SimCSE
0.4
该存储库包含我们的纸张SIMCSE的代码和预训练的模型:简单的对比度学习句子嵌入。
**************************************************************
我们提出了一个简单的对比学习框架,该框架与未标记和标记的数据一起使用。无监督的SIMCSE只是采用输入句子,并在对比度学习框架中预测自己,仅将标准辍学用作噪声。我们有监督的SIMCSE通过使用entailment对作为肯定和contradiction对作为硬否负面因素,将NLI数据集的带注释的对对比度学习。下图是我们模型的例证。
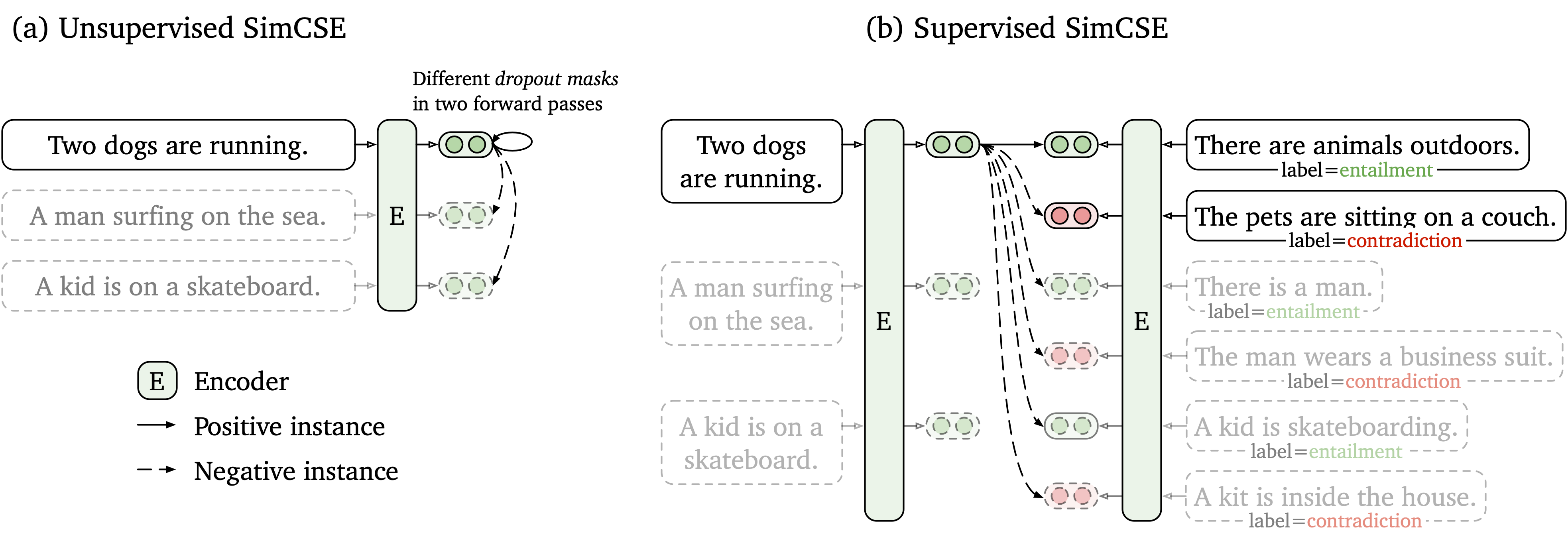
我们根据SIMCSE模型提供了易于使用的句子嵌入工具(有关详细用法,请参见我们的Wiki)。要使用该工具,请先从PYPI安装simcse软件包
pip install simcse或直接从我们的代码安装
python setup.py install请注意,如果要启用GPU编码,则应安装支持CUDA的Pytorch的正确版本。有关说明,请参见Pytorch官方网站。
安装软件包后,您只需两行代码加载我们的模型
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )有关可用型号的完整列表,请参见模型列表。
然后,您可以使用我们的模型将句子编码为嵌入
embeddings = model . encode ( "A woman is reading." )计算两组句子之间的余弦相似性
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )或为一组句子构建索引并在其中搜索
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." )我们还支持有效的相似性搜索库Faiss。只需在此处安装包装按照说明即可, simcse将自动使用faiss进行有效的搜索。
警告:我们发现faiss不能很好地支持Nvidia Ampere GPU(3090和A100)。在这种情况下,您应该更改为其他GPU或安装CPU版本的faiss软件包。
我们还提供一个易于构建的演示网站,以显示如何在句子检索中使用SIMCSE。该代码基于密码和演示(非常感谢致密词的作者)。
我们发布的模型如下。您可以使用simcse软件包或使用HuggingFace的变压器导入这些模型。
| 模型 | avg。 sts |
|---|---|
| Princeton-NLP/Unsup-Simcse-Bert-Base-Base-Base-unc. | 76.25 |
| Princeton-NLP/Unsup-Simcse-Bert-large-unge | 78.41 |
| 普林斯顿-NLP/Unsup-Simcse-Roberta基础 | 76.57 |
| 普林斯顿-NLP/Unsup-Simcse-Roberta-large | 78.90 |
| Princeton-NLP/SUP-SIMCSE-BERT-BASE不合格 | 81.57 |
| 普林斯顿-NLP/sup-simcse-bert-large-large | 82.21 |
| 普林斯顿-NLP/SUP-SIMCSE-ROBERTA-BASE | 82.52 |
| 普林斯顿-NLP/SUP-SIMCSE-ROBERTA-LARGE | 83.76 |
请注意,在采用了一组新的超参数(有关超参数,请参见培训部分)后,结果比我们在本文当前版本中报告的结果稍好一些。
命名规则: unsup和sup分别代表“无监督”(在Wikipedia语料库中训练)和“监督”(在NLI数据集中受过培训)。
除了使用我们提供的句子嵌入工具外,您还可以轻松地使用HuggingFace的transformers导入我们的模型:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 ))如果您通过HuggingFace的API直接加载模型时会遇到任何问题,则还可以从上表手动下载模型,并使用model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL}) 。
在下一节中,我们描述了如何使用我们的代码训练SIMCSE模型。
首先,按照官方网站的说明安装Pytorch。为了忠实地重现我们的结果,请使用与您的平台/CUDA版本相对应的正确的1.7.1版本。 pytorch版本高于1.7.1也应起作用。例如,如果您使用Linux和CUDA11 (如何检查CUDA版本),请按以下命令安装Pytorch,
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html如果您使用CUDA <11或CPU ,请按以下命令安装Pytorch,
pip install torch==1.7.1然后运行以下脚本以安装剩余的依赖项,
pip install -r requirements.txt我们针对句子嵌入的评估代码基于Senteval的修改版本。它评估句子嵌入语义文本相似性(STS)任务和下游传输任务。对于STS任务,我们的评估采用“所有”设置,并报告Spearman的相关性。有关评估详细信息,请参见我们的论文(附录B)。
在评估之前,请通过运行下载评估数据集
cd SentEval/data/downstream/
bash download_dataset.sh然后回到根目录,您可以使用我们的评估代码评估任何基于transformers的预训练模型。例如,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode test预计将以表格格式输出结果:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
评估脚本的论点如下,
--model_name_or_path :基于transformers的预训练检查点的名称或路径。您可以直接使用上表中的模型,例如, princeton-nlp/sup-simcse-bert-base-uncased 。--pooler :合并方法。现在我们支持cls (默认):使用[CLS]令牌的表示。表示在表示后(标准BERT实施中)应用线性+激活层。如果您使用监督的SIMCSE ,则应使用此选项。cls_before_pooler :使用[CLS]令牌的表示,而无需额外的线性+激活。如果您使用无监督的SIMCSE ,则应采用此选项。avg :最后一层的平均嵌入。如果您使用Sbert/Sroberta(纸)的检查站,则应使用此选项。avg_top2 :最后两层的平均嵌入。avg_first_last :第一层和最后一层的平均嵌入。如果您使用Vanilla Bert或Roberta,则最好。请注意,在论文中,我们报告了最后一层的平均值和静态单词嵌入;我们将其定义为最后一层和第一层的平均值,并带来了更好的性能。请参阅此问题以进行详细讨论。--mode :评估模式test (默认):默认测试模式。为了忠实地重现我们的结果,您应该使用此选项。dev :报告开发集结果。请注意,在STS任务中,只有STS-B和SICK-R具有开发集,因此我们只报告其数字。它还需要快速的传输任务模式,因此运行时间比test模式短得多(尽管数字略低)。fasttest :它与test相同,但是使用快速模式,因此运行时间要短得多,但是报告的数字可能较低(仅适用于转移任务)。--task_set :要评估的一组任务集(如果设置,它将覆盖--tasks )sts (默认):在STS任务上进行评估,包括STS 12~16 , STS-B和SICK-R 。这是评估句子嵌入质量的最常用的任务集。transfer :评估转移任务。full :对两个ST和转移任务进行评估。na :按--tasks手动设置任务。--tasks :指定要评估的数据集。如果--task_set不是na ,将被覆盖。请参阅代码以获取完整的任务列表。数据
对于无监督的Simcse,我们从英语Wikipedia中进行了100万句话;对于受监督的SIMCSE,我们使用SNLI和MNLI数据集。您可以运行data/download_wiki.sh和data/download_nli.sh下载两个数据集。
培训脚本
我们为无监督和监督的SIMCSE提供示例培训脚本。在run_unsup_example.sh中,我们为无监督版提供了一个单GPU(或CPU)示例,在run_sup_example.sh中,我们为监督版提供了一个多GPU示例。两个脚本都致电train.py进行培训。我们在以下内容中解释了以下论点:
--train_file :培训文件路径。我们支持“ txt”文件(一个句子的一行)和“ csv”文件(2个列:没有硬性负面的数据; 3列:配对数据与一个相应的硬否实例)。您可以使用我们提供的Wikipedia或NLI数据,也可以使用自己的数据以相同的格式使用。--model_name_or_path :首先进行的预训练检查点。目前,我们支持基于BERT的模型(基于bert-base-uncased , bert-large-uncased等)和基于Roberta的模型( RoBERTa-base , RoBERTa-large等)。--temp :对比度损失的温度。--pooler_type :池化方法。它与评估部分中的--pooler_type相同。--mlp_only_train :我们发现,对于无监督的SIMCSE,使用MLP层训练模型却更好,但没有它测试模型。在训练无监督的SIMCSE模型时,您应该使用此参数。--hard_negative_weight :如果使用硬负元(即,培训文件中有3列),则是重量的对数。例如,如果权重为1,则应将此参数设置为0(默认值)。--do_mlm :是否使用MLM辅助目标。如果是真的:--mlm_weight :MLM目标的重量。--mlm_probability :MLM目标的掩蔽率。所有其他论点都是标准的Huggingface的transformers培训论点。一些经常使用的参数是: --output_dir , --learning_rate , --per_device_train_batch_size 。在我们的示例脚本中,我们还设置了在STS-B开发集中评估模型(在评估部分之后需要下载数据集)并保存最佳检查点。
对于本文中的结果,我们将NVIDIA 3090 GPU与CUDA 11一起使用。使用不同类型的设备或不同版本的CUDA/其他软件可能会导致性能略有不同。
超参数
我们使用以下Hybreparamter进行培训SIMCSE:
| 解开。伯特 | 解开。罗伯塔 | sup。 | |
|---|---|---|---|
| 批量大小 | 64 | 512 | 512 |
| 学习率(基础) | 3E-5 | 1E-5 | 5E-5 |
| 学习率(大) | 1E-5 | 3E-5 | 1E-5 |
转换模型
我们保存的检查点与HuggingFace的预训练检查点略有不同。运行python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER}将其转换。之后,您可以通过我们的评估代码对其进行评估,也可以将其直接使用。
如果您有与代码或论文有关的任何疑问,请随时发送电子邮件至Tianyu( [email protected] )和Xingcheng( [email protected] )。如果使用代码时遇到任何问题或想报告错误,则可以打开问题。请尝试使用详细信息指定问题,以便我们可以更好,更快地帮助您!
如果您在工作中使用Simcse,请引用我们的论文:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}我们感谢社区为扩展Simcse的努力!
sentence-transformers的培训代码。

