan pra-terlatih berbasis transformers . Anda dapat secara langsung menggunakan model di tabel di atas, misalnya, princeton-nlp/sup-simcse-bert-base-uncased .--pooler : Metode Pooling. Sekarang kami mendukungcls (default): Gunakan representasi token [CLS] . Lapisan aktivasi linier+diterapkan setelah representasi (itu dalam implementasi BerT standar). Jika Anda menggunakan simcse yang diawasi , Anda harus menggunakan opsi ini.cls_before_pooler : Gunakan representasi token [CLS] tanpa aktivasi linear+ekstra. Jika Anda menggunakan simcse tanpa pengawasan , Anda harus mengambil opsi ini.avg : Embeddings rata -rata dari lapisan terakhir. Jika Anda menggunakan pos pemeriksaan sbert/sroberta (kertas), Anda harus menggunakan opsi ini.avg_top2 : Embeddings rata -rata dari dua lapisan terakhir.avg_first_last : Embeddings rata -rata dari lapisan pertama dan terakhir. Jika Anda menggunakan Vanilla Bert atau Roberta, ini berfungsi terbaik. Perhatikan bahwa di koran kami melaporkan rata -rata lapisan terakhir dan kata embedding statis; Kami memperbaiki ini menjadi rata -rata lapisan terakhir dan pertama dan itu menyebabkan kinerja yang lebih baik. Lihat masalah ini untuk diskusi terperinci.--mode : mode evaluasitest (default): Mode uji default. Untuk mereproduksi hasil kami dengan setia, Anda harus menggunakan opsi ini.dev : Laporkan hasil yang ditetapkan pengembangan. Perhatikan bahwa dalam tugas STS, hanya STS-B dan SICK-R yang memiliki set pengembangan, jadi kami hanya melaporkan jumlah mereka. Ini juga membutuhkan mode cepat untuk tugas transfer, sehingga waktu berjalan jauh lebih pendek daripada mode test (meskipun angka sedikit lebih rendah).fasttest : Ini sama dengan test , tetapi dengan mode cepat sehingga waktu berjalan jauh lebih pendek, tetapi angka yang dilaporkan mungkin lebih rendah (hanya untuk tugas transfer).--task_set : Kumpulan tugas apa yang akan dievaluasi (jika diatur, itu akan mengganti --tasks )sts (default): Mengevaluasi tugas STS, termasuk STS 12~16 , STS-B dan SICK-R . Ini adalah set tugas yang paling sering digunakan untuk mengevaluasi kualitas embeddings kalimat.transfer : Evaluasi tugas transfer.full : Evaluasi STS dan Tugas Transfer.na : Atur tugas secara manual dengan --tasks .--tasks : Tentukan dataset mana yang akan dievaluasi. Akan ditimpa jika --task_set bukan na . Lihat kode untuk daftar lengkap tugas.Data
Untuk simcse tanpa pengawasan, kami mencicipi 1 juta hukuman dari Wikipedia Inggris; Untuk simcse yang diawasi, kami menggunakan dataset SNLI dan MNLI. Anda dapat menjalankan data/download_wiki.sh dan data/download_nli.sh untuk mengunduh dua set data.
Skrip pelatihan
Kami memberikan contoh skrip pelatihan untuk simcse yang tidak diawasi dan diawasi. Dalam run_unsup_example.sh , kami memberikan contoh gpu tunggal (atau CPU) untuk versi yang tidak diawasi, dan di run_sup_example.sh kami memberikan contoh multipel-gpu untuk versi yang diawasi. Kedua skrip memanggil train.py untuk pelatihan. Kami menjelaskan argumen di berikut:
--train_file : Path File Pelatihan. Kami mendukung file "txt" (satu baris untuk satu kalimat) dan file "CSV" (2-kolom: berpasangan data tanpa negatif keras; 3-kolom: berpasangan data dengan satu instance negatif keras yang sesuai). Anda dapat menggunakan data wikipedia atau NLI yang disediakan, atau Anda dapat menggunakan data Anda sendiri dengan format yang sama.--model_name_or_path : Pos pemeriksaan terlatih untuk memulai. Untuk saat ini kami mendukung model berbasis Bert ( bert-base-uncased , bert-large-uncased , dll.) Dan model yang berbasis di Roberta ( RoBERTa-base , RoBERTa-large , dll.).--temp : Suhu untuk kehilangan kontras.--pooler_type : Metode Pooling. Itu sama dengan --pooler_type di bagian evaluasi.--mlp_only_train : Kami telah menemukan bahwa untuk simcse tanpa pengawasan, ia bekerja lebih baik untuk melatih model dengan lapisan MLP tetapi menguji model tanpa itu. Anda harus menggunakan argumen ini saat melatih model SimCSE tanpa pengawasan.--hard_negative_weight : Jika menggunakan negatif keras (yaitu, ada 3 kolom dalam file pelatihan), ini adalah logaritma berat. Misalnya, jika beratnya adalah 1, maka argumen ini harus ditetapkan sebagai 0 (nilai default).--do_mlm : Apakah akan menggunakan tujuan tambahan MLM. Jika benar:--mlm_weight : Berat untuk tujuan MLM.--mlm_probability : laju masking untuk tujuan MLM. Semua argumen lainnya adalah argumen pelatihan transformers Standar HuggingFace. Beberapa argumen yang sering digunakan adalah: --output_dir , --learning_rate , --per_device_train_batch_size . Dalam contoh skrip kami, kami juga mengatur untuk mengevaluasi model pada set pengembangan STS-B (perlu mengunduh dataset mengikuti bagian evaluasi) dan menyimpan pos pemeriksaan terbaik.
Untuk hasil dalam makalah ini, kami menggunakan NVIDIA 3090 GPU dengan CUDA 11. Menggunakan berbagai jenis perangkat atau versi CUDA/perangkat lunak lainnya yang berbeda dapat menyebabkan kinerja yang sedikit berbeda.
Hyperparameters
Kami menggunakan hyperparamters berikut untuk melatih simcse:
| Unsup. Bert | Unsup. Roberta | Sup. | |
|---|---|---|---|
| Ukuran batch | 64 | 512 | 512 |
| Tingkat Pembelajaran (Basis) | 3e-5 | 1E-5 | 5e-5 |
| Tingkat Pembelajaran (Besar) | 1E-5 | 3e-5 | 1E-5 |
Konversi model
Pos pemeriksaan tersimpan kami sedikit berbeda dari pos pemeriksaan pra-terlatih HuggingFace. Jalankan python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} untuk mengonversinya. Setelah itu, Anda dapat mengevaluasinya dengan kode evaluasi kami atau secara langsung menggunakannya di luar kotak.
Jika Anda memiliki pertanyaan yang terkait dengan kode atau kertas, jangan ragu untuk mengirim email ke Tianyu ( [email protected] ) dan Xingcheng ( [email protected] ). Jika Anda mengalami masalah saat menggunakan kode, atau ingin melaporkan bug, Anda dapat membuka masalah. Silakan coba tentukan masalah dengan detail sehingga kami dapat membantu Anda lebih baik dan lebih cepat!
Harap kutip kertas kami jika Anda menggunakan simcse dalam pekerjaan Anda:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}Kami berterima kasih kepada upaya masyarakat untuk memperluas simcse!
sentence-transformers untuk SIMCSE.

