Text Summarization Repo
1.0.0
Среди NLP это пространство, которое накапливает качественные данные, связанные с полем текста. Я хотел бы быть хорошим руководством для тех, кто интересуется резюме текста.
Прежде всего, мы понимаем, какие подробные темы обобщают текст, составлены и рассмотрим основные документы, которые возглавляли это поле. С тех пор мы перечислили код, наборы данных и предварительные модели, необходимые для создания модели прямого текста.
Вступление в текстовое обобщение
Документы
Ресурсы
Другие
Berry, Dumais, & O'Brien (1995) определяет текстовое резюме следующим образом:
Текстовое суммирование - это процесс перевозчика наиболее важной информации из текста для получения определенной задачи и пользователя
Это процесс уточнения только важной информации среди текста, приведенного одним словом. Здесь выражение уточнения и важность важного - довольно абстрактное и субъективное выражение, поэтому я лично хочу определить его следующим образом.
f(text) = comprehensible information
Другими словами, текстовое резюме состоит в том, чтобы преобразовать исходный текст в простую и ценную информацию . Людям трудно увидеть с помощью текстовой информации, которая длинная или разделена на несколько документов. Иногда вы не знаете много профессиональных терминов. Это довольно полезно отражать эти тексты в простую и легкую -понять, в то же время хорошо отражая исходный текст. Конечно, то, что действительно стоит и как это изменить, будет варьироваться в зависимости от цели суммирования или личных вкусов.
С этой точки зрения можно сказать, что текст суммирует не только задачи, которые создают тексты, такие как протокол, заголовок инженера газеты, бумажный реферат и резюме, а также задачи, которые преобразуют текст в графики или изображения. Конечно, поскольку это не просто суммирование, это текстовое обобщение , поэтому источник резюме ограничен в форме текста. (Краткое изложение этого резюме заключается в том, что это может быть не только текст или видео, а также текст. Пример, первым примером является подписание изображения, последним примером является то, что видео -суммирование. Принимая во внимание недавнюю тенденцию глубокого обучения, когда граница между видением и NLP становится размытым, может быть смысл поставить текст в качестве предварительного нагрузки).
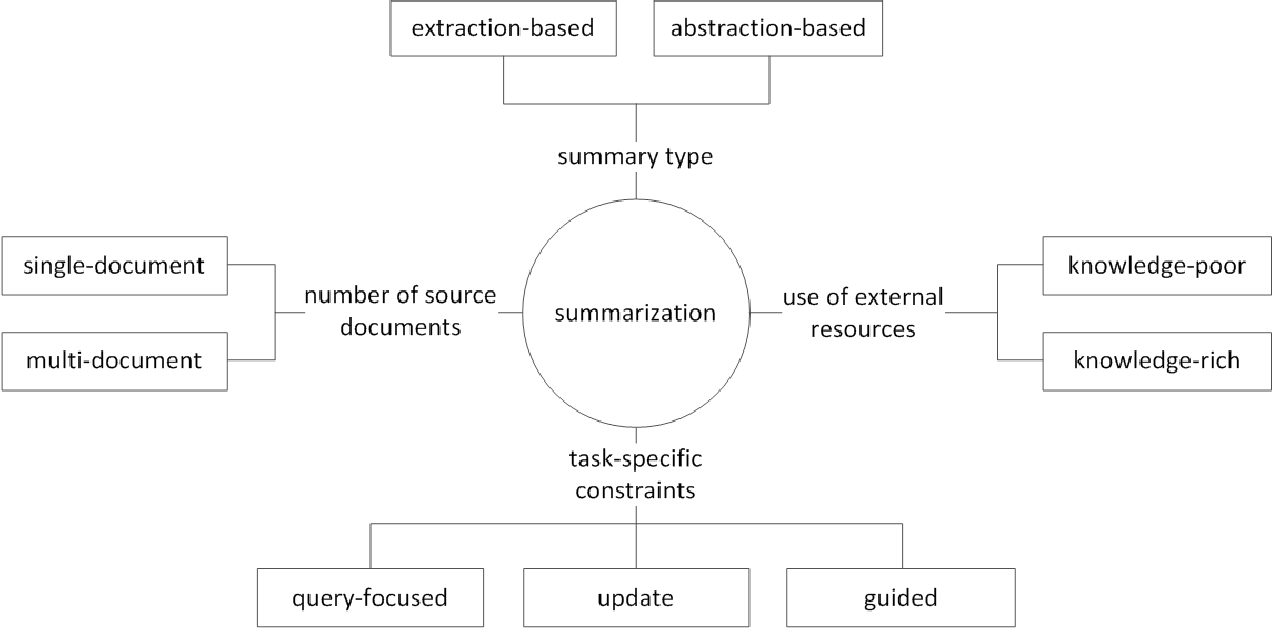
В целом, задача резюме текста делится на извлечение суммирования (далее, называемое как ext) и абстрактное суммирование (ABS), в зависимости от того, как они генерируют резюме. (Gudivada, 2018)
Извлечение методов выберите подмножество существующих слов, фраз или предложений в исходном тексте, чтобы сформировать резюме. Напротив, абстрактные методы сначала создают внутреннее семантическое представление и технологию использования естественного языка.
EXT обычно оценивает важность предложения, а затем выбирает и объединяет его для создания резюме. Это похоже на задачу рисования маркера во время чтения. ABS , с другой стороны , основан на исходном тексте, но является методом NLG (генерация естественного языка), который генерирует новый текст . EXT вряд ли будет включать выражения, которые ограничены выражениями из -за текста в исходном тексте. ABS, с другой стороны, имеет преимущество в том, что существует возможность создать беспрецедентное выражение, потому что он должен создать новый текст в модели, но у него более гибкие подходы.
Кроме того, в соответствии с номером исходных текстов, в соответствии с текстовой формой суммирования однократного/многочисленного документа , в соответствии с суммированием ключевого слова/предложения , в соответствии с тем, сколько внешней информации используется в кратком процессе , согласно сводному процессу существуют различные различия, такие как суммирование.
(G. Sizov (2010). Автоматическое обобщение на основе экстракции: теоретическое и эмпирическое исследование методов суммирования
Давайте посмотрим на основные темы исследования в области суммирования текста и подумаем о том, какие проблемы в этой области.
Суммизация многочисленных / длинных документов
Как упоминалось ранее, сводная задача состоит в том, чтобы изменить непостижимый текст на понятную информацию. Следовательно, чем дольше исходный текст или краткое изложение документов нескольких источников, а не одного документа, тем больше утилита резюме увеличивается. Проблема в том, что в то же время сложность резюме также увеличивается.
По этой причине, чем дольше исходный текст, тем быстрее увеличивается вычислительная сложность. Это гораздо более важная проблема в недавних методах, основанных на нейронных сети, включая трансформатор, чем в статистических методах, таких как Textrank в прошлом. Во -вторых, чем дольше исходный текст, тем больше не ядро содержимого, то есть шума. Нелегко определить, что такое шум, а что информативно. Наконец, длинные тексты и различные источники имеют различные перспективы и содержание одновременно, что затрудняет создание резюме, которое охватывает его хорошо.
Много документов суммирование (MDS)
MDS - это краткое изложение множества документов . На первый взгляд, будет трудно обобщить статьи различных перспектив различных авторов, чем суммировать документ, который описывает одну тему с последовательной тенденции и точки зрения. Конечно, даже в случае с MDS он обычно основан на одном и том же кластере документах, который касается аналогичных тем, но нелегко определить важную информацию и информацию о том, что среди многих документов нелегко.
Задача, которая суммирует отзывы о определенных продуктах, является примером MDS, о котором легче всего думать. Эта задача, обычно называемая суммированием мнений, характеризуется короткой длиной текста и субъективностью. Работа по созданию вики -документа также может рассматриваться как MDS. Лю и соавт. (2018) - это исходный текст текста веб -сайта в вики -документе, который является исходным текстом, который считается кратким изложением, и создает модель создания вики.
Длительные документы суммирование
Лю и соавт. (2018) - это статистический способ принять длинный текст в качестве ввода, создавая экстраальную резюме, используя только важные предложения и используя его в качестве ввода модели. Кроме того, чтобы уменьшить объем вычислений трансформатора, вход делится на блочные единицы, и в настоящее время 1-D свертка использует метод аттенсии, который уменьшает количество индивидуального ключа внимания и значения. Бумага Big Bird (2020) вводит редкий механизм гостей (линейный) вместо комбинации всех существующих слов для уменьшения расчета трансформатора. В результате то же самое оборудование для производительности было обобщено до восьми раз дольше.
Gidiotis & Tsoumakas (2020), с другой стороны, пытается приблизиться к разделению и контроле, что не решает задачу сразу же кратковременного текста и превращает ее в несколько небольших текстовых резюме. Обучите модель, изменяя исходный текст и сводку цели на несколько небольших небольших пар исходной цели. При выводе мы собираем частичные резюме, выводящие через эту модель, чтобы создать полное резюме.
Улучшение производительности
Как вы можете создать лучшую резюме?
Передача обучения
Недавно использование модели предварительной подготовки в НЛП стало почти дефолтом. Итак, какую структуру мы должны создать предварительную модель, которая может показать лучшую производительность в суммировании текста? Какой объект у меня должен быть?
В Pegasus (2020) метод GSG (генерация предложений GAP), который выбирает предложение, которое считается важным на основе оценки Rouge, предполагает, что тем более похожи на процесс сводного текста, а возражение будет показывать более высокую производительность. Текущая модель SOTA, BART (2020) (двунаправленные и авторегрессионные трансформаторы), учится в виде автоэкодора, который добавляет шум к некоторому входному тексту и восстанавливает его в качестве исходного текста.
Поколение текста с повышенным знакомым
В задаче текста в тексте часто трудно генерировать желаемый вывод только с исходным текстом. Таким образом, существует попытка повысить производительность, предоставляя различные знания для модели, а также оригинальный текст . Источник или предоставление этих знаний варьируются в различных типах ключевых слов, тем, лингвистических особенностей, баз знаний, графиков знания и заземленного текста.
Например, Tan, Qin, Xing и Hu (2020) обеспечивает общий набор данных для преобразования множества резюме на основе аспектов, и предоставляет более богатую информацию, связанную с данным аспектом для данного аспекта для модели. Используйте Википедию для. Если вы хотите узнать больше, Yu et al. Прочитайте документ опроса, написанный (2020).
После редактирования коррекция
Было бы неплохо создать хорошее резюме одновременно, но это нелегко. Так почему бы вам не создать резюме, а затем просмотреть и изменить его в различных критериях?
Например, Cao, Dong, Wu, & Cheung (2020) предлагает метод уменьшения фактической ошибки путем применения прибедренной модели нейронного корректора к генерируемому сводку.
Кроме того, существует также много попыток применять ** График нейронной сети (GNN) **, которая недавно привлекает много внимания.
Проблема дефицита данных
Сводка текста - это задача, которая занимает много времени, что нелегко для людей. Следовательно, по сравнению с другими задачами, это стоит относительно большие затраты на создание помеченного набора данных, и, конечно, отсутствует данные для обучения.
В дополнение к методу обучения передачи с использованием ранее упомянутой модели предварительного подготовки, мы учимся в неконтролируемых методах обучения или подкрепления обучения или пытаемся выполнять несколько выстрелов .
Естественно, создание хороших сводных данных также является очень важной темой исследования. В частности, многие из текущих наборов данных, связанных с суммированием, предвзяты в типах новостей на английском языке. В результате создаются многоязычные наборы данных, такие как Wikilingua и MLSUM. Для получения дополнительной информации взгляните на MLSUM: многоязычный корпус суммирования .
Метод метрики / оценки
Я написал сокрушительное выражение «хорошего» раньше. Что такое «хорошее резюме»? Бразинскас, Лапата и Титов (2020) используют следующие пять вещей, основанных на суждении хорошего резюме.
Проблема в том, что измерить эти части нелегко. Наиболее распространенным показателем измерения производительности в текстовых резюме является балл Rouge. Есть различные варианты в балле Rouge, но в основном «как слово слова сгенерированного сводного и справочного резюме?» Это означает, что схоже, но если у вас другая форма или если изменится заказ слова, вы можете получить более низкий результат, даже если это лучшая резюме. В частности, пытаясь поднять оценку Rouge, это может привести к нанесению нанесения нанесения нанесения выражения разнообразия резюме. Вот почему многие документы дают дополнительные результаты оценки человека с дорогими деньгами, а также баллом Rouge.
Lee et al. (2020) представляет RDASS (Семантическая оценка по пониманию и осведомленности о документах), что похоже на то, насколько он похож на текстовое и справочное резюме, а затем измеряется аналогичными дорогами на основе вектора. Ожидается, что этот метод повысит точность оценки корейского языка, которая объединяет слова и различные морфологии для выражения различных значений и грамматических функций. Kryściński, McCann, Xiong, & Socher (2020) предложили слабо насыщенный, модельный подход для оценки фактической согласованности.
Управляемое генерацию текста
Есть ли только одна лучшая краткая информация о данном документе? Это не так. Люди с разными склонностями могут предпочесть разные сводные тексты для одного и того же текста. Даже если вы один и тот же человек, резюме, которое вы хотите, будет зависеть от цели суммирования или ситуации. Этот метод регулировки вывода в нужную форму в соответствии с условиями, указанными пользователем, называется управляемым генерацией текста . Вы можете предоставить персонализированную сумму по сравнению с общим суммированием , которое создает ту же сумму для данного документа.
Сводное изложение, которое генерируется не только легко для понимания и ценности, но и быть тесно связанным с состоянием, которое вы собрали вместе.
f(text, condition ) = comprehensible information that meets the given conditions
Какое условие я могу добавить к сводной модели? И как вы можете создать резюме, которая подходит для этого условия?
Суммизация на основе аспектов
При суммировании отзывов пользователей AirPod вы можете подвести итог каждой стороне, деляя качество звука, батарею и дизайн. Или вы можете настроить стиль письма или настроения в статье. В этом исходном тексте работа, которая суммирует только информацию, связанную с конкретными аспектами или функциями, называется обобщением на основе аспектов .
Ранее только модели, которые работали только в предварительно определенном аспекте, которые в основном использовались для обучения моделям, теперь пытались разрешить рассуждение произвольного аспекта, который не был дан для обучения, такого как Tan, Qin, Xing и Hu (2020).
Суммизация сфокусированной на запроса (QFS)
Если условие является запросом , оно называется QFS. Запрос - это в основном естественный язык, поэтому основной задачей является то, как хорошо выполнять эти различные выражения и сопоставить их с исходным текстом. Это очень похоже на систему QA, которую мы хорошо знаем.
Обновление суммирования
Люди - это животные, которые продолжают учиться и расти. Поэтому сегодняшнее значение для определенной информации может полностью отличаться от стоимости недели спустя. Значение содержания в документе, которое я уже испытал, будет снижена, а новое содержимое, которое еще не было опытным, все равно будет иметь высокую ценность. С этой точки зрения, это называется обобщением обновлений для создания новой резюме нового контента, аналогичного содержанию документа, которое пользователь испытывал ранее .
CtrlSum принимает различные ключевые слова или описательные подсказки с текстом, чтобы настроить сгенерированное резюме. Это более общая модель контролируемого текста, в которой она показывает те же результаты, что и контролируемые по ключевым словам или подсказкам, которые явно не изучаются на этапе обучения. Вы можете легко использовать его через библиотеку Summarizers Koh Hyun.
В дополнение к этому, различные попытки создать сводную модель, подходящую для суммирования разговоров, а не типичную тему DL, такую как ** модель легкого веса, а также краткое изложение диалога, а не структурированный текст, такой как News или Wikipedia. Есть темы.
Если вы знаете следующее в поле «Сводка текста», вы сможете легче учиться.
Понимание базовой концепции NLP
Структура трансформатора/берта и объективное понимание предварительного обучения
Многие из последних документов НЛП основаны на нескольких предварительных моделях, включая Берт, основанные на трансформаторе, и Роберте и T5, которые являются вариантами этого Берта. Поэтому, если вы понимаете их схематическую структуру и предварительную задачу, это большая помощь в чтении или внедрении статьи.
Текстовое обобщение базовая концепция
Графическая нейронная сеть (GNN)
Машинный перевод (МТ)
MT является одной из наиболее активных задач в поле NLP с момента появления SEQ2SEQ. Если вы посмотрите на процесс суммирования как процесс преобразования одного текста в другой тип текста, его можно рассматривать как своего рода MT, так что большая часть MT -связанных исследований и идей, вероятно, будет заимствовано или применено в поле суммирования.
| Год | Бумага | Ключевые слова |
|---|---|---|
| 2004 Модель | Textrank : принести порядок в тексты R. Mihalcea, P. Tarau Это классика в секторе экстракции и все еще активен. В предположении, что важным предложением в документе (т.е., включенном в резюме) является алгоритм PageRank, первоначальная идея поисковой системы Google, предполагая, что он будет иметь высокую симусть с другими предложениями. Каждое предложение настраивает взвешенный график на уровне предложения для расчета сходства с другим предложением в документе, и включает в себя это высокое весовое предложение в резюме. Статистические методы обучения на основе статистического обучения могут быть разумными без отдельных учебных данных, а алгоритм ясен и прост для понимания. - [Библиотека] Gensim.summarization (доступна только 3.x версия. Удалить из версии 4.x), pytextrank - [Теория/Код] Ловит. Извлечение ключевых слов с использованием текстового и основного извлечения предложений | Док График на основе (PageRank), Без присмотра |
| 2019 Модель | Берцум : текстовое обобщение с предварительными кодерами (Officiad) Ян Лю, Мирелла Лапата / EMNLP 2019 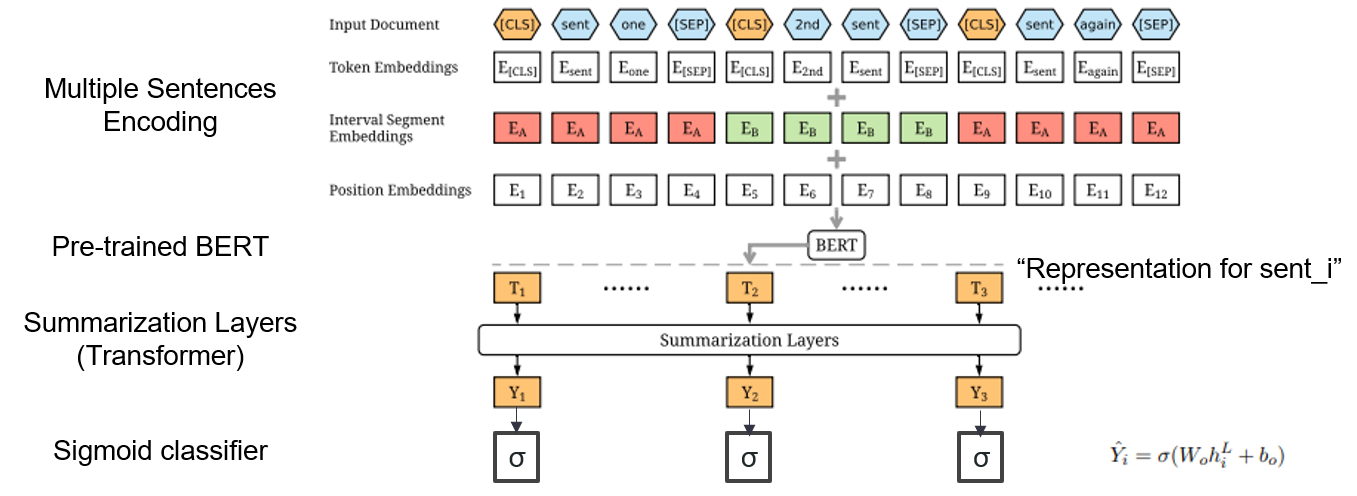 Как я могу использовать предварительно обученный BERT в резюме? Как я могу использовать предварительно обученный BERT в резюме?Берцум предлагает модифицированные входные вторжения, которые вставляют токены [CLS] перед каждым предложением и добавляет интервальные сегменты, чтобы добавить несколько предложений в один вход. Модель EXT использует структуру энкодера со слоями трансформатора на BERT, а модель ABS использует модель кодера-декодера с 6-слойным декодером трансформатора на модели EXT. - [Обзор] Ли Юнг -Хун (Koreauniv DSBA) - [Корейский] Коберцум | Ext/abs, Bert+Transformer, 2-й поставленная точная настройка |
| 2019 Предварительная модель | BART : дженочная последовательность к последовательности предварительной тренировки для генерации, перевода и понимания естественного языка Майк Льюис, Иньхан Лю, Наман Гоял, Марджан Газвининежад, Абдельрахман Мохамед, Омер Леви, Вес Стоянов, Люк Зеттлемуер / ACL 2020 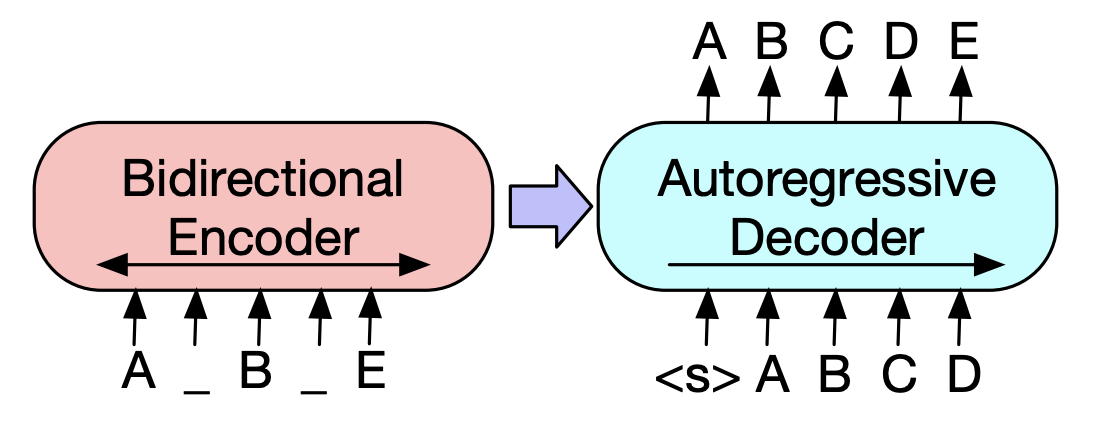 Берт-это бидоиретрический энкодер, слабый для задач генерации, и GPT имеет недостаток в том, что он не получает бидющую информацию с моделью автоматической регрессии. Берт-это бидоиретрический энкодер, слабый для задач генерации, и GPT имеет недостаток в том, что он не получает бидющую информацию с моделью автоматической регрессии.У BART есть форма SEQ2SEQ, которая их объединяет, поэтому вы можете экспериментировать с различными методами смены в одной модели. В результате текст, заполняющий (изменяет текст на один токен маски), а перетасовка предложения (случайное смешивание предложения) показывает производительность, которая превосходит модель Ki Sota в области суммирования. - [Корейский] SKT T3K. Кобарт -[Обзор] Jin Myung -hoon_video, Lim Yeon -Soo_ Записано Jiwung Hyun_ | Пресс, Seq2seq, Обеспечение автоэкодора, Текст заполняется |
| 2020 Модель | МатШум : извлечение суммирования как сопоставление текста (офис) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang / ACL 2020 - [Обзор] Yoo Kyung (Koreauniv DSBA) | Допредный |
| 2020 Техника | Суммирование текста по любым аспектам: ослабленный знание подход (Официальный код) Боуэн Тан, Лианхуи Цинь, Эрик П. Син, Zhiting Hu / Emnlp 2020 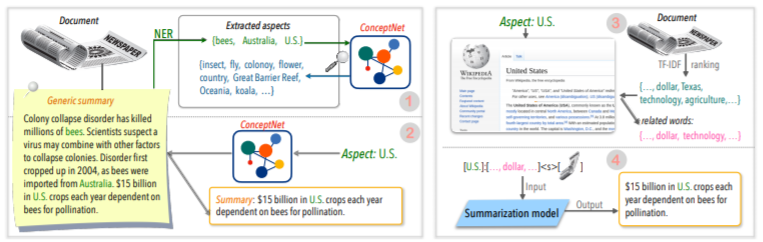 Суммизация на основе аспектов-это задача, которая не является легкой в том смысле, что она работает только в предварительно определенных аспектах данных, которые изучаются, даже если вы изучаете модель, и 2) отсутствие данных на основе аспектов. В этой статье используются внешние источники знаний для решения этой проблемы. -Т. Он выполняет два шага, чтобы преобразовать общее резюме в многочисленные резюме на основе аспектов. Прежде всего, чтобы увеличить количество аспектов, сущность, извлеченная из общего резюме, является семенами и извлечена из концептнета в своих соседей, и рассматривать каждого из них как аспект. Мы снова используем Concepnet для создания краткого изложения PSEDO для каждого из этих аспектов. Извлеките окружающую сущность, связанную с соответствующим аспектом в концептне, и извлеките только предложения, содержащие их в общем резюме. Это считается резюме для этой сущности (аспект). -Википедия используется для предоставления более распространенной информации, связанной с данным аспектом модели. В частности, среди слов, которые появляются в документе, оценка TF-IDF в документе высока и в то же время, и в то же время список из 10 слов на странице Википедии соответствует этому аспекту, добавляется к аспекту с вводом модели. Таким образом, предварительная модель предварительного настройки (BART) также отлично подходила для произвольного аспекта с небольшими данными. | На основе аспектов, Обогащенный Ноулге |
| 2020 Обзор | Что мы скоро отправили текстовые сообщения? Дандан Хуанг, Лейанг Куй, Сен Ян, Гуаншенг Бао, Кун Ван, Джун Си, Юэ Чжан / Эмнп 2020 В дополнение к баллу Rouge 10 репрезентативных сводных моделей оцениваются в соответствии с 8 метриками (политоп), связанным с точностью и беглостью. Суммировать результаты, -Традиционный метод, основанный на правилах, все еще действителен в качестве базовой линии. В аналогичных настройках модель EXT, как правило, показывает лучшую производительность в верных и фактических согласованности. Основным недостатком является неожиданность для добывающих моделей, а также упущения и внутренней галлюцинации для абстрактных моделей. -Более сложные структуры, такие как трансформаторы для создания представления предложения, не очень полезны, за исключением проблемы дублирования. -Copy ( Gointer-Generator )-это воспроизводительная деталь, которая эффективно решает задачу дублирования уровня слова, смешивая, а также неточность. Но имеет тенденцию вызывать избыточность в определенной степени. Покрытие является большим краем, что уменьшает ошибки повторения (дублирование), но в то же время увеличивает внутреннюю ошибку с добавлением и неточности. -Сибридная модель , которая является ABS после EXT, хороша для отзывов, но могут возникнуть проблемы с ошибкой неточности, поскольку она генерирует резюме через некоторые из исходных текстов (извлеченные фрагменты). Предварительное обучение, особенно модель Encoder-Decoder (BART), чем модель только энкодера (Bertsumextabs), очень эффективна в резюме. Это говорит о том, что предварительное понимание всего понимания и создания ввода очень полезно для выбора контента и комбинации. В то же время, в то время как большинство моделей ABS фокусируются на переднем предложении, Барт смотрит на весь исходный текст, который, по -видимому, является эффектом перетасовки предложений во время предварительного обучения. 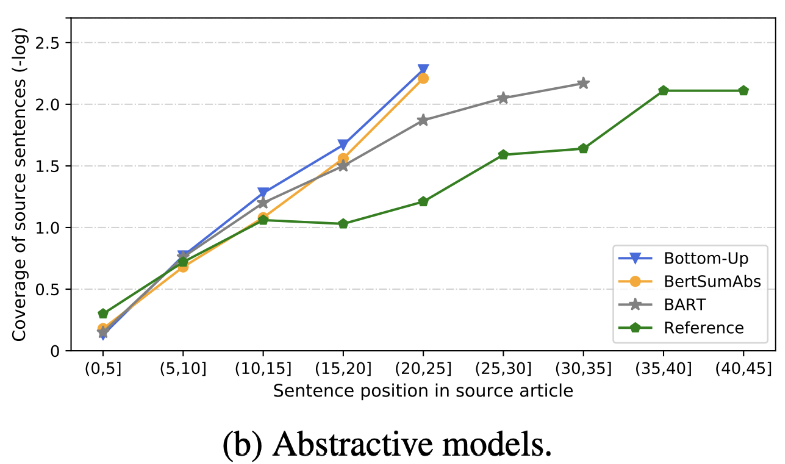 - [Обзор] Ким Хан -Гил, Хео Хун | Обзор |
| 2020 Модель | CtrlSum : к общему контролируемому текстовому суммированию (официальный код) Junxian He, Wojciech Kryściński, Bryan McCann, Nazneen Rajani, Caiming Xiong CtrlSum - это модель контролируемого текстового суммирования, которая позволяет настроить сводные операторы, сгенерированные с помощью ключевых слов или описательных подсказок. Обучение: Для создания управляемого набора данных на основе ключевых слов путем изменения общих сводных данных выберите подпоследовательности, что наиболее похоже на резюме, и извлечь там ключевое слово. Поместите это в ввод с документом и завершите предварительный настройка Bart. 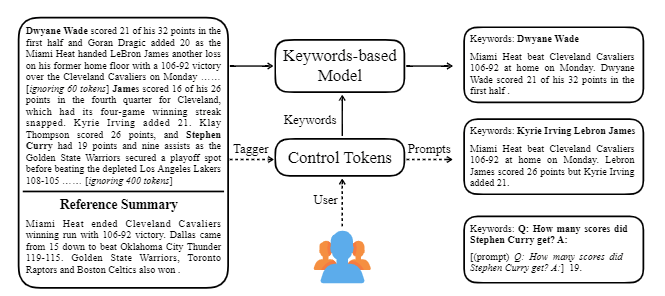 -Продейт: как показано на изображении ниже, вы можете добавить резюме резюме, например, создание резюме конкретной сущности, настройка сводной длины или создание ответа на вопрос. Следует отметить, что он работает так, как будто он не изучал такие подсказки на этапе моделирования, но это работало так, как если бы он понимал, и генерировал резюме. Похоже на GPT-3. 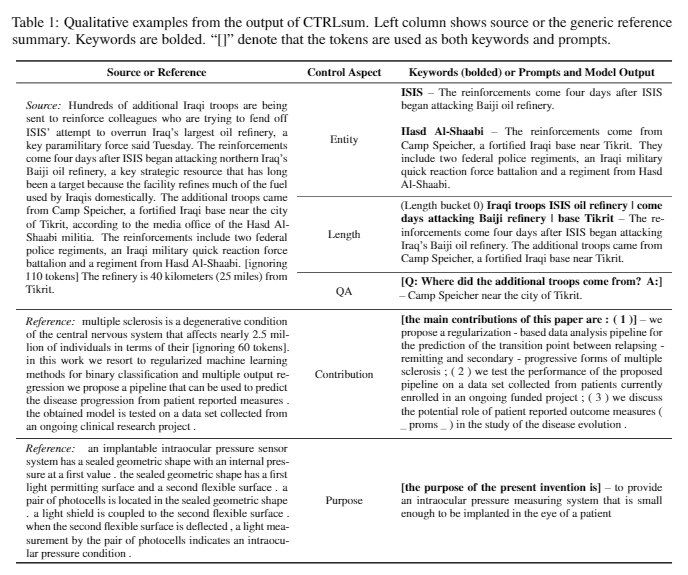 - [Библиотека] Пакет для контролируемого суммирования CtrlSum | Управляемый, Барт |
Paper Digest: недавние документы по версии текста
Документы с кодом: последние документы
EMNLP 2020 Papers-Summarization
Фактически, мы суммировали модели кода, данных и предварительных условий, необходимых для создания и практики сводных моделей. Это в основном корейские данные, а для английских материалов, пожалуйста, обратитесь к коде части каждой статьи в статье.
Значение слабых, используемых ниже, является следующим образом.
w : среднее значение количества слов; s : Среднее значение среднего количества предложений
Пример) 13s/214w → 1s/26w означает, что он предоставляет сводку, состоящий из в среднем 13 предложений (в среднем 214 слов) и в среднем одно предложение (в среднем 26 слов).
Сводка abs ; ext : добываемое резюме
| Набор данных | Домен / длина | Объем (Пара) | Лицензия |
|---|---|---|---|
| Краткое изложение слов все слова Название короткого текста новостей, 3 предложения ABS и EXT Summay Все слова всех, у кого есть идентификатор, с газетными лошадьми, вы можете получить дополнительную информацию, связанную с субтитрами, медиа, датой и темой. | новости -Origin → 3S (ABS); 3S (доблесть) | 13 167 | Национальный институт корейского языка (Индивидуальный контракт) |
| Айхуб-документ Краткий текст ABS и EXT SELMY для газетных статей, вкладов, журнальных статей и судебных обзоров - [EDA] Data Eda Notebook -Онгунированный корейский документ извлечение резюме резюме и резюме создания конкурса AI (~ 20.12.09) | -П. 13S/214W → 1S/26W (ABS); 3S/55W (EXT) | 400 000 | Aihub (Индивидуальный контракт) |
| Aihub-Summary Резюме ABS All и раздел для академических работ и патентных спецификаций | -Академические документы, патентные спецификации -ОРИГИН → АБС | 350 000 | Aihub (Индивидуальный контракт) |
| Айхаб-книга Сводка данных Сводка ABS для оригинальной корейской книги по различным темам | -Полета, жизнь, жизнь, налог, окружающая среда, развитие сообщества, торговля, экономика, труд и т. Д. -300-1000 символов → ABS | 200 000 | Aihub (Индивидуальный контракт) |
| SAE4K | 50 000 | CC-BY-SA-4.0 | |
| Sci-News-Sum-KR-50 | Новости (это/наука) | 50 | Грань |
| Wikilingua : многоязычный набор данных абстрактной суммирования (2020) На основе ручного сайта Wikihow, 18 языков, таких как корейский и английский -бумага, ноутбук для коллаб | -Как до документов -391W → 39W | 12,189 (KOR в общей сложности 770 087) | 2020, CC By-NC-SA 3.0 |
| Набор данных | Домен / длина | Объем | Лицензия |
|---|---|---|---|
| Scisummnet (бумага) Предоставляет три типа резюме для исследований ACL (NLP) -Cl-scisumm 2019-task2 (репо, бумага) -Cl-scisumm @ emnlp 2020-task2 (репо) | -Ресуральная статья (Вычислительные лингвисты, НЛП) 4,417W → 110 Вт (бумажный реферат); 2S (цитата); 151 Вт (ABS) | 1000 (ABS/ EXT) | CC BY-SA 4.0 |
| Лонгсумм Относительно длинное резюме (ABS на основе сообщений в блогах, связанные конференции Video Talks) -Longsumm 2020@emnlp 2020 -Longsumm 2021@ naacl 2021 | -Ресуративная статья (NLP, ML) -ОРИГИН → 100S/1500 Вт (ABS); 30S/ 990W (EXT) | 700 (ABS) + 1705 (Ext) | Атрибуция-некоммерка |
| CL-Laysumm Обеспечить легкий слой для непрофессионалов для полей NLP и ML. -Cl-laysumm @ emnlp 2020 | -Исследовательская статья (эпилепсия, археология, инженерия материалов) -ОРИГИН → 70 ~ 100 Вт | 600 (ABS) | Потребности в отдельном соглашении (отправлено электронное письмо по адресу [email protected]) |
| Глобальный голос : пересечение границ в автоматической сумме новостей (2019) -Бумага | - Новости -359W → 51W | ||
| MLSUM : многоязычное корпус суммирования Подобно набору данных CNN/Daily Mail, основные моменты/описание в новостных статьях считаются резюме и резюме для английского, французского, Германии, испанского, русского, турецкого набора данных -бумага, использование (Huggingface) | - Новости -790W → 56W (EN Основы) | 1,5 м (пресс) | Только некоммерческие исследования |
| Модель | Предварительное обучение | Использование | Лицензия |
|---|---|---|---|
| Берт (многоязычный) BERT-баз (параметры 110 м) | -Википедия (многоязычная) -Верство. -110K Общие слова | BERT-Base, Multilingual Cased версия( --do_lower_case=false опция)-Tensorflow | Google (Apache 2.0) |
| Коберт BERT-BASE (параметры 92 м) | -Wikipedia (5 м), новости (20 млн. Приговор) -Сенция 8 002 слова (без неиспользованного токена) | -Pytorch -Все доступны в виде библиотеки трансформаторов HuggingFace через Kobert-Transformers (Monologg), Distilkobert доступен | Sktbrain (Apache-2.0) |
| Корберт Берт-баз | -News (10 лет), Википедия и т. Д. 23 ГБ -Три Морфологический анализ API / Wordiece (предоставлено две версии отдельно) -30,349 слова Латинские алфавиты: обложка - [Введение] Лим Джун (Этри). NLU Tech Talk с Корбертом | -Pytorch, Tensorflow | Этри (Индивидуальный контракт) |
| Kcbert BERT-BASE/большой | -Дейвер новостей комментарий (12,5 ГБ, 8,9 миллионов предложений) (19.01.01 ~ 20.06.15 Комментарии из статей в статьях и комментариях) -Tokenizers BertWordPieCetokenizer -30 000 слоев | Beomi (MIT) | |
| Кобарт Барт (124 м) | -Wikipedia (5M) и другие (новости, книга, слова каждого (разговор, новости, ...), национальная петиция Чон Ва -да и т. Д. -Tockenizers 'Tearnizer BPE Tokenizer 30 000 слоев (включены) - [Пример] Seujung. Kobart-Summarization (код, демонстрация) | -Вывая специализация задачи -Суггингалфейс Трансформеры Поддержка библиотеки -Pytorch | SKT T3K (Модифицированный MIT) |
| Год | Бумага |
|---|---|
| 2018 | Обследование методов суммирования на основе нейронной сети Y. Dong |
| 2020 | Обзор техники и методов автоматической суммирования текста Widyassari, AP, Rustad, S., Shidik, GF, Noersasongko, E., Syukur, A. & Affandy, A. |
| 2020 | Обследование генерации текста с повышенным знанием Вэнхао Ю, Ченгуан Чжу, Зайтанг Ли, Жейт Ху, Цинюн Ван, Хенг Цзи, Мэн Цзян |
| Год | Бумага | Ключевые слова |
|---|---|---|
| 1958 | Автоматическое создание рефератов литературы Ph Luhn | Gen-Ex |
| 2000 | Генерация заголовков на основе статистического перевода М. Банко, Во Миттал и MJ Witbrock | Gen-Abs |
| 2004 | Lexrank : лексическая центральность на основе графика как значимость в суммировании текста Г. Эркан и Драдев, | Gen-Ex |
| 2005 | Суммизация единого документа на основе извлечения предложений J. Jagadeesh, P. Pingali и V. Varma | Gen-Ex |
| 2010 год | Поколение заголовков с квази-синхронной грамматикой К. Вудсенд, Ю. Фэн и М. Лапата, | Gen-Ex |
| 2011 год | Суммизация текста с использованием скрытого семантического анализа Mg Ozsoy, FN Alpaslan и I. Cicekli | Gen-Ex |
| Год | Бумага | Ключевые слова |
|---|---|---|
| 2014 | При использовании очень большого целевого словаря для перевода нейронной машины С. Джин, К. Чо, Р. Мемисевич и Йошуа Бенгио | Gen-Abs |
| 2015 Модель | NAMAS : модель нейронного внимания для абстрактной суммирования (код) Am Rush, S. Chopra и J. Weston / Emnlp 2015 Чтобы выйти за рамки существующего метода выбора и комбинации предложений, мы вводим внимание к целевому к источнику в флаге SEQ2SEQ, чтобы создать абстрактную резюме. | АБС Seq2seq с Att |
| 2015 | На пути к абстрактному суммированию с использованием семантических представлений Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 Модель | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 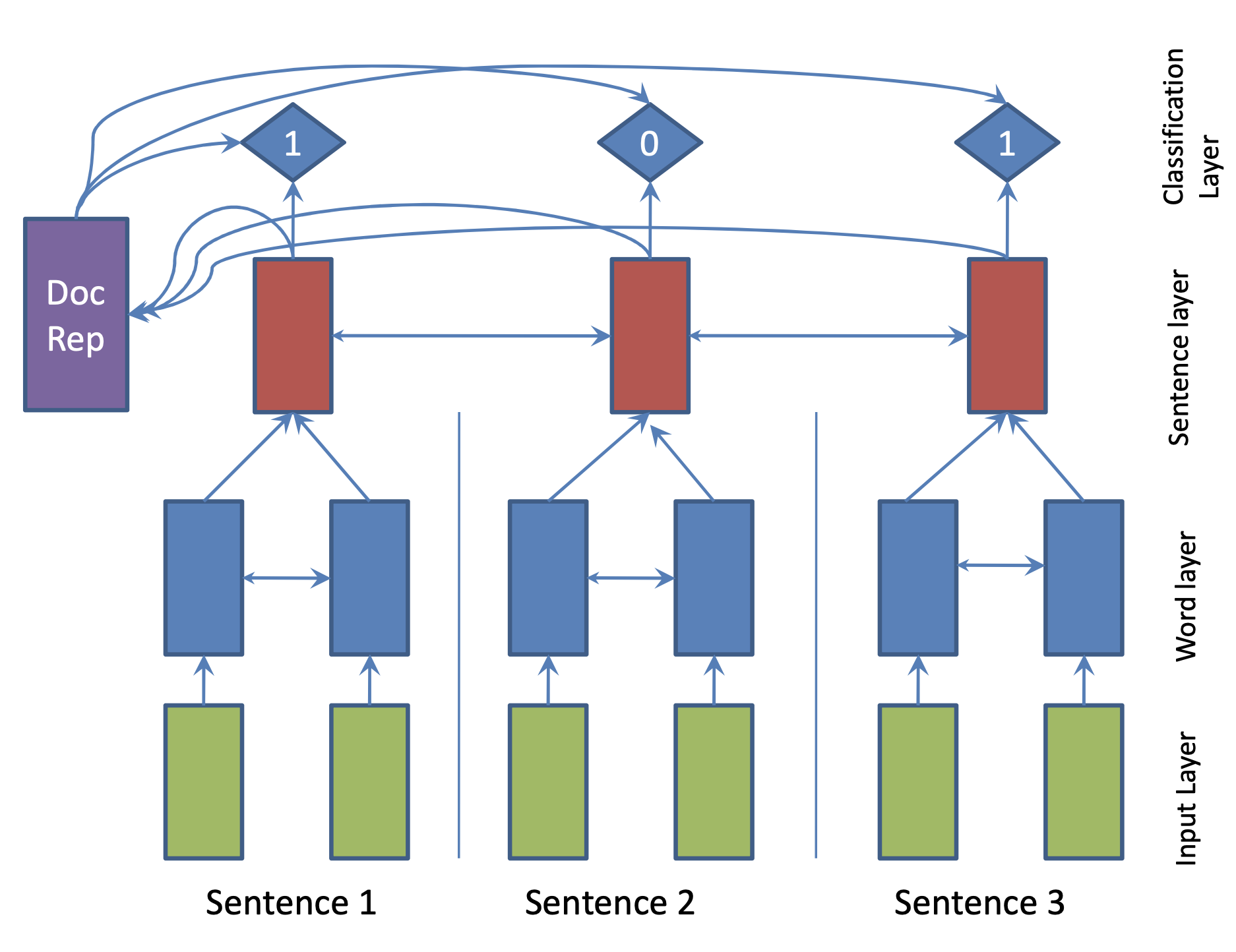 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 Модель, Техника | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 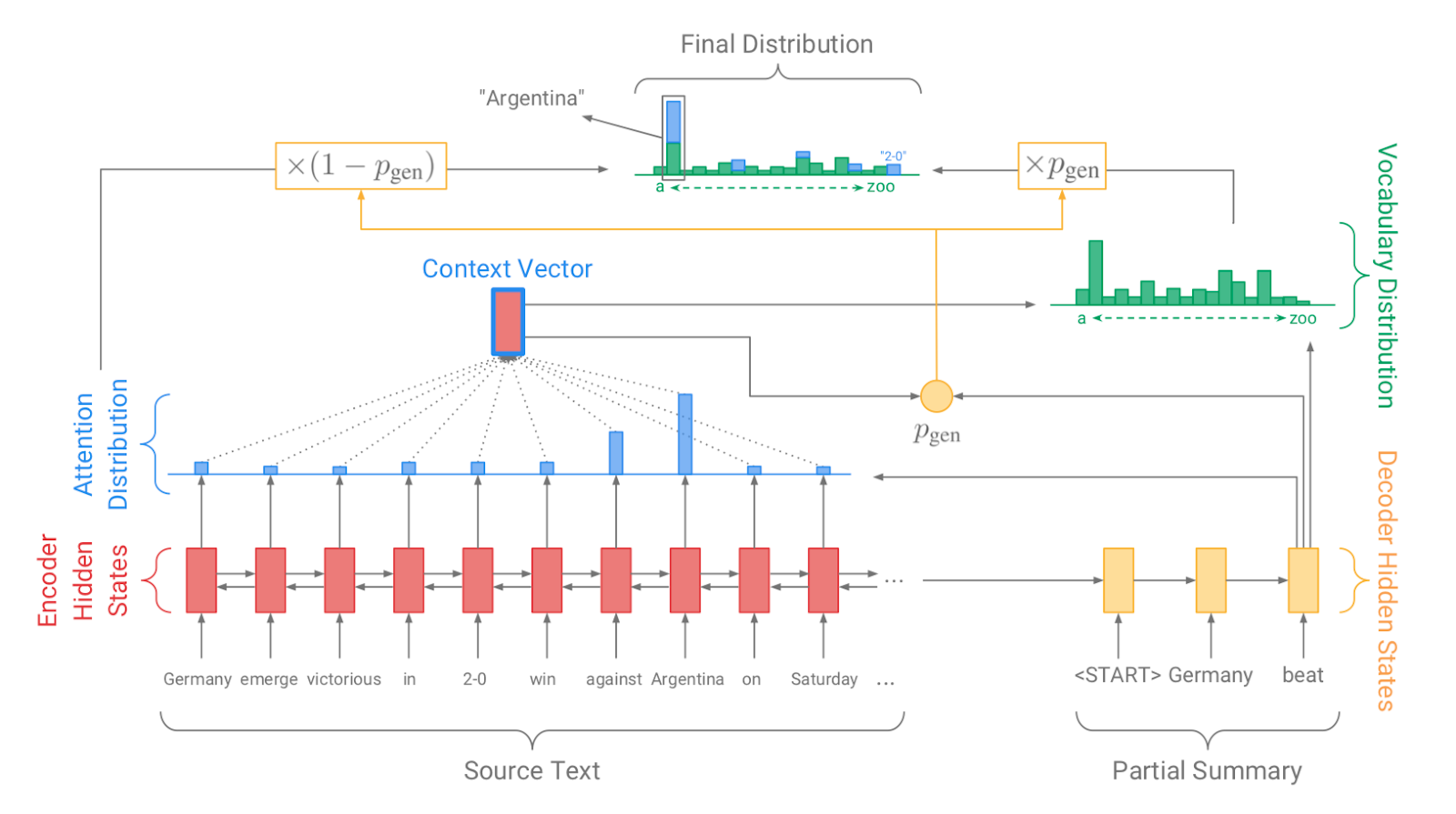 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 Модель | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 Модель | Вверх дном Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, Гибридный, Вверх дном |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 Модель | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 Модель | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 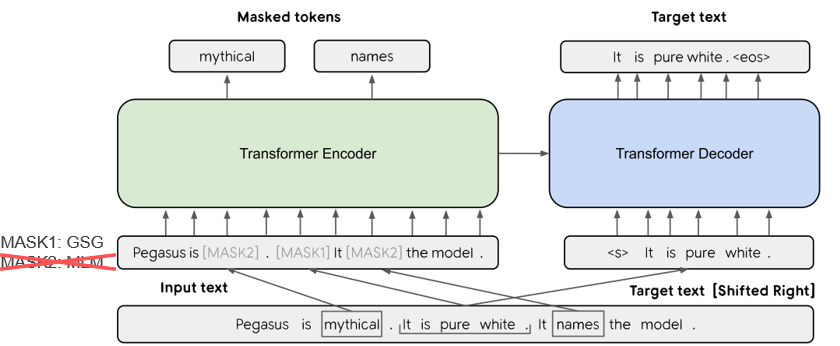 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 Модель | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


