Text Summarization Repo
1.0.0
Among the NLPs, it is a space that accumulates quality data related to the text summary field. I would like to be a good guide for those who are interested in the text summary.
First of all, we understand what detailed topics the text summarizes is composed and look at the main papers that have led this field. Since then, we have listed the code, datasets, and pre -crane models needed to create a direct text summary model.
Intro to text Summarization
PAPERS
Resources
Others
Berry, Dumais, & O'Brien (1995) defines the text summary as follows:
Text Summarization is the Process of Distilling The Most Important Information from a text to Produce an A Particular task and user
It's a process of refining only important information among the text given in a word. Here, the expression of refining and the importance of important is a rather abstract and subjective expression, so I personally want to define it as follows.
f(text) = comprehensible information
In other words, the text summary is to convert the original text into an easy and valuable information . Humans are hard to see at a glance of text information, which is long or divided into several documents. Sometimes you don't know a lot of professional terms. It is quite valuable to reflect these texts into a simple and easy -to -understand form while reflecting the original text well. Of course, what is really worthwhile and how to change it will vary depending on the purpose of summarizing or personal tastes.
From this point of view, it can be said that the text summarizes not only the tasks that create texts such as the minutes, newspaper engineer headline, paper Abstract, and resume, as well as tasks that convert text into graphs or images. Of course, since it is not just Summarization, it is a Text Summarization , so the source of the summary is limited in the form of text. (The summary of the summary is because it can be not only text or video as well as Text.In example, the former example is Image captioning, the latter example is Video Summarization. Considering the recent deep learning trend when the boundary between VISION and NLP is getting blurry, it may be meaningless to put 'TEXT' as a prefix.)
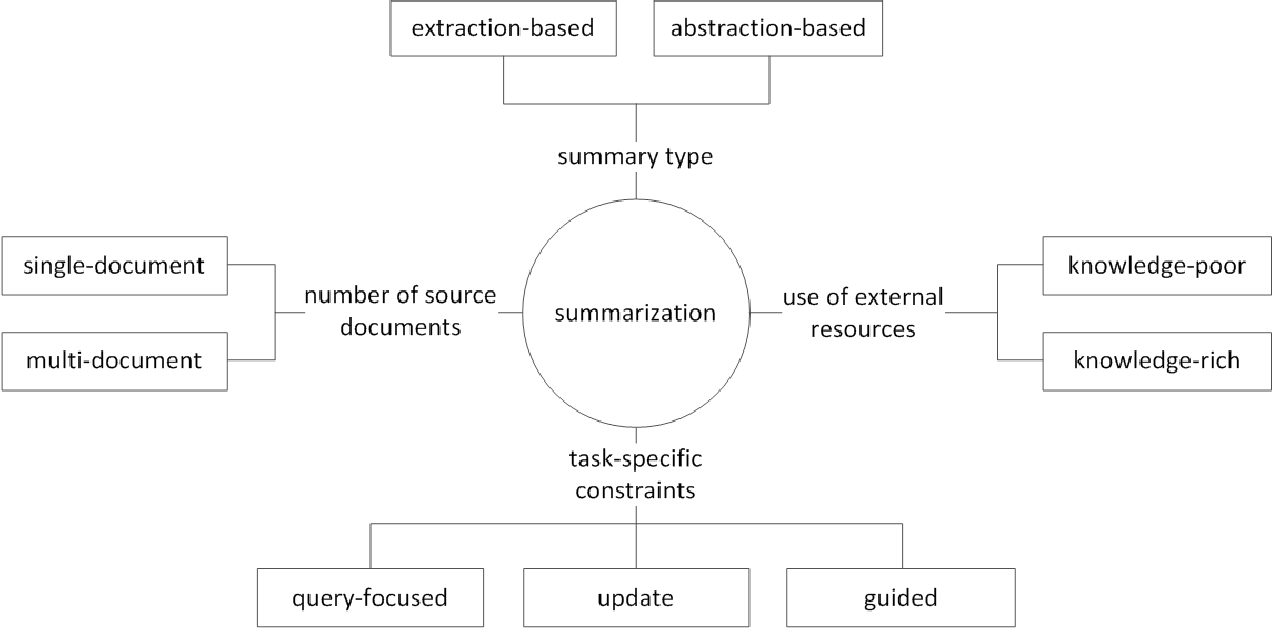
In general, the text summary task is divided into extractive summarization (hereinafter referred to as EXT) and Abstractive Summarization (ABS), depending on how they generate a summary. (Gudivada, 2018)
Extractive Methods Select a SubSet of Existing Words, Phrases, or Sentences in the Original text to Form a Summary. In Contrast, Abstractive Methods First Build an internal semantic representation and the use natural language generational technology.
EXT usually scores the importance of the sentence, and then selects and combines it to create a Summary. It's similar to the task of painting a highlighter while reading. ABS , on the other hand , is based on the original text, but is a NLG (NATURAL LANGUAGE GENERATION) method that generates a new text . EXT is unlikely to include expressions that are limited to expressions because of the text in the original text. ABS, on the other hand, has the advantage that there is a possibility of creating an unprecedented expression because it must create a new text in the model, but it has more flexible approaches.
In addition, according to the number of the original texts, according to the text form of Single/Multi Document Summarization, Keyword/Sentence Summarization, according to how much external information is used in the summary process , according to the summary process There are various distinctions such as Summarization.
(G. SIZOV (2010). Extraction-Based Automatic Summarization: Theoretical and Empirical Investigation of Summarization Techniques
Let's take a look at major research topics in the field of Text Summarization and think about what kind of challenge in this field.
Multi / Long Documents Summarization
As mentioned earlier, the summary task is to change the Incomprehensible text to Comprehensible Information. Therefore, the longer the original text, or the summary of the documents of multiple sources, not one document, the more the utility of the summary increases. The problem is that at the same time, the difficulty of summary also increases.
For this reason, the longer the original text, the more rapidly the computational complexity increases. This is a much more critical problem in the recent neural network -based methods including transformer than in statistical methods such as TextRank in the past. Second, the longer the original text, the more not the core of the contents, that is, noise. It is not easy to identify what is noise and what is informative. Finally, long texts and various sources have various perspectives and contents at the same time, making it difficult to create a summary that covers it well.
Multi Documents Summarization (MDS)
MDS is a summary of a plurality of documents . At first glance, it will be difficult to summarize the articles of different perspectives of various authors than to summarize a document that describes one theme from a consistent trend and point of view. Of course, even in the case of MDS, it is usually based on the same cluster document that deals with similar topics, but it is not easy to identify important information and filter outluge information among many documents.
TASK, which summarizes reviews on certain products, is an example of MDS that is the easiest to think of. This task, usually called Opinion Summarization, is characterized by a short text length and a subjectivity. The work of creating a wiki document can also be considered as an MDS. Liu et al. (2018) is the original text of the website text on the Wiki document, which is the original text, which is considered to be a Summary, and it creates a wiki creation model.
Long Documents Summarization
Liu et al. (2018) is a statistical way to accept long text as an input, creating an extracement summary, using only important sentences and using it as an input of the model. In addition, in order to reduce the transformer computing volume, the input is divided into block units, and at this time, the 1-D Convolution uses the Attension method that reduces the number of individual Attention Key and Value. The Big Bird (2020) paper introduces Sparse Attension Mechanism (Linear) instead of a combination of all existing words to reduce the calculation of the transformer. As a result, the same performance hardware has been summarized up to eight times longer.
Gidiotis & TSOUMAKAS (2020), on the other hand, attempts to approach the Divide-and-Conquer, which does not solve the long text summary problem at once and turns it into several small text summaries. Training the model by changing the original text and the target summary to the multiple small smaller source-target pairs. In the inference, we aggregate the partial summaries output through this model to create a Complete Summary.
Performance Improvement
How can you create a better summary?
Transfer Learning
Recently, using Pretraining Model in NLP has become almost default. So what kind of structure should we have to create a prerealing model that can show better performance in Text Summarization? What object should I have?
In Pegasus (2020), the GSG (GAP SENTENCES Generation) method, which selects a sentence that is considered important based on the Rouge Score, assumes that the more similar to the text summary process and the objection will show the higher performance. The current SOTA model, BART (2020) (Bidirectional and Auto-Regression Transformers), learns in the form of an autoencoder that adds noise to some of the input text and restores it as an original text.
KNOWEDGE-Enhanced Text Generation
In Text-to-Text Task, it is often difficult to generate the desired output with the original text alone. So, there is an attempt to improve performance by providing a variety of KNOWEDGE to the model as well as the original text . The source or provision of these KNOWEDGE varies in various types of Keywords, Topics, Linguistic Features, Knowledge Bases, Knowedge Graphs, and Grounded Text.
For example, TAN, Qin, Xing, & Hu (2020) delivers a general Summry Dataset to convert a plurality of Aspect-based Summary, and delivers more rich information related to a given aspect to a given aspect to the model. Use Wikipedia for. If you want to know more more, yu et al. Read the Survey paper written by (2020).
POST-EDITING CORECTION
It would be nice to create a good summary at once, but it's not easy. So why don't you create a summary and then review and modify it in a variety of criteria?
For example, CAO, DONG, WU, & CHEUNG (2020) suggests a method of reducing factual error by applying Pretated Neural Corrector Model to the generated summary.
In addition, there are also many attempts to apply ** Graph Neural Network (GNN) **, which has been receiving a lot of attention recently.
Data Scarcity Problem
Text summary is a task that takes a lot of time, which is not easy for humans. Therefore, compared to other tasks, it costs relatively larger costs to create labeled Dataset, and of course, there is a lack of data for Training.
In addition to the transfer learning method using the previously mentioned Pretraining Model, we are learning in unsupervised learning or reinforcement learning methods or attempting a Few-shot learning approach.
Naturally, making good summary data is also a very important research topic. In particular, many of the current Summarization -related datasets are biased in news types in the English language. As a result, multilingual datasets such as wikilingua and mlsum are being created. For more information, take a look at MLSUM: The Multilingual Summarization Corpus.
Metric / Evaluation Method
I wrote a crushing expression of 'good' earlier. What is a 'good summary'? Brazinskas, Lapata, & Titov (2020) use the following five things based on the judgment of a good summary.
The problem is that it is not easy to measure these parts. The most common performance measurement indicator in text summaries is Rouge Score. There are various variants in the Rouge Score, but basically 'how is the word of the word of the generated summary and reference summary?' It means similar, but if you have a different form or if the word order changes, you can get a lower score even if it is a better summary. In particular, trying to raise the Rouge Score, it can result in harming the expressive diversity of the summary. This is why many papers provide additional Human Evaluation results with expensive money as well as Rouge Score.
Lee et al. (2020) presents a RDASS (Reference and Document Awareness Semantic Score), which is how similar it is to the text and reference summary, and then measured by the vector -based similar roads. This method is expected to increase the accuracy of Korean language evaluation, which combines words and various morphology to express various meanings and grammatical functions. Kryściński, McCann, Xiong, & Socher (2020) proposed Weakly-Supervised, Model-Based Approach for evaluating Factual Consistency.
Controllable text generation
Is there only one best summary about a given document? It won't. People with different inclinations can prefer different summary texts for the same text. Even if you are the same person, the summary you want will depend on the purpose of summarizing or the situation. This method of adjusting the output to the desired form according to the conditions specified by the user is called Controllable Text Generation . You can provide personalized summary compared to generic summarization that creates the same summary for a given document.
The summary that is generated should not only be easy to understand and value, but also be closely related to the Condition you put together.
f(text, condition ) = comprehensible information that meets the given conditions
What condition can I add to the summary model? And how can you create a summary that suits that condition?
Aspect-Based Summarization
When summarizing AirPod user reviews, you may want to summarize each side by dividing the sound quality, battery, and design. Or you may want to adjust the writing style or sentiment in the article. In this original text , the work that summarizes only information related to specific aspects or features is called aspect-based summarization .
Previously, only models that worked only in pre-defined aspect, which were mainly used for model learning, were now attempted to allow for reasoning of Arbitrary Aspect, which was not given to learning such as TAN, Qin, Xing, & Hu (2020).
Query Focused Summarization (QFS)
If the condition is query , it is called QFS. Query is mainly natural language, so the main task is how to do these various expressions well and match them with the original text. It is quite similar to the QA system we know well.
Update Summarization
Humans are animals that continue to learn and grow. Therefore, today's value for certain information can be completely different from the value of a week later. The value of the contents in the document I have already experienced will be lowered, and the new contents that have not been experienced yet will still have high value. From this point of view, it is called update Summarization to create a new summary of a new content that is similar to the document contents that the user experienced previously .
Ctrlsum takes various Keywords or Descriptive Prompts with the text to adjust the summary that is generated. It is a more general -purpose Controllable text summarization model in that it shows the same results as being controlled for keywords or prompts that are not explicitly learned in the Training stage. You can easily use it through Koh Hyun -woong's Summarizers library.
In addition to this, a variety of attempts to create a summary model that is suitable for conversation summarization rather than a typical DL topic such as ** model lightweight, as well as a summary of dialogue rather than a structured text such as news or Wikipedia. There are topics.
If you know the following in the text summary field, you will be able to study more easily.
Understanding NLP Basic Concept
Transformer/Bert structure and pre-training objective understanding
Many of the latest NLP papers are based on several prerealing models, including BERT, based on Transformer, and Roberta and T5, which are variants of this BERT. Therefore, if you understand their schematic structure and Pre-Training Objective, it is a great help in reading or implementing a paper.
Text Summarization Basic Concept
Graph Neural Network (GNN)
Machine Translation (MT)
MT is one of the most active TASKs in the NLP field since the emergence of SEQ2SEQ. If you look at the Summarization process as a process of converting one text into a different type of text, it can be seen as a kind of MT, so much of MT -related studies and ideas are likely to be borrowed or applied in the Summarization field.
| Year | Paper | Keywords |
|---|---|---|
| 2004 Model | TextRank : Bringing Order INTO TEXTS R. MIHALCEA, P. Tarau It is a classic in the sector of extraction and is still active. In the assumption that the important sentence within the document (ie, included in the summary) is a pagerank algorithm, the initial idea of the Google Search Engine, assuming that it will have high Simility with other sentences. Each sentence configures the Sentence-Level Weighted Graph to calculate the SIMILARITY with another sentence in the document, and includes this high Weight Sentence in the Summary. Statistical -based Unsupervised Learning methods can be reasonable without separate learning data, and the algorithm is clear and easy to understand. - [Library] gensim.summarization (only 3.x version is available. Delete from version 4.x), pytextrank - [Theory/Code] Lovit. Keyword extraction using texttrank and core sentence extract | Ext, Graph-based (Pagerank), Unsupervised |
| 2019 Model | BERTSUM : Text Summarization with Pretated Encoders (OfficeIAD) Yang Liu, Mirella Lapata / EMNLP 2019 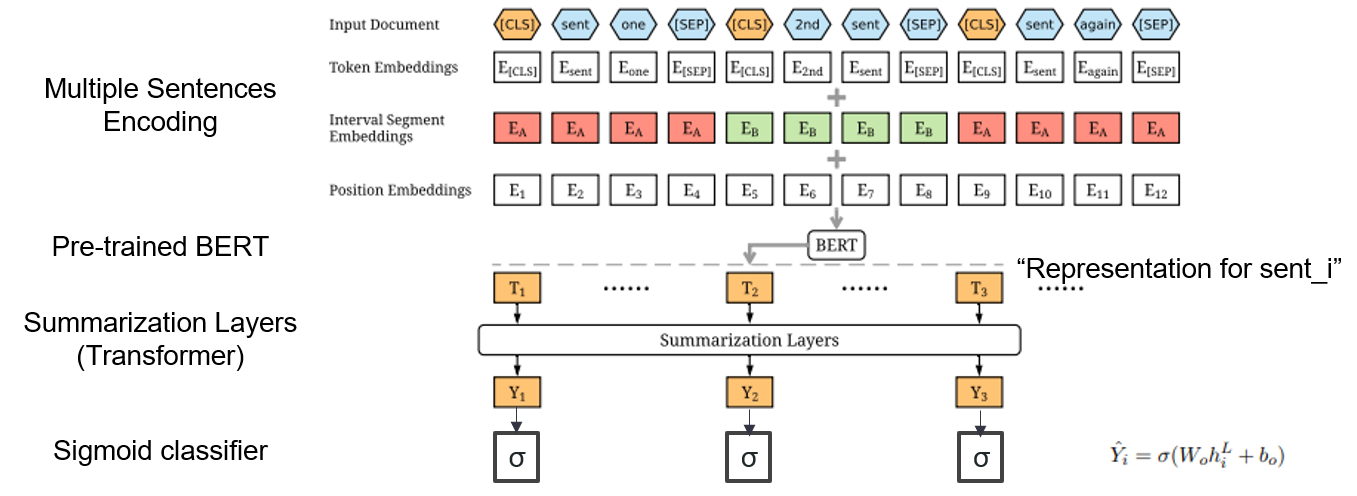 How can I use Pre-Trained Bert in summary? How can I use Pre-Trained Bert in summary?Bertsum suggests modified input embeddings that inserts [CLS] tokens in front of each sentence and adds interval segment embeddings to add multiple sentence into one input. The EXT model uses an encoder structure with a transformer layers on the BERT, and the ABS model uses an Encoder-Decoder model with a 6-layer transformer decoder on the EXT model. - [Review] Lee Jung -hoon (koreauniv dsba) - [Korean] Kobertsum | Ext/Abs, BERT+Transformer, 2-STAGED FINE-TUNING |
| 2019 Pretraining Model | BART : Denoising sequence-to-sequence pre-training for Natural Language Generation, Translation, and Comprehension Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer / ACL 2020 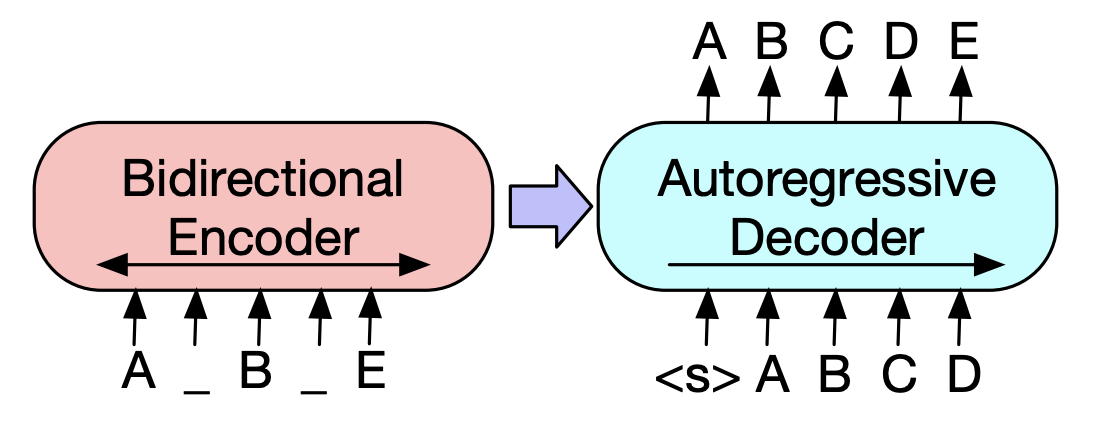 BERT is a bidirectrical encoder, weak to Generation tasks, and GPT has a disadvantage that it does not get bidirected information with an auto-regression model. BERT is a bidirectrical encoder, weak to Generation tasks, and GPT has a disadvantage that it does not get bidirected information with an auto-regression model.The BART has a SEQ2SEQ form that combines them, so you can experiment with various Denosing techniques in one model. As a result, the text infilling (changes the text span to one mask token) and the sentence shuffling (randomly mixing the sentence) shows the performance that surpasses the Ki SOTA model in the field of Summarization. - [Korean] SKT T3K. Kobart - [REVIEW] Jin Myung -hoon_Video, Lim Yeon -soo_ Written by JIWUNG Hyun_ | ABS, SEQ2SEQ, Denoising Autoencoder, Text infilling |
| 2020 Model | MatchSum : Extraction Summarization As Text Matching (Office) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, XIPENG QIU, Xuanjing Huang / ACL 2020 - [REVIEW] Yoo Kyung (KOREAUNIV DSBA) | Ext |
| 2020 Technique | SUMMARIZING TEXT on Any Aspects: A Knowledge-Informed Weakly-Supervised Approach (Official Code) Bowen Tan, Lianhui Qin, Eric P. Xing, Zhiting Hu / Emnlp 2020 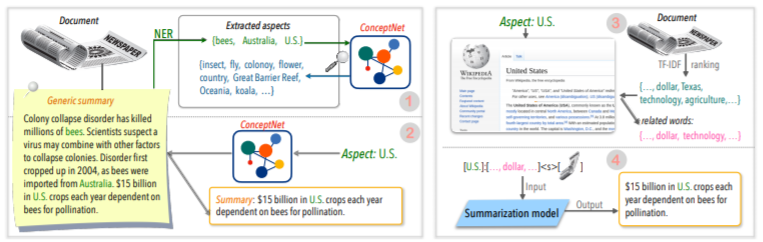 Aspect-based Summarization is a task that is not easy in that it runs only in the pre-defined aspects of DATA, which is learned even if you learn the model, and 2) Lack of Multiple Aspect-Based Summaries Data. This paper utilizes external knowledge sources to solve this problem. -It goes through two steps to convert generic summary to multiple aspect-based summaries. First of all, to increase the number of Aspect, the entity extracted from Generic Summary is seed and extracted from the Concepnet to its neighbors and consider each of them as an aspect. We use Concepnet again to create psedo summary for each of these aspects. Extract the surrounding entity connected to the corresponding aspect in Concepnet, and extract only the sentences containing them within General Summary. This is considered a Summary for that entity (aspect). -Wikipedia is used to deliver more abundant information related to the given aspect to the model. Specifically, among the words that appear in the document, the TF-IDF score in the document is high and at the same time, and at the same time, the list of 10 words in the Wikipedia page corresponds to that aspect is added to the aspect with the model input. In this way, the pre-tuning prerealing model (BART) was also excellent for Arbitrary Aspect with a small data. | Aspect-Based, KNOWLEGE-RICH |
| 2020 Review | What has we soon text Summarization? Dandan Huang, LEYANG CUI, SEN YANG, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang / EMNP 2020 In addition to Rouge Score, 10 representative summary models are evaluated according to 8 metrics (polytope) related to Accuracy and Fluency. To summarize the results, -The traditional rule-based method is still valid as Baseline. Under similar settings, the EXT model generally show better performance in FAITHFULNNESS and Factual-Consistency. The Main Shortcoming is unexessity for extractive models, and omission and intrinsic hallucination for abstractive models. -The more complex structures such as transformers for creating the Sentence Representation are not very helpful except the Duplication problem. -Copy ( POINTER-GENERATOR ) is a reproducing detail, which effectively solves the Word Level Duplication problem by mixing it as well as inaccuracy intrinsic. But tends to cause redundancy to a certain degree. Coverage is by a Large Margin, which reduces the repetition errors (duplication), but at the same time increases the Addition and Inaccuracy Intrinsic Error -Hybrid model , which is ABS after EXT, is good for recalls, but there may be problems with inaccuracy error because it generates summary through some of the original text (extracted snippets). Pre-training, especially the Encoder-Decoder model (BART) than the Encoder Only model (BERTSUMEXTABS) is very effective in the summary. This suggests that preraining all understanding and creation of input is very useful for content selection and combination. At the same time, while most ABS models focus on the front sentence, BART is looking at all the original text, which seems to be the effect of Sentence Shuffling during prerealing. 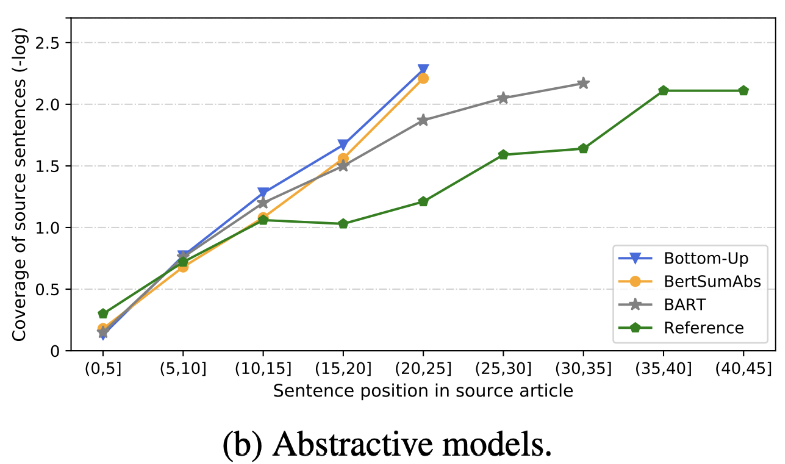 - [Review] Kim Han -gil, Heo Hoon | Review |
| 2020 Model | Ctrlsum : TOWARDS Generic Controllable Text Summarization (Official Code) Junxian He, Wojciech Kryściński, Bryan Mccann, Nazneen Rajani, Caiming XIONG Ctrlsum is a Controllable Text Summarization model that allows you to adjust the summary statements generated through keywords or descriptive prompts. Training: In order to create a keyword-based controllable Summary dataset by modifying general Summary data, select sub-sequences, which is the most similar to the summary, and extract the keyword there. Put this in an input with the document and finish the pre-tuning Bart. 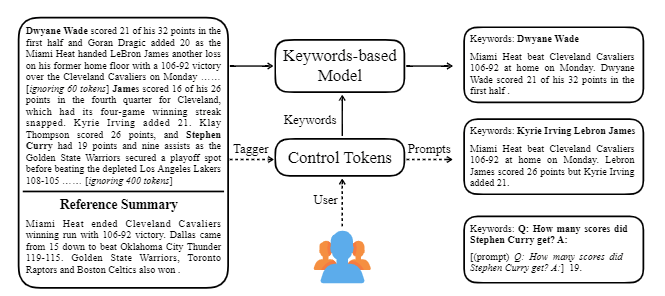 -Inperence: As shown in the image below, you can add a summary of the summary, such as creating a summary of a particular entity, adjusting the summary length, or creating a response to a question. It is noteworthy that it works as if it were not explicitly learning such Prompts in the modeling stage, but it worked as if it were to understand Prompt and generate a summary. Similar to GPT-3. 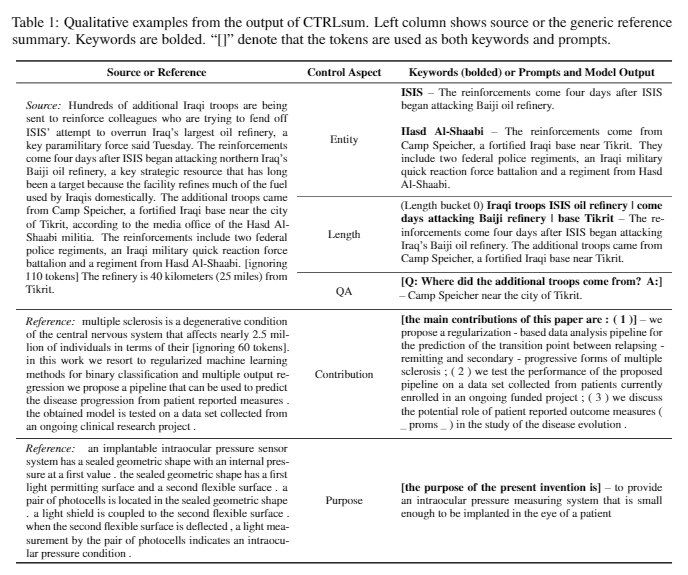 - [Library] Package for Controllable Summarization Based Ctrlsum | Controllable, Bart |
PAPER DIGEST: Recent Papers on text Summarization
PAPERS with Code: Latest Papers
Emnlp 2020 PAPERS-SUMMARIZATION
In fact, we have summarized the code, data, and preitrain models needed to create and practice summary models. It is mainly Korean data, and for English -related materials, please refer to the Code part of each paper in the PAPERS item.
The meaning of the weak used below is as follows.
w : Average value of The Number of Words; s : Average value of the Average Number of Sentences
Example) 13s/214w → 1s/26w means that it provides a summary text consisting of an average of 13 sentences (average 214 words) and an average of one sentence (26 words average).
abs Summary; ext : EXTRACTIVE SUMMARY
| Dataset | Domain / Length | Volume (Pair) | License |
|---|---|---|---|
| Everyone's words-Document summary Title of short news text, 3 sentence ABS and Ext Summay All of the words of everyone with ID-Combined with the newspaper horses, you can get additional information related to the subtitles, media, date, and topic. | news -Origin → 3S (abs); 3S (EXT) | 13,167 | National Institute of Korean Language (Individual contract) |
| AiHub-Document Summary Text ABS and EXT Summay for newspaper articles, contributions, magazine articles, and court reviews - [EDA] Data EDA notebook -Ongunated Korean Document Extraction Summary Summary and Creation Summary AI Contest (~ 20.12.09) | -The newspaper article 300,000, 60,000 contributions, 10,000 magazine articles, court ruling 30,000 13S/214W → 1S/26W (ABS); 3S/55W (EXT) | 400,000 | AiHub (Individual contract) |
| AiHub-Summary ABS SUMMARY by all and section for academic papers and patent specifications | -A academic papers, patent specifications -Origin → ABS | 350,000 | AiHub (Individual contract) |
| AIHUB-Book Data Summary ABS Summary for the original Korean book on various topics | -Lifetime, life, tax, environment, community development, trade, economy, labor, etc. -300-1000 characters → ABS | 200,000 | AiHub (Individual contract) |
| sae4k | 50,000 | CC-BY-SA-4.0 | |
| SCI-NEWS-SUM-KR-50 | News (IT/Science) | 50 | Mit |
| Wikilingua : a multilingual Abstractive Summarization Dataset (2020) Based on the manual site Wikihow, 18 languages such as Korean and English -Paper, Collab Notebook | -HOW-to DOCS -391W → 39W | 12,189 (KOR in total 770,087) | 2020, CC by-NC-SA 3.0 |
| Dataset | Domain / Length | Volume | License |
|---|---|---|---|
| Scisummnet (PAPER) Provides three types of Summary for ACL (NLP) Research -CL-SCISUMM 2019-TASK2 (Repo, Paper) -CL-Scisumm @ emnlp 2020-TASK2 (Repo) | -Research Paper (Computational Linguists, NLP) 4,417W → 110W (paper Abstract); 2S (Citation); 151W (ABS) | 1,000 (ABS/ EXT) | CC by-SA 4.0 |
| Longsumm NLP 및 ML 분야 Research paper에 대한 상대적으로 장문의 summary(관련 blog posts 기반 abs, 관련 conferences videos talks 기반 ext) 제공 - LongSumm 2020@EMNLP 2020 - LongSumm 2021@ NAACL 2021 | - Research paper(NLP, ML) - origin → 100s/1,500w(abs); 30s/ 990w(ext) | 700(abs) + 1,705(ext) | Attribution-NonCommercial-ShareAlike 4.0 |
| CL-LaySumm NLP 및 ML 분야 Research paper에 대해 비전문가를 위한 쉬운(lay) summary 제공 - CL-LaySumm @ EMNLP 2020 | - Research paper(epilepsy, archeology, materials engineering) - origin → 70~100w | 600(abs) | 개별약정 필요([email protected] 로 이메일을 송부) |
| Global Voices : Crossing Borders in Automatic News Summarization (2019) - Paper | - news - 359w→ 51w | ||
| MLSUM : The Multilingual Summarization Corpus CNN/Daily Mail dataset과 유사하게 news articles 내 highlights/description을 summary로 간주하여 English, French, German, Spanish, Russian,Turkish에 대한 summary dataset을 구축 - Paper, 이용(huggingface) | - news - 790w→ 56w (en 기준) | 1.5M(abs) | non-commercial research purposes only |
| Model | Pre-training | Usage | License |
|---|---|---|---|
| BERT(multilingual) BERT-Base(110M parameters) | - Wikipedia(multilingual) - WordPiece. - 110k shared vocabs | - BERT-Base, Multilingual Cased 버전 권장( --do_lower_case=false 옵션 넣어주기)- Tensorflow | Google (Apache 2.0) |
| KOBERT BERT-Base(92M parameters) | - 위키백과(문장 5M개), 뉴스(문장 20M개) - SentencePiece - 8,002 vocabs(unused token 없음) | - PyTorch - KoBERT-Transformers(monologg)를 통해 Huggingface Transformers 라이브러리로 이용 가능, DistilKoBERT 이용 가능 | SKTBrain (Apache-2.0) |
| KorBERT BERT-Base | - 뉴스(10년 치), 위키백과 등 23GB - ETRI 형태소분석 API / WordPiece(두 버전을 별도로 제공) - 30,349 vocabs - Latin alphabets: Cased - [소개] 임준(ETRI). NLU Tech Talk with KorBERT | - PyTorch, Tensorflow | ETRI (개별 약정) |
| KcBERT BERT-Base/Large | - 네이버 뉴스 댓글(12.5GB, 8.9천만개 문장) (19.01.01 ~ 20.06.15 기사 중 댓글 많은 기사 내 댓글과 대댓글) - tokenizers의 BertWordPieceTokenizer - 30,000 vocabs | Beomi (MIT) | |
| KoBART BART(124M) | - 위키백과(5M), 기타(뉴스, 책, 모두의 말뭉치 (대화, 뉴스, ...), 청와대 국민청원 등 0.27B) - tokenizers의 Character BPE tokenizer - 30,000 vocabs( 포함) - [Example] seujung. KoBART-summarization(Code, Demo) | - 요약 task에 특화 - Huggingface Transformers 라이브러리 지원 - PyTorch | SKT T3K (modified MIT) |
| Year | Paper |
|---|---|
| 2018 | A Survey on Neural Network-Based Summarization Methods Y. Dong |
| 2020 | Review of Automatic Text Summarization Techniques & Methods Widyassari, AP, Rustad, S., Shidik, GF, Noersasongko, E., Syukur, A., & Affandy, A. |
| 2020 | A Survey of Knowledge-Enhanced Text Generation Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, Meng Jiang |
| Year | Paper | Keywords |
|---|---|---|
| 1958 | Automatic creation of literature abstracts PH Luhn | gen-ext |
| 2000 | Headline Generation Based on Statistical Translation M. Banko, VO Mittal, and MJ Witbrock | gen-abs |
| 2004 | LexRank : graph-based lexical centrality as salience in text summarization G. Erkan, and DR Radev, | gen-ext |
| 2005 | Sentence Extraction Based Single Document Summarization J. Jagadeesh, P. Pingali, and V. Varma | gen-ext |
| 2010 | Title generation with quasi-synchronous grammar K. Woodsend, Y. Feng, and M. Lapata, | gen-ext |
| 2011 | Text summarization using Latent Semantic Analysis MG Ozsoy, FN Alpaslan, and I. Cicekli | gen-ext |
| Year | Paper | Keywords |
|---|---|---|
| 2014 | On using very large target vocabulary for neural machine translation S. Jean, K. Cho, R. Memisevic, and Yoshua Bengio | gen-abs |
| 2015 Model | NAMAS : A Neural Attention Model for Abstractive Sentence Summarization (Code) AM Rush, S. Chopra, and J. Weston / EMNLP 2015 기존의 문장 선택 및 조합 방식을 넘어서기 위해 기 Seq2Seq에 target-to-source attention을 도입하여 abstractive summary를 생성합니다. | abs Seq2Seq with att |
| 2015 | Toward Abstractive Summarization Using Semantic Representations Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 Model | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 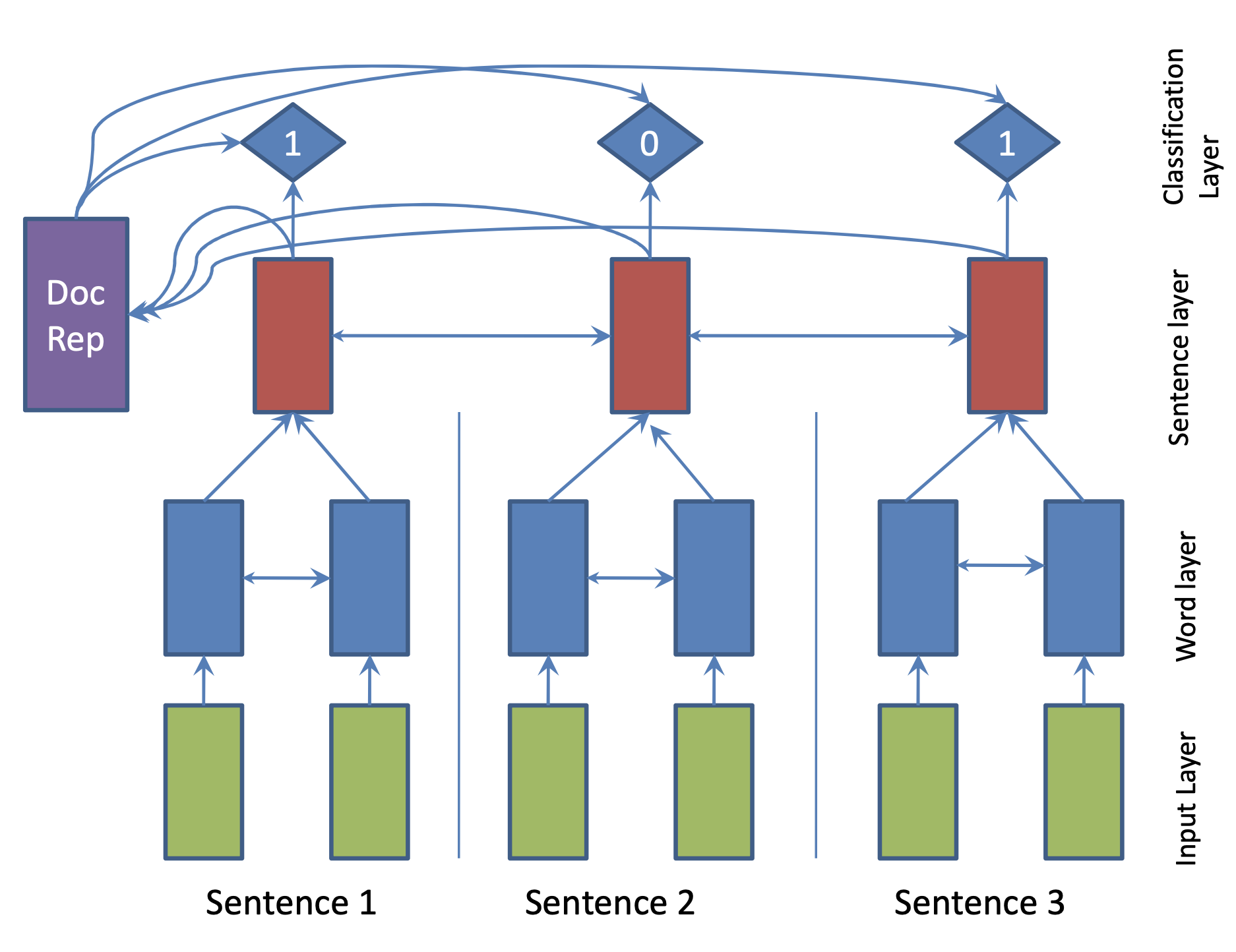 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 Model, Technique | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 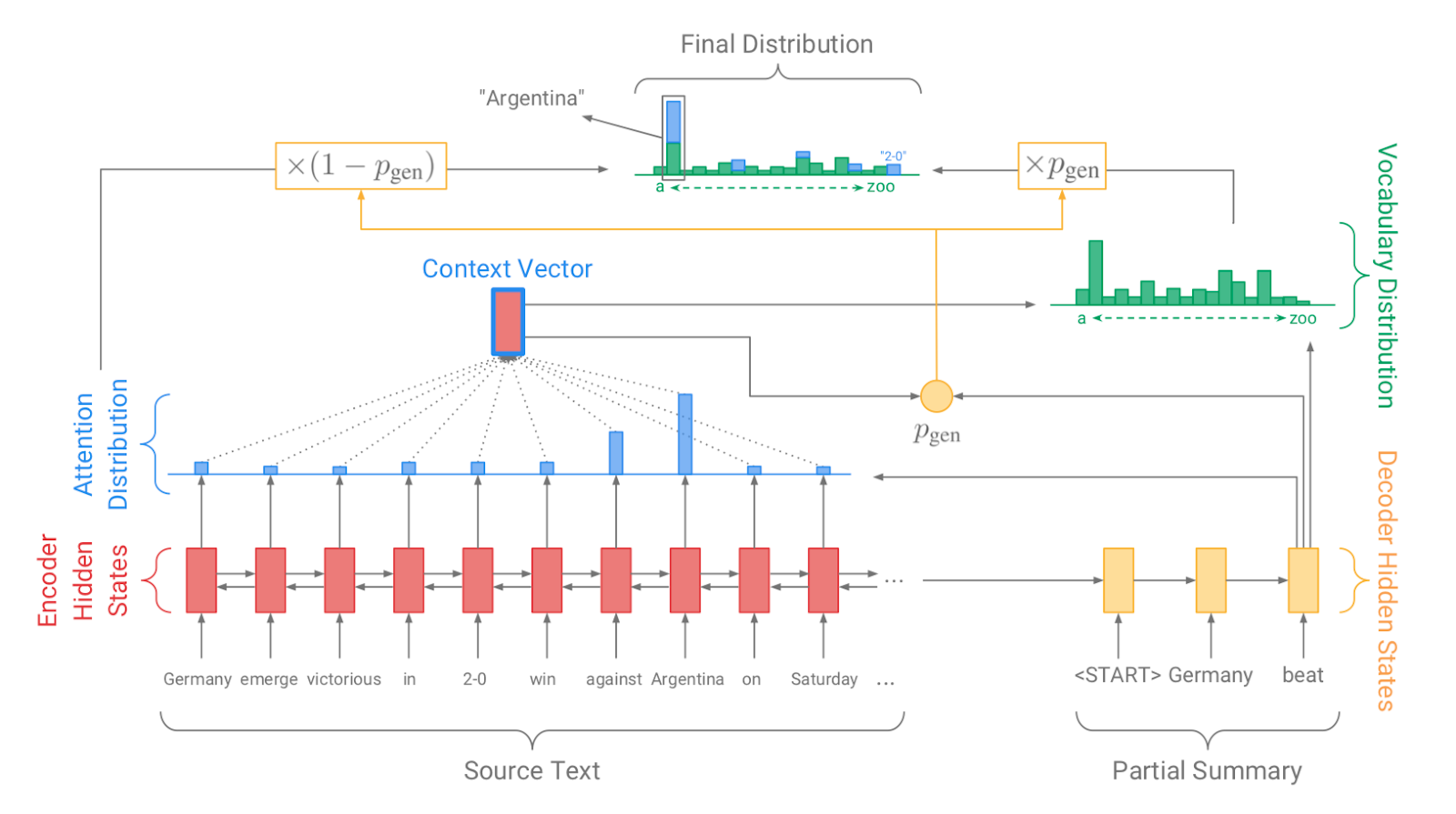 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 Model | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 Model | Bottom-Up Abstractive Summarization Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, hybrid, bottom-up attention |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 Model | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 Model | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 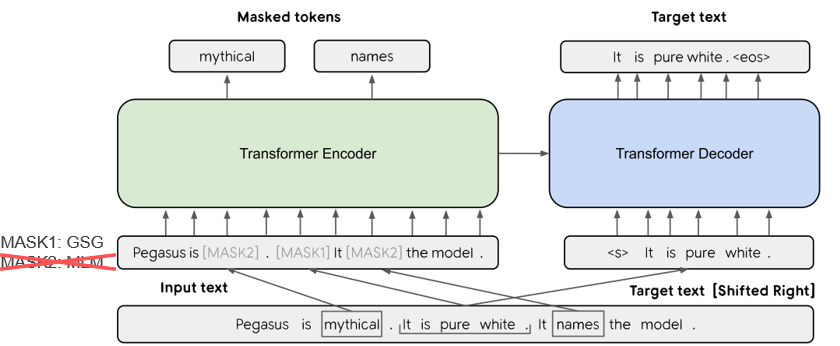 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 Model | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


