Text Summarization Repo
1.0.0
Parmi les NLP, c'est un espace qui accumule des données de qualité liées au champ Résumé du texte. Je voudrais être un bon guide pour ceux qui sont intéressés par le résumé du texte.
Tout d'abord, nous comprenons les sujets détaillés que le texte résume est composé et examine les principaux articles qui ont mené ce champ. Depuis lors, nous avons répertorié le code, les ensembles de données et les modèles de pré-crrane nécessaires pour créer un modèle de résumé de texte direct.
Intro au résumé de texte
PAPIERS
Ressources
Autres
Berry, Dumais et O'Brien (1995) définissent le résumé du texte comme suit:
Le résumé de texte est le processus de distillation des informations les plus importantes d'un texte pour produire une tâche et un utilisateur particuliers
Il s'agit d'un processus de raffinage uniquement d'informations importantes parmi le texte donné en un mot. Ici, l'expression du raffinage et l'importance de l'importance est une expression plutôt abstraite et subjective, donc je veux personnellement la définir comme suit.
f(text) = comprehensible information
En d'autres termes, le résumé du texte est de convertir le texte d'origine en une information facile et précieuse . Les humains sont difficiles à voir en un coup d'œil d'informations sur le texte, qui sont longues ou divisées en plusieurs documents. Parfois, vous ne connaissez pas beaucoup de termes professionnels. Il est très utile de refléter ces textes en une forme simple et facile à comprendre tout en reflétant bien le texte d'origine. Bien sûr, ce qui vaut vraiment la peine et comment le changer variera en fonction de l'objectif de résumer ou de goûts personnels.
De ce point de vue, on peut dire que le texte résume non seulement les tâches qui créent des textes tels que le procès-verbal, le titre de l'ingénieur de journaux, le résumé de papier et le curriculum vitae, ainsi que des tâches qui convertissent le texte en graphiques ou images. Bien sûr, comme ce n'est pas seulement un résumé, c'est un résumé de texte , donc la source du résumé est limitée sous forme de texte. (Le résumé du résumé est parce qu'il peut non seulement être du texte ou de la vidéo ainsi que du texte.
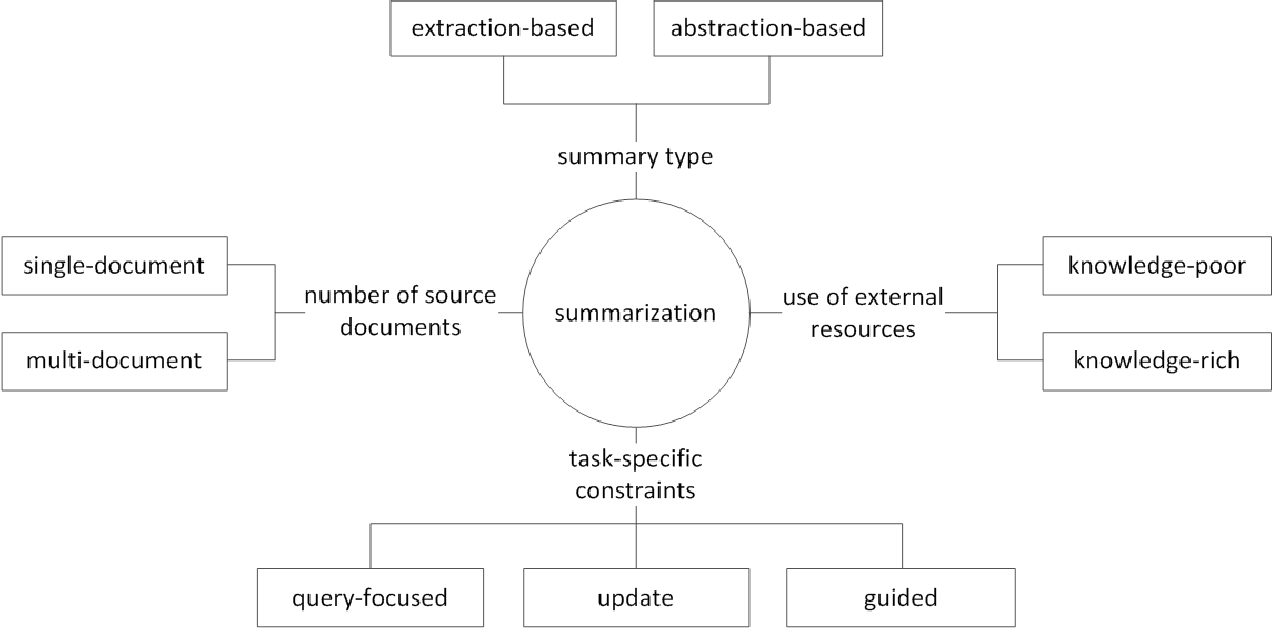
En général, la tâche de résumé du texte est divisée en résumé extractif (ci-après dénommé EXT) et résumé abstrait (ABS), selon la façon dont ils génèrent un résumé. (Gudivada, 2018)
Méthodes extractives Sélectionnez un sous-ensemble de mots, phrases ou phrases existants dans le texte d'origine pour former un résumé. En revanche, les méthodes abstraites créent d'abord une représentation sémantique interne et utilisent la technologie générationnelle du langage naturel.
EXT marque généralement l'importance de la phrase, puis la sélectionne et la combine pour créer un résumé. C'est similaire à la tâche de peindre un surligneur pendant la lecture. ABS , en revanche , est basé sur le texte d'origine, mais est une méthode NLG (génération de langage naturel) qui génère un nouveau texte . Il est peu probable que l'EXT inclut des expressions limitées aux expressions en raison du texte du texte d'origine. ABS, en revanche, a l'avantage qu'il existe une possibilité de créer une expression sans précédent car elle doit créer un nouveau texte dans le modèle, mais il a des approches plus flexibles.
En outre, selon le nombre de textes d'origine, selon la forme de texte de la résumé de documents uniques / multiples , le résumé des mots clés / phrases , selon la quantité d'informations externes utilisées dans le processus de résumé , selon le processus de résumé, il existe diverses distinctions telles que le résumé.
(G. Sizov (2010). Résumé automatique basé sur l'extraction: étude théorique et empirique des techniques de résumé
Jetons un coup d'œil aux principaux sujets de recherche dans le domaine de la résumé de texte et réfléchissons au type de défi dans ce domaine.
Résumé des documents multi-/ longs
Comme mentionné précédemment, la tâche sommaire consiste à modifier le texte incompréhensible en informations compréhensibles. Par conséquent, plus le texte d'origine est long, ou le résumé des documents de plusieurs sources, pas un seul document, plus l'utilité du résumé augmente. Le problème est qu'en même temps, la difficulté du résumé augmente également.
Pour cette raison, plus le texte d'origine est long, plus la complexité de calcul augmente rapidement. Il s'agit d'un problème beaucoup plus critique dans les méthodes récentes basées sur le réseau neuronal, y compris le transformateur que dans les méthodes statistiques telles que Textrank dans le passé. Deuxièmement, plus le texte d'origine est long, plus le noyau du contenu est long, c'est-à-dire le bruit. Il n'est pas facile d'identifier ce qui est le bruit et ce qui est informatif. Enfin, les longs textes et diverses sources ont diverses perspectives et contenu en même temps, ce qui rend difficile la création d'un résumé qui le couvre bien.
Résumé des documents multi-documents (MDS)
MDS est un résumé d'une pluralité de documents . À première vue, il sera difficile de résumer les articles de perspectives différentes de divers auteurs que de résumer un document qui décrit un thème d'une tendance et d'un point de vue cohérents. Bien sûr, même dans le cas de MDS, il est généralement basé sur le même document de cluster qui traite de sujets similaires, mais il n'est pas facile d'identifier les informations importantes et de filtrer les informations sur les nombreux documents.
La tâche, qui résume les avis sur certains produits, est un exemple de MDS qui est le plus facile à penser. Cette tâche, généralement appelée résumé d'opinion, est caractérisée par une courte longueur de texte et une subjectivité. Le travail de création d'un document wiki peut également être considéré comme un MDS. Liu et al. (2018) est le texte original du texte du site Web sur le document Wiki, qui est le texte original, qui est considéré comme un résumé, et il crée un modèle de création de wiki.
Résumé des documents longs
Liu et al. (2018) est un moyen statistique d'accepter le texte long comme entrée, créant un résumé d'extracement, en utilisant uniquement des phrases importantes et en l'utilisant comme entrée du modèle. De plus, afin de réduire le volume de calcul du transformateur, l'entrée est divisée en unités de bloc, et à l'heure actuelle, la convolution 1-D utilise la méthode de tension qui réduit le nombre de clés et de valeur d'attention individuelles. L'article Big Bird (2020) introduit un mécanisme d'attension clairsemé (linéaire) au lieu d'une combinaison de tous les mots existants pour réduire le calcul du transformateur. En conséquence, le même matériel de performance a été résumé jusqu'à huit fois de plus.
Gidiotis & Tsoumakas (2020), en revanche, tente d'approcher le diviser et le conquéraire, qui ne résout pas le long problème de résumé de texte à la fois et le transforme en plusieurs petits résumés de texte. Formation du modèle en modifiant le texte d'origine et le résumé cible vers les multiples petites paires de cibles source-cible. Dans l'inférence, nous agrégeons la sortie des résumés partiels via ce modèle pour créer un résumé complet.
Amélioration des performances
Comment pouvez-vous créer un meilleur résumé?
Transfert d'apprentissage
Récemment, l'utilisation du modèle de pré-formation dans la PNL est devenue presque par défaut. Alors, quel type de structure devrions-nous avoir pour créer un modèle de pré-alimentation qui peut montrer de meilleures performances dans le résumé de texte? Quel objet dois-je avoir?
Dans Pegasus (2020), la méthode GSG (GAP Sentendies Generation), qui sélectionne une phrase considérée comme importante sur la base du score Rouge, suppose que plus le processus de résumé de texte est similaire et l'objection montrera les performances plus élevées. Le modèle SOTA actuel, BART (2020) (transformateurs bidirectionnels et auto-régression), apprend sous la forme d'un autoencodeur qui ajoute du bruit à une partie du texte d'entrée et le restaure en tant que texte d'origine.
Génération de texte améliorée à connaissance
Dans la tâche texte à texte, il est souvent difficile de générer la sortie souhaitée avec le texte d'origine seul. Il y a donc une tentative d'améliorer les performances en fournissant une variété de KnowEdge au modèle ainsi qu'au texte d'origine . La source ou la fourniture de ces connaissances varie dans divers types de mots clés, de sujets, de fonctionnalités linguistiques, de bases de connaissances, de graphiques de connaissances et de texte mis à la terre.
Par exemple, Tan, Qin, Xing et Hu (2020) fournissent un ensemble de données de sommation général pour convertir une pluralité de résumé basé sur l'aspect et fournit des informations plus riches liées à un aspect donné à un aspect donné au modèle. Utilisez Wikipedia pour. Si vous voulez en savoir plus, Yu et al. Lisez le document d'enquête rédigé par (2020).
Corection post-édition
Ce serait bien de créer un bon résumé à la fois, mais ce n'est pas facile. Alors pourquoi ne créez-vous pas un résumé, puis ne le révisez et le modifiez-vous dans une variété de critères?
Par exemple, Cao, Dong, Wu et Cheung (2020) suggèrent une méthode de réduction des erreurs factuelles en appliquant un modèle de correcteur neuronal préposé au résumé généré.
De plus, il existe également de nombreuses tentatives pour appliquer ** Graph Neural Network (GNN) **, qui a reçu beaucoup d'attention récemment.
Problème de rareté de données
Le résumé du texte est une tâche qui prend beaucoup de temps, ce qui n'est pas facile pour les humains. Par conséquent, par rapport à d'autres tâches, cela coûte des coûts relativement plus élevés pour créer un ensemble de données étiqueté, et bien sûr, il existe un manque de données pour la formation.
En plus de la méthode d'apprentissage du transfert utilisant le modèle de pré-formation mentionné précédemment, nous apprenons dans des méthodes d'apprentissage ou d'apprentissage de renforcement non supervisées ou de tentative d'approche d'apprentissage à quelques coups .
Naturellement, faire de bonnes données de résumé est également un sujet de recherche très important. En particulier, bon nombre des ensembles de données liés à la résumé actuels sont biaisés dans les types d'actualités en anglais. En conséquence, des ensembles de données multilingues tels que Wikilingua et MLSUM sont en cours de création. Pour plus d'informations, jetez un œil à MLSUM: le Corpus de résumé multilingue.
Méthode métrique / évaluation
J'ai écrit une expression écrasante de «bon» plus tôt. Qu'est-ce qu'un «bon résumé»? Brazinskas, Lapata et Titov (2020) utilisent les cinq choses suivantes en fonction du jugement d'un bon résumé.
Le problème est qu'il n'est pas facile de mesurer ces pièces. L'indicateur de mesure de performance le plus courant dans les résumés de texte est le score Rouge. Il existe diverses variantes dans le score Rouge, mais en gros «comment est le mot du mot du résumé généré et du résumé de référence? Cela signifie similaire, mais si vous avez une forme différente ou si l'ordre des mots change, vous pouvez obtenir un score inférieur même s'il s'agit d'un meilleur résumé. En particulier, en essayant d'augmenter le score Rouge, cela peut entraîner de nuire à la diversité expressive du résumé. C'est pourquoi de nombreux articles fournissent des résultats d'évaluation humaine supplémentaires avec de l'argent coûteux ainsi qu'un score Rouge.
Lee et al. (2020) présente un RDASS (score sémantique de conscience de référence et de document), ce qui est similaire au résumé du texte et de la référence, puis mesuré par les routes similaires basées sur le vecteur. Cette méthode devrait augmenter la précision de l'évaluation du langage coréen, qui combine les mots et diverses morphologies pour exprimer diverses significations et fonctions grammaticales. Kryściński, McCann, Xiong et Socher (2020) ont proposé une approche basée sur des modèles faiblement supervisée pour évaluer la cohérence factuelle.
Génération de texte contrôlable
Y a-t-il un seul meilleur résumé sur un document donné? Ce n'est pas le cas. Les personnes avec des inclinations différentes peuvent préférer différents textes sommaires pour le même texte. Même si vous êtes la même personne, le résumé que vous voulez dépendra du but de résumer ou de la situation. Cette méthode d'ajustement de la sortie à la forme souhaitée en fonction des conditions spécifiées par l'utilisateur est appelée génération de texte contrôlable . Vous pouvez fournir un résumé personnalisé par rapport à un résumé générique qui crée le même résumé pour un document donné.
Le résumé généré doit non seulement être facile à comprendre et à évaluer, mais également être étroitement lié à la condition que vous assemblez.
f(text, condition ) = comprehensible information that meets the given conditions
Quelle condition puis-je ajouter au modèle de résumé? Et comment pouvez-vous créer un résumé qui convient à cette condition?
Résumé basé sur l'aspect
Lorsque vous résumez les critiques des utilisateurs d'AirPod, vous voudrez peut-être résumer chaque côté en divisant la qualité sonore, la batterie et la conception. Ou vous pouvez peut-être ajuster le style d'écriture ou le sentiment dans l'article. Dans ce texte original , le travail qui résume uniquement les informations liées à des aspects ou des fonctionnalités spécifiques est appelé résumé basé sur l'aspect .
Auparavant, seuls les modèles qui ne fonctionnaient qu'en aspect prédéfini, qui étaient principalement utilisés pour l'apprentissage des modèles, ont maintenant tenté de permettre le raisonnement de l'aspect arbitraire, qui n'a pas été donné à l'apprentissage tel que Tan, Qin, Xing et Hu (2020).
Résumé focalisé de la requête (QFS)
Si la condition est requête , elle s'appelle QFS. La requête est principalement un langage naturel, donc la tâche principale est de savoir comment bien faire ces différentes expressions et les associer au texte d'origine. Il est assez similaire au système QA que nous connaissons bien.
Mettre à jour le résumé
Les humains sont des animaux qui continuent d'apprendre et de grandir. Par conséquent, la valeur d'aujourd'hui pour certaines informations peut être complètement différente de la valeur d'une semaine plus tard. La valeur du contenu dans le document que j'ai déjà connu sera abaissée, et le nouveau contenu qui n'a pas encore été expérimenté aura encore une valeur élevée. De ce point de vue, il est appelé Résumé de la mise à jour pour créer un nouveau résumé d'un nouveau contenu similaire au contenu du document que l'utilisateur a connu précédemment .
Ctrlsum prend divers mots clés ou invites descriptives avec le texte pour ajuster le résumé généré. Il s'agit d'un modèle de résumé de texte contrôlable plus général en ce qu'il montre les mêmes résultats que d'être contrôlé pour les mots clés ou les invites qui ne sont pas explicitement apprises au stade de la formation. Vous pouvez facilement l'utiliser via la bibliothèque des résumés de Koh Hyun -Woong.
En plus de cela, une variété de tentatives pour créer un modèle de résumé qui convient au résumé de conversation plutôt qu'à un sujet DL typique tel que ** modèle léger, ainsi qu'un résumé du dialogue plutôt qu'un texte structuré tel que les nouvelles ou Wikipedia. Il y a des sujets.
Si vous connaissez ce qui suit dans le domaine du résumé du texte, vous pourrez étudier plus facilement.
Comprendre le concept de base de la PNL
Structure transformateur / bert et compréhension objective pré-formation
Bon nombre des derniers articles PNL sont basés sur plusieurs modèles de pré-alimentation, dont Bert, basé sur Transformer, et Roberta et T5, qui sont des variantes de ce Bert. Par conséquent, si vous comprenez leur structure schématique et leur objectif de pré-formation, c'est une grande aide pour lire ou mettre en œuvre un article.
Résumé de texte Concept de base
Graphique Network Network (GNN)
Traduction machine (MT)
MT est l'une des tâches les plus actives du champ NLP depuis l'émergence de SEQ2SEQ. Si vous considérez le processus de résumé comme un processus de conversion d'un texte en un type de texte différent, il peut être considéré comme une sorte de MT, une grande partie d'études et d'idées liées à la MT sont susceptibles d'être empruntées ou appliquées dans le domaine de la résumé.
| Année | Papier | Mots clés |
|---|---|---|
| 2004 Modèle | Textrank : introduire l'ordre dans les textes R. Mihalcea, P. Tarau C'est un classique dans le secteur de l'extraction et est toujours actif. En supposant que la phrase importante dans le document (c'est-à-dire incluse dans le résumé) est un algorithme PageRank, l'idée initiale du moteur de recherche Google, en supposant qu'il aura une simulation élevée avec d'autres phrases. Chaque phrase configure le graphique pondéré au niveau de la phrase pour calculer la similitude avec une autre phrase dans le document et comprend cette phrase de poids élevé dans le résumé. Les méthodes d'apprentissage non supervisées basées sur les statistiques peuvent être raisonnables sans des données d'apprentissage distinctes, et l'algorithme est clair et facile à comprendre. - [Library] Gensim.summarisation (seule la version 3.x est disponible. Supprimer de la version 4.x), Pytextrank - [Théorie / Code] Awit. Extraction de mots clés à l'aide de TextTrank et d'extrait de phrase de base | Ext, Basé sur un graphique (PageRank), Sans surveillance |
| 2019 Modèle | BERTSUM : Résumé du texte avec des encodeurs à préted Yang Liu, Mirella Lapata / EMNLP 2019 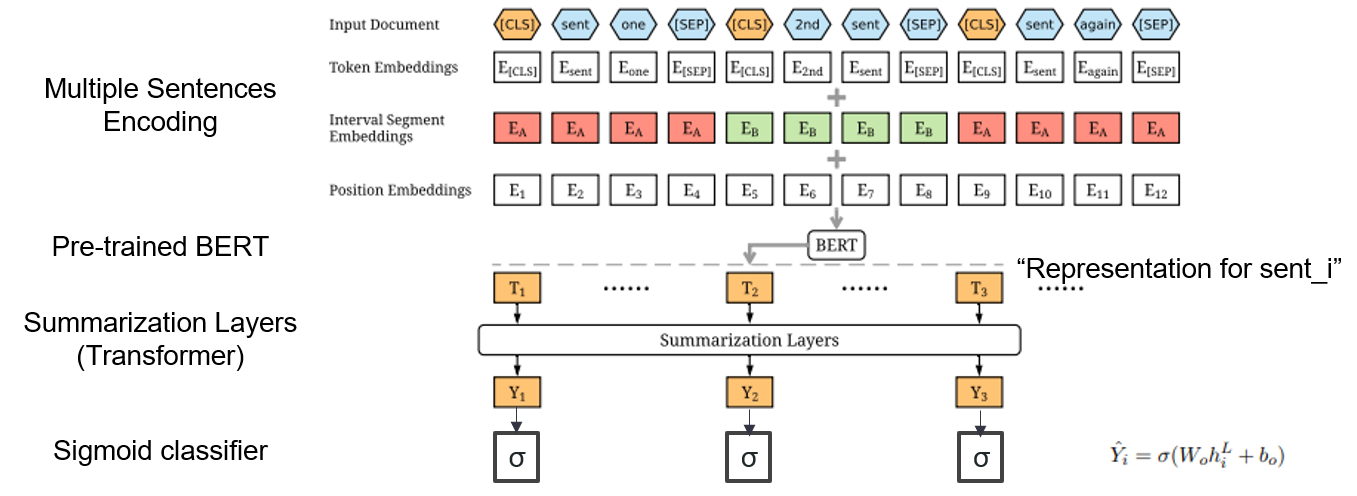 Comment puis-je utiliser Bert pré-formé en résumé? Comment puis-je utiliser Bert pré-formé en résumé?Berttsum suggère des incorporations d'entrée modifiées qui insèrent [CLS] les jetons devant chaque phrase et ajoute des incorporations d'intervalle pour ajouter plusieurs phrases dans une entrée. Le modèle EXT utilise une structure d'encodeur avec une couche de transformateur sur le Bert, et le modèle ABS utilise un modèle de coder-décodeur avec un décodeur de transformateur à 6 couches sur le modèle EXT. - [Revue] Lee Jung -Hoon (KoreAniniv DSBA) - [coréen] Kobertsum | Ext / abs, Bert + Transformer, Ajustement fin à 2 étapes |
| 2019 Modèle de pré-formation | BART : Pré-formation de séquence à séquence à la séquence pour la génération, la traduction et la compréhension du langage naturel Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer / ACL 2020 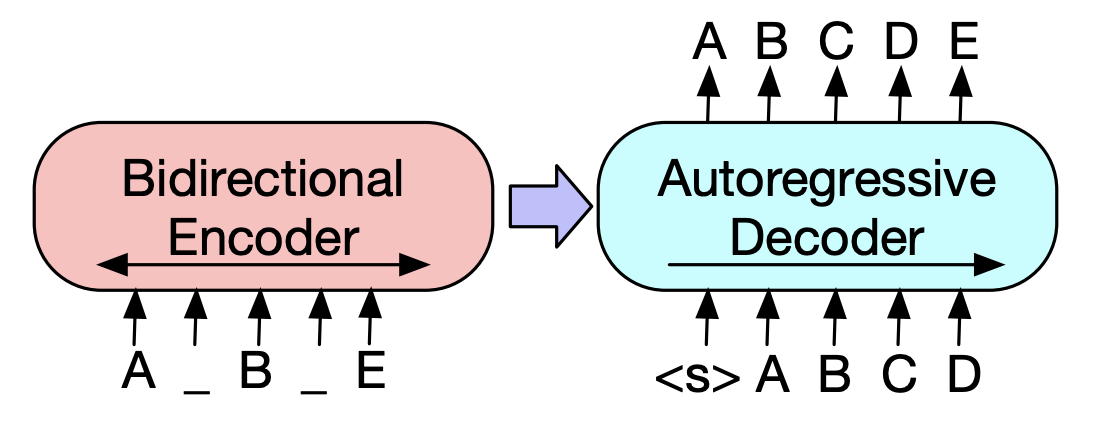 Bert est un encodeur bidirectrique, des tâches faibles à la génération, et GPT a un inconvénient qu'il n'obtient pas d'informations bidirées avec un modèle d'auto-régression. Bert est un encodeur bidirectrique, des tâches faibles à la génération, et GPT a un inconvénient qu'il n'obtient pas d'informations bidirées avec un modèle d'auto-régression.Le BART a une forme SEQ2SEQ qui les combine, vous pouvez donc expérimenter diverses techniques de dénomage dans un modèle. En conséquence, le remplissage de texte (modifie la durée de texte en un jeton de masque) et le mélange de phrase (mélange au hasard la phrase) montre les performances qui dépasse le modèle Ki Sota dans le domaine de la résumé. - [coréen] SKT T3K. Kobart - [Review] Jin Myung -Hoon_video, Lim Yeon -Soo_ Écrit par Jiwung Hyun_ | Abs, Seq2seq, Denoiser Autoencoder, Remplissage de texte |
| 2020 Modèle | Matchsum : Résumé d'extraction comme correspondance de texte (bureau) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang / ACL 2020 - [Revue] Yoo Kyung (Koreauniv DSBA) | Ext |
| 2020 Technique | Résumer le texte sur tous les aspects: une approche faiblement supervisée informée des connaissances (code officiel) Bowen Tan, Lianhui Qin, Eric P. Xing, Zhiting Hu / Emnlp 2020 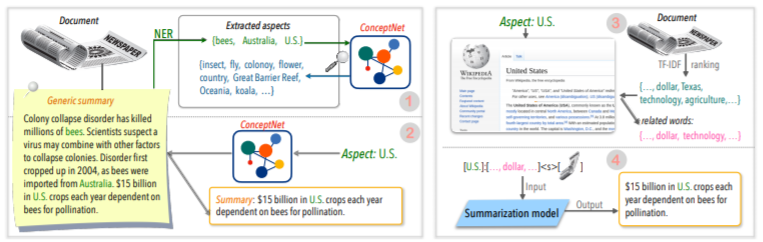 La résumé basé sur les aspects est une tâche qui n'est pas facile en ce qu'elle ne fonctionne que dans les aspects prédéfinis des données, qui est apprise même si vous apprenez le modèle, et 2) le manque de données de résumés basées sur des aspects. Cet article utilise des sources de connaissances externes pour résoudre ce problème. -Il passe par deux étapes pour convertir le résumé générique en résumés basés sur des aspects. Tout d'abord, pour augmenter le nombre d'aspects, l'entité extraite du résumé générique est la graine et extraite du conceptnet à ses voisins et considère chacun d'eux comme un aspect. Nous utilisons à nouveau Concepnet pour créer un résumé PSEDO pour chacun de ces aspects. Extraire l'entité environnante connectée à l'aspect correspondant dans Concepnet et extraire uniquement les phrases les contenant dans le résumé général. Ceci est considéré comme un résumé pour cette entité (aspect). -Wikipedia est utilisé pour fournir des informations plus abondantes liées à l'aspect donné au modèle. Plus précisément, parmi les mots qui apparaissent dans le document, le score TF-IDF dans le document est élevé et en même temps, et en même temps, la liste de 10 mots de la page Wikipedia correspond à cet aspect est ajoutée à l'aspect avec l'entrée du modèle. De cette façon, le modèle de pré-réalimentation préalable (BART) était également excellent pour l'aspect arbitraire avec une petite données. | Basé sur l'aspect, Savouré |
| 2020 Revoir | Qu'avons-nous bientôt un résumé de texte? Dandan Huang, Leyang Cui, Sen Yang, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang / EMNP 2020 En plus du score Rouge, 10 modèles de résumé représentatifs sont évalués selon 8 mesures (polytope) liées à la précision et à la maîtrise. Pour résumer les résultats, -La méthode traditionnelle basée sur des règles est toujours valable comme référence. Dans des contextes similaires, le modèle EXT montre généralement de meilleures performances dans la fidélité et la conscience factuelle. La principale lacune est inattendue pour les modèles extractifs, et l'omission et l'hallucination intrinsèque pour les modèles abstractifs. -Les structures les plus complexes telles que les transformateurs pour la création de la représentation des phrases ne sont pas très utiles, sauf le problème de la duplication. -Copy ( Generator Pointer ) est un détail de reproduction, qui résout efficacement le problème de duplication de niveau de mot en le mélangeant ainsi que l'inexactitude intrinsèque. Mais a tendance à provoquer la redondance dans une certaine mesure. La couverture est par une grande marge, ce qui réduit les erreurs de répétition (duplication), mais en même temps augmente l'erreur intrinsèque d'addition et d'inexactitude -Le modèle hybride , qui est ABS après Ext, est bon pour les rappels, mais il peut y avoir des problèmes d'erreur d'inexactitude car il génère un résumé à travers une partie du texte d'origine (extraits extraits). La pré-formation, en particulier le modèle d'encodeur-décodeur (BART) que le modèle de codeur uniquement (BERTSUMEXTABS) est très efficace dans le résumé. Cela suggère que la prévision de toute compréhension et création de contribution est très utile pour la sélection et la combinaison du contenu. Dans le même temps, alors que la plupart des modèles ABS se concentrent sur la phrase avant, BART examine tout le texte d'origine, ce qui semble être l'effet du mélange de la phrase pendant la présélection. 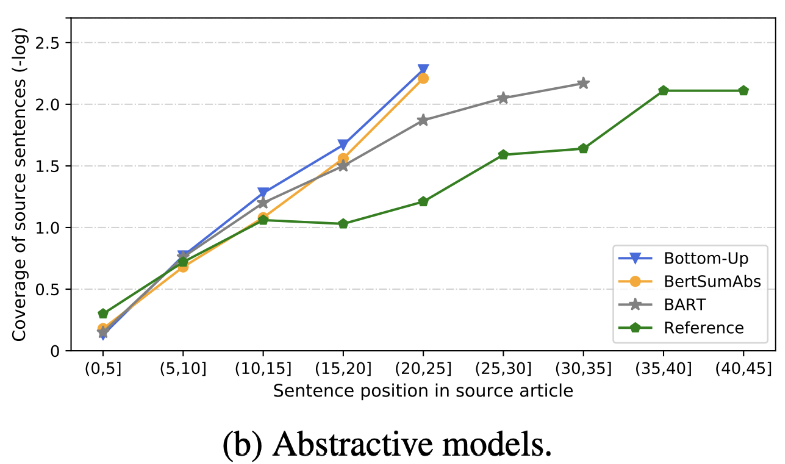 - [Revue] Kim Han -Gil, Heo Hoon | Revoir |
| 2020 Modèle | CTRLSUM : Vers une résumé de texte générique contrôlable (code officiel) Junxian He, Wojciech Kryściński, Bryan McCann, Nazneen Rajani, Caiming Xiong CTRLSUM est un modèle de résumé de texte contrôlable qui vous permet d'ajuster les instructions de résumé générées via des mots clés ou des invites descriptives. Formation: Afin de créer un ensemble de données de résumé contrôlable basé sur des mots clés en modifiant les données de résumé général, sélectionnez des sous-séquences, qui est la plus similaire au résumé et y extraire le mot-clé. Mettez-le dans une entrée avec le document et terminez le BART pré-réglage. 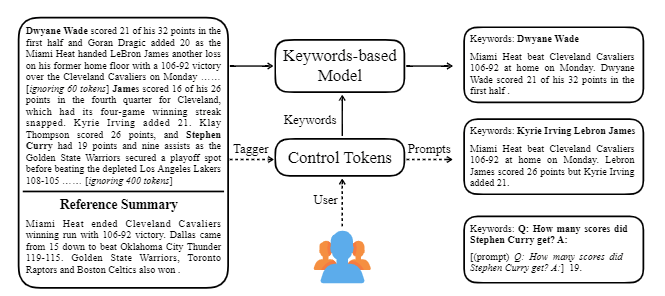 -InPesture: Comme indiqué dans l'image ci-dessous, vous pouvez ajouter un résumé du résumé, comme la création d'un résumé d'une entité particulière, l'ajustement de la durée de résumé ou la création d'une réponse à une question. Il est à noter que cela fonctionne comme s'il n'apprendait pas explicitement de telles invites au stade de la modélisation, mais cela a fonctionné comme s'il devait comprendre une invite et générer un résumé. Similaire à GPT-3. 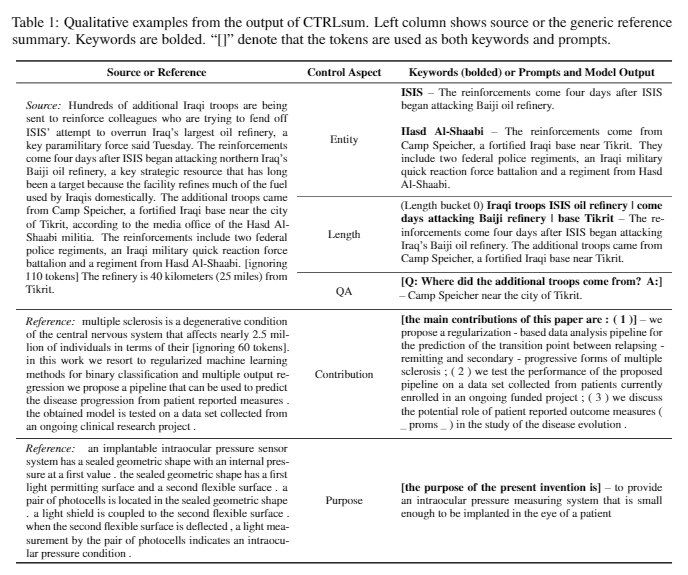 - Package [bibliothèque] pour Ctrlsum basé sur un résumé contrôlable | Contrôlable, Barbe |
Paper Digest: Documents récents sur le résumé de texte
Documents avec code: derniers articles
EMNLP 2020 Papiers-Summarisation
En fait, nous avons résumé les modèles de code, de données et de préitrain nécessaires pour créer et pratiquer des modèles de résumé. Il s'agit principalement de données coréennes, et pour les documents liés à l'anglais, veuillez vous référer à la partie code de chaque article dans l'article des papiers.
La signification des faibles utilisés ci-dessous est la suivante.
w : valeur moyenne du nombre de mots; s : valeur moyenne du nombre moyen de phrases
Exemple) 13s/214w → 1s/26w signifie qu'il fournit un texte sommaire composé d'une moyenne de 13 phrases (en moyenne 214 mots) et d'une moyenne d'une phrase (26 mots en moyenne).
Résumé de abs ; ext : Résumé extractif
| Ensemble de données | Domaine / longueur | Volume (Paire) | Licence |
|---|---|---|---|
| Résumé des mots-documents de chacun Titre du texte des nouvelles, 3 phrases ABS et extrémit Tous les mots de tous ceux qui ont été combinés par ID avec les chevaux du journal, vous pouvez obtenir des informations supplémentaires liées aux sous-titres, aux médias, à la date et au sujet. | nouvelles -Origine → 3S (ABS); 3s (ext) | 13 167 | Institut national de la langue coréenne (Contrat individuel) |
| Texte de résumé du document AIHUB ABS et EXT résumer pour les articles de journaux, les contributions, les articles de magazines et les critiques - [EDA] Data Eda Notebook -Rés résumé de l'extraction des documents coréens sur la collecte et le concours de la création (~ 20.12.09) | -L'article du journal 300 000, 60 000 contributions, 10 000 articles de magazines, décision de justice 30 000 13S / 214W → 1S / 26W (ABS); 3S / 55W (ext) | 400 000 | Aihub (Contrat individuel) |
| Aihub-Summary Résumé de l'ABS par tous et section pour les documents académiques et les spécifications de brevet | -Un papiers académiques, spécifications de brevet -Origin → Abs | 350 000 | Aihub (Contrat individuel) |
| Résumé des données AIHUB-Book Résumé de l'ABS pour le livre coréen original sur divers sujets | -LIFETime, vie, taxe, environnement, développement communautaire, commerce, économie, travail, etc. -300-1000 caractères → ABS | 200 000 | Aihub (Contrat individuel) |
| SAE4K | 50 000 | Cc-by-sa-4.0 | |
| Sci-news-Sum-kr-50 | Nouvelles (IT / Science) | 50 | Mit |
| Wikilingua : un ensemble de données de résumé abstractif multilingue (2020) Basé sur le site manuel Wikihow, 18 langues telles que coréen et anglais - Papier, Collab Unbook | -Comment des documents -391W → 39W | 12 189 (Kor au total 770 087) | 2020, CC BY-NC-SA 3.0 |
| Ensemble de données | Domaine / longueur | Volume | Licence |
|---|---|---|---|
| Scisummnet (papier) Fournit trois types de résumé pour la recherche sur la LCA (NLP) -CL-SCISUMM 2019-TASK2 (repo, papier) -Cl-scisumm @ emnlp 2020-task2 (repo) | -Dectif de recherche (Linguistes informatiques, NLP) 4 417W → 110W (résumé de papier); 2s (citation); 151W (ABS) | 1 000 (ABS / EXT) | CC BY-SA 4.0 |
| Longsumm Résumé relativement long (Articles de blog connexes - Abs basés sur les conférences connexes pour conférences vidéo) -Longsumm 2020 @ emnlp 2020 -Longsumm 2021 @ naacl 2021 | -Recar de recherche (NLP, ML) -Origin → 100S / 1 500W (ABS); 30s / 990w (ext) | 700 (ABS) + 1 705 (ext) | Attribution-noncommercial-sharealike 4.0 |
| CL-LAYSUMM Fournir une couche facile pour les non-professionnels pour les champs NLP et ML. -Cl-Laysumm @ EMNLP 2020 | -Reclé de recherche (épilepsie, archéologie, ingénierie des matériaux) -Origin → 70 ~ 100W | 600 (ABS) | Besoins de l'accord individuel (envoyé par e-mail à [email protected]) |
| Global Voice : Crossing Borders in Automatic News Résumé (2019) -Papier | - nouvelles -359W → 51W | ||
| MLSUM : le corpus de résumé multilingue Semblable à l'ensemble de données CNN / Daily Mail, les points forts / description des articles de presse sont considérés comme un résumé et un résumé pour l'anglais, le français, l'Allemagne, l'espagnol, le russe, le jeu de données de construction turque -Paper, utilisation (HuggingFace) | - nouvelles -790W → 56W (Base) | 1,5 m (ABS) | Des fins de recherche non commerciales uniquement |
| Modèle | Pré-formation | Usage | Licence |
|---|---|---|---|
| Bert (multilingue) Bert-base (paramètres 110m) | -Wikipedia (multilingue) -WORDPIECE. -110K Vocabs partagés | BERT-Base, Multilingual Cased( --do_lower_case=false option)-Tensorflow | Google (Apache 2.0) |
| Kobert Bert-base (paramètres 92m) | -Wikipedia (5m phrase), News (20m phrase) -Enthétence 8 002 Vocabs (pas de jeton inutilisé) | -Pytorch -Tout disponible en tant que bibliothèque de transformateurs HuggingFace via Kobert-Transformateurs (Monologg), Distilkobert disponible | Sktbrain (Apache-2.0) |
| Korbert Bascule | -News (10 ans), Wikipedia, etc. 23 Go -ETRI Analyse morphologique API / Poix d'éloge (a fourni deux versions séparément) -30,349 vocabs Alphabets latins: Basé - [Introduction] Lim Jun (ETRI). NLU Tech parle avec Korbert | -Pytorch, Tensorflow | ETRI (Contrat individuel) |
| Kcbert Bert-base / grand | -Daver News Commentaire (12,5 Go, 8,9 millions de phrases) (19.01.01 ~ 20.06.15 Commentaires à partir d'articles dans des articles et des commentaires) -Dekinisers BertwordPieceTokenizer -30 000 vocabs | Beomi (MIT) | |
| Kobart BART (124m) | -Wikipedia (5m) et autres (nouvelles, livre, paroles de chacun (conversation, nouvelles, ...), Cheong wa dae pétition nationale, etc. -Mor-Tokenizer BPE du personnage de Tockenizers 30 000 vocabs (inclus) - [Exemple] Seujung. Kobart-Summarisation (code, démo) | - Spécialisation des tâches dénoncées -Prise en charge de la bibliothèque des transformateurs sur le plan -Pytorch | SKT T3K (MIT modifié) |
| Année | Papier |
|---|---|
| 2018 | Une enquête sur les méthodes de résumé basées sur le réseau neuronal Y. Dong |
| 2020 | Revue de la technique et méthodes de résumé de texte automatique Widyassari, AP, Rustad, S., Shidik, GF, Noersasongko, E., Syukur, A., et Affandy, A. |
| 2020 | Une enquête sur la génération de texte améliorée aux connaissances Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, Meng Jiang |
| Année | Papier | Mots clés |
|---|---|---|
| 1958 | Création automatique des résumés de la littérature Ph Luhn | Génération |
| 2000 | Génération des gros titres basée sur la traduction statistique M. Banko, Vo Mittal et MJ Witbrock | Gén-abs |
| 2004 | Lexrank : centralité lexicale basée sur des graphiques comme saillance dans le résumé de texte G. Erkan et Dradev, | Génération |
| 2005 | Résumé de document unique basé sur l'extraction de phrases J. Jagadeesh, P. Pingali et V. Varma | Génération |
| 2010 | Génération de titre avec grammaire quasi-synchrone K. Woodsend, Y. Feng et M. Lapata, | Génération |
| 2011 | Résumé de texte à l'aide d'une analyse sémantique latente Mg Ozoy, Fn Alpaslan et I. Cicekli | Génération |
| Année | Papier | Mots clés |
|---|---|---|
| 2014 | Sur l'utilisation d'un très grand vocabulaire cible pour la traduction de la machine neuronale S. Jean, K. Cho, R. Memisevic et Yoshua Bengio | Gén-abs |
| 2015 Modèle | NAMAS : un modèle d'attention neuronale pour la résumé abstractif (code) Am Rush, S. Chopra et J. Weston / EMNLP 2015 Afin d'aller au-delà de la méthode de sélection et de combinaison de phrase existante, nous introduisons l'attention cible à source dans le drapeau Seq2Seq pour créer un résumé abstrait. | abs Seq2seq avec ATT |
| 2015 | Vers un résumé abstrait à l'aide de représentations sémantiques Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 Modèle | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 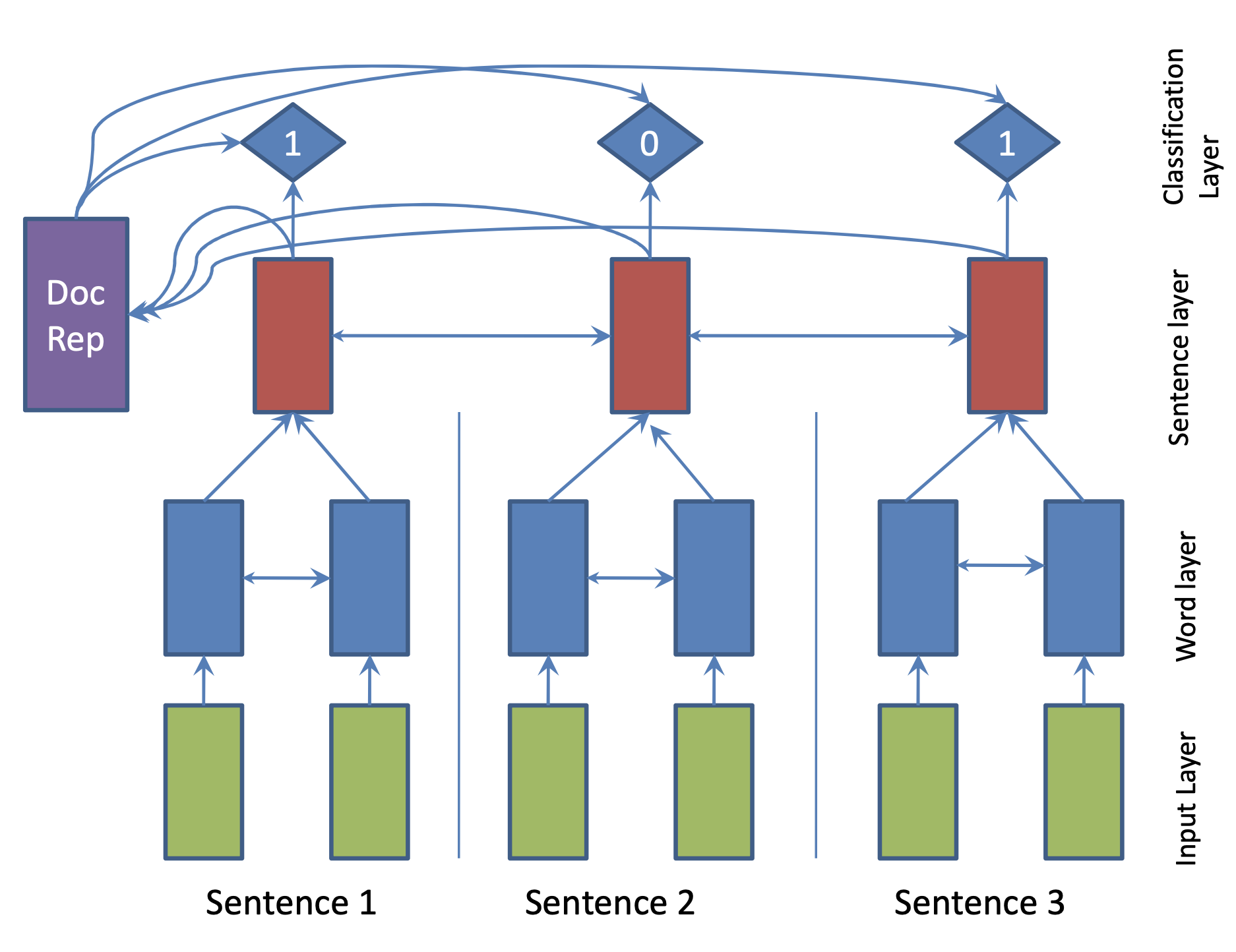 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 Modèle, Technique | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 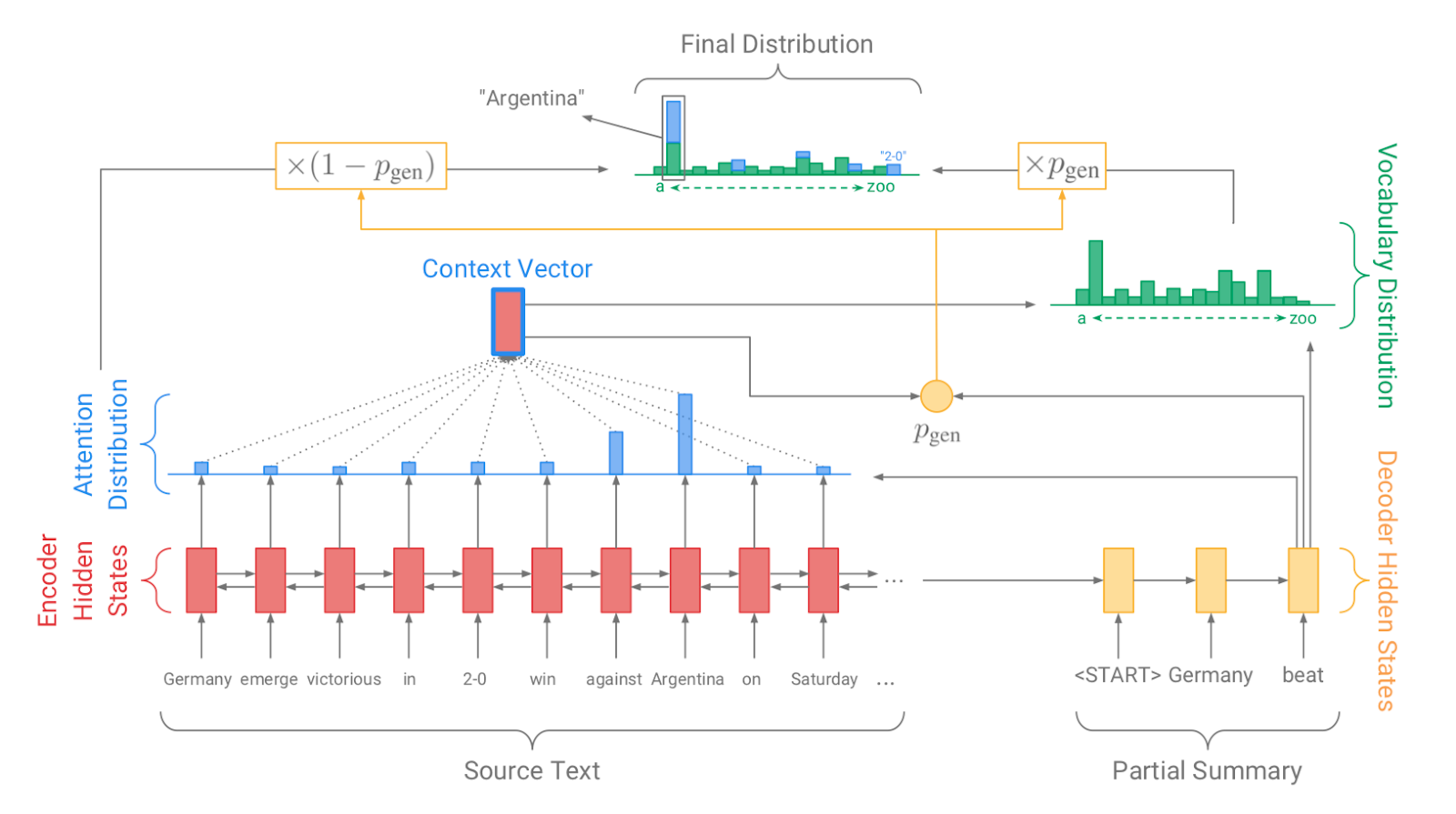 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 Modèle | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 Modèle | De bas en haut Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, Hybride, De bas en haut |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 Modèle | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 Modèle | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 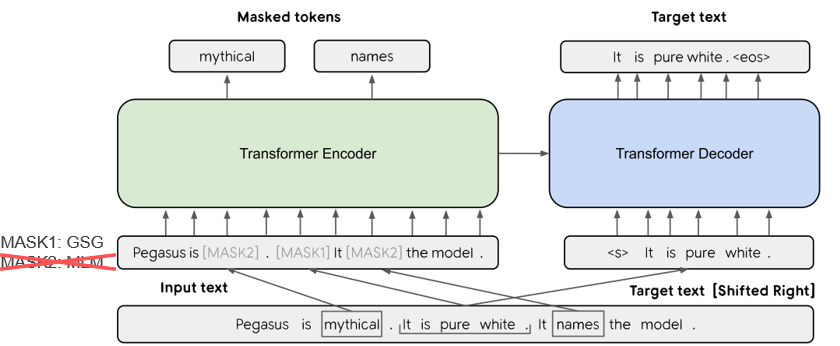 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 Modèle | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


