SimCSE
0.4
Este repositorio contiene el código y los modelos previamente capacitados para nuestro documento SIMCSE: aprendizaje contrastante simple de incrustaciones de oraciones.
**************************** ACTUALIZACIONES ********************************************
Proponemos un marco de aprendizaje contrastante simple que funcione con datos no etiquetados y etiquetados. SIMCSE sin supervisión simplemente toma una oración de entrada y se predice en un marco de aprendizaje contrastante, con solo abandono estándar utilizado como ruido. Nuestro SIMCSE supervisado incorpora pares anotados de conjuntos de datos NLI en el aprendizaje contrastante mediante el uso de pares entailment como positivos y pares contradiction como negativos duros. La siguiente figura es una ilustración de nuestros modelos.
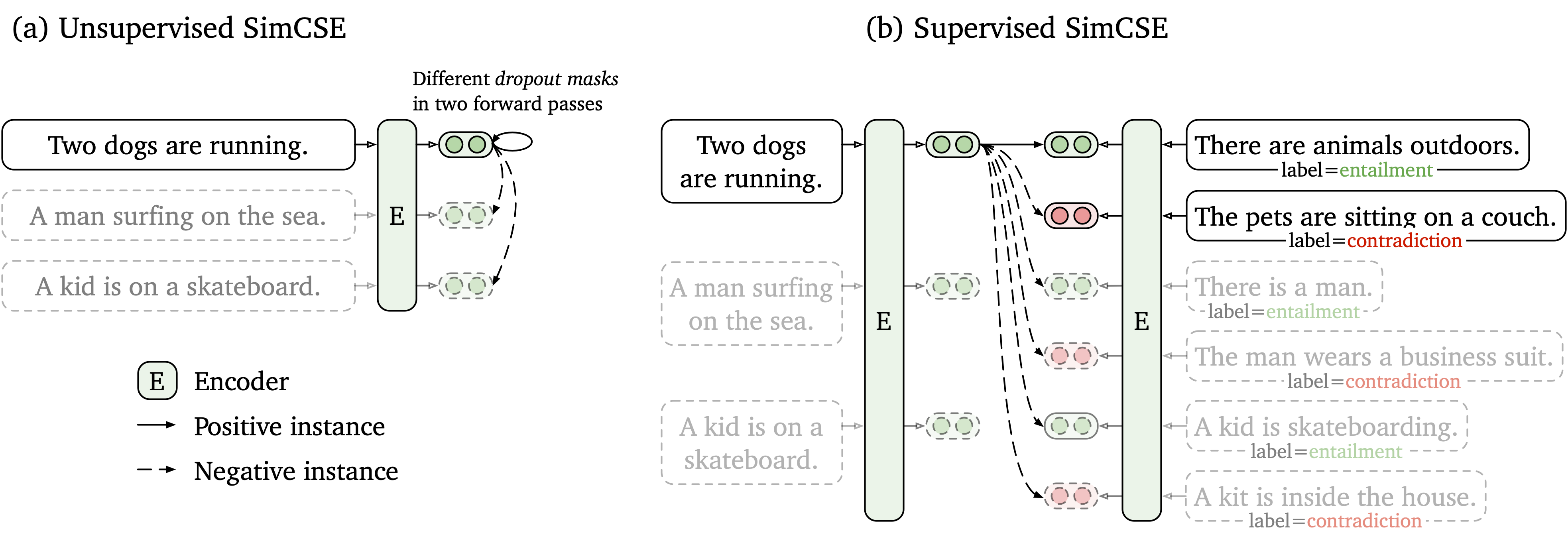
Proporcionamos una herramienta de incrustación de oraciones fáciles de usar basada en nuestro modelo SIMCSE (consulte nuestro wiki para un uso detallado). Para usar la herramienta, primero instale el paquete simcse desde Pypi
pip install simcseO instálelo directamente desde nuestro código
python setup.py installTenga en cuenta que si desea habilitar la codificación de GPU, debe instalar la versión correcta de Pytorch que admite CUDA. Consulte el sitio web oficial de Pytorch para obtener instrucciones.
Después de instalar el paquete, puede cargar nuestro modelo por solo dos líneas de código
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )Consulte la lista de modelos para obtener una lista completa de modelos disponibles.
Entonces puede usar nuestro modelo para codificar oraciones en incrustaciones
embeddings = model . encode ( "A woman is reading." )Calcule las similitudes de coseno entre dos grupos de oraciones
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )O construir índice para un grupo de oraciones y buscar entre ellas
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) También apoyamos FAISS, una biblioteca de búsqueda de similitud eficiente. Simplemente instale las instrucciones del paquete siguientes aquí y simcse usará automáticamente faiss para una búsqueda eficiente.
ADVERTENCIA : Hemos descubierto que faiss no apoyaba bien las GPU Nvidia Ampere (3090 y A100). En ese caso, debe cambiar a otras GPU o instalar la versión CPU del paquete faiss .
También proporcionamos un sitio web de demostración fácil de construir para mostrar cómo SIMCSE se puede usar en la recuperación de oraciones. El código se basa en el repositorio y la demostración de Frases densas (muchas gracias a los autores de lasfrases densas).
Nuestros modelos lanzados se enumeran como lo siguiente. Puede importar estos modelos utilizando el paquete simcse o utilizando Transformers de Huggingface.
| Modelo | Avg. Sts |
|---|---|
| Princeton-NLP/Unsup-Simcse-Base-Base | 76.25 |
| Princeton-NLP/Unsup-Simcse-Bert-Large-Inscuye | 78.41 |
| Princeton-NLP/Unsup-Simcse-Roberta-Base | 76.57 |
| Princeton-NLP/Unsup-Simcse-Roberta-Large | 78.90 |
| Princeton-NLP/SUP-Simcse-Base-Base | 81.57 |
| princeton-nlp/sup-simcse-bert-large | 82.21 |
| Princeton-NLP/SUP-SIMCSE-ROBERTA-BASE | 82.52 |
| Princeton-NLP/SUP-Simcse-Roberta-Large | 83.76 |
Tenga en cuenta que los resultados son ligeramente mejores que los que hemos informado en la versión actual del documento después de adoptar un nuevo conjunto de hiperparámetros (para hiperparamters, consulte la sección de entrenamiento).
Reglas de nombramiento : unsup y sup representan "sin supervisión" (entrenados en Wikipedia Corpus) y "supervisado" (entrenado en conjuntos de datos NLI) respectivamente.
Además de usar nuestra herramienta de incrustación de oraciones proporcionada, también puede importar fácilmente nuestros modelos con transformers de Huggingface:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) Si encuentra algún problema al cargar directamente los modelos por la API de Huggingface, también puede descargar los modelos manualmente desde la tabla anterior y usar model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) .
En la siguiente sección, describimos cómo entrenar un modelo SIMCSE utilizando nuestro código.
Primero, instale Pytorch siguiendo las instrucciones desde el sitio web oficial. Para reproducir fielmente nuestros resultados, utilice la versión correcta 1.7.1 correspondiente a sus plataformas/versiones CUDA. La versión de Pytorch superior a 1.7.1 también debería funcionar. Por ejemplo, si usa Linux y CUDA11 (cómo verificar la versión CUDA), instale pytorch por el siguiente comando,
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html Si en su lugar usa Cuda <11 o CPU , instale Pytorch por el siguiente comando,
pip install torch==1.7.1Luego ejecute el siguiente script para instalar las dependencias restantes,
pip install -r requirements.txtNuestro código de evaluación para incrustaciones de oraciones se basa en una versión modificada de Senteval. Evalúa las incrustaciones de oraciones en tareas de similitud textual semántica (STS) y tareas de transferencia posterior. Para las tareas STS, nuestra evaluación toma la configuración "All" e informa la correlación de Spearman. Consulte nuestro artículo (Apéndice B) para obtener detalles de evaluación.
Antes de la evaluación, descargue los conjuntos de datos de evaluación ejecutando
cd SentEval/data/downstream/
bash download_dataset.sh Luego regrese al directorio raíz, puede evaluar cualquier modelo previamente entrenado basado en transformers utilizando nuestro código de evaluación. Por ejemplo,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode testque se espera que genere los resultados en un formato tabular:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
Los argumentos para el script de evaluación son los siguientes,
--model_name_or_path : el nombre o ruta de un punto de control previamente entrenado basado en transformers . Puede usar directamente los modelos en la tabla anterior, por ejemplo, princeton-nlp/sup-simcse-bert-base-uncased .--pooler : método de agrupación. Ahora apoyamoscls (predeterminado): use la representación del token [CLS] . Se aplica una capa de activación lineal+después de la representación (está en la implementación estándar de BERT). Si usa SIMCSE supervisado , debe usar esta opción.cls_before_pooler : Use la representación del token [CLS] sin la activación adicional lineal+. Si usa SIMCSE no supervisado , debe tomar esta opción.avg : incrustaciones promedio de la última capa. Si usa puntos de control de Sbert/Sroberta (papel), debe usar esta opción.avg_top2 : incrustaciones promedio de las últimas dos capas.avg_first_last : incrustaciones promedio de la primera y las últimas capas. Si usa Vanilla Bert o Roberta, esto funciona mejor. Tenga en cuenta que en el documento informamos el promedio de la última capa y la incrustación de palabras estáticas; arreglamos esto para ser el último y promedio de la primera capa y condujo a un mejor rendimiento. Vea este tema para una discusión detallada.--mode : modo de evaluacióntest (predeterminado): el modo de prueba predeterminado. Para reproducir fielmente nuestros resultados, debe usar esta opción.dev : Informe los resultados del conjunto de desarrollo. Tenga en cuenta que en las tareas STS, solo STS-B y SICK-R tienen conjuntos de desarrollo, por lo que solo informamos sus números. También requiere un modo rápido para las tareas de transferencia, por lo que el tiempo de ejecución es mucho más corto que el modo test (aunque los números son ligeramente más bajos).fasttest : es lo mismo que test , pero con un modo rápido, por lo que el tiempo de ejecución es mucho más corto, pero los números informados pueden ser más bajos (solo para tareas de transferencia).--task_set : qué conjunto de tareas para evaluar (si se establece, anulará --tasks )sts (predeterminado): Evalúe en las tareas STS, incluyendo STS 12~16 , STS-B y SICK-R . Este es el conjunto de tareas más utilizados para evaluar la calidad de las integridades de las oraciones.transfer : evaluar en tareas de transferencia.full : evaluar tanto en Tareas de STS como de transferencia.na : Establecer manualmente tareas por --tasks .--tasks : especifique en qué conjunto de datos (s) evaluar. Se anulará si --task_set no es na . Vea el código para obtener una lista completa de tareas.Datos
Para SIMCSE no supervisado, tomamos 1 millón de oraciones de Wikipedia en inglés; Para SIMCSE supervisado, usamos los conjuntos de datos SNLI y MNLI. Puede ejecutar data/download_wiki.sh y data/download_nli.sh para descargar los dos conjuntos de datos.
Guiones de entrenamiento
Proporcionamos scripts de capacitación de ejemplo para SIMCSE no supervisado y supervisado. En run_unsup_example.sh , proporcionamos un ejemplo de GPU (o CPU) para la versión no supervisada, y en run_sup_example.sh damos un ejemplo de GPU múltiple para la versión supervisada. Ambos scripts llaman train.py para entrenar. Explicamos los argumentos al siguiente:
--train_file : ruta del archivo de entrenamiento. Admitimos archivos "TXT" (una línea para una oración) y archivos "CSV" (2 columnas: Pare datos sin negativo duro; 3 columnas: Pare datos con una instancia negativa dura correspondiente). Puede usar nuestros datos Wikipedia o NLI proporcionados, o puede usar sus propios datos con el mismo formato.--model_name_or_path : puntos de control previamente entrenados para comenzar. Por ahora, apoyamos modelos basados en Bert ( bert-base-uncased , bert-large-uncased , etc.) y modelos con sede en Roberta ( RoBERTa-base , RoBERTa-large , etc.).--temp : Temperatura para la pérdida de contraste.--pooler_type : método de agrupación. Es lo mismo que el --pooler_type en la parte de evaluación.--mlp_only_train : hemos descubierto que para SIMCSE no supervisado, funciona mejor entrenar el modelo con la capa MLP pero probar el modelo sin él. Debe usar este argumento cuando entrene a los modelos SIMCSE no supervisados.--hard_negative_weight : si se usa negativos duros (es decir, hay 3 columnas en el archivo de entrenamiento), este es el logaritmo del peso. Por ejemplo, si el peso es 1, entonces este argumento debe establecerse como 0 (valor predeterminado).--do_mlm : si se debe usar el objetivo auxiliar MLM. Si es cierto:--mlm_weight : peso para el objetivo MLM.--mlm_probability : tasa de enmascaramiento para el objetivo MLM. Todos los demás argumentos son los argumentos de entrenamiento transformers estándar de Huggingface. Algunos de los argumentos a menudo utilizados son: --output_dir , --learning_rate , --per_device_train_batch_size . En nuestros scripts de ejemplo, también nos configuramos para evaluar el modelo en el conjunto de desarrollo STS-B (necesita descargar el conjunto de datos después de la sección de evaluación) y guardar el mejor punto de control.
Para los resultados en el documento, utilizamos las GPU NVIDIA 3090 con CUDA 11. El uso de diferentes tipos de dispositivos o diferentes versiones de CUDA/otros softwares puede conducir a un rendimiento ligeramente diferente.
Hiperparámetros
Utilizamos los siguientes hiperparamters para entrenamiento SIMCSE:
| Unsup. Bert | Unsup. Roberta | Sorber. | |
|---|---|---|---|
| Tamaño por lotes | 64 | 512 | 512 |
| Tasa de aprendizaje (base) | 3E-5 | 1e-5 | 5E-5 |
| Tasa de aprendizaje (grande) | 1e-5 | 3E-5 | 1e-5 |
Convertir modelos
Nuestros puntos de control guardados son ligeramente diferentes de los puntos de control previamente capacitados de Huggingface. Ejecute python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} para convertirlo. Después de eso, puede evaluarlo mediante nuestro código de evaluación o usarlo directamente fuera de la caja.
Si tiene alguna pregunta relacionada con el código o el documento, no dude en enviar un correo electrónico a Tianyu ( [email protected] ) y a Xingcheng ( [email protected] ). Si encuentra algún problema al usar el código o desea informar un error, puede abrir un problema. ¡Intente especificar el problema con los detalles para que podamos ayudarlo mejor y más rápido!
Por favor cita nuestro documento si usa SIMCSE en su trabajo:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}¡Agradecemos los esfuerzos de la comunidad por extender SIMCSE!
sentence-transformers para SIMCSE.

