Text Summarization Repo
1.0.0
Entre os PNLs, é um espaço que acumula dados de qualidade relacionados ao campo de resumo do texto. Eu gostaria de ser um bom guia para quem está interessado no resumo do texto.
Primeiro de tudo, entendemos quais tópicos detalhados o texto resume é composto e analisamos os principais artigos que lideraram esse campo. Desde então, listamos o código, os conjuntos de dados e os modelos pré -criadores necessários para criar um modelo de resumo de texto direto.
Introdução ao resumo de texto
Papéis
Recursos
Outros
Berry, Dumais e O'Brien (1995) define o resumo do texto da seguinte forma:
Resumo do texto é o processo de destilar as informações mais importantes de um texto para produzir uma tarefa e usuário em particular
É um processo de refinar apenas informações importantes entre o texto fornecido em uma palavra. Aqui, a expressão de refino e a importância de importantes é uma expressão bastante abstrata e subjetiva, então eu pessoalmente quero defini -la da seguinte maneira.
f(text) = comprehensible information
Em outras palavras, o resumo do texto é converter o texto original em uma informação fácil e valiosa . Os seres humanos são difíceis de ver ao longo das informações de texto, que são longas ou divididas em vários documentos. Às vezes você não conhece muitos termos profissionais. É bastante valioso refletir esses textos em uma forma simples e fácil de compreender enquanto refletem bem o texto original. Obviamente, o que realmente vale a pena e como mudar isso variará dependendo do objetivo de resumir ou gostos pessoais.
Desse ponto de vista, pode -se dizer que o texto resume não apenas as tarefas que criam textos como as atas, a manchete do engenheiro de jornais, o resumo de papel e o currículo, bem como tarefas que convertem texto em gráficos ou imagens. Obviamente, como não é apenas o resumo, é um resumo de texto , portanto a fonte do resumo é limitada na forma de texto. (O resumo do resumo é porque pode ser não apenas texto ou vídeo, bem como texto. Por exemplo, o exemplo anterior é a legenda da imagem, o último exemplo é o resumo de vídeos. Considerando a recente tendência de aprendizado profundo quando o limite entre visão e PNL está ficando embaçado, pode ser sem sentido colocar 'texto' como prefixo.)
Em geral, a tarefa de resumo do texto é dividida em resumo extrativo (a seguir referido como ext) e resumo abstrato (ABS), dependendo de como eles geram um resumo. (Gudivada, 2018)
Os métodos extrativos selecionam um subconjunto de palavras, frases ou frases existentes no texto original para formar um resumo. Por outro lado, os métodos abstratos primeiro constroem uma representação semântica interna e o uso da tecnologia geracional de linguagem natural.
O ext geralmente obtém a importância da frase e depois seleciona e combina -a para criar um resumo. É semelhante à tarefa de pintar um marcador durante a leitura. O ABS , por outro lado , é baseado no texto original, mas é um método NLG (geração de linguagem natural) que gera um novo texto . É improvável que o Ext inclua expressões que sejam limitadas a expressões devido ao texto no texto original. O ABS, por outro lado, tem a vantagem de que exista a possibilidade de criar uma expressão sem precedentes, pois deve criar um novo texto no modelo, mas possui abordagens mais flexíveis.
Além disso, de acordo com o número de textos originais, de acordo com a forma de texto de resumo único/multi -documento , palavras -chave/resumo da sentença , de acordo com a quantidade de informações externas usadas no processo de resumo , de acordo com o processo de resumo, existem várias distinções como o resumo.
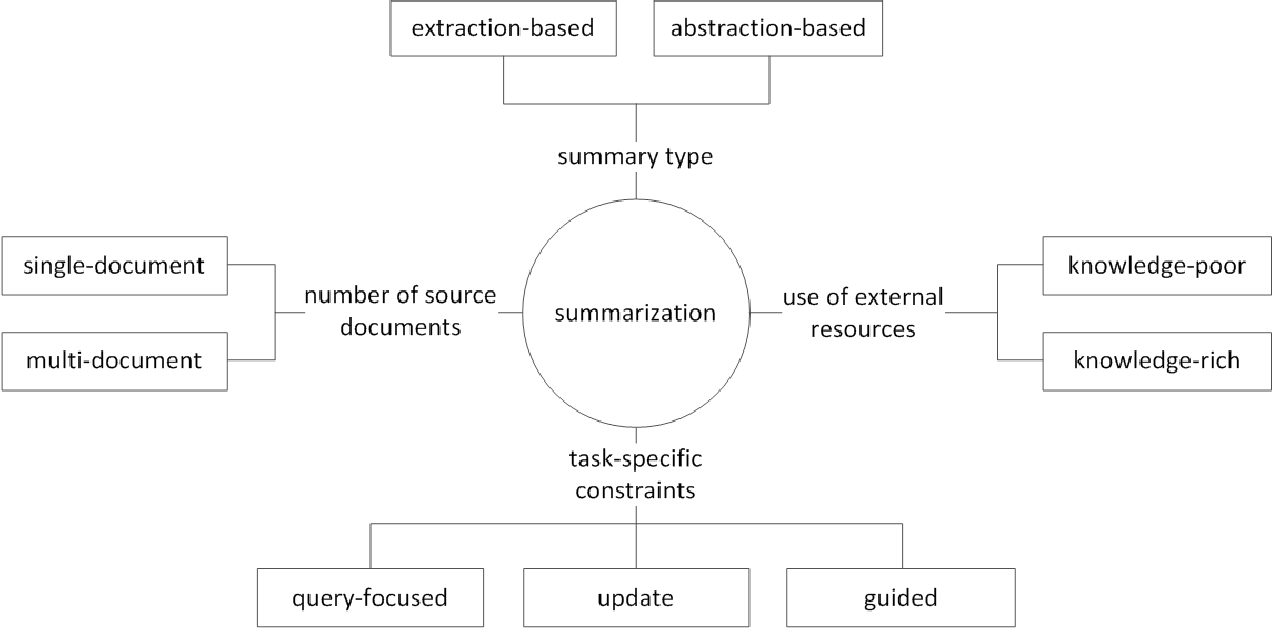
(G. Sizov (2010). Resumo automático baseado em extração: Investigação teórica e empírica de técnicas de resumo
Vamos dar uma olhada nos principais tópicos de pesquisa no campo do resumo de texto e pensar em que tipo de desafio nesse campo.
Resumo de documentos múltiplos / longos
Como mencionado anteriormente, a tarefa de resumo é alterar o texto incompreensível para informações compreensíveis. Portanto, quanto mais tempo o texto original, ou o resumo dos documentos de várias fontes, não um documento, mais a utilidade do resumo aumenta. O problema é que, ao mesmo tempo, a dificuldade de resumo também aumenta.
Por esse motivo, quanto mais tempo o texto original, mais rapidamente a complexidade computacional aumenta. Esse é um problema muito mais crítico nos métodos recentes baseados em rede neural, incluindo transformador do que em métodos estatísticos como o TexTrank no passado. Segundo, quanto mais tempo o texto original, mais não é o núcleo do conteúdo, ou seja, ruído. Não é fácil identificar o que é ruído e o que é informativo. Finalmente, textos longos e várias fontes têm várias perspectivas e conteúdos ao mesmo tempo, dificultando a criação de um resumo que o cobre bem.
Resumo de Multi Documentos (MDS)
MDS é um resumo de uma pluralidade de documentos . À primeira vista, será difícil resumir os artigos de diferentes perspectivas de vários autores do que resumir um documento que descreve um tema de uma tendência e ponto de vista consistentes. Obviamente, mesmo no caso do MDS, geralmente é baseado no mesmo documento de cluster que lida com tópicos semelhantes, mas não é fácil identificar informações importantes e filtrar informações de superfície entre muitos documentos.
A tarefa, que resume as críticas em determinados produtos, é um exemplo de MDS que é o mais fácil de pensar. Essa tarefa, geralmente chamada de resumo de opinião, é caracterizada por uma duração curta do texto e uma subjetividade. O trabalho de criar um documento wiki também pode ser considerado como um MDS. Liu et al. (2018) é o texto original do texto do site no documento wiki, que é o texto original, que é considerado um resumo, e cria um modelo de criação do Wiki.
Resumo de documentos longos
Liu et al. (2018) é uma maneira estatística de aceitar um texto longo como uma entrada, criando um resumo da extrocmentação, usando apenas frases importantes e usá -lo como uma entrada do modelo. Além disso, para reduzir o volume de computação do transformador, a entrada é dividida em unidades de bloco e, neste momento, a convolução 1-D usa o método de atensão que reduz o número de chave e valor de atenção individuais. O artigo do Big Bird (2020) apresenta o mecanismo de atitude escassa (linear) em vez de uma combinação de todas as palavras existentes para reduzir o cálculo do transformador. Como resultado, o mesmo hardware de desempenho foi resumido até oito vezes mais.
Gidiotis & Tsoumakas (2020), por outro lado, tentam se aproximar do divisão e conquista, que não resolve o problema de resumo de texto longo de uma só vez e o transforma em vários resumos de texto pequenos. Treinando o modelo alterando o texto original e o resumo de destino para os vários pares pequenos menores-alvos de origem. Na inferência, agregamos a saída de resumos parciais por meio deste modelo para criar um resumo completo.
Melhoria de desempenho
Como você pode criar um resumo melhor?
Transferência de aprendizado
Recentemente, o uso do modelo de pré -treinamento na PNL tornou -se quase padrão. Então, que tipo de estrutura devemos criar um modelo pré -realizado que possa mostrar melhor desempenho no resumo de texto? Que objeto devo ter?
Em Pegasus (2020), o método GSG (geração de sentenças GAP), que seleciona uma frase que é considerada importante com base na pontuação do Rouge, assume que quanto mais semelhante ao processo de resumo do texto e a objeção mostrará o desempenho mais alto. O modelo SOTA atual, Bart (2020) (transformadores bidirecionais e de regressão automática), aprende na forma de um autoencoder que adiciona ruído a alguns do texto de entrada e o restaura como um texto original.
Geração de texto aprimorada por Knowedge
Na tarefa de texto para texto, geralmente é difícil gerar a saída desejada apenas com o texto original. Portanto, há uma tentativa de melhorar o desempenho, fornecendo uma variedade de knowedge para o modelo, bem como o texto original . A fonte ou o fornecimento desses Knowedge varia em vários tipos de palavras -chave, tópicos, características linguísticas, bases de conhecimento, gráficos de conhecimento e texto fundamentado.
Por exemplo, Tan, Qin, Xing e Hu (2020) fornecem um conjunto de dados geral de Sumry para converter uma pluralidade de resumo baseado em aspectos e fornece informações mais ricas relacionadas a um determinado aspecto a um determinado aspecto do modelo. Use a Wikipedia para. Se você quiser saber mais, Yu et al. Leia o documento de pesquisa escrito por (2020).
Coreção pós-editora
Seria bom criar um bom resumo de uma só vez, mas não é fácil. Então, por que você não cria um resumo e depois revisa e modifica -o em uma variedade de critérios?
Por exemplo, CAO, DONG, WU, & CHEUNG (2020) sugere um método de redução de erro factual aplicando o modelo de corretor neural completo ao resumo gerado.
Além disso, também existem muitas tentativas de aplicar ** Rede Neural de Gráfico (GNN) **, que vem recebendo muita atenção recentemente.
Problema de escassez de dados
O resumo do texto é uma tarefa que leva muito tempo, o que não é fácil para os seres humanos. Portanto, em comparação com outras tarefas, custa custos relativamente maiores para criar conjunto de dados rotulado e, é claro, há uma falta de dados para o treinamento.
Além do método de aprendizado de transferência usando o modelo de pré-treinamento mencionado anteriormente, estamos aprendendo em métodos de aprendizado de aprendizado ou reforço não supervisionados ou tentando uma abordagem de aprendizado de poucos anos .
Naturalmente, fazer bons dados resumidos também é um tópico de pesquisa muito importante. Em particular, muitos dos conjuntos de dados relacionados ao resumo atual são tendenciosos em tipos de notícias no idioma inglês. Como resultado, conjuntos de dados multilíngues, como Wikilingua e MLSUM, estão sendo criados. Para obter mais informações, dê uma olhada no MLSUM: o corpus multilíngue de resumo .
Método de Métrica / Avaliação
Eu escrevi uma expressão esmagadora de 'bom' mais cedo. O que é um 'bom resumo'? Brazinskas, Lapata e Titov (2020) usam as cinco coisas a seguir, com base no julgamento de um bom resumo.
O problema é que não é fácil medir essas peças. O indicador de medição de desempenho mais comum nos resumos de texto é a pontuação do Rouge. Existem várias variantes na pontuação de Rouge, mas basicamente 'como é a palavra da palavra do resumo gerado e resumo de referência?' Significa semelhante, mas se você tiver uma forma diferente ou se a ordem das palavras mudar, poderá obter uma pontuação mais baixa, mesmo que seja um resumo melhor. Em particular, tentando aumentar a pontuação do Rouge, isso pode resultar em prejudicar a diversidade expressiva do resumo. É por isso que muitos trabalhos fornecem resultados adicionais de avaliação humana com dinheiro caro e pontuação de Rouge.
Lee et al. (2020) apresenta uma pontuação semântica de referência e conscientização de documentos), que é como é semelhante ao resumo de texto e referência e, em seguida, medido pelas estradas semelhantes baseadas em vetor. Espera -se que esse método aumente a precisão da avaliação da linguagem coreana, que combina palavras e várias morfologia para expressar vários significados e funções gramaticais. Kryściński, McCann, Xiong e Socher (2020) propuseram abordagem baseada em modelo fracamente supervisionada para avaliar a consistência factual.
Geração de texto controlável
Existe apenas um resumo melhor sobre um determinado documento? Não vai. Pessoas com inclinações diferentes podem preferir textos resumidos diferentes para o mesmo texto. Mesmo se você for a mesma pessoa, o resumo que você deseja dependerá do objetivo de resumir ou da situação. Este método de ajustar a saída no formulário desejado de acordo com as condições especificadas pelo usuário é chamado de geração de texto controlável . Você pode fornecer um resumo personalizado em comparação com o resumo genérico que cria o mesmo resumo para um determinado documento.
O resumo gerado não deve ser fácil de entender e valorizar, mas também estar intimamente relacionado à condição que você montou.
f(text, condition ) = comprehensible information that meets the given conditions
Que condição posso adicionar ao modelo de resumo? E como você pode criar um resumo que se adapte a essa condição?
Resumo baseado em aspectos
Ao resumir as análises do usuário do AirPod, você pode resumir cada lado dividindo a qualidade, a bateria e o design do som. Ou você pode querer ajustar o estilo ou sentimento de escrita no artigo. Neste texto original , o trabalho que resume apenas informações relacionadas a aspectos ou recursos específicos é chamado de resumo baseado em aspectos .
Anteriormente, apenas modelos que funcionavam apenas em aspecto predefinido, que eram usados principalmente para aprendizado de modelo, agora tentavam permitir o raciocínio de aspecto arbitrário, que não era dado ao aprendizado como Tan, Qin, Xing e Hu (2020).
Summarização focada em consulta (QFS)
Se a condição for consulta , ela é chamada QFS. A consulta é principalmente a linguagem natural, portanto, a principal tarefa é como fazer bem essas várias expressões e combiná -las com o texto original. É bastante semelhante ao sistema de controle de qualidade que conhecemos bem.
Atualizar resumo
Os seres humanos são animais que continuam aprendendo e crescendo. Portanto, o valor de hoje para determinadas informações pode ser completamente diferente do valor de uma semana depois. O valor do conteúdo no documento que já experimentei será reduzido e o novo conteúdo que ainda não foi experimentado ainda terá alto valor. Desse ponto de vista, é chamado de resumo de atualização para criar um novo resumo de um novo conteúdo semelhante ao conteúdo do documento que o usuário experimentou anteriormente .
Ctrlsum leva várias palavras -chave ou instruções descritivas com o texto para ajustar o resumo gerado. É um modelo de resumo de texto controlável mais geral, pois mostra os mesmos resultados que são controlados para palavras -chave ou instruções que não são aprendidas explicitamente no estágio de treinamento. Você pode usá -lo facilmente na biblioteca Summarizers Koh Hyun -Woong.
Além disso, uma variedade de tentativas de criar um modelo de resumo adequado para o resumo de conversas, em vez de um tópico típico de DL, como o ** modelo leve, bem como um resumo do diálogo em vez de um texto estruturado como notícias ou Wikipedia. Existem tópicos.
Se você souber o seguinte no campo de resumo do texto, poderá estudar com mais facilidade.
Compreendendo o conceito básico da PNL
Estrutura do transformador/Bert e compreensão objetiva pré-treinamento
Muitos dos documentos mais recentes da PNL são baseados em vários modelos de pré -realização, incluindo Bert, baseados em Transformer, e Roberta e T5, que são variantes deste Bert. Portanto, se você entender a estrutura esquemática deles e o objetivo de pré-treinamento, é uma grande ajuda para ler ou implementar um artigo.
Conceito básico de resumo de texto
Rede Neural de Gráfico (GNN)
Tradução da máquina (MT)
O MT é uma das tarefas mais ativas no campo PNL desde o surgimento do SEQ2SEQ. Se você observar o processo de resumo como um processo de conversão de um texto em um tipo diferente de texto, ele poderá ser visto como uma espécie de MT, é provável que muitos estudos e idéias relacionados ao MT sejam emprestados ou aplicados no campo de resumo.
| Ano | Papel | Palavras -chave |
|---|---|---|
| 2004 Modelo | TexTrank : trazendo ordem para textos R. Mihalcea, P. Tarau É um clássico no setor de extração e ainda está ativo. No pressuposto de que a frase importante dentro do documento (ou seja, incluída no resumo) é um algoritmo PageRank, a idéia inicial do mecanismo de pesquisa do Google, assumindo que ele terá alta similidade com outras frases. Cada frase configura o gráfico ponderado no nível da frase para calcular a semelhança com outra frase no documento e inclui essa frase de alto peso no resumo. Os métodos de aprendizado não supervisionado por estatísticas podem ser razoáveis sem dados de aprendizado separados, e o algoritmo é claro e fácil de entender. - [Biblioteca] Gensim.summarization (apenas a versão 3.x está disponível. Exclua da versão 4.x), PytexTrank - [Teoria/Code] Lovit. Extração de palavras -chave usando o textTranck e o Core Sentence Extract | Ext, Baseado em gráficos (PageRank), Não supervisionado |
| 2019 Modelo | Bertsum : resumo de texto com codificadores pretendidos (officeiad) Yang Liu, Mirella Lapata / EMNLP 2019 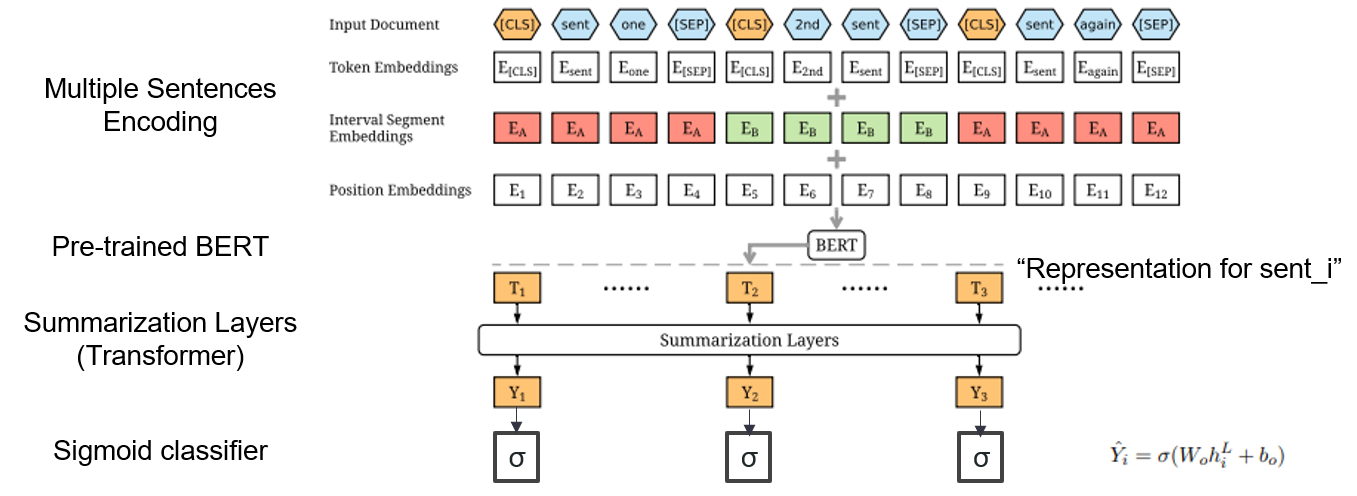 Como posso usar o Bert pré-treinado em resumo? Como posso usar o Bert pré-treinado em resumo?O Bertsum sugere incorporação de entrada modificada que insere [CLS] Tokens na frente de cada frase e adiciona incorporações de segmento de intervalo para adicionar várias frases a uma entrada. O modelo EXT usa uma estrutura de codificador com uma camada de transformador no BERT, e o modelo ABS usa um modelo de codificador-decodificador com um decodificador de transformador de 6 camadas no modelo EXT. - [Revisão] Lee Jung -Hoon (KoreAuniv DSBA) - [coreano] Kobertsum | Ext/abs, Bert+transformador, Tuneamento fino de 2 etapas |
| 2019 Modelo de pré -treinamento | BART : DenOising Sequence-Sensence Pré-treinamento para geração de linguagem natural, tradução e compreensão Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke ZettleMoyer / ACL 2020 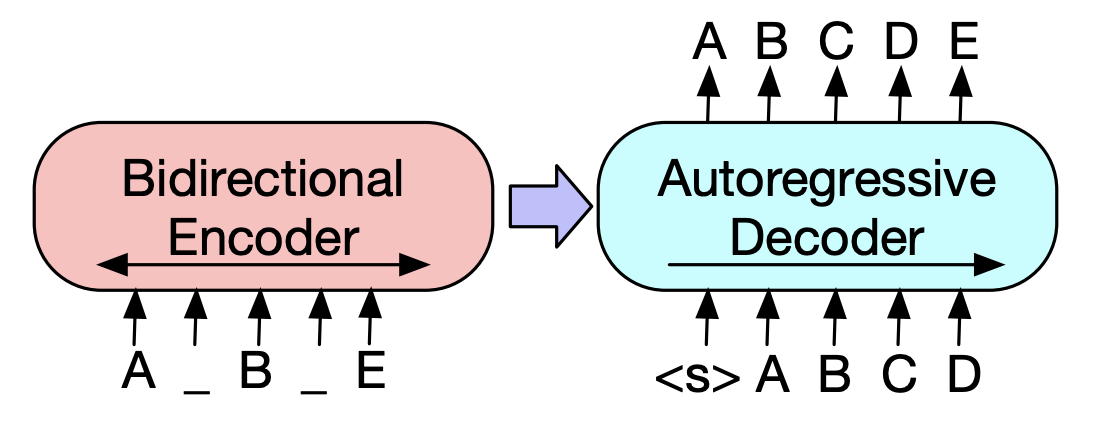 Bert é um codificador bidirétrico, fraco para tarefas de geração, e o GPT tem uma desvantagem de não obter informações bidirecidas com um modelo de regressão automática. Bert é um codificador bidirétrico, fraco para tarefas de geração, e o GPT tem uma desvantagem de não obter informações bidirecidas com um modelo de regressão automática.O Bart possui um formulário seq2seq que os combina, para que você possa experimentar várias técnicas desnocas em um modelo. Como resultado, o texto preenchendo (muda o tempo de texto para uma máscara) e a frase embaralhando (misturando a frase aleatoriamente) mostra o desempenho que ultrapassa o modelo Ki Sota no campo do resumo. - [coreano] skt t3k. Kobart -[Review] Jin Myung -Hoon_video, Lim Yeon -soo_ Escrito por Jiwung Hyun_ | Abs, SEQ2SEQ, Denoising AutoEncoder, Texto preenchido |
| 2020 Modelo | Soma de fósforos : resumo da extração como correspondência de texto (escritório) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, XiEng Qiu, Xuanjing Huang / ACL 2020 - [Revisão] Yoo Kyung (KoreAuniv DSBA) | Ext |
| 2020 Técnica | Resumindo o texto sobre quaisquer aspectos: uma abordagem fracamente supervisionada do conhecimento (código oficial) Bowen Tan, Lianhui Qin, Eric P. Xing, Zhiting HU / EMNLP 2020 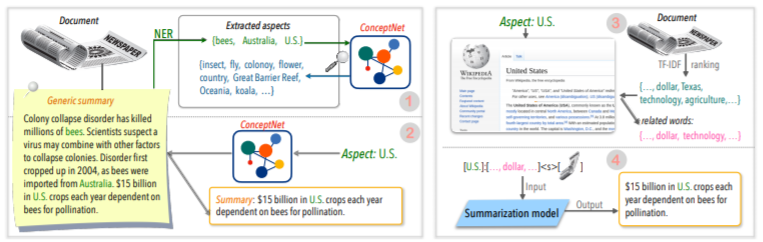 O resumo baseado em aspectos é uma tarefa que não é fácil, pois é executada apenas nos aspectos predefinidos dos dados, que são aprendidos mesmo se você aprender o modelo e 2) falta de dados de resumos baseados em múltiplos aspectos. Este artigo utiliza fontes de conhecimento externas para resolver esse problema. -Vents passa por duas etapas para converter o resumo genérico em vários resumos baseados em aspectos. Primeiro de tudo, para aumentar o número de aspectos, a entidade extraída do resumo genérico é semente e extraída do concepnet para seus vizinhos e considerar cada um deles como um aspecto. Utilizamos o ConcepNet novamente para criar um resumo do PSEDO para cada um desses aspectos. Extraia a entidade circundante conectada ao aspecto correspondente no concepnet e extraia apenas as frases que as contêm dentro do resumo geral. Isso é considerado um resumo para essa entidade (aspecto). -Wikipedia é usada para fornecer informações mais abundantes relacionadas ao aspecto fornecido ao modelo. Especificamente, entre as palavras que aparecem no documento, a pontuação do TF-IDF no documento é alta e ao mesmo tempo e, ao mesmo tempo, a lista de 10 palavras na página da Wikipedia corresponde a esse aspecto é adicionada ao aspecto com a entrada do modelo. Dessa forma, o modelo pré-regressivo (BART) também foi excelente para aspecto arbitrário com pequenos dados. | Baseado em aspecto, Knowlege rico |
| 2020 Análise | O que logo temos o resumo de texto? Dandan Huang, Leyang Cui, Sen Yang, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang / EMNP 2020 Além da pontuação do ROUGE, 10 modelos de resumo representativos são avaliados de acordo com 8 métricas (politopo) relacionadas à precisão e fluência. Para resumir os resultados, -O método tradicional baseado em regras ainda é válido como linha de base. Sob configurações semelhantes, o modelo EXT geralmente mostra melhor desempenho em fiéis e consistência factual. A principal falha é a inesperada para modelos extrativos, e omissão e alucinação intrínseca para modelos abstratos. -As estruturas mais complexas, como transformadores para criar a representação de frases, não são muito úteis, exceto o problema de duplicação. -Copy ( Pointer-Generator ) é um detalhe reproduzido, que resolve efetivamente o problema de duplicação do nível da palavra, misturando-o, bem como a imprecisão intrínseca. Mas tende a causar redundância até certo ponto. A cobertura é por uma grande margem, o que reduz os erros de repetição (duplicação), mas ao mesmo tempo aumenta a adição e a imprecisão. -Hibrid Modelo , que é ABS após EXT, é bom para recalls, mas pode haver problemas com erro de imprecisão porque gera resumo através de alguns dos texto originais (trechos extraídos). O pré-treinamento, especialmente o modelo de codificador-decodificador (BART) do que o modelo apenas do codificador (Bertsumextabs) é muito eficaz no resumo. Isso sugere que a pré -exposição de toda a compreensão e criação de entrada é muito útil para seleção e combinação de conteúdo. Ao mesmo tempo, enquanto a maioria dos modelos de ABS se concentra na frase frontal, Bart está olhando para todo o texto original, o que parece ser o efeito de arrastar a frase durante a pré -realização. 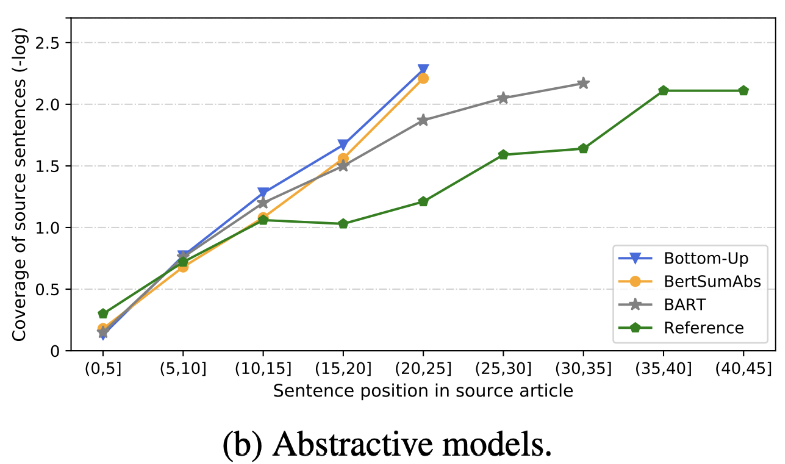 - [Revisão] Kim Han -gil, Heo Hoon | Análise |
| 2020 Modelo | Ctrlsum : Rumo ao resumo genérico de texto controlável (código oficial) Junxian He, Wojciech Kryściński, Bryan McCann, Nazneen Rajani, Caiming Xiong Ctrlsum é um modelo de resumo de texto controlável que permite ajustar as instruções resumidas geradas por palavras -chave ou prompts descritivos. Treinamento: para criar um conjunto de dados de resumo controlável baseado em palavras-chave, modificando os dados gerais de resumo, selecione Sub-seqüências, que é o mais semelhante ao resumo e extraia a palavra-chave lá. Coloque isso em uma entrada com o documento e termine o Bart de pré-ajuste. 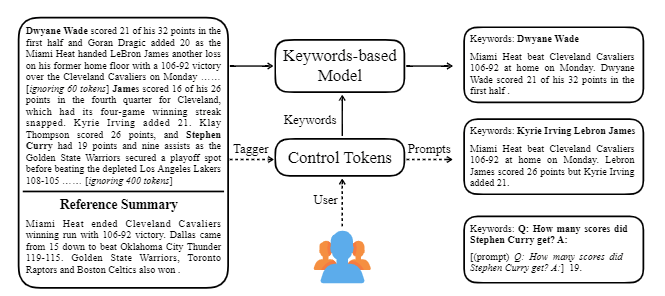 -InPerência: Como mostrado na imagem abaixo, você pode adicionar um resumo do resumo, como criar um resumo de uma entidade específica, ajustar o comprimento do resumo ou criar uma resposta a uma pergunta. Vale ressaltar que funciona como se não estivesse aprendendo explicitamente tais instruções no estágio de modelagem, mas funcionou como se fosse para entender o rápido e gerar um resumo. Semelhante ao GPT-3. 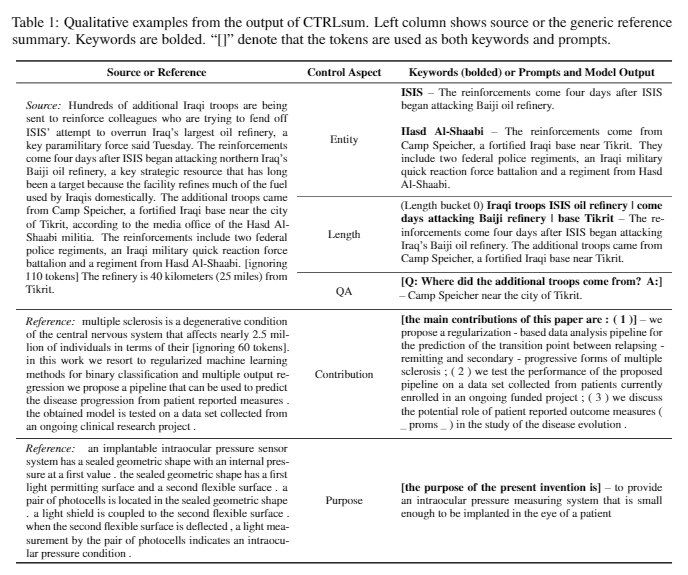 - Pacote [Biblioteca] para Ctrlsum baseado em resumo controlável | Controlável, Bart |
Artigo Digest: Documentos recentes sobre resumo de texto
Documentos com Código: Papéis Últimos
EMNLP 2020 Papers-Summarização
De fato, resumimos os modelos Código, Dados e Preitranos necessários para criar e praticar modelos de resumo. São principalmente dados coreanos e, para materiais relacionados ao inglês, consulte a parte do código de cada artigo no item de artigos.
O significado dos fracos usados abaixo é o seguinte.
w : valor médio do número de palavras; s : valor médio do número médio de frases
Exemplo) 13s/214w → 1s/26w significa que fornece um texto resumido que consiste em uma média de 13 frases (média de 214 palavras) e uma média de uma frase (26 palavras em média).
Resumo abs ; ext : resumo extrativo
| Conjunto de dados | Domínio / comprimento | Volume (Par) | Licença |
|---|---|---|---|
| Resumo do documento de palavras de todos Título de texto curto de notícias, 3 frases abdom Todas as palavras de todos com identidade combinados com os cavalos de jornal, você pode obter informações adicionais relacionadas às legendas, mídia, data e tópico. | notícias -Rigin → 3s (ABS); 3s (ext) | 13.167 | Instituto Nacional de Língua Coreana (Contrato individual) |
| Texto resumido do documento aihub ABS e Ext Summer para artigos de jornais, contribuições, artigos de revistas e críticas judiciais - [EDA] Notebook EDA Data EDA -Resumo do resumo da extração de documentos coreanos e concurso de resumo da criação (~ 20.12.09) | -O artigo de jornal 300.000, 60.000 contribuições, 10.000 artigos de revistas, decisão judicial 30.000 13S/214W → 1S/26W (ABS); 3s/55W (ext) | 400.000 | AiHub (Contrato individual) |
| Aihub-sumário Resumo do ABS por todos e seção para trabalhos acadêmicos e especificações de patentes | -Um trabalhos acadêmicos, especificações de patentes -Rigin → Abs | 350.000 | AiHub (Contrato individual) |
| Resumo dos dados do AiHub-Book Resumo do ABS para o livro coreano original sobre vários tópicos | -Extime, vida, imposto, meio ambiente, desenvolvimento comunitário, comércio, economia, trabalho, etc. -300-1000 caracteres → ABS | 200.000 | AiHub (Contrato individual) |
| SAE4K | 50.000 | CC-BY-SA-4.0 | |
| Sci-News-SUM-KR-50 | Notícias (IT/Science) | 50 | Mit |
| Wikilingua : um conjunto de dados de resumo abstrato multilíngue (2020) Com base no site manual wikihow, 18 idiomas como coreano e inglês -Plaim, Caderno de colaboração | -COMO-TO DOCS -391W → 39W | 12.189 (Kor no total 770.087) | 2020, CC BY-NC-SA 3.0 |
| Conjunto de dados | Domínio / comprimento | Volume | Licença |
|---|---|---|---|
| Scisummnet (papel) Fornece três tipos de resumo para a pesquisa da ACL (PNL) -Cl-scisummumm 2019-Task2 (repo, papel) -Cl-scisumm @ emnlp 2020-Task2 (repo) | -Documento de pesquisa (Linguistas computacionais, PN) 4.417W → 110W (resumo em papel); 2s (citação); 151W (ABS) | 1.000 (ABS/ EXT) | CC BY-SA 4.0 |
| Longsumm Resumo da lista relativamente longa (postagens relacionadas ao blog -abdominais baseados, conferências relacionadas conversas em vídeo) -LongSumm 2020@EMNLP 2020 -Longsumm 2021@ NAACL 2021 | -Research Paper (NLP, ML) -Rigin → 100s/1.500W (ABS); 30s/ 990W (ext) | 700 (ABS) + 1.705 (ext) | Attribution-NonCommercial-Sharealike 4.0 |
| CL-Laysumm Forneça uma camada fácil para não -profissionais para campos de PNL e ML. -Cl-laysumm @ emnlp 2020 | -Research Paper (epilepsia, arqueologia, engenharia de materiais) -Rigin → 70 ~ 100w | 600 (ABS) | Necessidades de acordo individual (enviado por e -mail para [email protected]) |
| Voz global : Crossing Borders in Automatic News Summarization (2019) -Papel | - notícias -359w → 51w | ||
| MLSUM : o corpus multilíngue de resumo Semelhante ao conjunto de dados da CNN/Daily Mail, os destaques/descrição em artigos de notícias são considerados um resumo e resumo para o conjunto de dados em inglês, francês, Alemanha, espanhol, russo e turco -Plaim, use (Huggingface) | - notícias -790W → 56W (Em base) | 1,5m (ABS) | Apenas fins de pesquisa não comercial |
| Modelo | Pré-treinamento | Uso | Licença |
|---|---|---|---|
| Bert (multilíngue) BERT-BASE (parâmetros 110m) | -Wikipedia (multilíngue) -WordPiece. -110K Vocabs compartilhados | BERT-Base, Multilingual Cased( --do_lower_case=false )-Tensorflow | Google (Apache 2.0) |
| Kobert BERT-BASE (parâmetros 92m) | -Wikipedia (frase de 5m), notícias (frase de 20 milhões) -Sentencepiece 8.002 Vocabs (sem token não utilizado) | -Pytorch -Todos disponíveis como Biblioteca de Transformers do Huggingface através de Kobert-Transformers (Monologg), Distilkobert disponível | Sktbrain (Apache-2.0) |
| Korbert Bert-base | -Nows (10 anos), Wikipedia, etc. 23 GB -Etri Morfological Analysis API / Palavra (forneceu duas versões separadamente) -30.349 Vocabs Alfabetos latinos: CASED - [Introdução] Lim Jun (ETRI). NLU Tech Talk com Korbert | -Pytorch, tensorflow | ETRI (Contrato individual) |
| KCBERT Bert-base/grande | -Daver News Comment (12,5 GB, 8,9 milhões de frases) (19.01.01 ~ 20.06.15 Comentários de artigos em artigos e comentários) -Tokenizers BERTWORDPIECETOKenizer -30.000 Vocabs | Beomi (MIT) | |
| Kobart Bart (124m) | -Wikipedia (5m) e outros (notícias, livro, palavras de todos (conversa, notícias, ...), Cheong Wa Dae National Petition, etc. -Tokenizador de BPE de personagem de Tockenizers 30.000 vocabs (incluídos) - [Exemplo] Seujung. KOBART-SUMARIZAÇÃO (Código, demonstração) | -Especialização da tarefa SUSCRO -Huggingface Transformers Suporte da biblioteca -Pytorch | Skt t3k (MIT modificado) |
| Ano | Papel |
|---|---|
| 2018 | Uma pesquisa sobre métodos de resumo baseados em rede neural Y. Dong |
| 2020 | Revisão da técnica e métodos automáticos de resumo de texto Widyassari, AP, Rustad, S., Shidik, GF, Noersasongko, E., Syukur, A., & Afmandy, A. |
| 2020 | Uma pesquisa com geração de texto aprimorada pelo conhecimento Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, Meng Jiang |
| Ano | Papel | Palavras -chave |
|---|---|---|
| 1958 | Criação automática de resumos de literatura Ph Luhn | Gen-ex |
| 2000 | Geração de manchete com base na tradução estatística M. Banko, Vo Mittal e MJ Witbrock | Gen-abs |
| 2004 | Lexrank : centralidade lexical baseada em gráfico como saliência no resumo de texto G. Erkan e Dradev, | Gen-ex |
| 2005 | Resumo de documentos únicos baseados em extração de frases J. Jagadeesh, P. Pingali e V. Varma | Gen-ex |
| 2010 | Geração de título com gramática quase síncrona K. Woodsend, Y. Feng e M. Lapata, | Gen-ex |
| 2011 | Resumo de texto usando análise semântica latente Mg ozsoy, fn alpaslan e I. cicekli | Gen-ex |
| Ano | Papel | Palavras -chave |
|---|---|---|
| 2014 | Ao usar vocabulário alvo muito grande para tradução para a máquina neural S. Jean, K. Cho, R. Memisevic e Yoshua Bengio | Gen-abs |
| 2015 Modelo | NAMAS : Um modelo de atenção neural para resumo abstrato (código) Am Rush, S. Chopra e J. Weston / EMNLP 2015 Para ir além do método de seleção e combinação de frases existentes, introduzimos a atenção de destino a fonte no sinalizador SEQ2SEQ para criar um resumo abstrato. | Abs Seq2seq com att |
| 2015 | Toward Abstractive Summarization Using Semantic Representations Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 Modelo | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 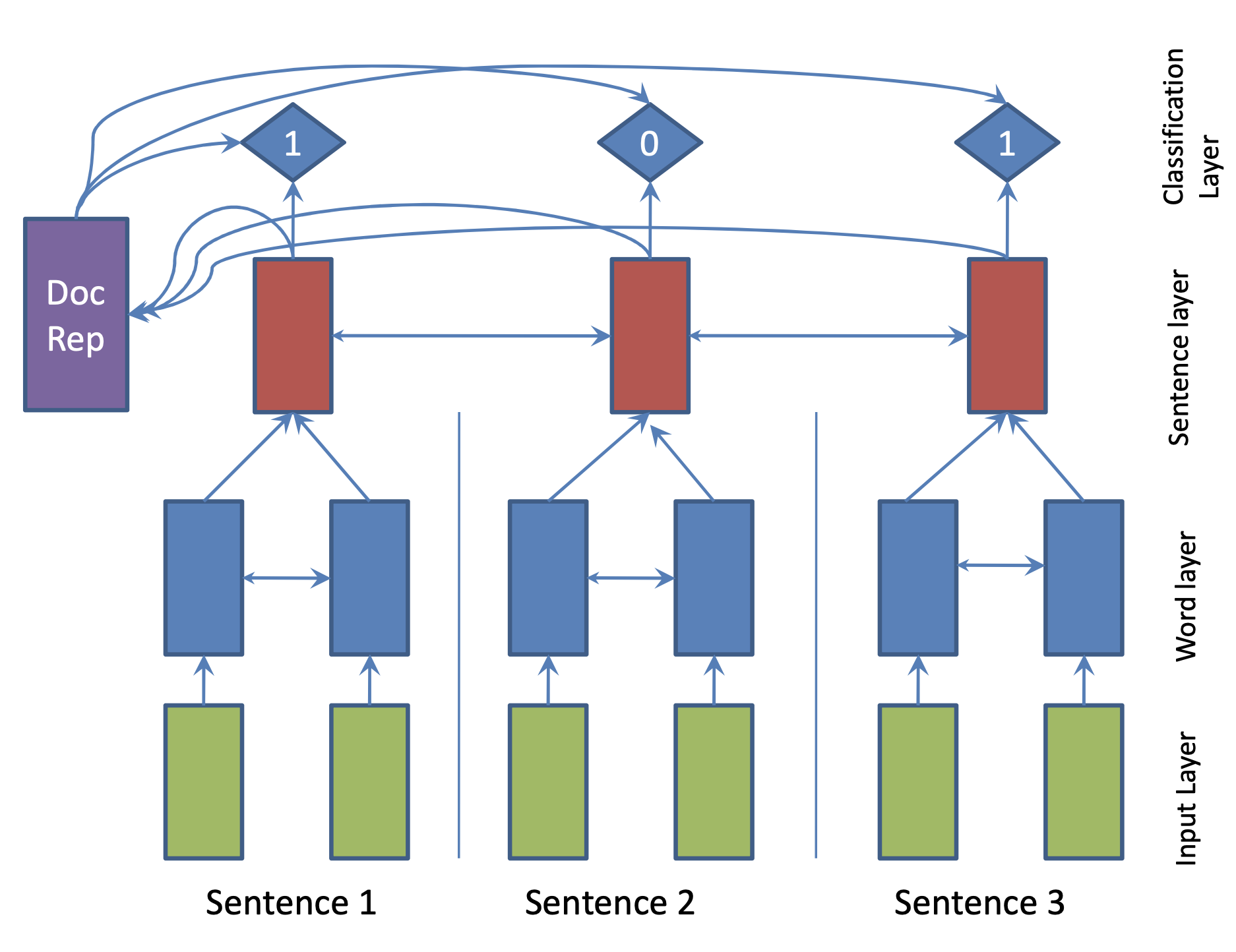 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 Modelo, Técnica | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 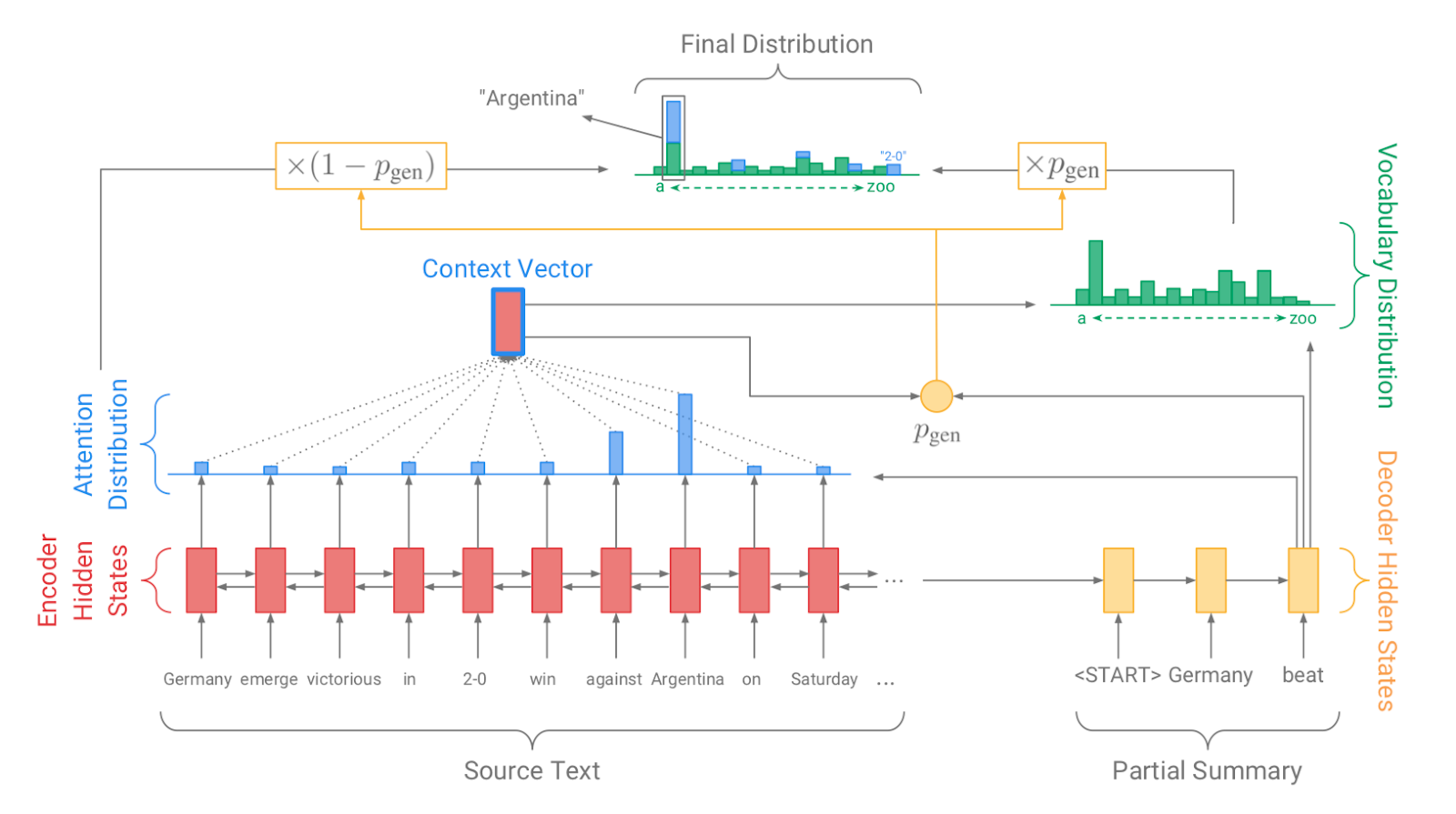 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 Modelo | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 Modelo | Baixo para cima Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, Híbrido, Baixo para cima |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 Modelo | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 Modelo | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 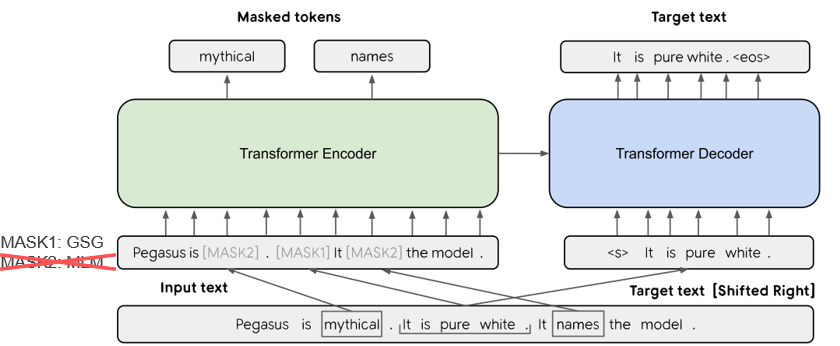 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 Modelo | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


