SimCSE
0.4
ที่เก็บนี้มีรหัสและโมเดลที่ผ่านการฝึกอบรมมาล่วงหน้าสำหรับ Simcse กระดาษของเรา: การเรียนรู้ที่แตกต่างอย่างง่ายของการฝังประโยค
************************** การอัปเดต ****************************
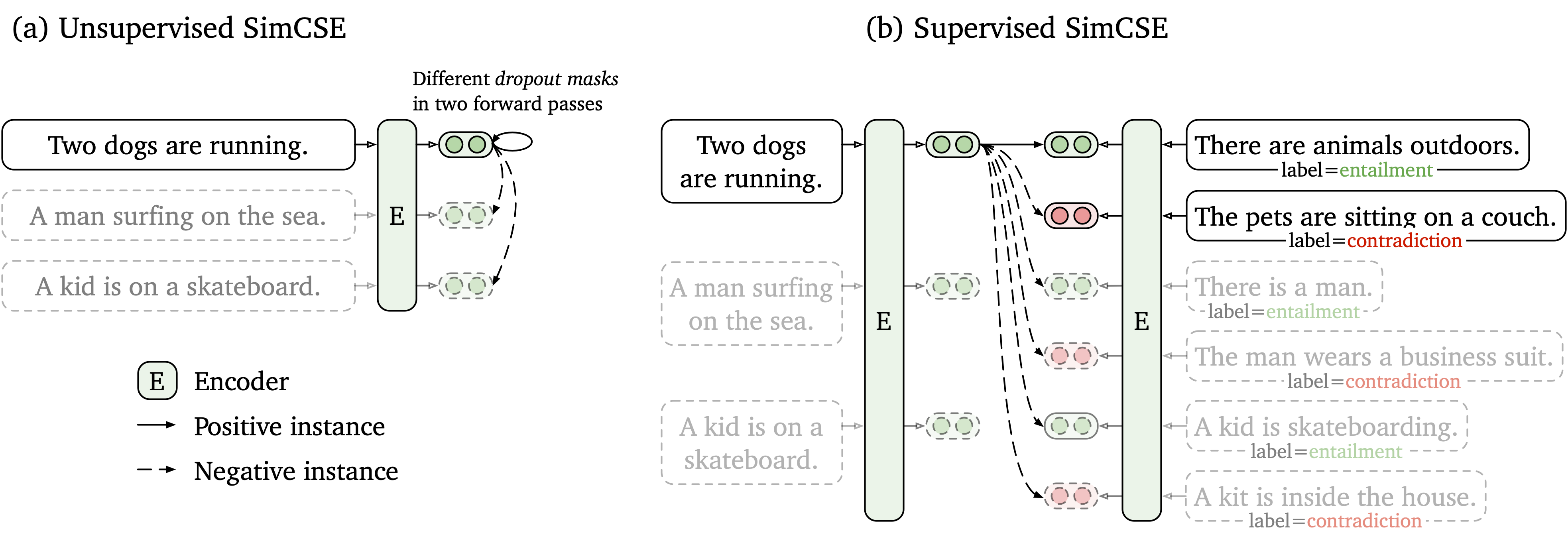
เราเสนอกรอบการเรียนรู้แบบตัดกันที่เรียบง่ายซึ่งทำงานกับข้อมูลทั้งที่ไม่มีป้ายกำกับและมีป้ายกำกับ Simcse ที่ไม่ได้รับการดูแลเพียงแค่ใช้ประโยคอินพุตและทำนายตัวเองในกรอบการเรียนรู้ที่ตรงกันข้ามโดยมีเพียงการออกกลางคันมาตรฐานที่ใช้เป็นเสียงรบกวน SIMCSE ภายใต้การดูแลของเราได้รวมคู่ที่มีคำอธิบายประกอบจากชุดข้อมูล NLI เข้ากับการเรียนรู้แบบตัดกันโดยใช้คู่ที่เป็น entailment และคู่ contradiction เป็นเชิงลบอย่างหนัก รูปต่อไปนี้เป็นภาพประกอบของโมเดลของเรา
เราจัดหาเครื่องมือฝังประโยคที่ใช้งานง่ายโดยใช้โมเดล Simcse ของเรา (ดูวิกิของเราสำหรับการใช้งานโดยละเอียด) หากต้องการใช้เครื่องมือก่อนอื่นให้ติดตั้งแพ็คเกจ simcse จาก PYPI
pip install simcseหรือติดตั้งโดยตรงจากรหัสของเรา
python setup.py installโปรดทราบว่าหากคุณต้องการเปิดใช้งานการเข้ารหัส GPU คุณควรติดตั้ง pytorch เวอร์ชันที่ถูกต้องที่รองรับ CUDA ดูเว็บไซต์อย่างเป็นทางการของ Pytorch สำหรับคำแนะนำ
หลังจากติดตั้งแพ็คเกจคุณสามารถโหลดโมเดลของเราได้เพียงสองบรรทัดของรหัส
from simcse import SimCSE
model = SimCSE ( "princeton-nlp/sup-simcse-bert-base-uncased" )ดูรายการรุ่นสำหรับรายการทั้งหมดของรุ่นที่มีอยู่
จากนั้นคุณสามารถใช้โมเดลของเราสำหรับ การเข้ารหัสประโยคลงใน embeddings
embeddings = model . encode ( "A woman is reading." )คำนวณความคล้ายคลึงกันของโคไซน์ ระหว่างสองกลุ่มของประโยค
sentences_a = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
sentences_b = [ 'He plays guitar.' , 'A woman is making a photo.' ]
similarities = model . similarity ( sentences_a , sentences_b )หรือสร้างดัชนีสำหรับกลุ่มประโยคและ ค้นหา ระหว่างพวกเขา
sentences = [ 'A woman is reading.' , 'A man is playing a guitar.' ]
model . build_index ( sentences )
results = model . search ( "He plays guitar." ) นอกจากนี้เรายังสนับสนุน FAISS ซึ่งเป็นห้องสมุดการค้นหาที่มีความคล้ายคลึงกันที่มีประสิทธิภาพ เพียงติดตั้งแพ็คเกจต่อไปนี้คำแนะนำที่นี่และ simcse จะใช้ faiss โดยอัตโนมัติเพื่อการค้นหาที่มีประสิทธิภาพ
คำเตือน : เราพบว่า faiss ไม่สนับสนุน Nvidia Ampere GPU (3090 และ A100) ในกรณีนี้คุณควรเปลี่ยนเป็น GPU อื่น ๆ หรือติดตั้งแพ็คเกจ faiss เวอร์ชัน CPU
นอกจากนี้เรายังมีเว็บไซต์สาธิตที่ง่ายต่อการสร้างเพื่อแสดงว่า Simcse สามารถใช้ในการดึงประโยคได้อย่างไร รหัสขึ้นอยู่กับ repo และการสาธิตของ Densephrases (ขอบคุณผู้เขียน Densephrases)
รุ่นที่ปล่อยออกมาของเรามีการระบุไว้ดังต่อไปนี้ คุณสามารถนำเข้าโมเดลเหล่านี้ได้โดยใช้แพ็คเกจ simcse หรือใช้หม้อแปลงของ HuggingFace
| แบบอย่าง | avg. STS |
|---|---|
| Princeton-NLP/Unsup-Simcse-Bert-Base-uncased | 76.25 |
| Princeton-NLP/Unsup-Simcse-Bert-Large-uncased | 78.41 |
| Princeton-NLP/Unsup-Simcse-Roberta-base | 76.57 |
| Princeton-NLP/Unsup-Simcse-Roberta-Large | 78.90 |
| Princeton-NLP/SUP-SIMCSE-BERT-BASE-uncased | 81.57 |
| Princeton-NLP/SUP-SIMCSE-BERT-LARGE-ONCASED | 82.21 |
| Princeton-NLP/SUP-SIMCSE-ROBERTA-BASE | 82.52 |
| Princeton-NLP/SUP-Simcse-Roberta-Large | 83.76 |
โปรดทราบว่าผลลัพธ์จะดีกว่าที่เราได้รายงานไว้ในกระดาษเวอร์ชันปัจจุบันเล็กน้อยหลังจากใช้ชุดพารามิเตอร์ชุดใหม่ (สำหรับพารามิเตอร์ hyperparamters ให้ดูส่วนการฝึกอบรม)
กฎการตั้งชื่อ : unsup และ sup เป็นตัวแทนของ "ไม่ได้รับการดูแล" (ได้รับการฝึกฝนเกี่ยวกับ Wikipedia Corpus) และ "ภายใต้การดูแล" (ได้รับการฝึกฝนเกี่ยวกับชุดข้อมูล NLI) ตามลำดับ
นอกเหนือจากการใช้เครื่องมือฝังประโยคที่ให้มาของเราแล้วคุณยังสามารถนำเข้าโมเดลของเราได้อย่างง่ายดายด้วย transformers ของ HuggingFace:
import torch
from scipy . spatial . distance import cosine
from transformers import AutoModel , AutoTokenizer
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
model = AutoModel . from_pretrained ( "princeton-nlp/sup-simcse-bert-base-uncased" )
# Tokenize input texts
texts = [
"There's a kid on a skateboard." ,
"A kid is skateboarding." ,
"A kid is inside the house."
]
inputs = tokenizer ( texts , padding = True , truncation = True , return_tensors = "pt" )
# Get the embeddings
with torch . no_grad ():
embeddings = model ( ** inputs , output_hidden_states = True , return_dict = True ). pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine ( embeddings [ 0 ], embeddings [ 1 ])
cosine_sim_0_2 = 1 - cosine ( embeddings [ 0 ], embeddings [ 2 ])
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 1 ], cosine_sim_0_1 ))
print ( "Cosine similarity between " %s " and " %s " is: %.3f" % ( texts [ 0 ], texts [ 2 ], cosine_sim_0_2 )) หากคุณพบปัญหาใด ๆ เมื่อโหลดโมเดลโดยตรงโดย API ของ HuggingFace คุณยังสามารถดาวน์โหลดโมเดลด้วยตนเองจากตารางด้านบนและใช้ model = AutoModel.from_pretrained({PATH TO THE DOWNLOAD MODEL})
ในส่วนต่อไปนี้เราอธิบายวิธีการฝึกอบรมโมเดล Simcse โดยใช้รหัสของเรา
ขั้นแรกให้ติดตั้ง Pytorch โดยทำตามคำแนะนำจากเว็บไซต์ทางการ หากต้องการทำซ้ำผลลัพธ์ของเราอย่างซื่อสัตย์โปรดใช้เวอร์ชัน 1.7.1 ที่ถูกต้องที่สอดคล้องกับแพลตฟอร์ม/รุ่น Cuda ของคุณ รุ่น Pytorch สูงกว่า 1.7.1 ควรใช้งานได้เช่นกัน ตัวอย่างเช่นหากคุณใช้ Linux และ CUDA11 (วิธีการตรวจสอบเวอร์ชัน CUDA) ให้ติดตั้ง pytorch ตามคำสั่งต่อไปนี้
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html หากคุณใช้ cuda <11 หรือ CPU แทนให้ติดตั้ง pytorch โดยคำสั่งต่อไปนี้
pip install torch==1.7.1จากนั้นเรียกใช้สคริปต์ต่อไปนี้เพื่อติดตั้งการพึ่งพาที่เหลืออยู่
pip install -r requirements.txtรหัสการประเมินผลของเราสำหรับการฝังประโยคนั้นขึ้นอยู่กับรุ่นที่แก้ไขของ SentEval มันประเมินประโยคฝังตัวในงานความคล้ายคลึงกันของข้อความความหมาย (STS) และงานการถ่ายโอนปลายน้ำ สำหรับงาน STS การประเมินผลของเราใช้การตั้งค่า "ทั้งหมด" และรายงานความสัมพันธ์ของ Spearman ดูบทความของเรา (ภาคผนวก B) สำหรับรายละเอียดการประเมินผล
ก่อนการประเมินผลโปรดดาวน์โหลดชุดข้อมูลการประเมินผลโดยเรียกใช้
cd SentEval/data/downstream/
bash download_dataset.sh จากนั้นกลับมาที่ไดเรกทอรีรากคุณสามารถประเมินโมเดลที่ผ่านการฝึกอบรมมาก่อน transformers โดยใช้รหัสการประเมินของเรา ตัวอย่างเช่น,
python evaluation.py
--model_name_or_path princeton-nlp/sup-simcse-bert-base-uncased
--pooler cls
--task_set sts
--mode testซึ่งคาดว่าจะส่งออกผลลัพธ์ในรูปแบบตาราง:
------ test ------
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 75.30 | 84.67 | 80.19 | 85.40 | 80.82 | 84.26 | 80.39 | 81.58 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
อาร์กิวเมนต์สำหรับสคริปต์การประเมินมีดังนี้
--model_name_or_path : ชื่อหรือเส้นทางของจุดตรวจสอบที่ได้รับการฝึก transformers ล่วงหน้า คุณสามารถใช้โมเดลโดยตรงในตารางด้านบนเช่น princeton-nlp/sup-simcse-bert-base-uncased--pooler : วิธีการรวม ตอนนี้เราสนับสนุนcls (ค่าเริ่มต้น): ใช้การเป็นตัวแทนของโทเค็น [CLS] เลเยอร์การเปิดใช้งานเชิงเส้น+จะถูกนำไปใช้หลังจากการเป็นตัวแทน (อยู่ในการใช้งาน BERT มาตรฐาน) หากคุณใช้ SimcSe ภายใต้การดูแล คุณควรใช้ตัวเลือกนี้cls_before_pooler : ใช้การเป็นตัวแทนของโทเค็น [CLS] โดยไม่ต้องเปิดใช้งานเชิงเส้นเพิ่มขึ้น หากคุณใช้ Simcse ที่ไม่ได้รับการดูแล คุณควรใช้ตัวเลือกนี้avg : การฝังเฉลี่ยของเลเยอร์สุดท้าย หากคุณใช้จุดตรวจของ Sbert/Sroberta (กระดาษ) คุณควรใช้ตัวเลือกนี้avg_top2 : การฝังค่าเฉลี่ยของสองชั้นสุดท้ายavg_first_last : การฝังค่าเฉลี่ยของชั้นแรกและชั้นสุดท้าย หากคุณใช้ Vanilla Bert หรือ Roberta สิ่งนี้ใช้งานได้ดีที่สุด โปรดทราบว่าในกระดาษเรารายงานค่าเฉลี่ยของเลเยอร์สุดท้ายและการฝังคำคงที่ เราแก้ไขสิ่งนี้ให้เป็นค่าเฉลี่ยของชั้นสุดท้ายและครั้งแรกและนำไปสู่ประสิทธิภาพที่ดีขึ้น ดูปัญหานี้สำหรับการสนทนาโดยละเอียด--mode : โหมดการประเมินผลtest (ค่าเริ่มต้น): โหมดทดสอบเริ่มต้น ในการทำซ้ำผลลัพธ์ของเราอย่างซื่อสัตย์คุณควรใช้ตัวเลือกนี้dev : รายงานผลการพัฒนาชุดผลลัพธ์ โปรดทราบว่าในงาน STS มีเพียง STS-B และ SICK-R เท่านั้นที่มีชุดพัฒนาดังนั้นเราจึงรายงานตัวเลขของพวกเขาเท่านั้น นอกจากนี้ยังใช้โหมดที่รวดเร็วสำหรับงานถ่ายโอนดังนั้นเวลาทำงานจะสั้นกว่าโหมด test มาก (แม้ว่าตัวเลขจะต่ำกว่าเล็กน้อย)fasttest : มันเหมือนกับ test แต่ด้วยโหมดที่รวดเร็วดังนั้นเวลาทำงานจะสั้นกว่ามาก แต่ตัวเลขที่รายงานอาจต่ำกว่า (สำหรับงานถ่ายโอนเท่านั้น)--task_set : ชุดของงานที่จะประเมิน (ถ้าตั้งค่ามันจะแทนที่ --tasks )sts (ค่าเริ่มต้น): ประเมินผลงาน STS รวมถึง STS 12~16 , STS-B และ SICK-R นี่คือชุดงานที่ใช้กันมากที่สุดเพื่อประเมินคุณภาพของการฝังประโยคtransfer : ประเมินผลงานการถ่ายโอนfull : ประเมินทั้ง STS และงานถ่ายโอนna : ตั้งค่างานด้วยตนเองโดย --tasks--tasks : ระบุชุดข้อมูลใดที่จะประเมิน จะถูกแทนที่ถ้า --task_set ไม่ใช่ na ดูรหัสสำหรับรายการงานเต็มรูปแบบข้อมูล
สำหรับ Simcse ที่ไม่ได้รับการดูแลเราได้ตัวอย่าง 1 ล้านประโยคจากภาษาอังกฤษวิกิพีเดีย สำหรับ SIMCSE ภายใต้การดูแลเราใช้ชุดข้อมูล SNLI และ MNLI คุณสามารถเรียกใช้ data/download_wiki.sh และ data/download_nli.sh เพื่อดาวน์โหลดชุดข้อมูลสองชุด
สคริปต์การฝึกอบรม
เราให้ตัวอย่างสคริปต์การฝึกอบรมสำหรับ SIMCSE ที่ไม่ได้รับการดูแลและดูแล ใน run_unsup_example.sh เราให้ตัวอย่าง GPU (หรือ CPU) เดี่ยวสำหรับรุ่นที่ไม่ได้รับการดูแลและใน run_sup_example.sh เราให้ตัวอย่าง หลาย GPU สำหรับเวอร์ชันภายใต้การดูแล สคริปต์ทั้งสองเรียก train.py สำหรับการฝึกอบรม เราอธิบายข้อโต้แย้งดังต่อไปนี้:
--train_file : เส้นทางไฟล์การฝึกอบรม เรารองรับไฟล์ "txt" (หนึ่งบรรทัดสำหรับหนึ่งประโยค) และ "CSV" ไฟล์ (2 คอลัมน์: ข้อมูลจับคู่ที่ไม่มีค่าลบอย่างหนัก 3 คอลัมน์: จับคู่ข้อมูลที่มีอินสแตนซ์เชิงลบที่สอดคล้องกันหนึ่งอัน) คุณสามารถใช้ข้อมูล Wikipedia หรือ NLI ที่ให้มาของเราหรือคุณสามารถใช้ข้อมูลของคุณเองในรูปแบบเดียวกัน--model_name_or_path : จุดตรวจสอบที่ผ่านการฝึกอบรมมาก่อนจะเริ่มต้นด้วย สำหรับตอนนี้เรารองรับโมเดลที่ใช้ Bert ( bert-base-uncased , bert-large-uncased ฯลฯ ) และโมเดลที่ใช้ Roberta ( RoBERTa-base , RoBERTa-large ฯลฯ )--temp : อุณหภูมิสำหรับการสูญเสียความคมชัด--pooler_type : วิธีการรวม มันเหมือนกับ --pooler_type ในส่วนการประเมิน--mlp_only_train : เราพบว่าสำหรับ simcse ที่ไม่ได้รับการดูแลมันทำงานได้ดีกว่าในการฝึกอบรมแบบจำลองด้วยเลเยอร์ MLP แต่ทดสอบแบบจำลองโดยไม่ต้องใช้ คุณควรใช้อาร์กิวเมนต์นี้เมื่อการฝึกอบรมแบบจำลอง SimcSe ที่ไม่ได้รับการดูแล--hard_negative_weight : หากใช้ Hard Negative (เช่นมี 3 คอลัมน์ในไฟล์การฝึกอบรม) นี่คือลอการิทึมของน้ำหนัก ตัวอย่างเช่นหากน้ำหนักคือ 1 ดังนั้นอาร์กิวเมนต์นี้ควรตั้งค่าเป็น 0 (ค่าเริ่มต้น)--do_mlm : จะใช้วัตถุประสงค์เสริม MLM หรือไม่ ถ้าเป็นจริง:--mlm_weight : น้ำหนักสำหรับวัตถุประสงค์ MLM--mlm_probability : อัตราการปิดบังสำหรับวัตถุประสงค์ MLM ข้อโต้แย้งอื่น ๆ ทั้งหมดคือข้อโต้แย้งการฝึกอบรม transformers ของ HuggingFace Standard อาร์กิวเมนต์บางส่วนที่ใช้บ่อยคือ: --output_dir , --learning_rate , --per_device_train_batch_size ในสคริปต์ตัวอย่างของเราเรายังตั้งค่าเพื่อประเมินโมเดลในชุดการพัฒนา STS-B (จำเป็นต้องดาวน์โหลดชุดข้อมูลตามส่วนการประเมินผล) และบันทึกจุดตรวจสอบที่ดีที่สุด
สำหรับผลลัพธ์ในกระดาษเราใช้ NVIDIA 3090 GPU กับ CUDA 11 การใช้อุปกรณ์ประเภทต่าง ๆ หรือซอฟต์แวร์ CUDA/ซอฟต์แวร์อื่น ๆ รุ่นต่าง ๆ อาจนำไปสู่ประสิทธิภาพที่แตกต่างกันเล็กน้อย
พารามิเตอร์
เราใช้ hyperparamters ต่อไปนี้สำหรับการฝึกอบรม simcse:
| unsup. เบิร์ต | unsup. โรเบอร์ต้า | จีบ. | |
|---|---|---|---|
| ขนาดแบทช์ | 64 | 512 | 512 |
| อัตราการเรียนรู้ (ฐาน) | 3e-5 | 1E-5 | 5E-5 |
| อัตราการเรียนรู้ (ใหญ่) | 1E-5 | 3e-5 | 1E-5 |
แปลงรุ่น
จุดตรวจที่บันทึกไว้ของเรานั้นแตกต่างจากจุดตรวจสอบที่ผ่านการฝึกอบรมมาก่อนของ HuggingFace เล็กน้อย เรียกใช้ python simcse_to_huggingface.py --path {PATH_TO_CHECKPOINT_FOLDER} เพื่อแปลง หลังจากนั้นคุณสามารถประเมินได้ด้วยรหัสการประเมินผลของเราหรือใช้โดยตรงจากกล่อง
หากคุณมีคำถามใด ๆ ที่เกี่ยวข้องกับรหัสหรือกระดาษอย่าลังเลที่จะส่งอีเมล tianyu ( [email protected] ) และ Xingcheng ( [email protected] ) หากคุณพบปัญหาใด ๆ เมื่อใช้รหัสหรือต้องการรายงานข้อบกพร่องคุณสามารถเปิดปัญหาได้ โปรดพยายามระบุปัญหาพร้อมรายละเอียดเพื่อให้เราสามารถช่วยคุณได้ดีขึ้นและเร็วขึ้น!
โปรดอ้างอิงกระดาษของเราหากคุณใช้ Simcse ในงานของคุณ:
@inproceedings { gao2021simcse ,
title = { {SimCSE}: Simple Contrastive Learning of Sentence Embeddings } ,
author = { Gao, Tianyu and Yao, Xingcheng and Chen, Danqi } ,
booktitle = { Empirical Methods in Natural Language Processing (EMNLP) } ,
year = { 2021 }
}เราขอขอบคุณความพยายามของชุมชนในการขยาย Simcse!
sentence-transformers สำหรับ SIMCSE

