Text Summarization Repo
1.0.0
ในบรรดา NLPs เป็นพื้นที่ที่สะสมข้อมูลคุณภาพที่เกี่ยวข้องกับฟิลด์สรุปข้อความ ฉันต้องการเป็นแนวทางที่ดีสำหรับผู้ที่สนใจสรุปข้อความ
ก่อนอื่นเราเข้าใจว่าหัวข้อที่ละเอียดเกี่ยวกับข้อความสรุปคืออะไรและดูเอกสารหลักที่นำไปสู่ฟิลด์นี้ ตั้งแต่นั้นมาเราได้แสดงรายการโค้ดชุดข้อมูลและโมเดล pre -crane ที่จำเป็นในการสร้างโมเดลสรุปข้อความโดยตรง
แนะนำการสรุปข้อความ
เอกสาร
ทรัพยากร
คนอื่น
Berry, Dumais, & O'Brien (1995) กำหนดบทสรุปข้อความดังนี้:
การสรุปข้อความเป็นกระบวนการ กลั่นข้อมูลที่สำคัญที่สุด จากข้อความเพื่อสร้างงานและผู้ใช้โดยเฉพาะ
มันเป็น กระบวนการของการกลั่นข้อมูลที่สำคัญเพียงอย่างเดียวระหว่างข้อความที่ให้ไว้ ในคำ ที่นี่การแสดงออกของ การกลั่น และ ความสำคัญของความสำคัญ คือการแสดงออกที่เป็นนามธรรมและเป็นอัตนัยดังนั้นโดยส่วนตัวแล้วฉันต้องการกำหนดมันดังนี้
f(text) = comprehensible information
กล่าวอีกนัยหนึ่งการสรุปข้อความคือ การแปลงข้อความต้นฉบับเป็นข้อมูลที่ง่ายและมีค่า มนุษย์ยากที่จะเห็นข้อมูลข้อความซึ่งยาวหรือแบ่งออกเป็นเอกสารหลายฉบับ บางครั้งคุณไม่รู้คำศัพท์มืออาชีพมากมาย มันค่อนข้างมีค่าที่จะสะท้อนข้อความเหล่านี้เป็นรูปแบบที่เรียบง่ายและง่ายต่อ -เข้าใจในขณะที่สะท้อนข้อความต้นฉบับได้ดี แน่นอนว่าสิ่งที่คุ้มค่าจริงๆและวิธีการเปลี่ยนแปลงมันจะแตกต่างกันไปขึ้นอยู่กับวัตถุประสงค์ของการสรุปหรือรสนิยมส่วนตัว
จากมุมมองนี้อาจกล่าวได้ว่าข้อความสรุปไม่เพียง แต่งานที่สร้างข้อความเช่นนาทีพาดหัววิศวกรหนังสือพิมพ์บทคัดย่อกระดาษและประวัติย่อรวมถึงงานที่แปลงข้อความเป็นกราฟหรือรูปภาพ แน่นอนเนื่องจากไม่ได้เป็นเพียงการสรุปเท่านั้นจึงเป็นการ สรุปข้อความ ดังนั้นแหล่งที่มาของบทสรุปจึงถูก จำกัด ในรูปแบบของข้อความ (บทสรุปของบทสรุปเป็นเพราะไม่เพียง แต่เป็นข้อความหรือวิดีโอเช่นเดียวกับข้อความตัวอย่างในตัวอย่างเดิมคือคำบรรยายภาพตัวอย่างหลังคือการสรุปวิดีโอเมื่อพิจารณาถึงแนวโน้มการเรียนรู้ที่ลึกซึ้งเมื่อเร็ว ๆ นี้เมื่อขอบเขตระหว่างการมองเห็นและ NLP กำลังพร่ามัว
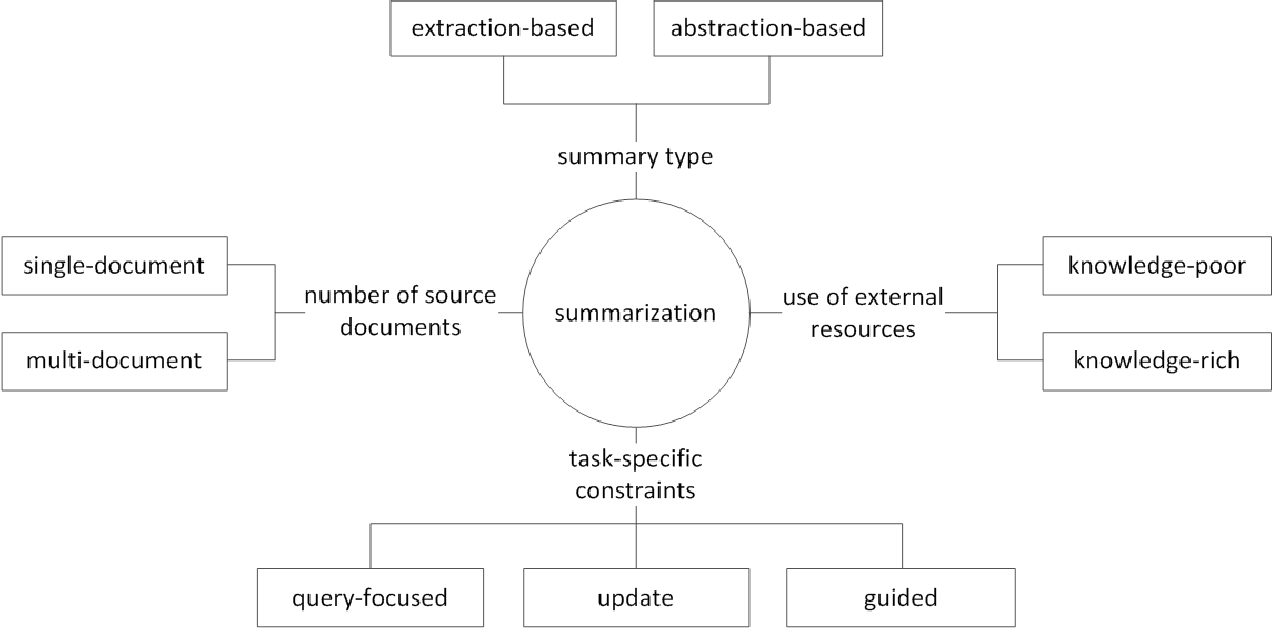
โดยทั่วไปงานสรุปข้อความจะถูกแบ่งออกเป็นการ สรุปการสกัด (ต่อไปนี้จะเรียกว่า ext) และ การสรุปเชิงนามธรรม (ABS) ขึ้นอยู่กับวิธีที่พวกเขาสร้างบทสรุป (Gudivada, 2018)
วิธีการสกัดเลือกชุดย่อยของคำวลีหรือประโยคที่มีอยู่ในข้อความต้นฉบับเพื่อสร้างบทสรุป ในทางตรงกันข้ามวิธีการแบบนามธรรมก่อนสร้างการเป็นตัวแทนความหมายภายในและการใช้เทคโนโลยีการสร้างภาษาธรรมชาติ
Ext มักจะ ทำคะแนนความสำคัญของประโยคจากนั้นเลือกและรวมเข้าด้วยกัน เพื่อสร้างบทสรุป มันคล้ายกับงานวาดปากกาเน้นข้อความขณะอ่าน ในทางกลับกัน ABS นั้นขึ้นอยู่กับข้อความต้นฉบับ แต่เป็นวิธี NLG (การสร้างภาษาธรรมชาติ) ที่สร้างข้อความใหม่ Ext ไม่น่าจะรวมถึงการแสดงออกที่ จำกัด เฉพาะการแสดงออกเนื่องจากข้อความในข้อความต้นฉบับ ในทางกลับกัน ABS มีข้อได้เปรียบที่มีความเป็นไปได้ในการสร้างนิพจน์ที่ไม่เคยมีมาก่อนเพราะต้องสร้างข้อความใหม่ในโมเดล แต่มีวิธีการที่ยืดหยุ่นมากขึ้น
นอกจากนี้ตามจำนวนข้อความต้นฉบับตามรูปแบบข้อความของการสรุป เอกสารเดี่ยว/หลายฉบับ การสรุป คำหลัก/ประโยค ตามข้อมูลภายนอกที่ใช้ในกระบวนการสรุปจำนวนเท่าใด ตาม กระบวนการสรุปมีความแตกต่างต่าง ๆ เช่นการสรุป
(G. Sizov (2010). การสรุปอัตโนมัติจากการสกัด: การตรวจสอบเชิงทฤษฎีและเชิงประจักษ์ของเทคนิคการสรุป
ลองมาดูหัวข้อการวิจัยที่สำคัญในด้านการสรุปข้อความและคิดเกี่ยวกับความท้าทายในสาขานี้
การสรุปเอกสารหลาย / ยาว
ดังที่ได้กล่าวไว้ก่อนหน้านี้งานสรุปคือการเปลี่ยนข้อความที่เข้าใจไม่ได้เป็นข้อมูลที่เข้าใจได้ ดังนั้นยิ่งข้อความต้นฉบับยาวขึ้นหรือบทสรุปของเอกสารของหลายแหล่งไม่ใช่เอกสารเดียวยิ่งยูทิลิตี้ของการสรุปเพิ่มขึ้นเท่านั้น ปัญหาคือในเวลาเดียวกันความยากลำบากในการสรุปก็เพิ่มขึ้นเช่นกัน
ด้วยเหตุผลนี้ยิ่งข้อความต้นฉบับนานขึ้นเท่าใดความซับซ้อนของการคำนวณก็จะเพิ่มขึ้นอย่างรวดเร็ว นี่เป็นปัญหาที่สำคัญยิ่งกว่าในวิธีการที่ใช้เครือข่ายประสาทรวมถึงหม้อแปลงมากกว่าวิธีการทางสถิติเช่น Textrank ในอดีต ประการที่สองยิ่งข้อความต้นฉบับนานเท่าไหร่ก็ยิ่งเป็นแกนกลางของเนื้อหานั่นก็คือเสียงรบกวน ไม่ใช่เรื่องง่ายที่จะระบุว่าอะไรคือเสียงรบกวนและสิ่งที่ให้ข้อมูล ในที่สุดข้อความยาวและแหล่งข้อมูลต่าง ๆ มีมุมมองและเนื้อหาที่หลากหลายในเวลาเดียวกันทำให้ยากที่จะสร้างบทสรุปที่ครอบคลุมได้ดี
การสรุปเอกสารหลายฉบับ (MDS)
MDS เป็น บทสรุปของเอกสารส่วนใหญ่ เมื่อมองแวบแรกมันจะเป็นเรื่องยากที่จะสรุปบทความของมุมมองที่แตกต่างกันของผู้เขียนหลายคนมากกว่าที่จะสรุปเอกสารที่อธิบายธีมเดียวจากแนวโน้มและมุมมองที่สอดคล้องกัน แน่นอนแม้ในกรณีของ MDS มันมักจะขึ้นอยู่กับเอกสารคลัสเตอร์เดียวกันที่เกี่ยวข้องกับหัวข้อที่คล้ายกัน แต่มันไม่ง่ายที่จะระบุข้อมูลที่สำคัญและตัวกรองข้อมูลที่ไม่มีอยู่ในเอกสารจำนวนมาก
งานที่สรุปความคิดเห็นเกี่ยวกับผลิตภัณฑ์บางอย่างเป็นตัวอย่างของ MDS ที่ง่ายที่สุดในการคิด งานนี้มักจะเรียกว่าการสรุปความคิดเห็นนั้นมีความยาวข้อความสั้น ๆ และความเป็นส่วนตัว งานของการสร้างเอกสาร Wiki ยังถือได้ว่าเป็น MDS Liu et al. (2018) เป็นข้อความต้นฉบับของข้อความเว็บไซต์ในเอกสาร Wiki ซึ่งเป็นข้อความต้นฉบับซึ่งถือว่าเป็นบทสรุปและสร้างรูปแบบการสร้างวิกิ
การสรุปเอกสารยาว
Liu et al. (2018) เป็นวิธีทางสถิติในการยอมรับข้อความยาวเป็นอินพุตสร้างสรุปการแยกโดยใช้ประโยคที่สำคัญเท่านั้นและใช้เป็นอินพุตของโมเดล นอกจากนี้เพื่อลดปริมาณการคำนวณหม้อแปลงอินพุตจะถูกแบ่งออกเป็นหน่วยบล็อกและในเวลานี้การประชุม 1-D ใช้วิธีการเข้าร่วมที่ลดจำนวนคีย์และค่าความสนใจส่วนบุคคล กระดาษบิ๊กเบิร์ด (2020) แนะนำกลไกการเข้าร่วมที่กระจัดกระจาย (เชิงเส้น) แทนที่จะเป็นการรวมกันของคำที่มีอยู่ทั้งหมดเพื่อลดการคำนวณของหม้อแปลง เป็นผลให้ฮาร์ดแวร์ประสิทธิภาพเดียวกันได้รับการสรุปนานถึงแปดเท่า
ในทางกลับกัน Gidiotis & Tsoumakas (2020) พยายามที่จะเข้าใกล้การแบ่งแยกและพิชิตซึ่งไม่ได้แก้ปัญหาสรุปข้อความยาวในครั้งเดียวและเปลี่ยนเป็นบทสรุปข้อความเล็ก ๆ หลายรายการ การฝึกอบรมแบบจำลองโดยการเปลี่ยนข้อความต้นฉบับและสรุปเป้าหมายเป็นคู่เป้าหมายขนาดเล็กขนาดเล็กหลายคู่ ในการอนุมานเรารวมเอาท์พุทสรุปบางส่วนผ่านโมเดลนี้เพื่อสร้างบทสรุปที่สมบูรณ์
การปรับปรุงประสิทธิภาพ
คุณจะสร้างบทสรุปที่ดีกว่าได้อย่างไร?
ถ่ายโอนการเรียนรู้
เมื่อเร็ว ๆ นี้การใช้รูปแบบการเตรียมการใน NLP ได้กลายเป็นค่าเริ่มต้นเกือบแล้ว ดังนั้นโครงสร้างแบบไหนที่เราควรสร้างแบบจำลองก่อนหน้านี้สามารถแสดงประสิทธิภาพที่ดีขึ้นในการสรุปข้อความ? ฉันควรมีวัตถุอะไร?
ใน Pegasus (2020) วิธีการสร้างประโยค GSG (GAP ประโยค) ซึ่งเลือกประโยคที่ถือว่ามีความสำคัญตามคะแนน Rouge ถือว่าคล้ายกับกระบวนการสรุปข้อความมากขึ้นและการคัดค้านจะแสดงประสิทธิภาพที่สูงขึ้น โมเดล SOTA ปัจจุบัน, BART (2020) (Transformers แบบสองทิศทางและอัตโนมัติ) เรียนรู้ในรูปแบบของ AutoEncoder ที่เพิ่มเสียงรบกวนให้กับข้อความอินพุตบางส่วนและเรียกคืนเป็นข้อความต้นฉบับ
การสร้างข้อความที่เพิ่มความรู้
ในงานข้อความเป็นข้อความมักจะยากที่จะสร้างผลลัพธ์ที่ต้องการด้วยข้อความต้นฉบับเพียงอย่างเดียว ดังนั้นจึงมี ความพยายามที่จะปรับปรุงประสิทธิภาพโดยการให้ความรู้ที่หลากหลายแก่โมเดลรวมถึงข้อความต้นฉบับ แหล่งที่มาหรือบทบัญญัติของความรู้เหล่านี้แตกต่างกันไปในประเภทของคำหลักหัวข้อคุณสมบัติทางภาษาศาสตร์ฐานความรู้กราฟความรู้และข้อความที่ต่อสายดิน
ตัวอย่างเช่น Tan, Qin, Xing, & Hu (2020) ส่งชุดข้อมูล Summry ทั่วไปเพื่อแปลงส่วนใหญ่ของการสรุปอิงตามและให้ข้อมูลที่หลากหลายมากขึ้นที่เกี่ยวข้องกับแง่มุมที่กำหนดให้กับโมเดลที่กำหนด ใช้ Wikipedia สำหรับ หากคุณต้องการทราบเพิ่มเติมมากขึ้น Yu et al อ่านกระดาษสำรวจที่เขียนโดย (2020)
โพสต์การแก้ไข
มันจะเป็นการดีที่จะสร้างบทสรุปที่ดีในครั้งเดียว แต่ก็ไม่ใช่เรื่องง่าย แล้วทำไมคุณไม่สร้างบทสรุปจากนั้นตรวจสอบและแก้ไขในเกณฑ์ที่หลากหลาย?
ตัวอย่างเช่น Cao, Dong, Wu, & Cheung (2020) แนะนำวิธีการลดข้อผิดพลาดจริงโดยใช้แบบจำลองการแก้ไขระบบประสาทที่เรียกว่าบทสรุปที่สร้างขึ้น
นอกจากนี้ยังมีความพยายามมากมายที่จะใช้ ** กราฟประสาทเครือข่าย (GNN) ** ซึ่งได้รับความสนใจเป็นอย่างมากเมื่อเร็ว ๆ นี้
ปัญหาความขาดแคลนข้อมูล
บทสรุปข้อความเป็นงานที่ใช้เวลามากซึ่งไม่ใช่เรื่องง่ายสำหรับมนุษย์ ดังนั้นเมื่อเปรียบเทียบกับงานอื่น ๆ ค่าใช้จ่ายค่อนข้างมากในการสร้างชุดข้อมูลที่มีป้ายกำกับและแน่นอนว่าไม่มีข้อมูลสำหรับการฝึกอบรม
นอกเหนือจากวิธี การเรียนรู้การถ่ายโอน โดยใช้รูปแบบการฝึกอบรมก่อนหน้านี้เรากำลังเรียนรู้ใน การเรียนรู้ที่ไม่ได้รับการดูแล หรือวิธี การเรียนรู้การเสริมแรง หรือพยายามใช้วิธี การเรียนรู้สองสามครั้ง
โดยธรรมชาติแล้วการทำข้อมูลสรุปที่ดีก็เป็นหัวข้อการวิจัยที่สำคัญมาก โดยเฉพาะอย่างยิ่งชุดข้อมูลที่เกี่ยวข้องกับการสรุปปัจจุบันจำนวนมากนั้นมีอคติในประเภทข่าวในภาษาอังกฤษ เป็นผลให้มีการสร้างชุดข้อมูลหลายภาษาเช่น WikilingUA และ MLSUM สำหรับข้อมูลเพิ่มเติมลองดูที่ MLSUM: คลัง ข้อมูลสรุป หลายภาษา
วิธี การวัด / ประเมินผล
ฉันเขียนการแสดงออกของ 'ดี' ก่อนหน้านี้ 'สรุปที่ดี' คืออะไร? Brazinskas, Lapata, & Titov (2020) ใช้ห้าสิ่งต่อไปนี้ตามการตัดสินของการสรุปที่ดี
ปัญหาคือการวัดชิ้นส่วนเหล่านี้ไม่ใช่เรื่องง่าย ตัวบ่งชี้การวัดประสิทธิภาพที่พบบ่อยที่สุดในบทสรุปข้อความคือคะแนนรูจ มีหลายตัวแปรในคะแนน Rouge แต่โดยทั่วไปแล้ว 'คำของคำของบทสรุปและการอ้างอิงที่สร้างขึ้นเป็นอย่างไร?' มันหมายถึงคล้ายกัน แต่ถ้าคุณมีรูปแบบที่แตกต่างกันหรือหากคำสั่งซื้อเปลี่ยนแปลงคุณจะได้คะแนนต่ำกว่าแม้ว่าจะเป็นบทสรุปที่ดีกว่าก็ตาม โดยเฉพาะอย่างยิ่งการพยายามเพิ่มคะแนนรูจอาจส่งผลให้เกิดอันตรายต่อความหลากหลายของการแสดงออกของบทสรุป นี่คือเหตุผลที่เอกสารจำนวนมากให้ผลการประเมินผลของมนุษย์เพิ่มเติมด้วยเงินที่มีราคาแพงรวมถึงคะแนน Rouge
Lee et al. (2020) นำเสนอคะแนนความหมาย RDASS (การอ้างอิงและการรับรู้เอกสาร) ซึ่งเป็นวิธีที่คล้ายกันกับข้อความและการอ้างอิงสรุปจากนั้นวัดโดยเวกเตอร์ -ถนนที่คล้ายกัน วิธีนี้คาดว่าจะเพิ่มความแม่นยำของการประเมินภาษาเกาหลีซึ่งรวมคำและสัณฐานวิทยาต่าง ๆ เพื่อแสดงความหมายและฟังก์ชั่นไวยากรณ์ต่างๆ Kryściński, McCann, Xiong, & Socher (2020) เสนอวิธีการแบบจำลองที่ไม่ได้รับการสนับสนุนอย่างอ่อน
การสร้างข้อความที่ควบคุมได้
มีบทสรุปที่ดีที่สุดเพียงอย่างเดียวเกี่ยวกับเอกสารที่กำหนดหรือไม่? มันจะไม่ ผู้ที่มีความโน้มเอียงที่แตกต่างกันสามารถเลือกข้อความสรุปที่แตกต่างกันสำหรับข้อความเดียวกัน แม้ว่าคุณจะเป็นคนเดียวกัน แต่บทสรุปที่คุณต้องการจะขึ้นอยู่กับวัตถุประสงค์ของการสรุปหรือสถานการณ์ วิธีการปรับเอาต์พุตเป็นแบบฟอร์มที่ต้องการนี้ตามเงื่อนไขที่ระบุโดยผู้ใช้ เรียกว่า การสร้างข้อความที่ควบคุมได้ คุณสามารถให้ข้อมูลสรุป ส่วนบุคคล เมื่อเทียบกับ การสรุปทั่วไป ที่สร้างบทสรุปเดียวกันสำหรับเอกสารที่กำหนด
บทสรุปที่สร้างขึ้นไม่เพียง แต่ง่ายต่อการเข้าใจและคุณค่า แต่ยัง เกี่ยวข้องกับเงื่อนไขที่คุณรวบรวมไว้อย่างใกล้ชิด
f(text, condition ) = comprehensible information that meets the given conditions
ฉันสามารถเพิ่ม เงื่อนไข ใดในแบบจำลองสรุปได้? และคุณจะสร้างบทสรุปที่เหมาะสมกับเงื่อนไขนั้นได้อย่างไร?
การสรุปอิง
เมื่อสรุปความคิดเห็นของผู้ใช้ AirPod คุณอาจต้องการสรุปแต่ละด้านด้วยการหารคุณภาพเสียงแบตเตอรี่และการออกแบบ หรือคุณอาจต้องการปรับสไตล์การเขียนหรือความเชื่อมั่นในบทความ ในข้อความต้นฉบับนี้ งานที่สรุปเฉพาะข้อมูลที่เกี่ยวข้องกับแง่มุมเฉพาะหรือคุณสมบัติ ที่เรียกว่า การสรุปอิงตาม
ก่อนหน้านี้มีเพียงแบบจำลองที่ทำงานเฉพาะในแง่มุมที่กำหนดไว้ล่วงหน้าซึ่งส่วนใหญ่ใช้สำหรับการเรียนรู้แบบจำลองตอนนี้พยายามที่จะให้ เหตุผลในแง่มุมโดยพลการ ซึ่งไม่ได้ให้การเรียนรู้เช่น Tan, Qin, Xing, & Hu (2020)
การสืบค้นที่เน้นการสรุป (QFS)
หาก เงื่อนไข เป็น แบบสอบถาม จะเรียกว่า QFS แบบสอบถามเป็นภาษาธรรมชาติเป็นหลัก ดังนั้นภารกิจหลักคือวิธีการแสดงออกที่หลากหลายเหล่านี้และจับคู่กับข้อความต้นฉบับ มันค่อนข้างคล้ายกับระบบ QA ที่เรารู้จักดี
อัปเดตการสรุป
มนุษย์เป็นสัตว์ที่ยังคงเรียนรู้และเติบโต ดังนั้นมูลค่าของวันนี้สำหรับข้อมูลบางอย่างอาจแตกต่างจากมูลค่าของสัปดาห์ต่อมา มูลค่าของเนื้อหาในเอกสารที่ฉันได้รับแล้วจะลดลงและเนื้อหาใหม่ที่ยังไม่ได้รับประสบการณ์ แต่จะยังคงมีมูลค่าสูง จากมุมมองนี้เรียกว่า การสรุปการอัปเดต เพื่อสร้างสรุปใหม่ของเนื้อหาใหม่ที่คล้ายกับเนื้อหาเอกสารที่ผู้ใช้เคยพบมาก่อนหน้านี้
Ctrlsum ใช้คำหลักหรือพรอมต์เชิงพรรณนาด้วยข้อความเพื่อปรับบทสรุปที่สร้างขึ้น มันเป็นรูปแบบการสรุปข้อความที่ควบคุมได้ทั่วไปมากขึ้นซึ่งแสดงผลลัพธ์เช่นเดียวกับการควบคุมสำหรับคำหลักหรือการแจ้งเตือนที่ไม่ได้เรียนรู้อย่างชัดเจนในขั้นตอนการฝึกอบรม คุณสามารถใช้งานได้อย่างง่ายดายผ่านห้องสมุดสรุปของ Koh Hyun -woong
นอกจากนี้ความพยายามที่หลากหลายในการสร้างแบบจำลองสรุปที่เหมาะสำหรับ การสรุปการสนทนามากกว่าหัวข้อ DL ทั่วไปเช่น ** Model Lightweight รวมถึงบทสนทนาบทสนทนา มากกว่าข้อความที่มีโครงสร้างเช่นข่าวหรือ Wikipedia มีหัวข้อ
หากคุณรู้สิ่งต่อไปนี้ในฟิลด์สรุปข้อความคุณจะสามารถเรียนได้ง่ายขึ้น
ทำความเข้าใจแนวคิดพื้นฐานของ NLP
โครงสร้างหม้อแปลง/เบิร์ตและความเข้าใจวัตถุประสงค์ก่อนการฝึกอบรม
เอกสาร NLP ล่าสุดจำนวนมากขึ้นอยู่กับรุ่นก่อนหลายรุ่นรวมถึง Bert ซึ่งใช้หม้อแปลงและ Roberta และ T5 ซึ่งเป็นตัวแปรของเบิร์ตนี้ ดังนั้นหากคุณเข้าใจโครงสร้างแผนผังและวัตถุประสงค์ก่อนการฝึกอบรมมันเป็นความช่วยเหลือที่ดีในการอ่านหรือนำกระดาษ
การสรุปข้อความแนวคิดพื้นฐาน
Graph Neural Network (GNN)
การแปลด้วยเครื่อง (MT)
MT เป็นหนึ่งในงานที่ใช้งานมากที่สุดในฟิลด์ NLP เนื่องจากการเกิดขึ้นของ SEQ2SEQ หากคุณดูที่กระบวนการสรุปเป็นกระบวนการแปลงข้อความหนึ่งเป็นข้อความประเภทต่าง ๆ มันสามารถมองเห็นได้ว่าเป็น MT ชนิดหนึ่งของการศึกษาที่เกี่ยวข้องกับ MT และความคิดจำนวนมากมีแนวโน้มที่จะยืมหรือนำไปใช้ในสาขาสรุป
| ปี | กระดาษ | คำสำคัญ |
|---|---|---|
| พ.ศ. 2547 แบบอย่าง | Textrank : นำคำสั่งมาเป็นข้อความ R. Mihalcea, P. Tarau มันเป็นคลาสสิกในภาคการสกัดและยังคงทำงานอยู่ ในสมมติฐานที่ว่าประโยคสำคัญภายในเอกสาร (เช่นรวมอยู่ในบทสรุป) เป็นอัลกอริทึม PageRank แนวคิดเริ่มต้นของเครื่องมือค้นหาของ Google โดยสมมติว่ามันจะมีความคล้ายคลึงกับประโยคอื่น ๆ แต่ละประโยคกำหนดค่ากราฟถ่วงน้ำหนักระดับประโยคเพื่อคำนวณความคล้ายคลึงกันกับประโยคอื่นในเอกสารและรวมถึงประโยคน้ำหนักสูงนี้ในบทสรุป วิธีการเรียนรู้ที่ไม่ได้รับการสนับสนุนทางสถิติสามารถมีเหตุผลได้โดยไม่ต้องใช้ข้อมูลการเรียนรู้แยกต่างหากและอัลกอริทึมนั้นชัดเจนและเข้าใจง่าย - [Library] Gensim.summarization (มีเพียง 3.x เวอร์ชันเท่านั้นลบออกจากเวอร์ชัน 4.x), pytextrank - [ทฤษฎี/รหัส] Lovit การสกัดคำหลักโดยใช้ TextTrank และ Core Sentence Extract | ต่อ กราฟอิง (Pagerank) ไม่ได้รับอนุญาต |
| 2019 แบบอย่าง | Bertsum : การสรุปข้อความด้วย encoders ที่เรียกว่า (OfficeAd) Yang Liu, Mirella Lapata / Emnlp 2019 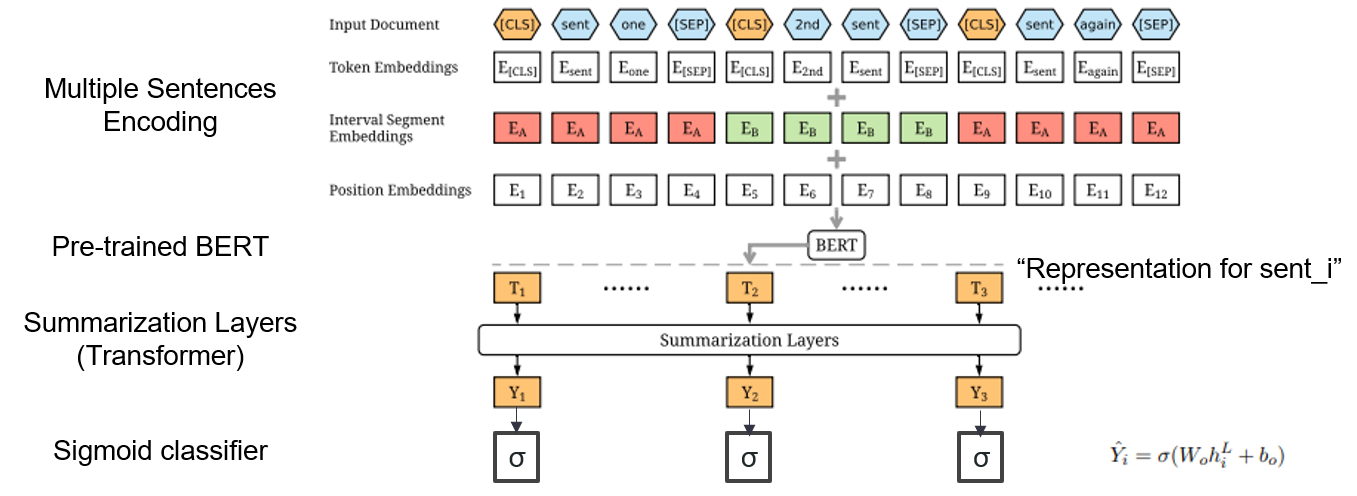 ฉันจะใช้เบิร์ตที่ผ่านการฝึกอบรมมาก่อนได้อย่างไร ฉันจะใช้เบิร์ตที่ผ่านการฝึกอบรมมาก่อนได้อย่างไรBertsum แนะนำการฝังอินพุตที่แก้ไขซึ่งแทรกโทเค็น [CLS] ที่ด้านหน้าของแต่ละประโยคและเพิ่มส่วนที่ฝังช่วงเวลาเพื่อเพิ่มหลายประโยคลงในอินพุตหนึ่งอินพุต โมเดล EXT ใช้โครงสร้างตัวเข้ารหัสที่มีเลเยอร์หม้อแปลงบนเบิร์ตและโมเดล ABS ใช้โมเดลตัวเข้ารหัสเครื่องเข้ารหัสที่มีตัวถอดรหัสหม้อแปลง 6 ชั้นบนโมเดล EXT - [รีวิว] Lee Jung -Hoon (Koreauniv DSBA) - [เกาหลี] Kobertsum | ext/abs Bert+Transformer การปรับแต่ง 2 ขั้นตอน |
| 2019 รูปแบบการเตรียมการ | Bart : denoising sequence to-sequence pre-training สำหรับการสร้างภาษาธรรมชาติการแปลและความเข้าใจ Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer / ACL 2020 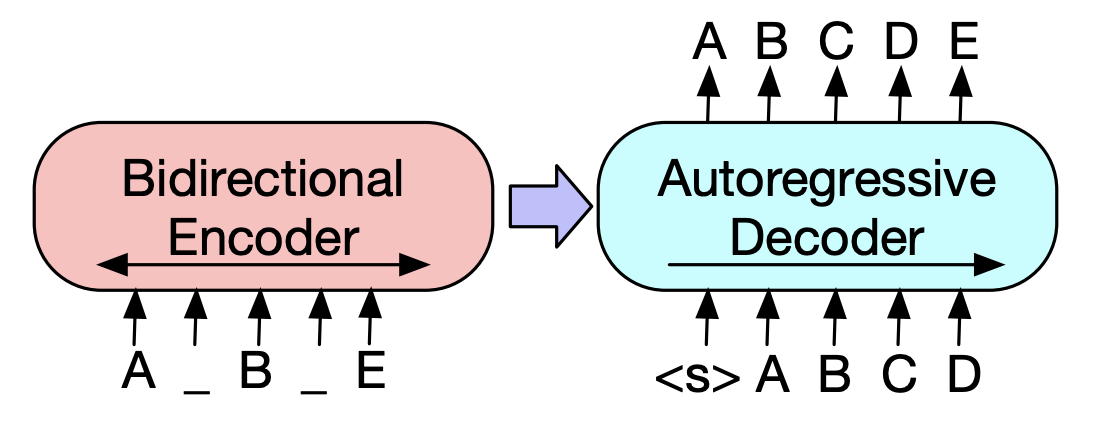 เบิร์ตเป็นเครื่องเข้ารหัสแบบ bidirectrical อ่อนแอต่องานสร้างและ GPT มีข้อเสียที่ว่าไม่ได้รับข้อมูลแบบ bitirected ด้วยโมเดลการถดถอยอัตโนมัติ เบิร์ตเป็นเครื่องเข้ารหัสแบบ bidirectrical อ่อนแอต่องานสร้างและ GPT มีข้อเสียที่ว่าไม่ได้รับข้อมูลแบบ bitirected ด้วยโมเดลการถดถอยอัตโนมัติBART มีแบบฟอร์ม SEQ2SEQ ที่รวมเข้าด้วยกันดังนั้นคุณสามารถทดลองใช้เทคนิคต่าง ๆ ที่บอกได้ในรุ่นเดียว เป็นผลให้ข้อความที่แทรกซึม (เปลี่ยนช่วงข้อความเป็นโทเค็นหน้ากากหนึ่งตัว) และการสับประโยค (การผสมประโยคแบบสุ่ม) แสดงประสิทธิภาพที่เหนือกว่าโมเดล Ki Sota ในสาขาการสรุป - [เกาหลี] SKT T3K โคคาร์ต -[รีวิว] Jin Myung -Hoon_Video, Lim Yeon -Soo_ เขียนโดย Jiwung Hyun_ | หน้าท้อง seq2seq denoising autoencoder ข้อความแทรกซึม |
| 2020 แบบอย่าง | MatchSum : การสรุปการสกัดเป็นการจับคู่ข้อความ (Office) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang / ACL 2020 - [รีวิว] Yoo Kyung (Koreauniv DSBA) | ต่อ |
| 2020 เทคนิค | การสรุปข้อความในทุกแง่มุม: วิธีการที่ไม่ได้รับความรู้อย่างอ่อนความรู้ (รหัสอย่างเป็นทางการ) Bowen Tan, Lianhui Qin, Eric P. Xing, Zhiting Hu / Emnlp 2020 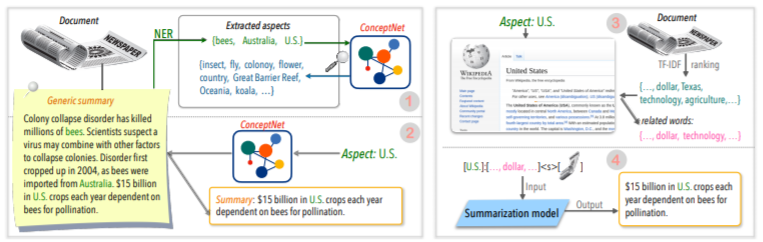 การสรุปอิงตามมุมมองเป็นงานที่ไม่ใช่เรื่องง่ายในการทำงานเฉพาะในด้านข้อมูลที่กำหนดไว้ล่วงหน้าซึ่งเรียนรู้แม้ว่าคุณจะเรียนรู้โมเดลและ 2) ขาดข้อมูลสรุปหลายแง่มุม บทความนี้ใช้แหล่งความรู้ภายนอกเพื่อแก้ปัญหานี้ -ผ่านสองขั้นตอนเพื่อแปลงสรุปทั่วไปเป็นบทสรุปหลายด้าน ก่อนอื่นเพื่อเพิ่มจำนวนแง่มุมเอนทิตีที่สกัดจากบทสรุปทั่วไปคือเมล็ดและสกัดจาก Concepnet ไปยังเพื่อนบ้านและพิจารณาว่าแต่ละคนเป็นมุมมอง เราใช้ Concepnet อีกครั้งเพื่อสร้างบทสรุป Psedo สำหรับแต่ละแง่มุมเหล่านี้ แยกเอนทิตีรอบ ๆ ที่เชื่อมต่อกับแง่มุมที่สอดคล้องกันใน Concepnet และแยกเฉพาะประโยคที่มีอยู่ภายในบทสรุปทั่วไป นี่ถือเป็นบทสรุปสำหรับเอนทิตีนั้น (แง่มุม) -วิกิพีเดียใช้เพื่อส่งมอบข้อมูลมากมายที่เกี่ยวข้องกับแง่มุมที่กำหนดให้กับโมเดล โดยเฉพาะอย่างยิ่งในบรรดาคำที่ปรากฏในเอกสารคะแนน TF-IDF ในเอกสารสูงและในเวลาเดียวกันและในเวลาเดียวกันรายการ 10 คำในหน้า Wikipedia สอดคล้องกับแง่มุมนั้นจะถูกเพิ่มเข้าไปในแง่มุมของอินพุตแบบจำลอง ด้วยวิธีนี้โมเดล pre-peraling ก่อนการปรับแต่ง (BART) ก็ยอดเยี่ยมสำหรับแง่มุมโดยพลการด้วยข้อมูลขนาดเล็ก | อิงตามมุมมอง มีความรู้มากมาย |
| 2020 ทบทวน | การสรุปข้อความในไม่ช้าเรามีอะไรบ้าง? Dandan Huang, Leyang Cui, Sen Yang, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang / EMNP 2020 นอกเหนือจากคะแนน Rouge แล้วยังมีการประเมินแบบจำลองตัวแทน 10 แบบตาม 8 Metrics (polytope) ที่เกี่ยวข้องกับความแม่นยำและความคล่องแคล่ว เพื่อสรุปผลลัพธ์ -วิธีการตามกฎแบบดั้งเดิมยังคงถูกต้องเป็นพื้นฐาน ภายใต้การตั้งค่าที่คล้ายกันโดยทั่วไป โมเดล EXT จะแสดงประสิทธิภาพที่ดีขึ้นในความซื่อสัตย์และความสม่ำเสมอตามข้อเท็จจริง ข้อบกพร่องที่สำคัญคือความไม่สะดวกสำหรับแบบจำลองการสกัดและการละเว้นและภาพหลอนภายในสำหรับแบบจำลองเชิงนามธรรม - โครงสร้างที่ซับซ้อนมากขึ้นเช่นหม้อแปลง สำหรับการสร้างการเป็นตัวแทนประโยคนั้นไม่ได้มีประโยชน์มากนักยกเว้นปัญหาการทำซ้ำ -Copy ( Pointer-Generator ) เป็นรายละเอียดการทำซ้ำซึ่งแก้ปัญหาการทำซ้ำระดับคำได้อย่างมีประสิทธิภาพโดยการผสมมันรวมถึงความไม่ถูกต้องภายใน แต่มีแนวโน้มที่จะทำให้เกิดความซ้ำซ้อนในระดับหนึ่ง ความครอบคลุม เป็นระยะขอบขนาดใหญ่ซึ่งช่วยลดข้อผิดพลาดการทำซ้ำ (การทำซ้ำ) แต่ในเวลาเดียวกันจะเพิ่มข้อผิดพลาดในการเพิ่มและความไม่ถูกต้อง -Hybrid Model ซึ่งเป็น ABS หลังจาก ext นั้นดีสำหรับการเรียกคืน แต่อาจมีปัญหาเกี่ยวกับข้อผิดพลาดที่ไม่ถูกต้องเพราะมันสร้างสรุปผ่านข้อความต้นฉบับบางส่วน (ตัวอย่างที่แยกออกมา) การฝึกอบรมล่วงหน้าโดยเฉพาะอย่างยิ่งโมเดลตัวเข้ารหัส (BART) มากกว่ารุ่นเข้ารหัสเท่านั้น (bertsumextabs) มีประสิทธิภาพมากในการสรุป สิ่งนี้ชี้ให้เห็นว่าการได้รับความเข้าใจและการสร้างอินพุตทั้งหมดมีประโยชน์มากสำหรับการเลือกเนื้อหาและการรวมกัน ในเวลาเดียวกันในขณะที่รุ่น ABS ส่วนใหญ่มุ่งเน้นไปที่ประโยคด้านหน้าบาร์ตกำลังดูข้อความต้นฉบับทั้งหมดซึ่งดูเหมือนจะเป็นผลของการสับประโยคในระหว่างการทำล่วงหน้า 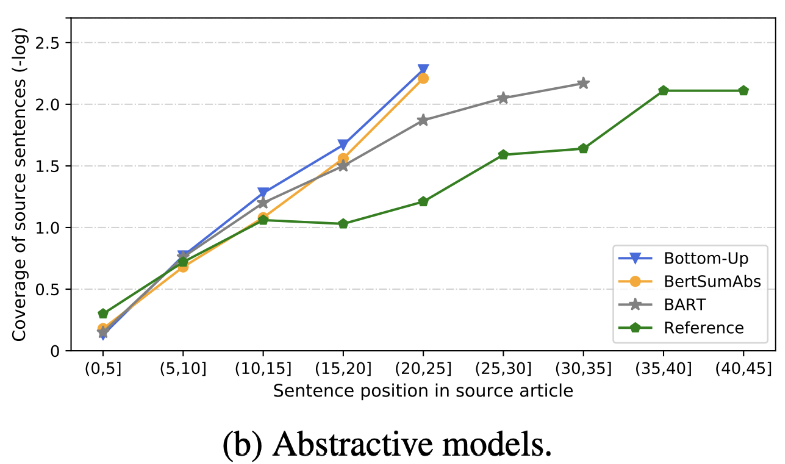 - [รีวิว] Kim Han -Gil, Heo Hoon | ทบทวน |
| 2020 แบบอย่าง | Ctrlsum : ไปสู่การสรุปข้อความทั่วไป (รหัสอย่างเป็นทางการ) Junxian He, Wojciech Kryściński, Bryan McCann, Nazneen Rajani, Caiming Xiong CtrlSum เป็นรูปแบบการสรุปข้อความที่ควบคุมได้ซึ่งช่วยให้คุณสามารถปรับคำสั่งสรุปที่สร้างขึ้นผ่านคำหลักหรือพรอมต์เชิงพรรณนา การฝึกอบรม: เพื่อสร้างชุดข้อมูลสรุปที่ใช้คำหลักได้โดยการแก้ไขข้อมูลสรุปทั่วไปเลือกลำดับย่อยซึ่งคล้ายกับบทสรุปมากที่สุดและแยกคำหลักที่นั่น ใส่สิ่งนี้ลงในอินพุตด้วยเอกสารและเสร็จสิ้นบาร์ตก่อนการปรับแต่ง 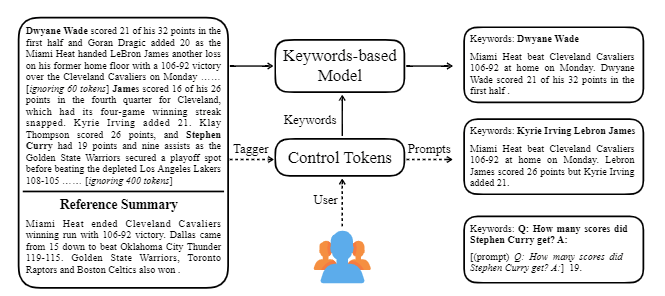 -Inperence: ดังที่แสดงในภาพด้านล่างคุณสามารถเพิ่มบทสรุปของบทสรุปเช่นการสร้างบทสรุปของเอนทิตีเฉพาะปรับความยาวสรุปหรือสร้างการตอบกลับคำถาม เป็นที่น่าสังเกตว่ามันใช้งานได้ราวกับว่ามันไม่ได้เรียนรู้การแจ้งเตือนดังกล่าวอย่างชัดเจนในขั้นตอนการสร้างแบบจำลอง แต่ก็ใช้งานได้ราวกับว่ามันจะเข้าใจพร้อมที่จะสร้างบทสรุป คล้ายกับ GPT-3 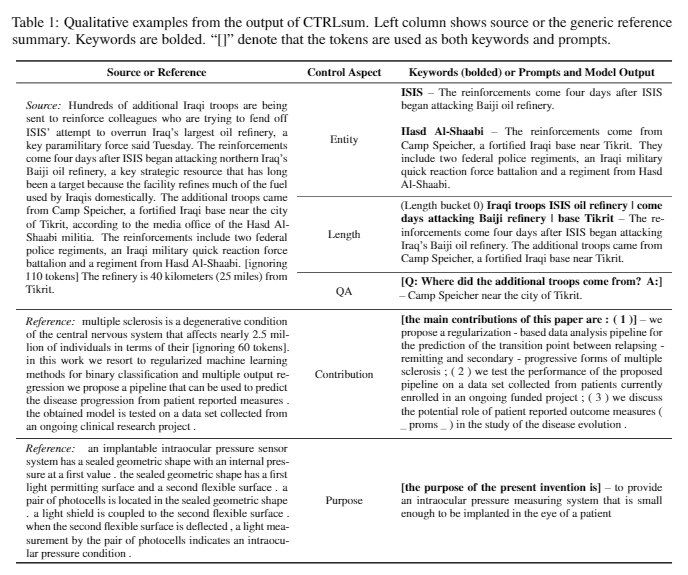 - [ไลบรารี] แพ็คเกจสำหรับการสรุปที่สามารถควบคุมได้ Ctrlsum | ควบคุมได้ บาร์ต |
Paper Digest: เอกสารล่าสุดเกี่ยวกับการสรุปข้อความ
เอกสารที่มีรหัส: เอกสารล่าสุด
EMNLP 2020 Papers-Summarization
ในความเป็นจริงเราได้สรุปรหัสข้อมูลและโมเดล preitrain ที่จำเป็นในการสร้างและฝึกฝนแบบจำลองสรุป ส่วนใหญ่เป็นข้อมูลเกาหลีและสำหรับวัสดุที่เกี่ยวข้องกับภาษาอังกฤษโปรดดูส่วนรหัสของกระดาษแต่ละชิ้นในรายการเอกสาร
ความหมายของผู้อ่อนแอที่ใช้ด้านล่างมีดังนี้
w : ค่าเฉลี่ยของจำนวนคำ; s : ค่าเฉลี่ยของจำนวนประโยคเฉลี่ย
ตัวอย่าง) 13s/214w → 1s/26w หมายความว่ามันให้ข้อความสรุปประกอบด้วยค่าเฉลี่ย 13 ประโยค (เฉลี่ย 214 คำ) และค่าเฉลี่ยของหนึ่งประโยค (26 คำเฉลี่ย)
สรุป abs ; ext : สรุปสกัด
| ชุดข้อมูล | โดเมน / ความยาว | ปริมาณ (คู่) | ใบอนุญาต |
|---|---|---|---|
| สรุปเอกสารคำพูดของทุกคน ชื่อข้อความข่าวสั้น 3 ประโยค abs และ summay ext คำพูดทั้งหมดของทุกคนที่มี ID-combined กับม้าหนังสือพิมพ์คุณสามารถรับข้อมูลเพิ่มเติมที่เกี่ยวข้องกับคำบรรยายสื่อวันที่และหัวข้อ | ข่าว -origin → 3s (abs); 3S (ext) | 13,167 | สถาบันภาษาเกาหลีแห่งชาติ (สัญญาส่วนบุคคล) |
| ข้อความสรุปเอกสาร AIHUB ABS และ EXT Summay สำหรับบทความในหนังสือพิมพ์ผลงานบทความนิตยสารและบทวิจารณ์ของศาล - [eda] สมุดบันทึกข้อมูล EDA -สรุปการสกัดเอกสารการสกัดเอกสารสรุปและการประกวด AI สรุป AI (~ 20.12.09) | -บทความในหนังสือพิมพ์ 300,000, 60,000 การบริจาค, บทความนิตยสาร 10,000 บทความ, การพิจารณาคดีของศาล 30,000 13S/214W → 1S/26W (ABS); 3S/55W (EXT) | 400,000 | AIHUB (สัญญาส่วนบุคคล) |
| Aihub-summary สรุป ABS โดยทั้งหมดและส่วนสำหรับเอกสารทางวิชาการและข้อกำหนดสิทธิบัตร | -เอกสารทางวิชาการข้อกำหนดสิทธิบัตร -Origin → ABS | 350,000 | AIHUB (สัญญาส่วนบุคคล) |
| สรุปข้อมูล Aihub-Book สรุป ABS สำหรับหนังสือภาษาเกาหลีต้นฉบับในหัวข้อต่าง ๆ | -ชีวิต, ชีวิต, ภาษี, สิ่งแวดล้อม, การพัฒนาชุมชน, การค้า, เศรษฐกิจ, แรงงาน, ฯลฯ -300-1000 อักขระ→ ABS | 200,000 | AIHUB (สัญญาส่วนบุคคล) |
| SAE4K | 50,000 | CC-BY-SA-4.0 | |
| Sci-News-Sum-KR-50 | ข่าว (ไอที/วิทยาศาสตร์) | 50 | มิกซ์ |
| Wikilingua : ชุดข้อมูลการสรุปแบบนามธรรมหลายภาษา (2020) ขึ้นอยู่กับไซต์คู่มือ WikiHow 18 ภาษาเช่นภาษาเกาหลีและภาษาอังกฤษ -กระดาษ, สมุดบันทึกร่วมมือกัน | -เอกสารได้อย่างไร -391W → 39W | 12,189 (KOR ทั้งหมด 770,087) | 2020, CC BY-NC-SA 3.0 |
| ชุดข้อมูล | โดเมน / ความยาว | ปริมาณ | ใบอนุญาต |
|---|---|---|---|
| scisummnet (กระดาษ) ให้สรุปสามประเภทสำหรับการวิจัย ACL (NLP) -CL-SCISUMM 2019-TASK2 (repo, Paper) -cl-scisumm @ emnlp 2020-task2 (repo) | -Research Paper (นักภาษาศาสตร์คำนวณ, NLP) 4,417W → 110W (บทคัดย่อกระดาษ); 2S (การอ้างอิง); 151W (ABS) | 1,000 (ABS/ EXT) | CC BY-SA 4.0 |
| Longsumm บทสรุปที่ค่อนข้างยาว (โพสต์บล็อกที่เกี่ยวข้อง -ABS ตามการประชุมการประชุมที่เกี่ยวข้องการพูดคุยวิดีโอ) -longsumm 2020@EMNLP 2020 -longsumm 2021@ NAACL 2021 | -Research Paper (NLP, ML) -Origin → 100S/1,500W (ABS); 30S/ 990W (EXT) | 700 (abs) + 1,705 (ext) | Attribution-Noncommercial-Sharealike 4.0 |
| CL-Laysumm ให้เลเยอร์ง่าย ๆ สำหรับไม่มืออาชีพสำหรับฟิลด์ NLP และ ML -cl-laysumm @ emnlp 2020 | -Research Paper (โรคลมชัก, โบราณคดี, วิศวกรรมวัสดุ) -Origin → 70 ~ 100W | 600 (abs) | ความต้องการข้อตกลงส่วนบุคคล (ส่งอีเมลไปที่ [email protected]) |
| เสียงทั่วโลก : ข้ามพรมแดนในการสรุปข่าวอัตโนมัติ (2019) -กระดาษ | - ข่าว -359W → 51W | ||
| MLSUM : คลังข้อมูลสรุปหลายภาษา คล้ายกับชุดข้อมูล CNN/Daily Mail, ไฮไลท์/คำอธิบายในบทความข่าวถือเป็นบทสรุปและสรุปสำหรับภาษาอังกฤษ, ฝรั่งเศส, เยอรมนี, สเปน, รัสเซีย, ชุดข้อมูลการสร้างตุรกี -Paper, ใช้ (HuggingFace) | - ข่าว -790W → 56W (EN พื้นฐาน) | 1.5m (ABS) | วัตถุประสงค์การวิจัยที่ไม่ใช่เชิงพาณิชย์เท่านั้น |
| แบบอย่าง | การฝึกอบรมล่วงหน้า | การใช้งาน | ใบอนุญาต |
|---|---|---|---|
| เบิร์ต (หลายภาษา) Bert-base (พารามิเตอร์ 110m) | -Wikipedia (หลายภาษา) -wordpiece คำศัพท์ที่ใช้ร่วมกัน -110k | BERT-Base, Multilingual Cased ที่แนะนำ( --do_lower_case=false )-tensorflow | Google (Apache 2.0) |
| โคเบิร์ต bert-base (พารามิเตอร์ 92m) | -Wikipedia (ประโยค 5m), ข่าว (ประโยค 20m) -Sentencepiece 8,002 คำศัพท์ (ไม่ใช้โทเค็นที่ไม่ได้ใช้) | -pytorch -มีให้บริการทั้งหมดเป็นห้องสมุด HuggingFace Transformers ผ่าน Kobert-Transformers (Monologg), Distilkobert | Sktbrain (Apache-2.0) |
| คอร์เบิร์ต เบิร์ตเบส | -News (10 ปี), Wikipedia ฯลฯ 23GB -การวิเคราะห์ทางสัณฐานวิทยา api / wordpiece (ให้สองรุ่นแยกกัน) -30,349 คำศัพท์ ตัวอักษรละติน: cased - [บทนำ] Lim Jun (ETRI) NLU Tech Talk กับ Korbert | -pytorch, tensorflow | Etri (สัญญาส่วนบุคคล) |
| Kcbert เบิร์ตเบส/ใหญ่ | -daver News Comment (12.5GB, 8.9 ล้านประโยค) (19.01.01 ~ 20.06.15 ความคิดเห็นจากบทความในบทความและความคิดเห็น) -tokenizers bertwordpiecetokenizer -30,000 คำศัพท์ | Beomi (MIT) | |
| โคคาร์ต บาร์ต (124m) | -Wikipedia (5m) และอื่น ๆ (ข่าว, หนังสือ, คำพูดของทุกคน (การสนทนา, ข่าว, ... ), Cheong wa dae คำร้องแห่งชาติ ฯลฯ -tockenizers ตัวละคร bpe tokenizer คำศัพท์ 30,000 คำ (รวม) - [ตัวอย่าง] Seujung Kobart-Summarization (รหัสสาธิต) | -ความเชี่ยวชาญในงานสรุป -การสนับสนุนห้องสมุด Transformers Huggingface -pytorch | SKT T3K (แก้ไข MIT) |
| ปี | กระดาษ |
|---|---|
| 2018 | การสำรวจวิธีการสรุปเครือข่ายประสาท Y. Dong |
| 2020 | ตรวจสอบเทคนิคการสรุปข้อความอัตโนมัติและวิธีการ Widyassari, AP, Rustad, S. , Shidik, GF, Noersasongko, E. , Syukur, A. , & Affandy, A. |
| 2020 | การสำรวจการสร้างข้อความที่เพิ่มความรู้ Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, Meng Jiang |
| ปี | กระดาษ | คำสำคัญ |
|---|---|---|
| 2501 | การสร้างบทคัดย่อวรรณกรรมอัตโนมัติ Ph Luhn | EX |
| ปี 2000 | การสร้างพาดหัวขึ้นอยู่กับการแปลทางสถิติ M. Banko, Vo Mittal และ MJ Witbrock | Gen-Abs |
| พ.ศ. 2547 | Lexrank : ศูนย์คำศัพท์ที่ใช้กราฟเป็นความสำคัญในการสรุปข้อความ G. Erkan และ Dradev | EX |
| ปี 2548 | การสรุปเอกสารการสกัดด้วยประโยค J. Jagadeesh, P. Pingali และ V. Varma | EX |
| 2010 | การสร้างชื่อเรื่องด้วยไวยากรณ์กึ่งซิงโครนัส K. Woodsend, Y. Feng และ M. Lapata | EX |
| ปี 2554 | การสรุปข้อความโดยใช้การวิเคราะห์ความหมายแฝง MG Ozsoy, FN Alpaslan และ I. Cicekli | EX |
| ปี | กระดาษ | คำสำคัญ |
|---|---|---|
| 2014 | ในการใช้คำศัพท์เป้าหมายที่มีขนาดใหญ่มากสำหรับการแปลเครื่องประสาท S. Jean, K. Cho, R. Memisevic และ Yoshua Bengio | Gen-Abs |
| ปี 2558 แบบอย่าง | NAMAS : รูปแบบความสนใจทางประสาทสำหรับการสรุปนามธรรม (รหัส) Am Rush, S. Chopra และ J. Weston / Emnlp 2015 เพื่อที่จะไปไกลกว่าการเลือกประโยคและวิธีการรวมที่มีอยู่เราแนะนำความสนใจเป้าหมายไปยังแหล่งที่มาใน Flag SEQ2SEQ เพื่อสร้างบทสรุปเชิงนามธรรม | เอบีเอส SEQ2SEQ กับ ATT |
| ปี 2558 | Toward Abstractive Summarization Using Semantic Representations Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 แบบอย่าง | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 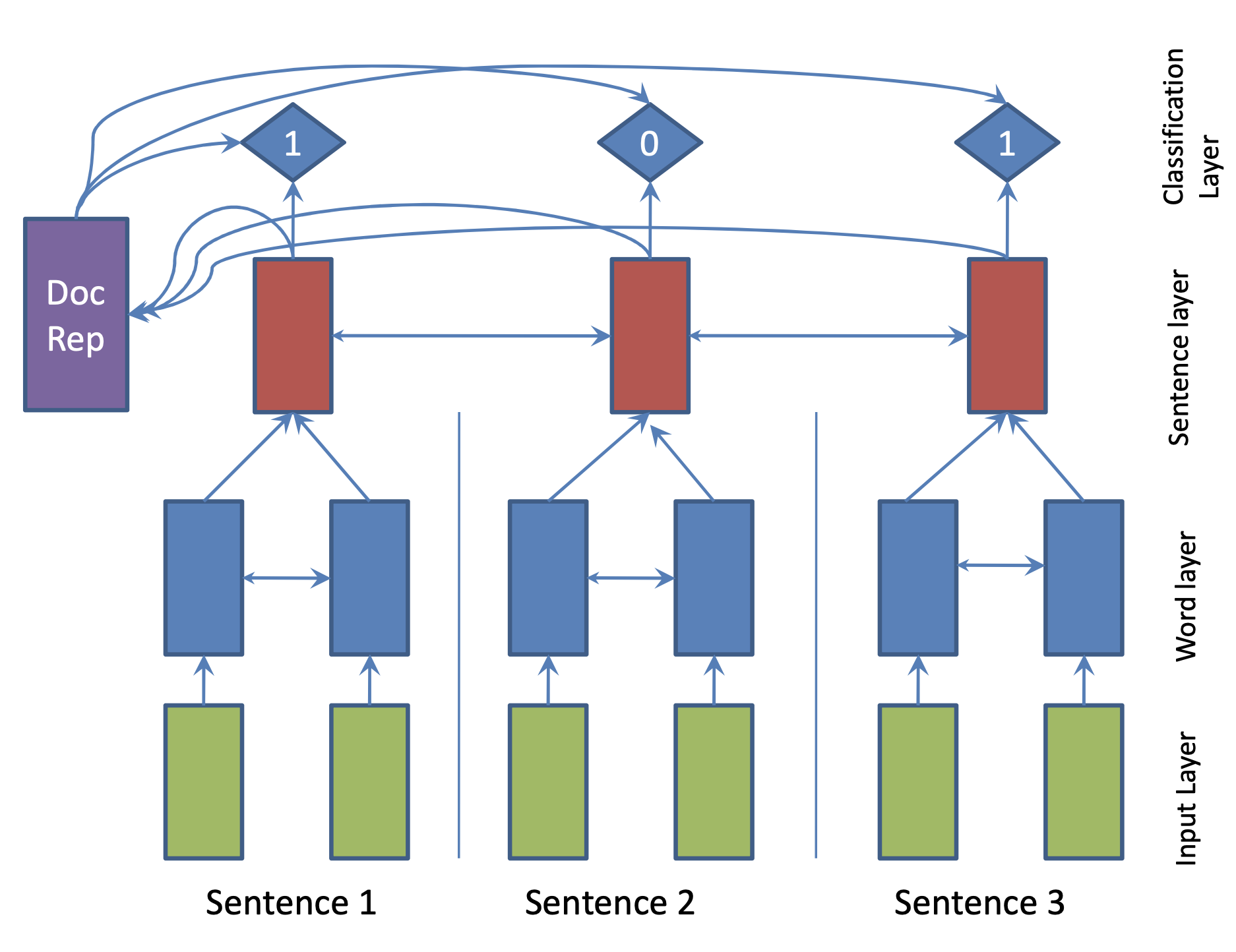 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 แบบอย่าง, เทคนิค | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 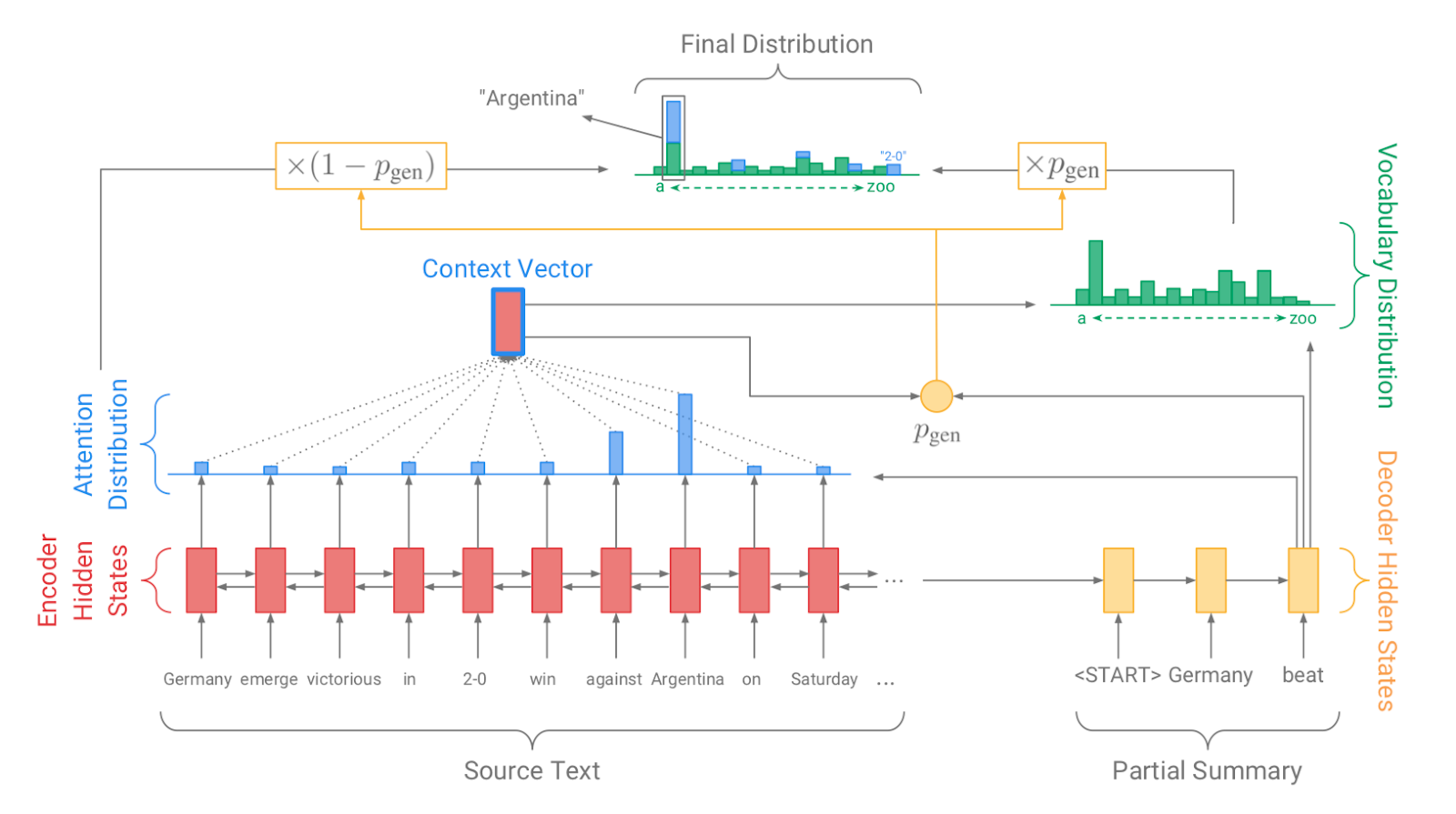 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 แบบอย่าง | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 แบบอย่าง | Bottom-Up Abstractive Summarization Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, hybrid, bottom-up attention |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 แบบอย่าง | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 แบบอย่าง | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 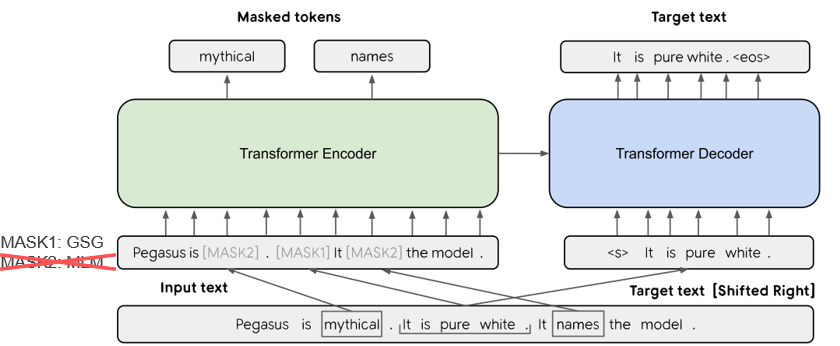 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 แบบอย่าง | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


