Text Summarization Repo
1.0.0
在NLP中,它是一個累積與文本摘要字段相關的質量數據的空間。我想成為那些對文本摘要感興趣的人的好指南。
首先,我們了解文本總結的詳細主題是組成的,並查看引導該領域的主要論文。從那以後,我們列出了創建直接文本摘要模型所需的代碼,數據集和前才木模型。
文本摘要介紹
文件
資源
其他的
Berry,Dumais和O'Brien(1995)定義了文本摘要如下:
文本摘要是從文本中提取最重要信息以產生特定任務和用戶的過程
這是一個僅在單詞中給出的文本中僅完善重要信息的過程。在這裡,精煉的表達和重要的重要性是一種相當抽象的主觀表達,因此我個人想將其定義如下。
f(text) = comprehensible information
換句話說,文本摘要是將原始文本轉換為簡單而有價值的信息。很難一目了然地看到人類的文本信息,這些信息長期或分為幾個文檔。有時您不知道很多專業條款。在很好地反映原始文本的同時,將這些文本反映成一種簡單而簡單的理解形式是非常有價值的。當然,真正值得的以及如何更改它會因總結或個人品味的目的而有所不同。
從這個角度來看,可以說文本不僅概述了創建文本的任務,例如會議記錄,報紙工程師的標題,紙張摘要和簡歷,以及將文本轉換為圖形或圖像的任務。當然,由於它不僅是摘要,因此是文本摘要,因此摘要的來源以文本形式有限。 (摘要的摘要是因為它不僅可以是文本或視頻以及文本。
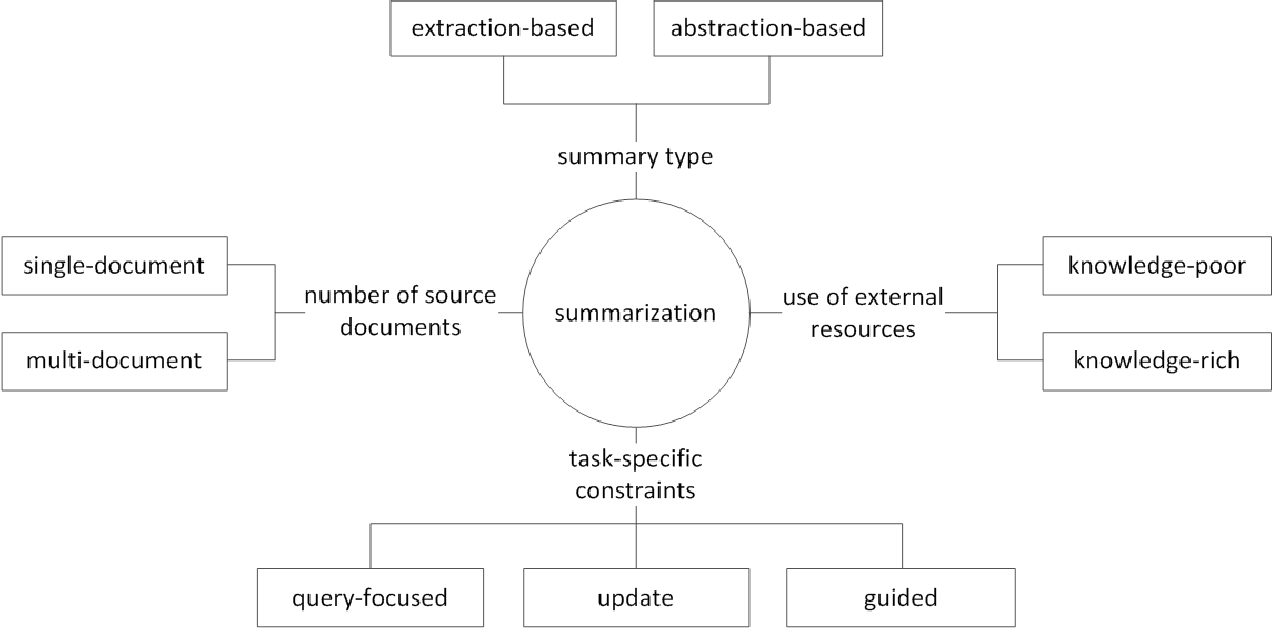
通常,根據它們如何生成摘要,將文本摘要任務分為提取性摘要(以下稱為ext)和抽象性摘要(ABS)。 (古迪瓦達,2018年)
提取方法在原始文本中選擇現有單詞,短語或句子的子集以形成摘要。相比之下,抽象方法首先構建了內部語義表示和使用自然語言世代技術。
EXT通常會得分句子的重要性,然後選擇並結合起來以創建摘要。這類似於在閱讀時繪製熒光筆的任務。另一方面, ABS基於原始文本,但是一種生成新文本的NLG(自然語言生成)方法。由於原始文本中的文本,Ext不太可能包括限於表達式的表達式。另一方面,ABS具有創建前所未有的表達式的可能性,因為它必須在模型中創建一個新文本,但是它具有更靈活的方法。
此外,根據原始文本的數量,根據單/多文檔摘要的文本形式,關鍵字/句子摘要,根據摘要過程中使用了多少外部信息,根據摘要過程,例如摘要等各種區別。
(G。Sizov(2010)。基於提取的自動摘要:摘要技術的理論和經驗研究
讓我們看一下文本摘要領域的主要研究主題,並思考該領域的哪種挑戰。
多 /長文檔摘要
如前所述,摘要任務是將不可理解的文本更改為可理解的信息。因此,原始文本或多個來源文檔的摘要越長,不是一個文檔,摘要的實用性越多。問題在於,同時,摘要的困難也增加了。
因此,原始文本越長,計算複雜性的增加就越快。在最近的基於神經網絡的方法(包括變壓器)中,這比過去的統計方法(例如Textrank)更為關鍵問題。其次,原始文本的時間越長,內容核心的核心越多,即噪聲。確定什麼是噪音和內容豐富的內容並不容易。最後,長文本和各種來源同時具有各種觀點和內容,因此很難創建一個涵蓋它的摘要。
多文檔摘要(MDS)
MDS是多個文件的摘要。乍一看,要總結各種作者不同觀點的文章,而不是總結一個文檔,該文檔從一致的趨勢和觀點中描述一個主題。當然,即使在MDS的情況下,它通常也基於涉及類似主題的同一集群文檔,但是在許多文檔中識別重要信息並過濾了Outluge信息並不容易。
總結某些產品的評論的任務是最容易想到的MD的一個例子。該任務通常稱為意見摘要,其特徵是短期長度和主觀性。創建Wiki文檔的工作也可以視為MDS。劉等。 (2018年)是Wiki文檔上網站文本的原始文本,這是原始文本,這被認為是摘要,它創建了Wiki創建模型。
長文件摘要
劉等。 (2018)是一種接受長文本作為輸入,創建外推摘要,僅使用重要句子並將其用作模型輸入的統計方法。另外,為了減少變壓器計算量,輸入分為塊單元,此時,1D卷積使用的方法使用了減少單個注意力鍵和值的數量。 Big Bird(2020)論文引入了稀疏的賦形機制(線性),而不是所有現有單詞的組合以減少變壓器的計算。結果,相同的性能硬件總結了長達八倍的長度。
另一方面,Gidiotis&Tsoumakas(2020)試圖接近分界線,這並不能一次解決長期摘要問題,並將其變成幾個小文本摘要。通過將原始文本和目標摘要更改為多個小較小的源目標對來訓練模型。在推論中,我們通過此模型匯總了部分摘要輸出,以創建一個完整的摘要。
績效提高
您如何創建更好的摘要?
轉移學習
最近,在NLP中使用預訓練模型幾乎已成為默認設置。那麼,我們應該必須創建哪種結構來創建一個可以在文本摘要中顯示出更好性能的預先模型?我應該有什麼對象?
在Pegasus(2020)中,GSG(GAP句子生成)方法選擇了一個基於Rouge分數認為重要的句子,假定與文本摘要過程更相似,並且反對意見將顯示更高的性能。當前的SOTA模型BART(2020)(雙向和自動回歸變壓器)以自動編碼器的形式學習,該自動編碼器將噪聲添加到某些輸入文本並將其恢復為原始文本。
知識增強的文本生成
在文本到文本任務中,通常很難單獨使用原始文本生成所需的輸出。因此,通過為模型以及原始文本提供各種知識,試圖提高性能。這些知識範圍的來源或提供在各種類型的關鍵字,主題,語言特徵,知識庫,知識範圍和接地文本方面有所不同。
例如,TAN,QIN,XING和HU(2020)提供了一個通用的峰頂數據集來轉換多個基於方面的摘要,並提供了與給定方面相關的更多豐富信息。使用Wikipedia。如果您想進一步了解更多,Yu等人。閱讀(2020)撰寫的調查文件。
後編輯圓環
立即創建一個好的摘要會很高興,但這並不容易。那麼,為什麼不創建摘要,然後以各種標准進行審查和修改呢?
例如,CAO,Dong,Wu和Cheung(2020)提出了一種通過在生成的摘要中應用預先的神經校正器模型來減少事實錯誤的方法。
此外,還有許多嘗試應用**圖神經網絡(GNN)**的嘗試,最近一直受到很多關注。
數據稀缺問題
文本摘要是一項需要大量時間的任務,對於人類而言,這並不容易。因此,與其他任務相比,創建標記的數據集的成本相對較大,當然,缺乏培訓數據。
除了使用先前提到的預處理模型的轉移學習方法外,我們還以無監督的學習或強化學習方法學習或嘗試了幾次學習方法。
自然,製作良好的摘要數據也是一個非常重要的研究主題。特別是,當前許多相關的數據集都以英語的新聞類型偏見。結果,正在創建多語言數據集,例如Wikilingua和Mlsum。有關更多信息,請查看MLSUM:多語言摘要語料庫。
公制/評估方法
我早些時候寫了一個“好”的表情。什麼是“好的摘要”? Brazinskas,Lapata和Titov(2020)根據良好摘要的判斷使用以下五件事。
問題在於測量這些部分並不容易。文本摘要中最常見的性能測量指標是胭脂分數。 Rouge分數中有各種各樣的變體,但基本上是“生成的摘要和參考摘要的單詞如何?”這意味著相似,但是如果您的形式不同或單詞訂單更改,即使是更好的摘要,也可以獲得較低的分數。特別是,試圖提高胭脂分數,可能會損害摘要的表達多樣性。這就是為什麼許多論文以昂貴的錢和胭脂分數提供其他人類評估結果的原因。
Lee等。 (2020)提出了一個rdass(參考和文檔意識語義分數),這與文本和參考摘要的相似之處,然後由基於向量的類似道路進行衡量。預計這種方法將提高韓國語言評估的準確性,該方法結合了單詞和各種形態,以表達各種含義和語法功能。 Kryściński,McCann,Xiong和Socher(2020)提出了評估事實一致性的弱監督,基於模型的方法。
可控文本生成
關於給定文件只有一個最好的摘要嗎?不會。具有不同傾向的人可能更喜歡同一文本的不同摘要文本。即使您是同一個人,您想要的摘要也將取決於總結或情況的目的。這種根據用戶指定的條件將輸出調整為所需形式的方法稱為可控文本生成。與通用摘要相比,您可以提供個性化的摘要,該摘要為給定文檔創建相同的摘要。
生成的摘要不僅應該易於理解和價值,而且還與您在一起的條件密切相關。
f(text, condition ) = comprehensible information that meets the given conditions可理解信息
我可以在摘要模型中添加什麼條件?您如何創建適合該條件的摘要?
基於方面的摘要
總結AirPod用戶評論時,您可能需要通過將聲音質量,電池和設計分配來匯總每一方面。或者,您可能想調整文章中的寫作風格或情感。在此原始文本中,僅總結與特定方面或特徵有關的信息的工作稱為基於方面的摘要。
以前,僅在主要用於模型學習的預定義方面起作用的模型現在試圖允許進行任意方面的推理,而這些方面並未用於學習,例如TAN,QIN,QIN,XING和HU(2020)。
查詢集中摘要(QFS)
如果條件是查詢,則稱為QFS。查詢主要是自然語言,因此主要的任務是如何很好地執行這些各種表達方式並與原始文本匹配。它與我們知道的質量檢查系統非常相似。
更新摘要
人類是繼續學習和成長的動物。因此,今天的某些信息的價值可能與一周後的價值完全不同。我已經經歷過的文檔中內容的價值將被降低,尚未經歷的新內容仍然具有很高的價值。從這個角度來看,稱為“更新摘要” ,以創建與用戶以前經歷的文檔內容相似的新內容的新摘要。
Ctrlsum使用文本採用各種關鍵字或描述性提示,以調整生成的摘要。這是一個更通用的可使用的可控文本摘要模型,因為它顯示出與在培訓階段未明確學習的關鍵字或提示所控制的結果相同的結果。您可以通過Koh Hyun -Woong的摘要庫輕鬆使用它。
除此之外,還嘗試創建適合對話摘要的摘要模型的各種嘗試,而不是**模型輕量級等典型的DL主題,以及對話的摘要,而不是諸如新聞或Wikipedia之類的結構化文本。有主題。
如果您知道文本摘要字段中的以下內容,則可以更輕鬆地學習。
了解NLP基本概念
變壓器/BERT結構和訓練前客觀理解
許多最新的NLP論文都是基於幾種預先了解的模型,包括基於變形金剛的Bert,以及Roberta和T5,這些模型是該BERT的變體。因此,如果您了解他們的示意性結構和預訓練目標,那麼這對於閱讀或實施論文是一個很大的幫助。
文本摘要基本概念
圖神經網絡(GNN)
機器翻譯(MT)
MT是自SEQ2SEQ出現以來NLP字段中最活躍的任務之一。如果您將摘要過程視為將一個文本轉換為不同類型文本的過程,則可以將其視為一種MT,那麼與MT相關的研究和想法很可能在摘要字段中藉用或應用。
| 年 | 紙 | 關鍵字 |
|---|---|---|
| 2004 模型 | Textrank :將命令納入文本 R. Mihalcea,P。 Tarau 它是提取領域的經典,仍然是活躍的。假設文檔中的重要句子(IE,摘要中包含)是Pagerank算法,即Google搜索引擎的初始想法,假設它將與其他句子具有很高的典型性。每個句子都配置了句子級的加權圖,以計算文檔中的另一句話的相似性,並在摘要中包括此高權重句。 沒有單獨的學習數據,基於統計的無監督學習方法可以是合理的,並且算法清晰易於理解。 - [庫] Gensim.summarization(只有3.x版本。從版本4.x刪除),pytextrank - [理論/代碼] Lovit。使用文本trank和核心句子提取的關鍵字提取 | ext, 基於圖的(Pagerank), 無監督 |
| 2019 模型 | Bertsum :帶有預言編碼器(OfficeIAD)的文本摘要 Yang Liu,Mirella Lapata / Emnlp 2019 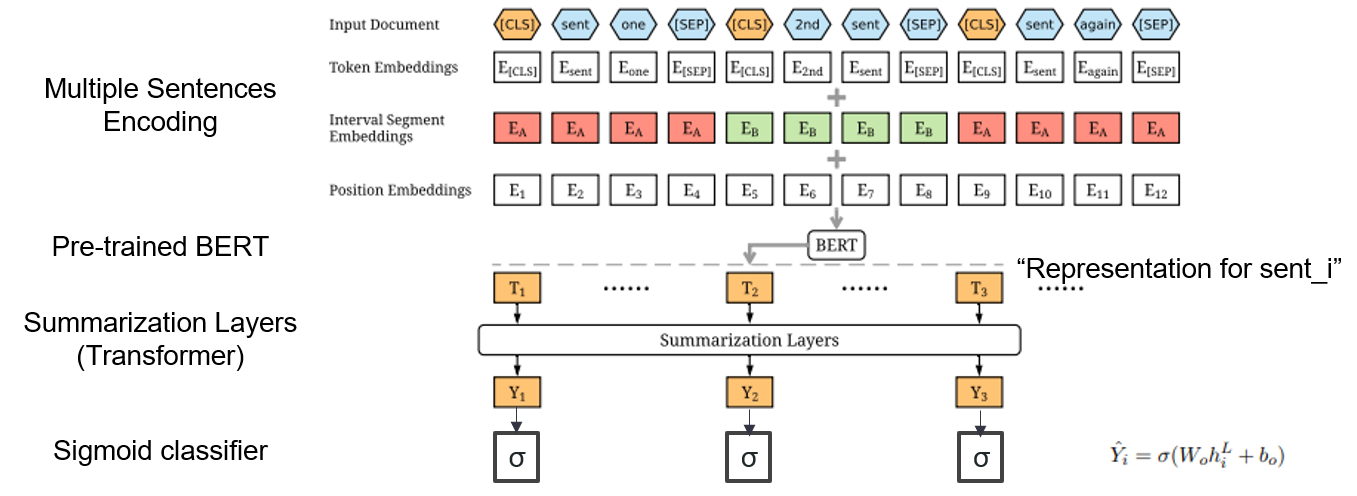 我如何在摘要中使用預訓練的BERT? 我如何在摘要中使用預訓練的BERT?Bertsum建議修改後的輸入嵌入,將[Cls]令牌插入每個句子的前面,並添加間隔段嵌入,以在一個輸入中添加多個句子。 EXT模型使用BERT上具有變壓器層的編碼器結構,ABS模型使用EXT模型上的6層變壓器解碼器的編碼器碼頭模型。 - [評論] Lee Jung -Hoon(Koreauniv DSBA) - [韓國人] Kobertsum | ext/abs, BERT+變壓器, 2階段的微調 |
| 2019 預訓練模型 | 巴特:自然語言生成,翻譯和理解的序列前訓練序列前訓練 Mike Lewis,Yinhan Liu,Naman Goyal,Marjan Ghazvininejad,Abdelrahman Mohamed,Omer Levy,Ves Stoyanov,Luke Zettlemoyer / ACL 2020 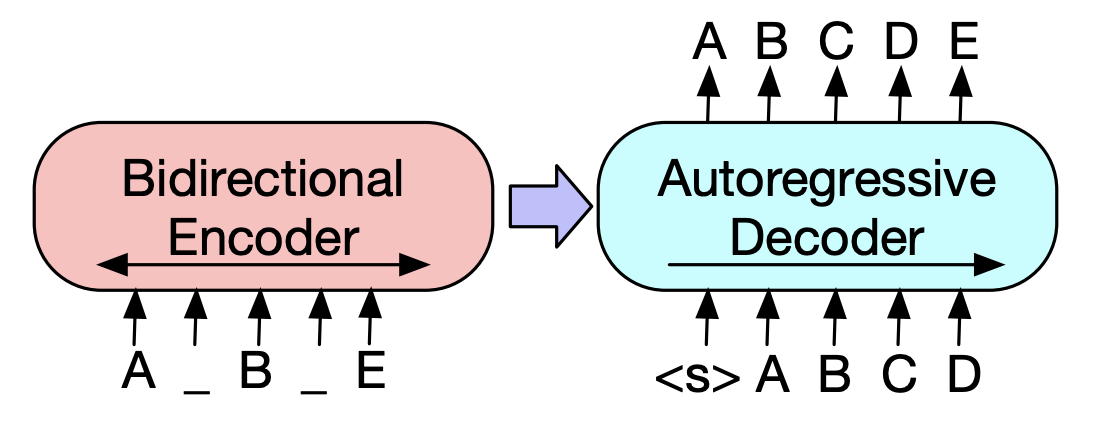 Bert是雙向編碼器,對生成任務較弱,而GPT的缺點是,它不會通過自動回歸模型獲得雙向信息。 Bert是雙向編碼器,對生成任務較弱,而GPT的缺點是,它不會通過自動回歸模型獲得雙向信息。BART具有將它們結合在一起的SEQ2SEQ形式,因此您可以在一個模型中嘗試各種否定的技術。結果,文本填充(將文本跨度更改為一個掩碼令牌),句子改組(隨機混合句子)顯示了超過摘要領域Ki Sota模型的性能。 - [韓語] SKT T3K。科巴特 - [評論] Jin Myung -Hoon_Video,lim Yeon -soo_ jiwung Hyun_撰寫 | 腹部, seq2seq, Denoising AutoCoder, 文字填充 |
| 2020 模型 | 火柴:提取摘要作為文本匹配(Office) 明·宗,李·劉,伊蘭·陳,王王,Xipeng Qiu,Xuanjing Huang / acl 2020 - [評論] Yoo Kyung(Koreauniv DSBA) | 分機 |
| 2020 技術 | 總結任何方面的文本:知識知識的弱監督方法(官方代碼) Bowen Tan,Lianhui Qin,Eric P. Xing,zhiting hu / emnlp 2020 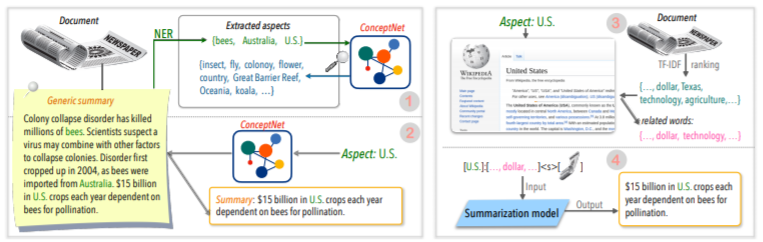 基於方面的摘要是一項不容易的任務,因為它僅在數據的預定方面運行,即使您學習了模型,也可以學到,2)缺乏多個基於方面的摘要數據。 本文利用外部知識來源解決此問題。 - 通過兩個步驟將通用摘要轉換為基於多個方面的摘要。首先,為了增加從通用摘要中提取的實體是種子,並從concepnet提取到其鄰居,並將每個實體視為一個方面。我們再次使用concepnet為每個方面創建psedo摘要。提取連接到Concepnet中相應方面的周圍實體,並僅提取一般摘要中包含它們的句子。這被認為是該實體(方面)的摘要。 - Wikipedia用於傳遞與模型給定方面相關的更多豐富信息。具體而言,在文檔中出現的單詞中,文檔中的TF-IDF分數很高,同時,與此同時,Wikipedia頁面中10個單詞的列表與該方面相對應,並與模型輸入相對應。 通過這種方式,使用較小的數據的任意方面也非常適合進行調整預先介紹模型(BART)。 | 基於方面的, 知識豐富 |
| 2020 審查 | 我們很快發短信摘要? Dandan Huang,Leyang Cui,Sen Yang,Guangsheng Bao,Kun Wang,Jun Xie,Yue Zhang / emnp 2020 除胭脂評分外,根據與準確性和流利度有關的8個指標(Polytope)評估了10個代表性摘要模型。總結結果, - 基於規則的傳統方法仍然有效作為基線。 在類似的設置下,EXT模型通常在忠實和事實矛盾方面表現出更好的表現。主要的缺點是提取模型的不可行性,而抽像模型的遺漏和內在幻覺。 - 除了重複問題之外,更複雜的結構(例如用於創建句子表示的變壓器)不是很有幫助。 - 副本(指針生成器)是一個複制的細節,它通過混合以及不准確性的固有來有效地解決了級別的重複問題。但是傾向於在一定程度上引起冗餘。 覆蓋範圍很大,這減少了重複錯誤(重複),但同時增加了添加和不准確的固有錯誤 - 雜交模型(在EXT之後是ABS)非常適合召回,但是不准確誤差可能存在問題,因為它通過一些原始文本(提取的片段)生成摘要。 與僅編碼器模型(bertsamextabs)相比,預訓練,尤其是編碼器模型(BART)在摘要中非常有效。這表明,對所有理解和創建的所有理解和創建對於內容選擇和組合非常有用。同時,儘管大多數ABS模型都集中在正面句子上,但Bart正在研究所有原始文本,這似乎是句子在預先介紹過程中的效果。 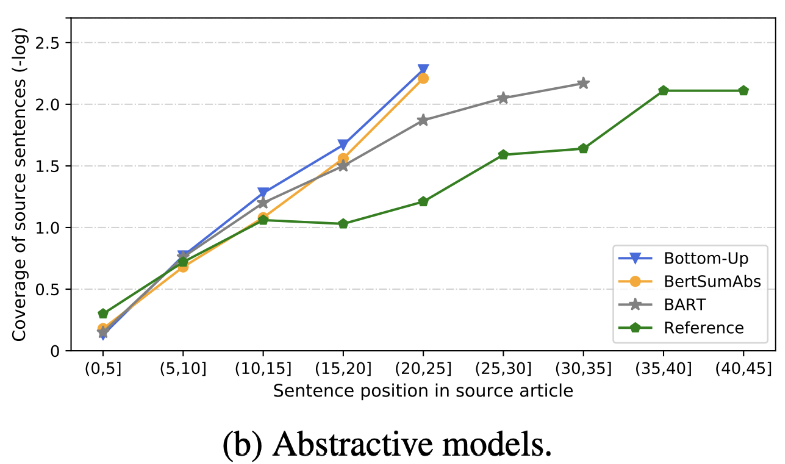 - [評論] Kim Han -Gil,Heo Hoon | 審查 |
| 2020 模型 | CTRLSUM :邁向通用可控文本摘要(官方代碼) Junxian He,WojciechKryściński,Bryan McCann,Nazneen Rajani,Caiming Xim CTRLSUM是一個可控的文本摘要模型,它允許您調整通過關鍵字或描述性提示生成的摘要語句。 培訓:為了通過修改一般摘要數據來創建一個基於關鍵字的可控制摘要數據集,請選擇與摘要最相似的子序列,並在此處提取關鍵字。將其放入文檔的輸入中,然後完成預啟動巴特。 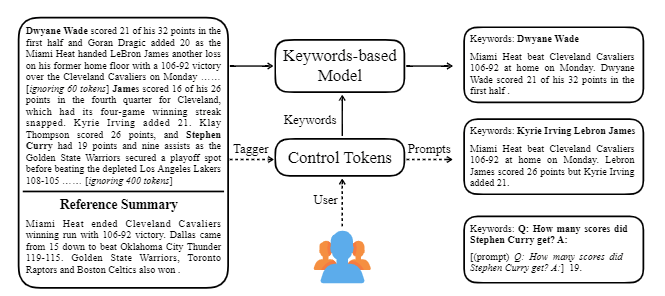 - 啟示:如下圖所示,您可以添加摘要的摘要,例如創建特定實體的摘要,調整摘要長度或對問題的回答。值得注意的是,它好像不是在建模階段明確學習此類提示一樣,但是它好像是在理解提示並產生摘要一樣起作用。類似於GPT-3。 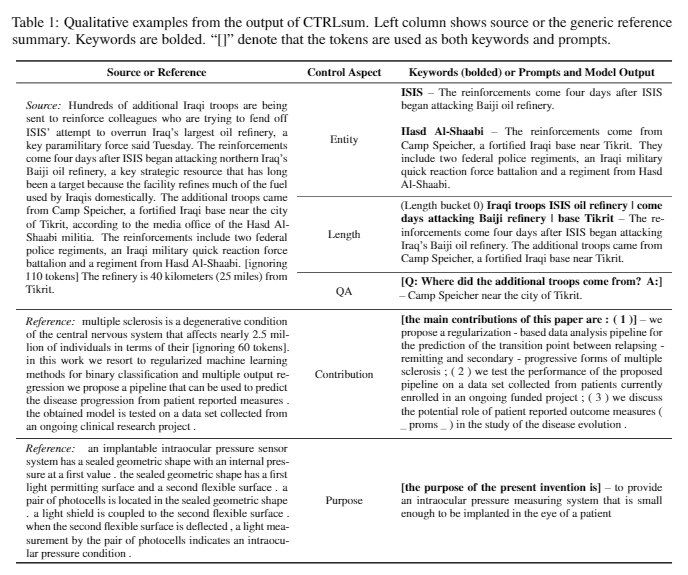 - [庫]基於可控摘要的ctrlsum的軟件包 | 可控, 巴特 |
紙摘要:有關文本摘要的最新論文
用代碼的論文:最新論文
EMNLP 2020論文 - 夏季化
實際上,我們總結了創建和練習摘要模型所需的代碼,數據和preitrain模型。它主要是韓國數據,對於與英語相關的材料,請參閱論文項目中每個論文的代碼部分。
下面使用的弱的含義如下。
w :單詞數的平均值; s :平均句子的平均值
示例) 13s/214w → 1s/26w意味著它提供了一個摘要文本,該文本由13個句子(平均214個單詞)和平均句子(平均26個單詞)組成。
abs摘要; ext :提取性摘要
| 數據集 | 域 /長度 | 體積 (一對) | 執照 |
|---|---|---|---|
| 每個人的單詞文件摘要 簡短新聞文字的標題,3句ABS和Ext Summay 每個人的所有單詞都與ID與報紙馬相結合,您可以獲得與字幕,媒體,日期和主題有關的其他信息。 | 消息 -origin→3s(ABS); 3s(ext) | 13,167 | 韓國國家學院 (個人合同) |
| AIHUB文檔摘要文本 報紙文章,貢獻,雜誌文章和法院審查的ABS和Ext Summay - [EDA]數據EDA筆記本 - 韓國文檔提取摘要摘要和創建摘要AI競賽(〜20.12.09) | - 報紙第300,000條,60,000款,10,000份雜誌,法院裁決30,000 13S/214W→1S/26W(ABS); 3S/55W(EXT) | 400,000 | aihub (個人合同) |
| aihub-summary 所有的ABS摘要和部分的學術論文和專利規格 | - 學術論文,專利規格 -origin→ABS | 350,000 | aihub (個人合同) |
| Aihub-Book數據摘要 關於各種主題的原始書籍的ABS摘要 | - 長期,生命,稅收,環境,社區發展,貿易,經濟,勞動等。 -300-1000個字符→ABS | 200,000 | aihub (個人合同) |
| SAE4K | 50,000 | cc-by-sa-4.0 | |
| 科幻-News-SUM-KR-50 | 新聞(IT/科學) | 50 | 麻省理工學院 |
| Wikilingua :多語言抽象摘要數據集(2020) 根據手動網站Wikihow,韓語和英語等18種語言 - 紙,合作筆記本 | - 如何進行文檔 -391W→39W | 12,189 (Kor總共770,087) | 2020年, CC BY-NC-SA 3.0 |
| 數據集 | 域 /長度 | 體積 | 執照 |
|---|---|---|---|
| Scisummnet (紙) 為ACL(NLP)研究提供了三種類型的摘要 -cl-scisumm 2019-task2(回購,紙) -cl-scisumm @ emnlp 2020-task2(repo) | - 研究論文 (計算語言學家,NLP) 4,417W→110W(紙張摘要); 2s(引用); 151W(ABS) | 1,000(ABS/ EXT) | CC BY-SA 4.0 |
| Longsumm 相對較長的摘要(相關博客文章的ABS,相關會議視頻談話) -Longsumm 2020@Emnlp 2020 -longsumm 2021@ naacl 2021 | - 研究論文(NLP,ML) -origin→100s/1,500W(ABS); 30S/ 990W(EXT) | 700(ABS) + 1,705(EXT) | 歸因非商業共享4.0 |
| cl-laysumm 為NLP和ML字段的非專業人士提供簡單的層。 -cl-laysumm @ emnlp 2020 | - 研究論文(癲癇,考古,材料工程) -origin→70〜100W | 600(ABS) | 個人協議需求(發送電子郵件至[email protected]) |
| 全球聲音:自動新聞摘要中的邊界(2019年) -紙 | - 消息 -359W→51W | ||
| MLSUM :多語言摘要語料庫 與CNN/Daily Mail數據集類似,新聞文章中的亮點/描述被認為是英語,法語,德國,西班牙語,俄語,土耳其構建數據集的摘要和摘要 - 紙,使用(huggingface) | - 消息 -790W→56W (基礎) | 15m(ABS) | 僅非商業研究目的 |
| 模型 | 預訓練 | 用法 | 執照 |
|---|---|---|---|
| 伯特(多語言) BERT基本(110m參數) | -Wikipedia(多語言) - 單詞。 -110k共享詞彙 | BERT-Base, Multilingual Cased推薦版本( --do_lower_case=false選項)-tensorflow | Google (Apache 2.0) |
| 科伯特 BERT基本(9200萬參數) | -Wikipedia(5m句),新聞(20m句) - 句子 8,002個詞彙(沒有未使用的令牌) | -Pytorch - 通過Kobert-Transformers(Monologg),Distilkobert可用,可作為Huggingface Transformers庫可用 | Sktbrain (Apache-2.0) |
| 科伯特 伯特基 | -News(10年),Wikipedia等23GB -Ertri形態分析API / Wordpiece(分別提供了兩個版本) -30,349個詞彙 拉丁字母:外殼 - [簡介] Lim Jun(ETRI)。 NLU Tech與Korbert的談話 | -Pytorch,張量 | etri (個人合同) |
| Kcbert Bert-Base/大 | -Daver News評論(12.5GB,890萬句) (19.01.01〜20.06.15在文章和評論中的文章中評論) -tokenizers bertwordpieCeTokenizer -30,000個詞彙 | Beomi (麻省理工學院) | |
| 科巴特 巴特(124m) | -Wikipedia(5M)和其他(新聞,書籍,每個人的話(對話,新聞,...),Cheong Wa dae National請願書,等等。 -tockenizer的角色BPE令牌 30,000個詞彙(包括) - [示例] Seujung。 kobart-summarization(代碼,演示) | - 夏季任務專業 - 手持式變形金剛庫支持 -Pytorch | SKT T3K (修改後的MIT) |
| 年 | 紙 |
|---|---|
| 2018 | 基於神經網絡的摘要方法的調查 Y. Dong |
| 2020 | 回顧自動文本摘要技術和方法 Widyassari,AP,Rustad,S.,Shidik,GF,Noersasongko,E.,Syukur,A。 ,&Affandy,A。 |
| 2020 | 知識增強文本生成的調查 Wenhao Yu,Chenguang Zhu,Zaitang Li,Zhiting Hu,Qingyun Wang,Heng JI,Meng Jiang |
| 年 | 紙 | 關鍵字 |
|---|---|---|
| 1958年 | 自動創建文學摘要 luhn | Gen-ex |
| 2000 | 基於統計翻譯的標題生成 M. Banko,Vo Mittal和MJ Witbrock | Gen-abs |
| 2004 | Lexrank :基於圖的詞彙中心性作為文本摘要中的顯著性 G. Erkan和Dradev, | Gen-ex |
| 2005 | 基於句子提取的單文件摘要 J. Jagadeesh,P。 Pingali和V. Varma | Gen-ex |
| 2010 | 與準同步語法的產生一代 K. Woodsend,Y. Feng和M. Lapata, | Gen-ex |
| 2011 | 使用潛在語義分析的文本摘要 Mg Ozsoy,Fn Alpaslan和I. Cicekli | Gen-ex |
| 年 | 紙 | 關鍵字 |
|---|---|---|
| 2014 | 在使用非常大的目標詞彙進行神經機器翻譯 S. Jean,K。 Cho,R。 Memisevic和Yoshua Bengio | Gen-abs |
| 2015 模型 | NAMAS :抽象摘要的神經註意力模型(代碼) Am Rush,S。 Chopra和J. Weston / Emnlp 2015 為了超越現有的句子選擇和組合方法,我們在FLAG SEQ2SEQ中介紹了目標對源的關注,以創建抽象性摘要。 | 腹肌 seq2seq with att |
| 2015 | 使用語義表示來抽象性摘要 Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA級 | 腹部, 任務事件, 拱形圖 |
| 2016 | 神經摘要通過說出句子和單詞 Jianpeng Cheng,Mirella Lapata / ACL | Gen-2階段 |
| 2016 | 抽象性句子摘要與細心的複發神經網絡 S. Chopra,M。 Auli和Am Rush / Naa級 | Gen-abs, RNN,CNN, 拱形 |
| 2016 | 抽象性文本摘要使用序列到序列 R. Nallapati,B。 Zhou,C。 DosSantos,C。 Gulcehre和B. Xiang / Conll | Gen-Abs,數據新 |
| 2017 模型 | 摘要:基於復發性神經網絡的序列模型,用於提取文檔的提取性摘要 R. Nallapati,F。 Zhai和B. Zhou 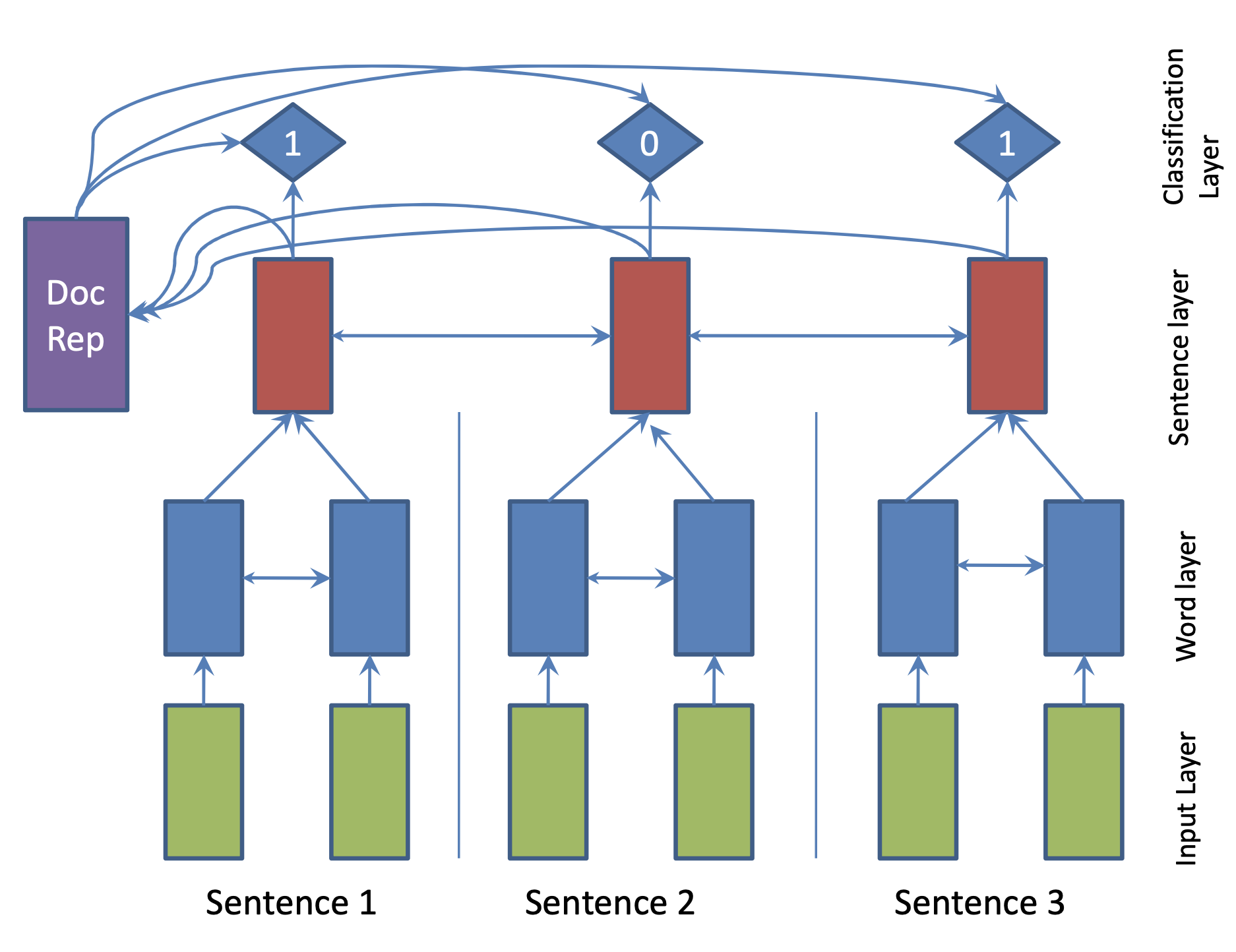 用層次的Bigru結構編碼文檔。首先,通過句子輸入第一個bigru來創建一個句子向量,然後將其傳遞回Bigru,為每個句子創建一個隱藏的狀態。在物流分類器中輸入這些單獨的句子嵌入和DOC VECTORT,這是一個有意義的總和,以確定句子是否將包含在摘要中。 | ext, RNN (分層bigru) |
| 2017 模型, 技術 | 指針生成器:指點:用Pointergenerator Networks(代碼)匯總 A.參見PJ Liu和CD Manning / ACL 2017 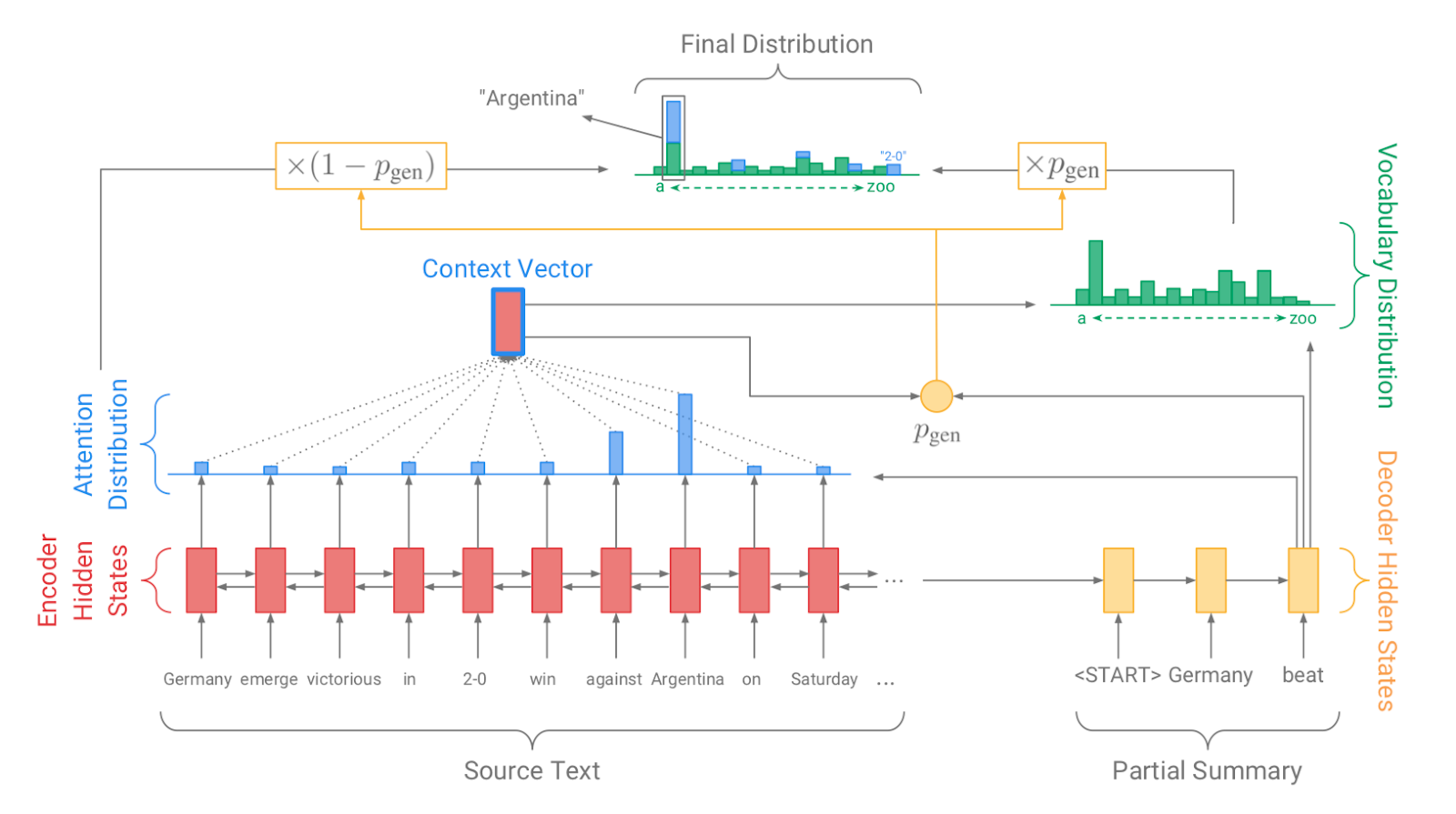 通過發電機創建詞彙分佈,創建一個注意力分佈,該分佈指示通過指針通過指針進行原始文本的哪個單詞,然後根據學習概率(PGEN)稱重 - sum,以確定最終單詞的分佈。混合方法結合了節制系統和提取方法,該方法結合了事實一致性和事實一致性的問題。此外,為了解決一個反復生成特定單詞的問題,損失中包括基於累積注意分佈值(覆蓋量向量C)的重複懲罰項。 - [評論] Kim Hyung -Seok(韓國) | ext/abs, 指針生成器, 覆蓋損失 |
| 2017 | 抽象性摘要的深鋼筋模型 R. Paulus,C。 Xiong和R. Socher | Gen-EX/ABS |
| 2017 | 通過基於圖的注意神經模型的抽象文檔摘要 Jiwei Tan,Xiaojun Wan,Jianguo Xiao / acl | ext,abs, Arch-Graph,Arch-Arch-Att |
| 2017 | 抽象文本摘要的深度重複解碼器 Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / Emnlp | 潛在vae |
| 2017 | 生成用於抽象文本摘要的對抗網絡 | |
| 2018 | 控制解碼更多 N. Weber,L。 Shekhar,N。 Balasubramanian和K. Cho | ext/abs |
| 2018 模型 | 通過總結長序列生成Wikipedia PJ Liu,M.Saleh,E。 Pot,B。 Goodrich,R。 Sepassi,L。 Kaiser和N. Shazeer / ICLR | ext/abs |
| 2018 | 以查詢為中心的抽象性摘要:結合查詢相關性,多文件覆蓋範圍和摘要 T. Baumel,M。 Eyal和M. Elhadad | ext/abs |
| 2018 模型 | 自下而上 Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / Emnlp 2018 這是一個代表性的2階段模型,它提取可以首先在摘要中使用的單詞,然後基於此生成摘要(ABS)。 ** | 腹部, 雜交種, 自下而上 |
| 2018 | 深層通信代理以抽象摘要 Asliçelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Care | ABS,任務較長的文本,拱形圖 |
| 2018 | 快速抽象性摘要,並加強式句子 Y. Chen,M。 Bansal | Gen-EX/ABS 拱形圖 |
| 2018 | 通過加強學習進行提取性摘要的排名 Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext,abs, RNN,CNN, Nondif-force |
| 2018 | 土匪:提取性摘要作為上下文匪徒 Yue Dong,Yikang Shen,Eric Crawford,Herke Van Hoof,Jackie Chi Kit Cheung | ext,abs, rnn, Nondif-force |
| 2018 | 深度學習模型的內容選擇 克里斯·凱茲(Chris Kedzie),凱瑟琳·麥克基(Kathleen McKeown) | ext, 任務知識 |
| 2018 | 忠於原始的:事實意識到神經抽象摘要 | |
| 2018 | 抽象性摘要的增強主題感知的捲積序列到序列模型 | |
| 2018 | 不要給我細節,只是摘要!主題感知的捲積神經網絡,用於極端摘要 | |
| 2018 | 全局編碼抽象摘要 | |
| 2018 | 快速抽象性摘要,並加強式句子 | |
| 2018 | 神經文檔摘要通過共同學習得分和選擇句子 | |
| 2018 | 檢索,重讀和重寫:基於軟模板的神經摘要 | |
| 2019 模型 | 微調BERT用於提取性摘要 劉 | Gen-ex |
| 2019 | 基於訓練的自然語言生成文本摘要 H. Zhang,J。 Xu和J. Wang | Gen-abs |
| 2019 | 改善提取性摘要的確定點過程的統一度量 Sangwoo Cho,Logan Lebanoff,Hassan Forosh,Fei Liu / acl | 任務 - 穆爾迪多克 |
| 2019 | Hibert:文檔級別的層次雙向變壓器的培訓用於文檔化 Xingxing Zhang,Furu Wei,Ming Zhou / acl | 拱形轉換器 |
| 2019 | 搜索有效的神經提取性摘要:什麼有效,下一步是明中心,pengfei liu,danqing wang,xipeng qiu | Gen-ex |
| 2019 | 瓶子:無監督和自製的前衛 彼得·韋斯特(Peter West),阿里·霍爾茨曼(Ari Holtzman),揚·布斯(Jan Buys),yejin choi / emnlp | Gen-ex,sup-sup,sup-unsup,拱形轉換器 |
| 2019 | 為抽象摘要評分單例和對 Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | Gen-Abs,Arch-CNN |
| 2019 模型 | PEGASUS :用提取的間隙句子進行抽象摘要(代碼)進行預訓練 Jingqing Zhang,Yao Zhao,Mohammad Saleh,Peter J. Liu / icml 2020 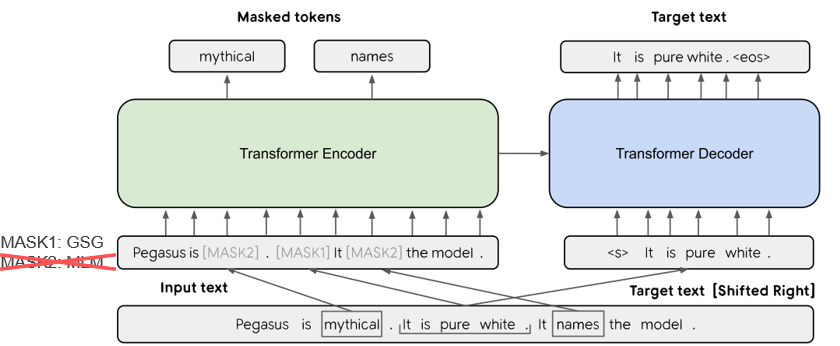 Pegasus使用了GSG(GAP句子生成)方法,該方法選擇了一個根據Rouge分數認為重要的句子,假設預先實現的目標將顯示出更高的性能作為文本摘要過程。 - [評論] Kim Han -Gil。視頻,演示材料 | |
| 2020 模型 | TLDR:科學文檔的極端總結(代碼,演示) Isabel Cachola,Kyle LO,Arman Cohan,Daniel S. Weld | Gen-EX/ABS |


