Text Summarization Repo
1.0.0
NLPの中で、テキストの要約フィールドに関連する品質データを蓄積するスペースです。テキストの概要に興味がある人のための良いガイドになりたいです。
まず、テキストが要約する詳細なトピックが作曲されていることを理解し、この分野を導いた主要な論文を見ていきます。それ以来、直接テキストサマリーモデルを作成するために必要なコード、データセット、およびプレクレーンモデルをリストしました。
テキストの要約へのイントロ
論文
リソース
その他
Berry、Dumais、&O'Brien(1995)は、テキストの概要を次のように定義しています。
テキストの要約は、最も重要な情報をテキストから蒸留して特定のタスクとユーザーを作成するプロセスです
これは、単語で与えられたテキストの間で重要な情報のみを洗練するプロセスです。ここでは、精製の表現と重要性の重要性はかなり抽象的で主観的な表現なので、私は個人的に次のように定義したいと思います。
f(text) = comprehensible information
言い換えれば、テキストの概要は、元のテキストを簡単で貴重な情報に変換することです。人間は、いくつかの文書に長い間または分割されている多くのテキスト情報で見るのが難しいです。時々、あなたは多くの専門的な用語を知りません。これらのテキストを、元のテキストをよく反映しながら、シンプルで簡単な形式に反映することは非常に価値があります。もちろん、本当に価値があり、それを変更する方法は、要約や個人的な好みの目的によって異なります。
この観点から、テキストは、議事録、新聞エンジニアの見出し、紙の要約、履歴書などのテキストを作成するタスクだけでなく、テキストをグラフや画像に変換するタスクを要約するだけではないと言えます。もちろん、それは単なる要約ではないため、テキストの要約であるため、要約のソースはテキストの形式で制限されています。 (概要の要約は、テキストやビデオだけでなくテキストだけでなく、テキストだけでなく、画像キャプションであるため、後者の例はビデオ要約です。ビジョンとNLPの境界がぼやけている場合、最近の深い学習傾向を考慮して、プレフィックスとして「テキスト」を「テキスト」にすることが意味がないかもしれません。
一般に、テキストの概要タスクは、要約の生成方法に応じて、抽出的な要約(以下とextと呼ばれる)および抽象的要約(ABS)に分割されます。 (Gudivada、2018)
抽出方法元のテキストの既存の単語、フレーズ、または文のサブセットを選択して、要約を形成します。対照的に、抽象的な方法は、最初に内部セマンティック表現と自然言語の世代間技術を使用します。
extは通常、文の重要性をスコアリングし、それを選択して結合して要約を作成します。読書中に蛍光ペンをペイントするタスクに似ています。一方、 ABSは元のテキストに基づいていますが、新しいテキストを生成するNLG(自然言語生成)メソッドです。 extは、元のテキストのテキストのために式に限定された表現を含めることはほとんどありません。一方、ABSには、モデルに新しいテキストを作成する必要があるため、前例のない表現を作成する可能性があるという利点がありますが、より柔軟なアプローチがあります。
さらに、元のテキストの数に従って、単一/マルチドキュメントの要約のテキストフォームに従って、キーワード/文の要約に従って、要約プロセスで使用される外部情報の量に従って、要約プロセスに従って、要約などのさまざまな区別があります。
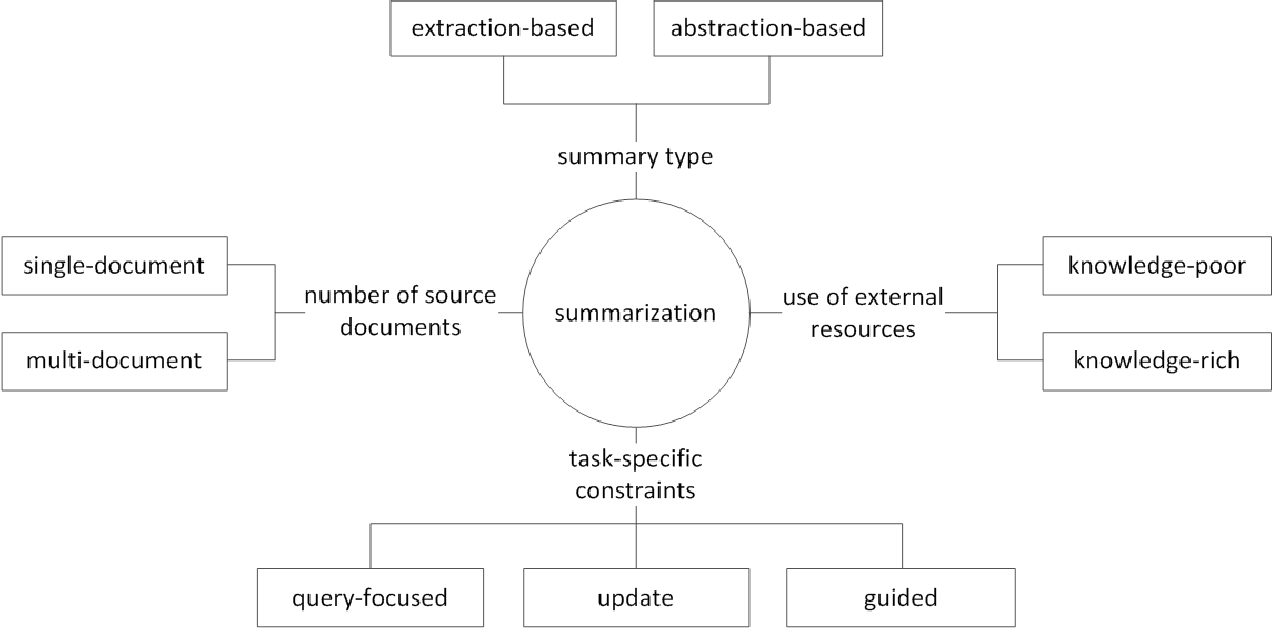
(G. Sizov(2010)。抽出ベースの自動要約:要約技術の理論的および経験的調査
テキストの要約の分野での主要な研究トピックを見て、この分野でどのような課題を考えてみましょう。
マルチ /ロングドキュメントの要約
前述のように、要約タスクは、理解できないテキストを理解できる情報に変更することです。したがって、元のテキスト、または複数のソースのドキュメントの概要が長くなるほど、ドキュメントの1つではなく、概要の有用性が増加します。問題は、同時に、要約の難しさも増加することです。
このため、元のテキストが長くなればなるほど、計算の複雑さがより迅速に増加します。これは、過去のテキストランなどの統計的方法よりもトランスを含む最近のニューラルネットワークベースの方法では、はるかに重要な問題です。第二に、元のテキストが長くなればなるほど、コンテンツの中核、つまりノイズ。何がノイズと何が有益であるかを識別するのは簡単ではありません。最後に、長いテキストやさまざまなソースには、さまざまな視点と内容が同時にあるため、適切にカバーする要約を作成することが困難です。
マルチドキュメント要約(MDS)
MDSは、複数のドキュメントの要約です。一見すると、一貫した傾向と観点から1つのテーマを説明するドキュメントを要約するよりも、さまざまな著者のさまざまな視点の記事を要約することは困難です。もちろん、MDSの場合でも、通常、同様のトピックを扱う同じクラスタードキュメントに基づいていますが、重要な情報を特定し、多くのドキュメント間で延長情報をフィルタリングするのは簡単ではありません。
特定の製品のレビューを要約するタスクは、最も簡単なMDSの例です。通常、意見の要約と呼ばれるこのタスクは、短いテキストの長さと主観性によって特徴付けられます。 Wikiドキュメントを作成する作業もMDSと見なすことができます。 Liu et al。 (2018)は、WikiドキュメントのWebサイトテキストの元のテキストであり、これは要約と見なされる元のテキストであり、Wiki作成モデルを作成します。
長い文書の要約
Liu et al。 (2018)は、長いテキストを入力として受け入れる統計的な方法であり、重要な文のみを使用してモデルの入力として使用して、押し出し要約を作成します。さらに、トランスコンピューティングのボリュームを減らすために、入力はブロック単位に分割され、この時点で1-Dコンボリューションは、個々の注意キーと値の数を減らすためのAttensionメソッドを使用します。 Big Bird(2020)の論文は、変圧器の計算を減らすために、すべての既存の単語の組み合わせではなく、まばらな態度メカニズム(線形)を導入します。その結果、同じパフォーマンスハードウェアが最大8倍長く要約されています。
一方、Gidiotis&Tsoumakas(2020)は、一度に長いテキストの要約の問題を解決せず、いくつかの小さなテキストの要約に変える分裂と征服にアプローチしようとします。元のテキストとターゲットの要約を複数の小さな小さなソースターゲットペアに変更して、モデルをトレーニングします。推論では、このモデルを介して部分的な要約出力を集約して、完全な概要を作成します。
パフォーマンスの改善
どのようにしてより良い要約を作成できますか?
転送学習
最近、NLPで事前削除モデルを使用することはほぼデフォルトになりました。では、テキストの要約でより良いパフォーマンスを示すことができる、どのような種類の構造を作成する必要があるのでしょうか。どのオブジェクトを持っているべきですか?
Pegasus(2020)では、Rougeスコアに基づいて重要と見なされる文を選択するGSG(Gap Sentences Generation)メソッドは、テキストの要約プロセスに類似しており、異議がより高いパフォーマンスを示すと想定しています。現在のSOTAモデルであるBART(2020)(双方向および自動回帰トランス)は、入力テキストの一部にノイズを追加し、元のテキストとして復元する自動エンコーダーの形で学習します。
Knowedgeが強化したテキスト生成
テキストからテキストへのタスクでは、元のテキストのみで目的の出力を生成することがしばしば困難です。したがって、モデルと元のテキストにさまざまな知識を提供することにより、パフォーマンスを改善する試みがあります。これらのKnowedgeのソースまたは提供は、さまざまなタイプのキーワード、トピック、言語機能、知識ベース、知識グラフ、および接地されたテキストによって異なります。
たとえば、Tan、Qin、Xing、&Hu(2020)は、複数のアスペクトベースの要約を変換するために一般的なサミリーデータセットを提供し、特定の側面に関連するより豊富な情報をモデルの特定の側面に配信します。ウィキペディアを使用してください。もっと知りたい場合は、Yu et al。 (2020)によって書かれた調査論文を読んでください。
編集後のコレクション
一度に良い要約を作成するのはいいことですが、簡単ではありません。それでは、要約を作成してから、さまざまな基準で確認して変更してみませんか?
たとえば、Cao、Dong、Wu、&Cheung(2020)は、生成された概要にふさわしい神経補正モデルを適用することにより、事実上の誤りを減らす方法を提案しています。
さらに、**グラフニューラルネットワーク(GNN)**を適用する多くの試みもあります。これは最近多くの注目を集めています。
データ不足の問題
テキストの概要は、多くの時間がかかるタスクであり、人間にとっては容易ではありません。したがって、他のタスクと比較して、ラベル付きデータセットを作成するのに比較的大きなコストがかかります。もちろん、トレーニングにはデータが不足しています。
前述の前提条件モデルを使用した転送学習方法に加えて、監視されていない学習または強化学習方法またはいくつかのショット学習アプローチの試みで学習しています。
当然、適切な要約データを作成することも非常に重要な研究トピックです。特に、現在の要約関連データセットの多くは、英語のニュースタイプに偏っています。その結果、WikilinguaやMlsumなどの多言語データセットが作成されています。詳細については、MLSUM:The MultiNINGUAL Summarization Corpusをご覧ください。
メトリック/評価方法
私は以前に「良い」という圧倒的な表現を書きました。 「良い要約」とは何ですか? Brazinskas、Lapata、&Titov(2020)は、良い要約の判断に基づいて、次の5つのことを使用しています。
問題は、これらの部分を測定するのは容易ではないことです。テキストサマリの最も一般的なパフォーマンス測定インジケーターは、ルージュスコアです。ルージュスコアにはさまざまなバリエーションがありますが、基本的に「生成された概要と参照の概要の言葉はどうですか?」同様のことを意味しますが、フォームが異なる場合、または単語順序が変更された場合、より良い要約であっても、スコアが低くなる可能性があります。特に、ルージュスコアを上げようとすると、概要の表現力のある多様性を損なう可能性があります。これが、多くの論文が、Rougeスコアだけでなく、高価なお金で追加の人間の評価結果を提供する理由です。
Lee et al。 (2020)RDASS(参照およびドキュメントの認識セマンティックスコア)を提示します。これは、テキストとリファレンスの概要と同様であり、ベクトルベースの同様の道路によって測定されます。この方法は、言葉とさまざまな形態を組み合わせてさまざまな意味と文法機能を表現する韓国語評価の正確性を高めると予想されます。 Kryściński、McCann、Xiong、およびSocher(2020)は、事実の一貫性を評価するための弱く監視されたモデルベースのアプローチを提案しました。
制御可能なテキスト生成
特定のドキュメントに関する最良の要約は1つだけですか?そうしません。異なる傾向を持つ人々は、同じテキストに対して異なる要約テキストを好むことができます。あなたが同じ人であっても、あなたが望む要約は、要約または状況の目的に依存します。ユーザーが指定した条件に従って、出力を目的のフォームに調整するこの方法は、制御可能なテキスト生成と呼ばれます。特定のドキュメントに対して同じ要約を作成する一般的な要約と比較して、パーソナライズされた要約を提供できます。
生成される概要は、理解して価値があるだけでなく、まとめた状態にも密接に関連している必要があります。
f(text, condition ) = comprehensible information that meets the given conditions理解可能な情報
サマリーモデルにどのような条件を追加できますか?そして、その状態に合った要約をどのように作成できますか?
アスペクトベースの要約
AirPodユーザーのレビューを要約する場合、音質、バッテリー、デザインを分割して、各側面を要約することをお勧めします。または、記事の執筆スタイルや感情を調整することをお勧めします。この元のテキストでは、特定の側面または機能に関連する情報のみを要約する作業は、アスペクトベースの要約と呼ばれます。
以前は、主にモデル学習に使用されていた事前定義された側面でのみ機能したモデルのみが、Tan、Qin、Xing、およびHu(2020)などの学習に与えられなかったarbitrary意的な側面の推論を可能にしようとしました。
クエリに焦点を当てた要約(QFS)
条件がクエリの場合、QFSと呼ばれます。クエリは主に自然言語なので、主なタスクはこれらのさまざまな表現をうまく行い、元のテキストと一致させる方法です。これは、私たちがよく知っているQAシステムに非常に似ています。
要約を更新します
人間は、学び、成長し続ける動物です。したがって、特定の情報に対する今日の価値は、1週間後の値とはまったく異なる場合があります。私がすでに経験したドキュメント内の内容の価値は低下し、まだ経験されていない新しいコンテンツはまだ高い価値を持っています。この観点から、ユーザーが以前に経験したドキュメントコンテンツに似た新しいコンテンツの新しい要約を作成するために、更新要約と呼ばれます。
Ctrlsumは、生成される要約を調整するために、テキストでさまざまなキーワードまたは説明的なプロンプトを使用します。これは、トレーニング段階で明示的に学習されていないキーワードまたはプロンプトに対して制御されているのと同じ結果を示すという点で、より一般的な対照テキスト要約モデルです。 Koh Hyun -Woongの要約ライブラリを使用して簡単に使用できます。
これに加えて、 **モデルの軽量などの典型的なDLトピックではなく、会話の要約に適した要約モデルを作成しようとするさまざまな試みと、ニュースやウィキペディアなどの構造化されたテキストではなく対話の要約が作成されます。トピックがあります。
テキストの概要フィールドで以下を知っている場合は、より簡単に勉強できるようになります。
NLPの基本概念の理解
トランス/バート構造とトレーニング前の客観的理解
最新のNLPペーパーの多くは、このバートのバリエーションであるTransformerとRobertaとT5に基づいたBertを含むいくつかの事前に既製のモデルに基づいています。したがって、それらの概略構造とトレーニング前の目標を理解している場合、それは論文を読んだり実装したりするのに大きな助けになります。
テキスト要約の基本概念
グラフニューラルネットワーク(GNN)
機械翻訳(MT)
MTは、SEQ2SEQの出現以来、NLPフィールドで最もアクティブなタスクの1つです。要約プロセスを1つのテキストを異なるタイプのテキストに変換するプロセスとして見ると、MT関連の研究とアイデアの多くが要約分野で借りたり適用されたりする可能性が高いため、一種のMTと見なすことができます。
| 年 | 紙 | キーワード |
|---|---|---|
| 2004年 モデル | Textrank :テキストに注文を持ち込みます R.ミハルシア、P。タラウ 抽出部門の古典的なものであり、まだアクティブです。ドキュメント内の重要な文(すなわち、要約に含まれる)は、他の文で高い賢さがあると仮定して、Google検索エンジンの最初のアイデアであるPagerankアルゴリズムであるという仮定です。各文は、文書レベルの加重グラフを構成して、ドキュメント内の別の文との類似性を計算し、要約にこの高い重量文を含みます。 統計ベースの監視されていない学習方法は、個別の学習データがなければ合理的であり、アルゴリズムは明確で理解しやすいです。 - [ライブラリ] gensim.summarization(3.xバージョンのみが利用可能です。バージョン4.xから削除)、pytextrank - [理論/コード] lovit。テキストトランクとコア文抽出を使用したキーワード抽出 | 内線、 グラフベース(Pagerank)、 監視なし |
| 2019年 モデル | BERTSUM :ふさわしいエンコーダを使用したテキスト要約(OfficeIAD) Yang Liu、Mirella Lapata / EMNLP 2019 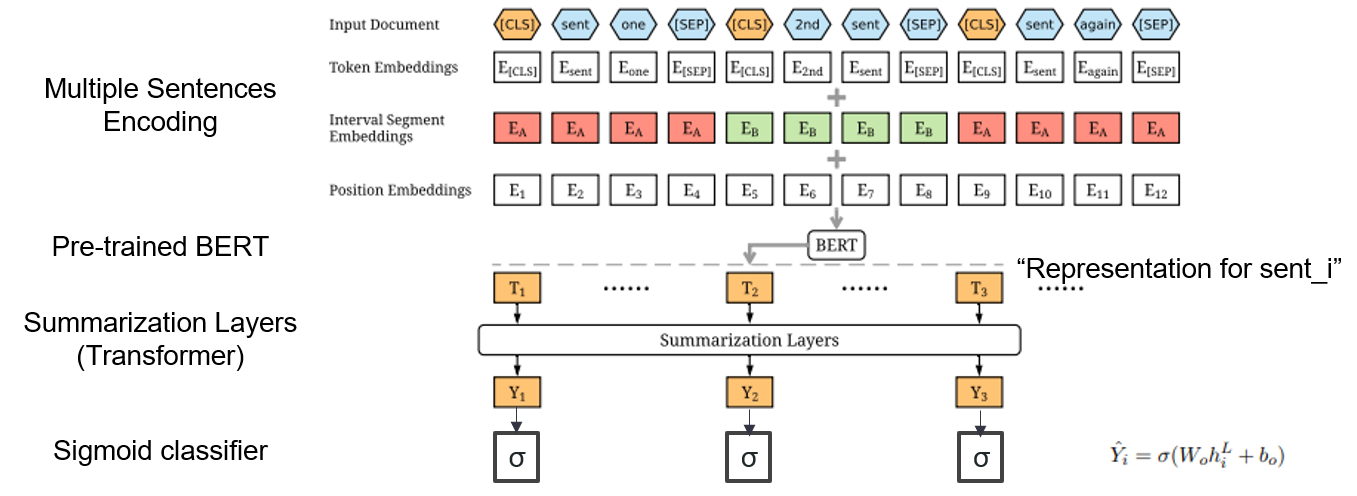 要約するには、事前に訓練されたBertを使用するにはどうすればよいですか? 要約するには、事前に訓練されたBertを使用するにはどうすればよいですか?Bertsumは、各文の前に[CLS]トークンを挿入し、間隔セグメント埋め込みを追加して複数の文を1つの入力に追加する修正された入力埋め込みを提案します。 EXTモデルは、BERTに変圧器層を備えたエンコーダー構造を使用し、ABSモデルはEXTモデルに6層トランスデコーダーを備えたエンコーダーデコーダーモデルを使用します。 - [レビュー] Lee Jung -Hoon(韓国DSBA) - [韓国] kobertsum | ext/abs、 Bert+Transformer、 2段階の微調整 |
| 2019年 事前削除モデル | BART :自然言語の生成、翻訳、および理解のためのシーケンスからシーケンス前訓練 マイク・ルイス、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Ves Stoyanov、Luke Zettlemoyer / ACL 2020 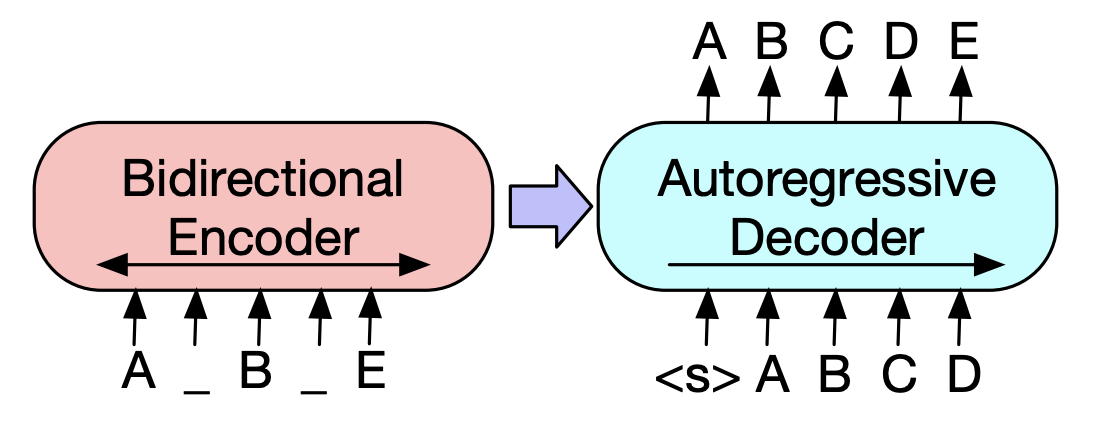 Bertはビドレクトリックエンコーダーであり、Generationタスクから弱いタスクであり、GPTには自動回帰モデルを使用して双方向情報を取得しないという不利な点があります。 Bertはビドレクトリックエンコーダーであり、Generationタスクから弱いタスクであり、GPTには自動回帰モデルを使用して双方向情報を取得しないという不利な点があります。BARTにはそれらを組み合わせたSEQ2SEQフォームがあるため、1つのモデルでさまざまな除去手法を試すことができます。その結果、テキストが充填されている(テキストスパンを1つのマスクトークンに変更)と文のシャッフル(文をランダムに混合)は、要約の分野でKi Sotaモデルを上回るパフォーマンスを示しています。 - [韓国] SKT T3K。コバート - [レビュー] Jin Myung -Hoon_Video、Lim Yeon -SOO_ Jiwung Hyun_によって書かれた | 腹筋、 seq2seq、 自動エンコーダーの除去、 テキストの透過 |
| 2020 モデル | マッチサム:テキストマッチングとしての抽出要約(オフィス) Ming Zhong、Pengfei Liu、Yiran Chen、Danqing Wang、Xipeng Qiu、Xuanjing Huang / ACL 2020 - [レビュー] Yoo Kyung(韓国DSBA) | 内線 |
| 2020 技術 | あらゆる側面に関するテキストの要約:知識に基づいた弱く監視されたアプローチ(公式コード) Bowen Tan、Lianhui Qin、Eric P. Xing、Zhiting hu / emnlp 2020 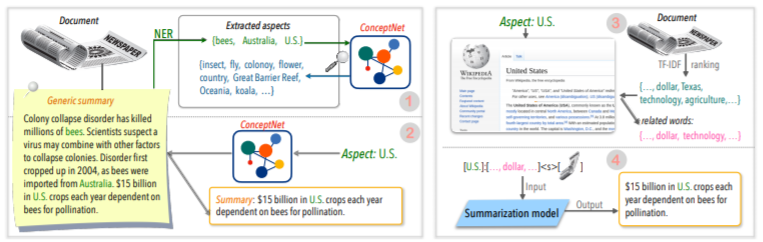 アスペクトベースの要約は、モデルを学習しても学習されていても学習されているデータの事前定義された側面でのみ実行されるという点で簡単ではないタスクです。 このペーパーでは、外部の知識ソースを利用してこの問題を解決します。 - 一般的な要約を複数のアスペクトベースの概要に変換するために2つのステップを踏みます。まず第一に、アスペクトの数を増やすために、一般的な要約から抽出されたエンティティはシードであり、コンセプネットからその近隣に抽出され、それぞれをアスペクトと見なします。 ConcepNetを再度使用して、これらの各側面のPsedo Summaryを作成します。コンセプネットの対応する側面に接続された周囲のエンティティを抽出し、一般的な要約内で含む文のみを抽出します。これは、そのエンティティ(アスペクト)の概要と見なされます。 -Wikipediaは、モデルの与えられた側面に関連するより豊富な情報を提供するために使用されます。具体的には、ドキュメントに表示される単語の中で、ドキュメントのTF-IDFスコアが高く、同時に同時に、ウィキペディアページの10ワードのリストは、モデル入力のアスペクトに追加されます。 このように、プレチューニング前モデル(BART)は、小さなデータを持つ任意の側面にも優れていました。 | アスペクトベース、 Knowlege Rich |
| 2020 レビュー | すぐにテキストの要約は何ですか? Dandan Huang、Leyang Cui、Sen Yang、Guangsheng Bao、Kun Wang、Jun Xie、Yue Zhang / EMNP 2020 Rougeスコアに加えて、精度と流encyさに関連する8つのメトリック(ポリトープ)に従って10の代表的な要約モデルが評価されます。結果を要約するには、 - 従来のルールベースの方法は、ベースラインとしてまだ有効です。 同様の設定では、EXTモデルは一般に、忠実さと事実の整合性のパフォーマンスの向上を示しています。主な欠点は、抽出モデルの不説明、抽象的モデルの省略と固有の幻覚です。 - 文の表現を作成するための変圧器などのより複雑な構造は、複製の問題を除いてあまり役に立ちません。 -copy( Pointer-generator )は、複製の詳細であり、単語レベルの複製問題と、不正確な内因性を混合することで効果的に解決します。しかし、ある程度冗長性を引き起こす傾向があります。 カバレッジは大きなマージンであり、繰り返しエラー(重複)が減少しますが、同時に追加と不正確な内因性エラーが増加します - extの後のABSであるハイブリッドモデルはリコールに適していますが、元のテキスト(抽出されたスニペット)の一部を介して要約を生成するため、不正確なエラーに問題がある可能性があります。 トレーニング前、特にエンコーダーのみモデル(Bertsumextabs)よりもエンコーダデコーダーモデル(BART)は、要約で非常に効果的です。これは、すべての理解と入力の作成を課すことが、コンテンツの選択と組み合わせに非常に役立つことを示唆しています。同時に、ほとんどのABSモデルは最前線に焦点を当てていますが、バートは元のテキストをすべて見ています。 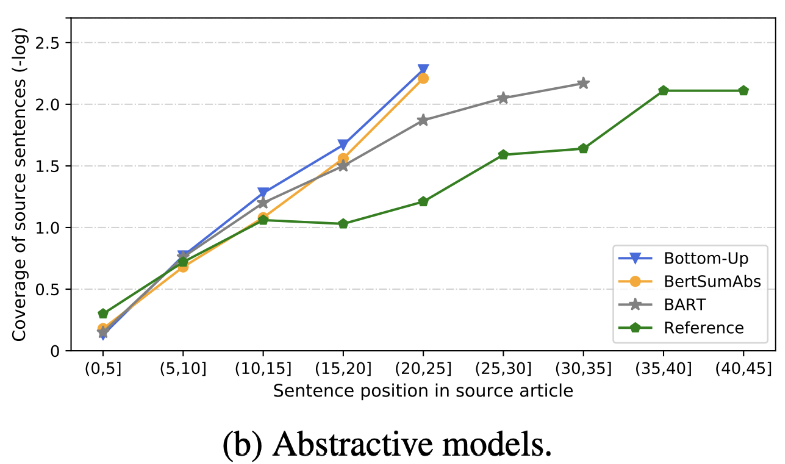 - [レビュー]キム・ハン - ギル、ホフン | レビュー |
| 2020 モデル | Ctrlsum :一般的な制御可能なテキスト要約(公式コード)に向けて Junxian He、WojciechKryściński、Bryan McCann、Nazneen Rajani、Caiming Xiong Ctrlsumは、キーワードまたは説明的なプロンプトを介して生成された要約ステートメントを調整できる制御可能なテキスト要約モデルです。 トレーニング:一般的な要約データを変更してキーワードベースの制御可能な要約データセットを作成するには、サブシーケンスを選択します。これは概要に最も似ており、そこでキーワードを抽出します。これをドキュメントの入力に入れて、事前調整BARTを完了します。 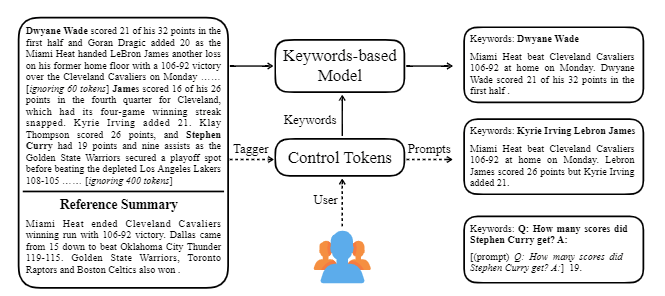 -Inperence:下の画像に示すように、特定のエンティティの概要を作成したり、概要の長さを調整したり、質問に対する回答を作成したりするなど、要約の要約を追加できます。モデリング段階でそのようなプロンプトを明示的に学習していないかのように機能することは注目に値しますが、プロンプトを理解して要約を生成するように機能しました。 GPT-3に似ています。 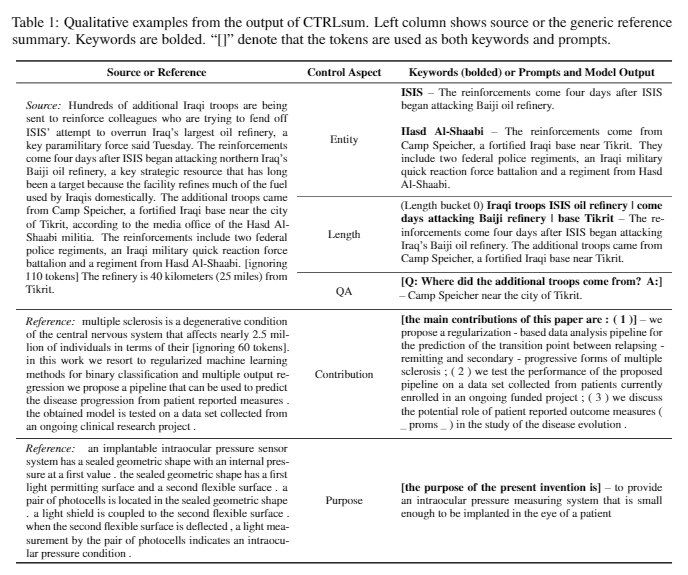 - [ライブラリ]制御可能な要約ベースのCtrlsumのパッケージ | 制御可能、 バート |
Paper Digest:テキスト要約に関する最近の論文
コード付きの論文:最新の論文
EMNLP 2020論文腫瘍化
実際、サマリーモデルを作成および練習するために必要なコード、データ、およびプリトレインモデルを要約しました。これは主に韓国のデータであり、英語関連の資料については、論文項目の各論文のコード部分を参照してください。
以下で使用される弱い人の意味は次のとおりです。
w :単語数の平均値。 s :文の平均数の平均値
例) 13s/214w → 1s/26wは、平均13文(平均214語)と平均1文(平均26語)で構成される要約テキストを提供することを意味します。
abs概要; ext :抽出概要
| データセット | ドメイン /長さ | 音量 (ペア) | ライセンス |
|---|---|---|---|
| みんなの単語ドキュメントの要約 短いニューステキストのタイトル、3文とext summay 新聞の馬とIDと一緒にいるすべての人のすべての言葉は、字幕、メディア、日付、トピックに関連する追加情報を取得できます。 | ニュース -ORIGIN→3S(ABS); 3s(ext) | 13,167 | 韓国語国立研究所 (個別契約) |
| aihub-documentの要約テキスト 新聞記事、貢献、雑誌記事、裁判所のレビューのためのABSおよびEXT SUMMAY - [eda]データEDAノートブック - 韓国文書の抽出概要と作成の概要AIコンテスト(〜20.12.09) | - 新聞記事300,000条、60,000の貢献、10,000の雑誌記事、裁判所の判決30,000 13S/214W→1S/26W(ABS); 3s/55W(ext) | 400,000 | aihub (個別契約) |
| aihub-summary アカデミックペーパーと特許仕様のすべてのABSの要約とセクション | - 学術論文、特許仕様 -ORIGIN→ABS | 350,000 | aihub (個別契約) |
| aihub-bookデータの概要 さまざまなトピックに関するオリジナルの韓国の本のABSサマリー | -lifetime、生命、税、環境、コミュニティ開発、貿易、経済、労働など。 -300-1000文字→ABS | 200,000 | aihub (個別契約) |
| SAE4K | 50,000 | CC-SA-4.0 | |
| SCI-NEWS-SUM-KR-50 | ニュース(IT/科学) | 50 | mit |
| Wikilingua :多言語の抽象的要約データセット(2020) マニュアルサイトWikihowに基づいて、韓国語や英語などの18の言語 - ペーパー、コラボートノートブック | - ドキュメントへの方法 -391W→39W | 12,189 (合計770,087のコル) | 2020、 CC by-nc-sa 3.0 |
| データセット | ドメイン /長さ | 音量 | ライセンス |
|---|---|---|---|
| scisummnet (紙) ACL(NLP)研究の3種類の要約を提供します -cl-scisumm 2019-task2(レポ、紙) -cl-scisumm @ emnlp 2020-task2(repo) | - 研究論文 (計算言語学者、NLP) 4,417W→110W(Paper Abstract); 2s(引用); 151W(ABS) | 1,000(ABS/ EXT) | CC by-sa 4.0 |
| ロングサム 比較的長いリストの要約(関連するブログ投稿 - 関連するABS、関連会議のビデオトーク) -Longsumm 2020@emnlp 2020 -longsumm 2021@ naacl 2021 | - 研究用紙(NLP、ML) -ORIGIN→100S/1,500W(ABS); 30S/ 990W(ext) | 700(abs) + 1,705(ext) | アトリビューション - コマーシャル - 恥ずかしさ4.0 |
| cl-laysumm NLPおよびMLフィールドの非専門家に簡単なレイヤーを提供します。 -cl-laysumm @ emnlp 2020 | - 研究用紙(てんかん、考古学、材料工学) -ORIGIN→70〜100W | 600(ABS) | 個々の契約のニーズ([email protected]にメールを送信) |
| グローバルボイス:自動ニュースの要約の交差境界線(2019) -紙 | - ニュース -359W→51W | ||
| MLSUM :多言語要約コーパス CNN/Daily Mailデータセットと同様に、ニュース記事のハイライト/説明は、英語、フランス語、ドイツ、スペイン語、ロシア語、トルコのビルドデータセットの要約と要約と見なされます - ペーパー、使用(ハギングフェイス) | - ニュース -790W→56W (enベース) | 1.5m(ABS) | 非営利の研究目的のみ |
| モデル | トレーニング前 | 使用法 | ライセンス |
|---|---|---|---|
| バート(多言語) バートベース(110mパラメーター) | - ウィキペディア(多言語) - ワードピース。 -110K共有の音声 | BERT-Base, Multilingual Cased推奨バージョン( --do_lower_case=falseオプション)-TENSORFLOW | グーグル (Apache2.0) |
| コバート バートベース(92mパラメーター) | -wikipedia(5m文)、ニュース(20m文) -Sentencepiece 8,002の音声(未使用のトークンなし) | -pytorch - すべてがKobert-Transformers(Monologg)を介してHuggingface Transformers Libraryとして利用可能で、Distilkobertが利用可能 | Sktbrain (Apache-2.0) |
| Korbert バートベース | -News(10年)、ウィキペディアなど。23GB -ETRI形態分析API / WordPiece(2つのバージョンを個別に提供) -30,349語彙 ラテンアルファベット:ケース - [はじめに] Lim Jun(Etri)。 NLU TechはKorbertと話します | -pytorch、tensorflow | エトリ (個別契約) |
| Kcbert バートベース/大 | - デイバーニュースコメント(12.5GB、890万文) (19.01.01〜20.06.15記事やコメントの記事からコメント -tokenizers bertwordpiecetokenizer -30,000の語彙 | Beomi (MIT) | |
| コバート バート(124m) | -wikipedia(5m)およびその他(ニュース、本、みんなの言葉(会話、ニュース、...)、Cheong wa dae National Pittationなど。 -TockenizersのキャラクターBPEトークネザー 30,000語の語彙(含まれています) - [例] Seujung。 Kobart-Summarization(コード、デモ) | - サマリータスクの専門化 -Huggingface Transformers Libraryサポート -pytorch | SKT T3K (変更されたMIT) |
| 年 | 紙 |
|---|---|
| 2018年 | ニューラルネットワークベースの要約方法に関する調査 Y.ドン |
| 2020 | 自動テキスト要約技術と方法のレビュー Widyassari、AP、Rustad、S.、Shidik、GF、Noersasongko、E.、Syukur、A。、&Affandy、A。 |
| 2020 | 知識が強化されたテキスト生成の調査 Wenhao Yu、Chenguang Zhu、Zaitang Li、Zhiting Hu、Qingyun Wang、Heng Ji、Meng Jiang |
| 年 | 紙 | キーワード |
|---|---|---|
| 1958年 | 文学要約の自動作成 ph luhn | gen-ex |
| 2000 | 統計翻訳に基づくヘッドライン生成 M. Banko、Vo Mittal、およびMJ Witbrock | gen-abs |
| 2004年 | Lexrank :テキストの要約の顕著性としてのグラフベースの語彙中心性 G.エルカン、ドラデフ、 | gen-ex |
| 2005年 | 文ベースの単一文書の要約 J.ジャガディーシュ、P。ピンガリ、およびV.バルマ | gen-ex |
| 2010年 | 準同期文法を備えたタイトル生成 K. Woodsend、Y。Feng、およびM. Lapata、 | gen-ex |
| 2011年 | 潜在的なセマンティック分析を使用したテキストの要約 Mg Ozsoy、Fn Alpaslan、およびI. Cicekli | gen-ex |
| 年 | 紙 | キーワード |
|---|---|---|
| 2014年 | 神経機械翻訳に非常に大きなターゲット語彙を使用することについて S. Jean、K。Cho、R。Memisevic、およびYoshua Bengio | gen-abs |
| 2015年 モデル | NAMAS :抽象的要約のための神経注意モデル(コード) Am Rush、S。Chopra、J。Weston / EMNLP 2015 既存の文の選択と組み合わせ方法を超えるために、Flag Seq2Seqにターゲットツーソースの注意を紹介して、抽象的な要約を作成します。 | 腹筋 ATTを使用したseq2seq |
| 2015年 | セマンティック表現を使用した抽象的な要約に向けて Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016年 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016年 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016年 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017年 モデル | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 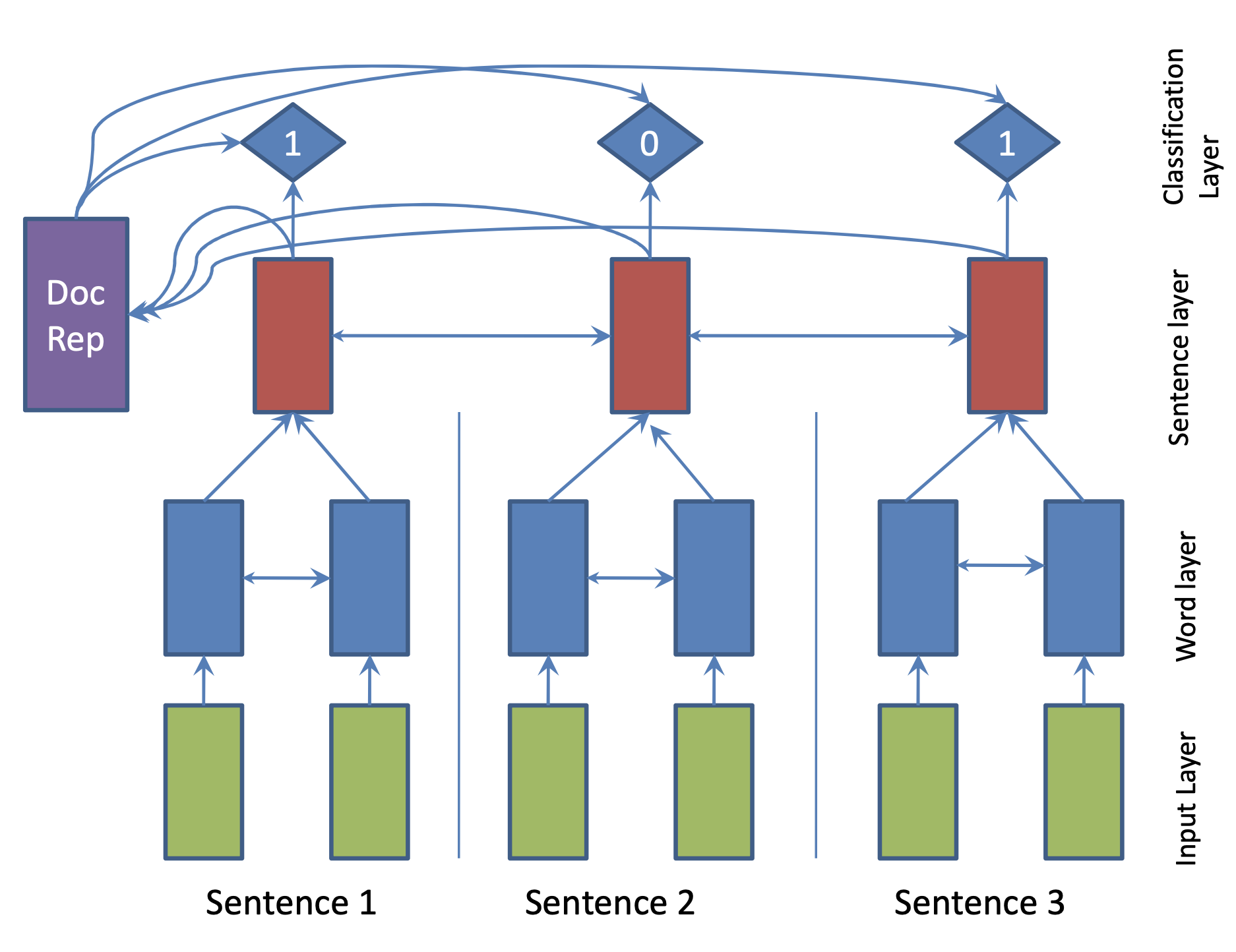 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017年 モデル、 技術 | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 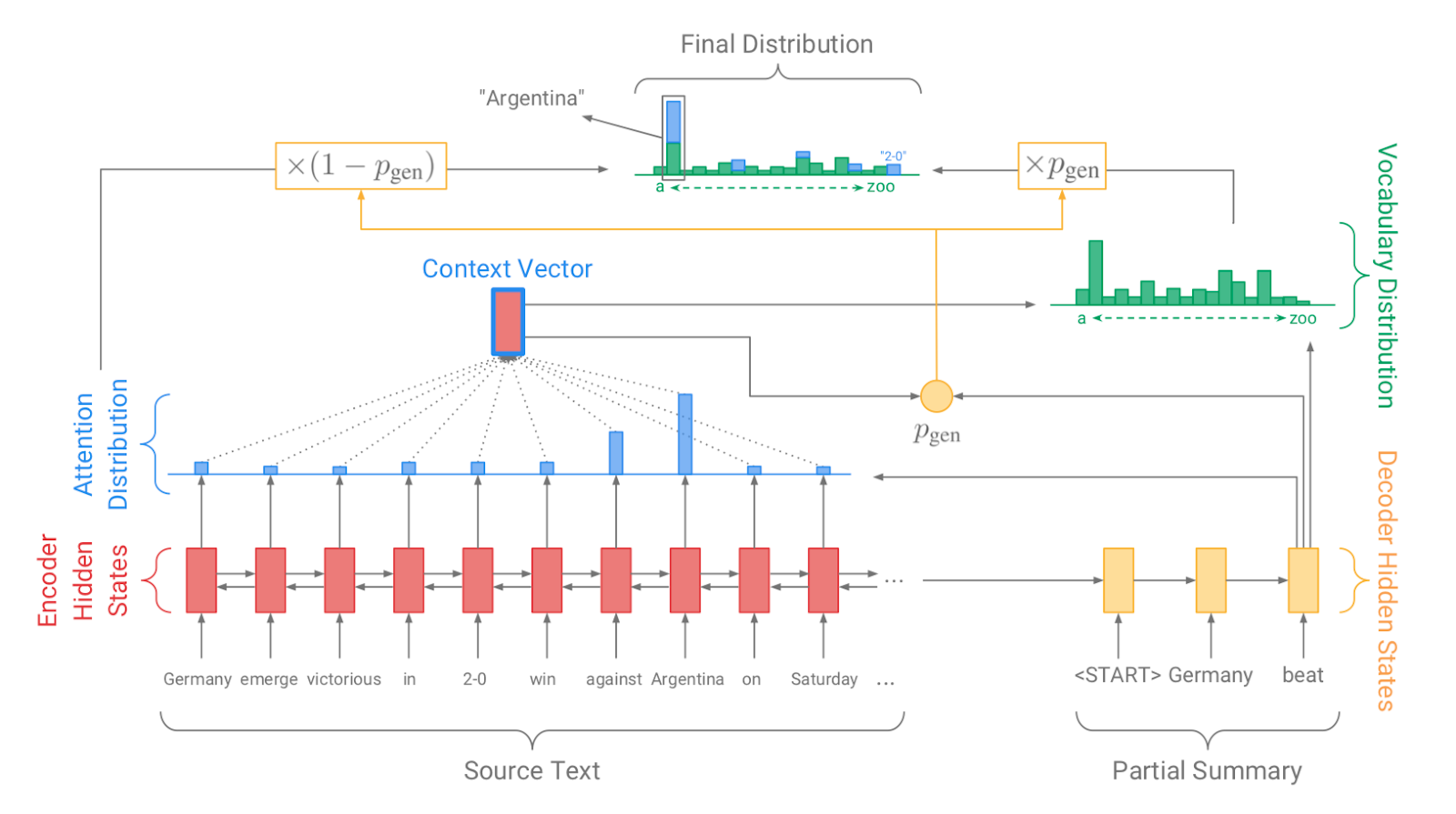 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017年 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017年 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017年 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017年 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018年 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018年 モデル | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018年 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018年 モデル | ボトムアップ Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, ハイブリッド、 ボトムアップ |
| 2018年 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018年 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018年 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018年 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018年 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018年 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018年 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018年 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018年 | Global Encoding for Abstractive Summarization | |
| 2018年 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018年 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018年 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019年 モデル | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019年 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019年 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019年 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019年 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019年 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019年 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019年 モデル | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 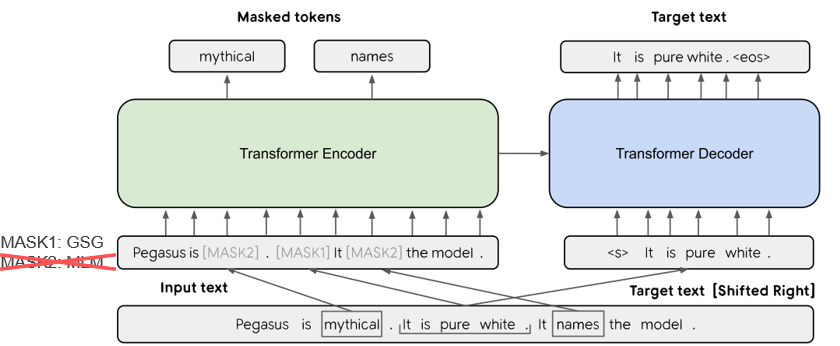 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 モデル | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


