Text Summarization Repo
1.0.0
Unter den NLPs handelt es sich um einen Raum, der Qualitätsdaten im Zusammenhang mit dem Feld "Textzusammenfassung" sammelt. Ich möchte ein guter Leitfaden für diejenigen sein, die sich für die Textübersicht interessieren.
Zunächst verstehen wir, welche detaillierten Themen, die der Text zusammenfasst, komponiert und die Hauptpapiere ansehen, die dieses Feld geführt haben. Seitdem haben wir die Modelle Code, Datensätze und Pre -Crane aufgelistet, die zum Erstellen eines direkten Textübersichtsmodells erforderlich sind.
Intro in die Textübersicht
PAPIERE
Ressourcen
Andere
Berry, Dumais & O'Brien (1995) definiert die Textübersicht wie folgt:
Die Zusammenfassung der Texte ist der Prozess, die wichtigsten Informationen aus einem Text zu destillieren, um eine bestimmte Aufgabe und einen bestimmten Benutzer zu erstellen
Es ist ein Prozess, nur wichtige Informationen unter dem in einem Wort angegebenen Text zu verfeinern . Hier ist der Ausdruck der Verfeinerung und die Bedeutung von Wichtigen ein eher abstrakter und subjektiver Ausdruck, daher möchte ich ihn persönlich wie folgt definieren.
f(text) = comprehensible information
Mit anderen Worten, in der Textübersicht besteht darin, den Originaltext in eine einfache und wertvolle Informationen umzuwandeln . Menschen sind auf einen Blick auf Textinformationen schwer zu erkennen, der lang oder in mehrere Dokumente unterteilt ist. Manchmal kennt man nicht viele professionelle Begriffe. Es ist ziemlich wertvoll, diese Texte in eine einfache und einfache Form zu reflektieren und gleichzeitig den Originaltext gut zu reflektieren. Was sich wirklich lohnt und wie man es ändert, hängt von dem Zweck des Zusammenfassens oder des persönlichen Geschmacks ab.
Aus dieser Sicht kann gesagt werden, dass der Text nicht nur die Aufgaben zusammenfasst, die Texte wie die Minuten, die Überschrift für Zeitungsingenieure, das Zusammenfassung und der Lebenslauf und die Aufgaben erstellen, sowie Aufgaben, die Text in Diagramme oder Bilder umwandeln. Da es sich nicht nur um eine Zusammenfassung handelt, handelt es sich um eine Textübersicht , sodass die Quelle der Zusammenfassung in Form von Text begrenzt ist. (Die Zusammenfassung der Zusammenfassung liegt daran, dass sie nicht nur Text oder Video wie Text sein kann. Im Beispiel ist das erstere Beispiel für Bildunterschriften. Letzteres Beispiel ist die Video -Zusammenfassung. Wenn man den jüngsten Deep -Lern -Trend bezieht, wenn die Grenze zwischen Vision und NLP verschwommen ist, kann es sinnlos sein, „Text“ als Präfix zu setzen.))
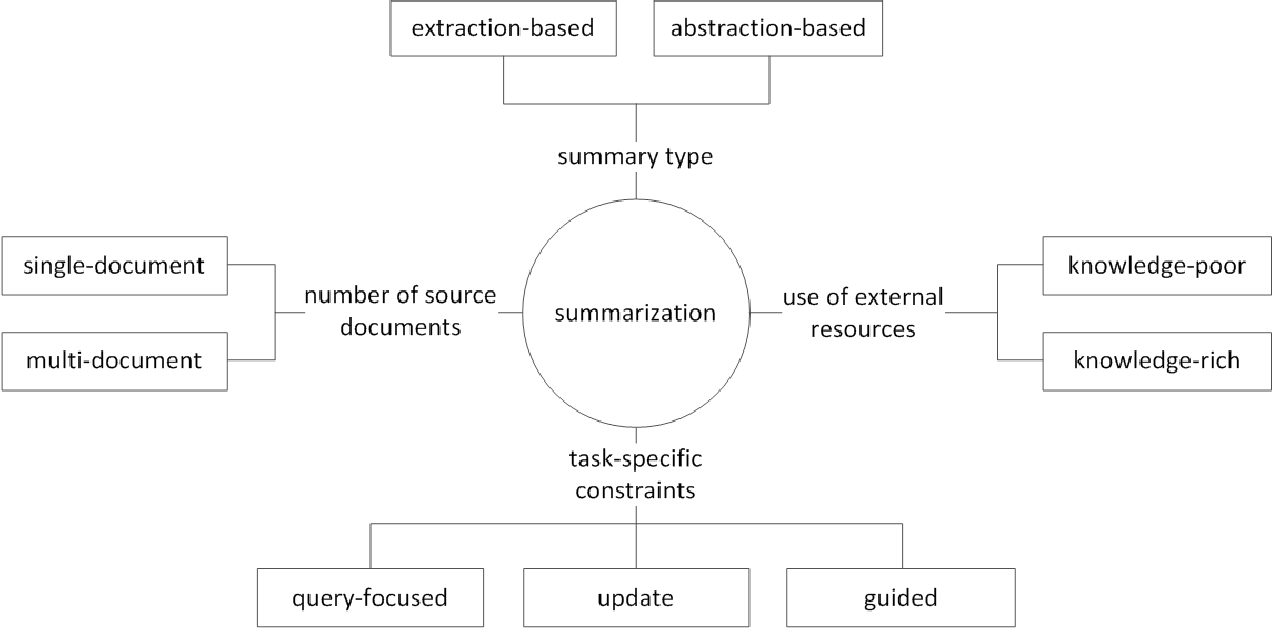
Im Allgemeinen wird die Aufgabe der Textübersicht in eine extraktive Zusammenfassung (im Folgenden als ext) und abstraktives Zusammenfassung (ABS) unterteilt, je nachdem, wie sie eine Zusammenfassung erzeugen. (Gudivada, 2018)
Extraktive Methoden wählen eine Teilmenge vorhandener Wörter, Phrasen oder Sätze im Originaltext, um eine Zusammenfassung zu bilden. Im Gegensatz dazu bauen abstraktische Methoden zunächst eine interne semantische Darstellung und die Nutzung der Generationstechnologie für natürliche Sprache auf.
Ext normalerweise bewertet die Bedeutung des Satzes und wählt ihn dann aus und kombiniert es, um eine Zusammenfassung zu erstellen. Es ähnelt der Aufgabe, beim Lesen einen Textmarker zu malen. ABS hingegen basiert auf dem Originaltext, ist jedoch eine NLG -Methode (Natural Language Generation), die einen neuen Text erzeugt . Es ist unwahrscheinlich, dass Ext Ausdrücke, die aufgrund des Textes im Originaltext auf Ausdrücke beschränkt sind. ABS hingegen hat den Vorteil, dass es die Möglichkeit gibt, einen beispiellosen Ausdruck zu erzeugen, da er im Modell einen neuen Text erstellen muss, aber flexiblere Ansätze hat.
Gemäß der Anzahl der Originaltexte entsprechend der Textform der Einzel-/Multi -Dokumenten -Zusammenfassung, des Schlüsselworts/Satzes Zusammenfassung gibt es je nach Zusammenfassung des Zusammenfassungsprozesses verschiedene externe Informationen , wie z. B. die Zusammenfassung.
(G. Sizov (2010). Extraktionsbasierte automatische Zusammenfassung: Theoretische und empirische Untersuchung der Zusammenfassungstechniken
Schauen wir uns die wichtigsten Forschungsthemen im Bereich der Textübersicht an und überlegen Sie, welche Art von Herausforderung in diesem Bereich.
Zusammenfassung der Multi / Long -Dokumente
Wie bereits erwähnt, besteht die Zusammenfassungsaufgabe darin, den unverständlichen Text in verständliche Informationen zu ändern. Je länger der ursprüngliche Text oder die Zusammenfassung der Dokumente mehrerer Quellen, desto mehr Dokument steigt die Nützlichkeit der Zusammenfassung. Das Problem ist, dass gleichzeitig auch die Schwierigkeit der Zusammenfassung zunimmt.
Aus diesem Grund steigt der ursprüngliche Text, je länger der ursprüngliche Text, die rechnerische Komplexität umso schneller zunimmt. Dies ist ein viel kritischeres Problem bei den jüngsten Methoden auf dem neuronalen Netzwerk, einschließlich Transformator als in statistischen Methoden wie Textrank in der Vergangenheit. Zweitens, je länger der Originaltext, desto mehr der Kern des Inhalts, dh Geräusche. Es ist nicht leicht zu ermitteln, was Geräusche und was informativ ist. Schließlich haben lange Texte und verschiedene Quellen gleichzeitig verschiedene Perspektiven und Inhalte, was es schwierig macht, eine Zusammenfassung zu erstellen, die sie gut abdeckt.
Multi -Dokumente Zusammenfassung (MDS)
MDS ist eine Zusammenfassung einer Vielzahl von Dokumenten . Auf den ersten Blick wird es schwierig sein, die Artikel verschiedener Perspektiven verschiedener Autoren zusammenzufassen, als ein Dokument zusammenzufassen, das ein Thema aus einem konsistenten Trend und einer konsistenten Sichtweise beschreibt. Selbst im Fall von MDS basiert es natürlich normalerweise auf demselben Cluster -Dokument, das sich mit ähnlichen Themen befasst, es ist jedoch nicht einfach, wichtige Informationen zu identifizieren und die Aussichtsinformationen unter vielen Dokumenten zu filtern.
Die Aufgabe, die Bewertungen zu bestimmten Produkten zusammenfasst, ist ein Beispiel für MDS, an das am einfachsten zu denken ist. Diese Aufgabe, die normalerweise als Meinungssassen bezeichnet wird, ist durch eine kurze Textlänge und eine Subjektivität gekennzeichnet. Die Arbeit der Erstellung eines Wiki -Dokuments kann auch als MDS betrachtet werden. Liu et al. (2018) ist der ursprüngliche Text des Website -Textes im Wiki -Dokument, der der ursprüngliche Text ist, der als Zusammenfassung angesehen wird, und erstellt ein Wiki -Erstellungsmodell.
Lange Dokumente Zusammenfassung
Liu et al. (2018) ist eine statistische Möglichkeit, langen Text als Eingabe zu akzeptieren, eine Extraszusammenfassungszusammenfassung zu erstellen, nur wichtige Sätze zu verwenden und ihn als Eingabe des Modells zu verwenden. Um das Transformator-Computervolumen zu verringern, wird die Eingabe in Blockeinheiten unterteilt, und zu diesem Zeitpunkt verwendet die 1-D-Faltung die Nachdruckmethode, die die Anzahl der individuellen Aufmerksamkeitsschlüssel und -wert verringert. Das Big Bird (2020) -Papier führt einen spärlichen Sichtmechanismus (linear) anstelle einer Kombination aller vorhandenen Wörter ein, um die Berechnung des Transformators zu verringern. Infolgedessen wurde die gleiche Leistungshardware bis zu achtmal länger zusammengefasst.
Gidiotis & Tsoumakas (2020) versucht andererseits, sich der Kluft und Konquer zu nähern, die das Problem der langen Textübersicht nicht gleichzeitig lösen und es in mehrere Zusammenfassungen kleiner Text umwandeln. Training des Modells, indem der Originaltext und die Zielübersicht in die mehrere kleinere kleinere Quellzielpaare geändert werden. In der Inferenz aggregieren wir die partiellen Zusammenfassungen, die die Ausgabe durch dieses Modell ausführen, um eine vollständige Zusammenfassung zu erstellen.
Leistungsverbesserung
Wie können Sie eine bessere Zusammenfassung erstellen?
Übertragungslernen
In jüngster Zeit ist die Verwendung des Vorab -Modells in NLP fast standardmäßig geworden. Welche Art von Struktur sollten wir also ein vorbereitendes Modell erstellen, das eine bessere Leistung in der Textübersicht zeigen kann? Welches Objekt sollte ich haben?
In Pegasus (2020) wird die GSG -Methode (GAP Sätze Generierung), die einen Satz auswählt, der basierend auf dem Rouge -Score als wichtig angesehen wird, an, dass der Textzusammenfassungsprozess und der Einspruch die höhere Leistung ähnlich sind. Das aktuelle SOTA-Modell BART (2020) (bidirektionale und automatische Regressionstransformatoren) lernt in Form eines AutoCoders, das einige der Eingabettext Rauschen hinzufügt und es als Originaltext wiederherstellt.
Knowedge-verstärkte Textgenerierung
Bei der Text-zu-Text-Aufgabe ist es oft schwierig, die gewünschte Ausgabe allein mit dem Originaltext zu generieren. Es gibt also einen Versuch, die Leistung zu verbessern, indem dem Modell sowie der Originaltext eine Vielzahl von Kenntnissen zur Verfügung stellt . Die Quelle oder Bereitstellung dieser KnowEdge variiert in verschiedenen Arten von Schlüsselwörtern, Themen, sprachlichen Merkmalen, Wissensbasis, Knowedge -Diagrammen und geerdetem Text.
Zum Beispiel liefert Tan, Qin, Xing & Hu (2020) einen allgemeinen Summy-Datensatz, um eine Vielzahl von Aspektzusammenfassungen umzuwandeln, und liefert mehr reichhaltige Informationen zu einem bestimmten Aspekt zu einem bestimmten Aspekt. Verwenden Sie Wikipedia für. Wenn Sie mehr wissen möchten, sind Yu et al. Lesen Sie das Umfragepapier von (2020).
Nachbearbeitung
Es wäre schön, gleichzeitig eine gute Zusammenfassung zu erstellen, aber es ist nicht einfach. Warum erstellen Sie also keine Zusammenfassung und überprüfen und ändern sie dann in verschiedenen Kriterien?
Zum Beispiel schlägt CAO, Dong, Wu & Cheung (2020) eine Methode zur Reduzierung des sachlichen Fehlers vor, indem er vorgezogenes neuronales Korrektormodell auf die generierte Zusammenfassung angewendet wird.
Darüber hinaus gibt es auch viele Versuche, ** Graph Neural Network (GNN) ** anzuwenden, was in letzter Zeit viel Aufmerksamkeit erhalten hat.
Datenknappheitsproblem
Die Zusammenfassung der Text ist eine Aufgabe, die viel Zeit in Anspruch nimmt, was für den Menschen nicht einfach ist. Daher kostet es im Vergleich zu anderen Aufgaben relativ größere Kosten für die Erstellung eines beschrifteten Datensatzes, und natürlich mangelt es an Daten für das Training.
Zusätzlich zur Methode zur Übertragungslernen unter Verwendung des zuvor erwähnten Vorbetrags-Modells lernen wir in unbeaufsichtigten Lern- oder Verstärkungslernmethoden oder versuchen, einen Lernansatz zu versuchen.
Natürlich ist es auch ein sehr wichtiges Forschungsthema, gute Zusammenfassungsdaten zu erstellen. Insbesondere sind viele der aktuellen summarisierten Datensätze in den Nachrichtentypen in englischer Sprache voreingenommen. Infolgedessen werden mehrsprachige Datensätze wie Wikilingua und MLSUM erstellt. Weitere Informationen finden Sie in MLSUM: den mehrsprachigen Zusammenfassungskorpus .
Metrik- / Bewertungsmethode
Ich habe früher einen zerdrückenden Ausdruck von "Gut" geschrieben. Was ist eine "gute Zusammenfassung"? Brazinskas, Lapata & Titov (2020) verwenden die folgenden fünf Dinge, die auf dem Urteil einer guten Zusammenfassung basieren.
Das Problem ist, dass es nicht einfach ist, diese Teile zu messen. Der häufigste Leistungsmessanzeiger in Textzusammenfassungen ist die Rouge -Punktzahl. Es gibt verschiedene Varianten in der Rouge -Punktzahl, aber im Grunde genommen "Wie ist das Wort des Wortes der generierten Zusammenfassung und der Referenzzusammenfassung?" Es bedeutet ähnlich, aber wenn Sie eine andere Form haben oder wenn sich die Wortauftrag ändert, können Sie eine niedrigere Punktzahl erhalten, auch wenn es sich um eine bessere Zusammenfassung handelt. Insbesondere der Versuch, den Rouge -Score zu erhöhen, kann dies dazu führen, dass die ausdrucksstarke Vielfalt der Zusammenfassung beeinträchtigt wird. Aus diesem Grund liefern viele Papiere zusätzliche Ergebnisse der menschlichen Bewertung mit teurem Geld sowie Rouge -Score.
Lee et al. (2020) präsentiert eine RDASS (Referenz- und Dokumentbewusstseins -semantischer Punktzahl), so ähnlich wie die Zusammenfassung des Textes und der Referenz, und dann von den Vektor -basierten ähnlichen Straßen gemessen. Es wird erwartet, dass diese Methode die Genauigkeit der koreanischen Sprachbewertung erhöht, die Wörter und verschiedene Morphologie kombiniert, um verschiedene Bedeutungen und grammatikalische Funktionen auszudrücken. Kryściński, McCann, Xiong & Socher (2020) schlugen vor, einen schwach beaufsichtigten, modellbasierten Ansatz zur Bewertung der sachlichen Konsistenz vorzuschlagen.
Steuerbare Textgenerierung
Gibt es nur eine beste Zusammenfassung zu einem bestimmten Dokument? Es wird nicht. Menschen mit unterschiedlichen Neigungen können verschiedene zusammenfassende Texte für denselben Text bevorzugen. Selbst wenn Sie dieselbe Person sind, hängt die gewünschte Zusammenfassung vom Zweck der Zusammenfassung oder der Situation ab. Diese Methode zur Anpassung der Ausgabe an die gewünschte Form gemäß den vom Benutzer angegebenen Bedingungen wird als kontrollierbare Textgenerierung bezeichnet. Sie können eine personalisierte Zusammenfassung im Vergleich zur generischen Zusammenfassung vorlegen, die dieselbe Zusammenfassung für ein bestimmtes Dokument erstellt.
Die generierte Zusammenfassung sollte nicht nur leicht zu verstehen und zu bewerten, sondern auch eng mit der von Ihnen zusammengestellten Erkrankung zusammenhängen.
f(text, condition ) = comprehensible information that meets the given conditions
Welche Bedingung kann ich zum Zusammenfassungsmodell hinzufügen? Und wie können Sie eine Zusammenfassung erstellen, die zu dieser Bedingung passt?
Aspektbasierte Zusammenfassung
Wenn Sie AirPod -Benutzerbewertungen zusammenfassen, möchten Sie möglicherweise jede Seite zusammenfassen, indem Sie die Klangqualität, den Akku und das Design teilen. Oder Sie möchten den Schreibstil oder das Gefühl im Artikel anpassen. In diesem Originaltext wird die Arbeit, die nur Informationen zu bestimmten Aspekten oder Merkmalen zusammenfasst, als Aspektbasis-Zusammenfassung bezeichnet.
Zuvor wurden nur Modelle, die nur in vordefinierter Aspekt funktionierten, die hauptsächlich für das Modelllernen verwendet wurden, nun versucht, die Argumentation willkürlicher Aspekte zu ermöglichen, die dem Lernen nicht wie Tan, Qin, Xing und Hu (2020) verabreicht wurden.
Abfrageorientierte Zusammenfassung (QFS)
Wenn die Bedingung abfragt wird, heißt sie QFS. Abfrage ist hauptsächlich eine natürliche Sprache, daher ist die Hauptaufgabe, wie man diese verschiedenen Ausdrücke gut macht und sie mit dem Originaltext abgibt. Es ist dem QA -System, das wir gut kennen, ziemlich ähnlich.
Summarierung aktualisieren
Menschen sind Tiere, die weiterhin lernen und wachsen. Daher kann der heutige Wert für bestimmte Informationen sich von dem Wert einer Woche später völlig unterscheiden. Der Wert des Inhalts im Dokument, das ich bereits erlebt habe, wird gesenkt, und der neue Inhalt, die noch nicht erlebt wurden, werden noch einen hohen Wert haben. Aus dieser Sicht wird als Update Summarization bezeichnet, um eine neue Zusammenfassung eines neuen Inhalts zu erstellen, der den zuvor erlebten Dokumentinhalten ähnelt .
Ctrlsum nimmt verschiedene Schlüsselwörter oder beschreibende Eingabeaufforderungen mit dem Text ein, um die generierte Zusammenfassung anzupassen. Es handelt sich um ein allgemeineres, kontrollierbares, kontrollierbares Textübersichtsmodell, da es die gleichen Ergebnisse wie für Schlüsselwörter oder Eingabeaufforderungen zeigt, die in der Trainingsphase nicht explizit gelernt werden. Sie können es problemlos über die Zusammenfassungsbibliothek von Koh Hyun -woong verwenden.
Darüber hinaus sind verschiedene Versuche, ein zusammenfassendes Modell zu erstellen, das eher für die Zusammenfassung der Konversation als für ein typisches DL -Thema wie ** Modellleichtgewicht sowie eine Zusammenfassung des Dialogs und nicht für einen strukturierten Text wie Nachrichten oder Wikipedia geeignet ist. Es gibt Themen.
Wenn Sie Folgendes im Feld Textübersicht kennen, können Sie leichter lernen.
NLP -Grundkonzept verstehen
Transformator/Bert-Struktur und objektives Verständnis vor dem Training
Viele der neuesten NLP -Papiere basieren auf mehreren Vorbereitungsmodellen, darunter Bert, basierend auf Transformator, Roberta und T5, die Varianten dieser Bert sind. Wenn Sie ihre schematische Struktur und das Vorbildungsziel verstehen, ist dies eine große Hilfe beim Lesen oder Implementieren eines Papiers.
SMS -Zusammenfassung Grundkonzept
Graph Neural Network (GNN)
Maschinelle Übersetzung (MT)
MT ist eine der aktivsten Aufgaben im NLP -Feld seit der Entstehung von SEQ2SEQ. Wenn Sie sich den Zusammenfassungsprozess als einen Prozess der Konvertierung eines Textes in einen anderen Texttyp betrachten, kann er als eine Art MT angesehen werden, so dass so viel von MT -bezogenen Studien und Ideen im Summarierungsfeld geliehen oder angewendet werden.
| Jahr | Papier | Schlüsselwörter |
|---|---|---|
| 2004 Modell | Textrank : Bestellung in Texte einbringen R. Mihalcea, P. Tarau Es ist ein Klassiker im Sektor der Extraktion und noch aktiv. In der Annahme, dass der wichtige Satz innerhalb des Dokuments (dh in der Zusammenfassung enthalten) ein PageRank -Algorithmus ist, der anfängliche Idee der Google -Suchmaschine, vorausgesetzt, er wird mit anderen Sätzen eine hohe Gleichstellung haben. Jeder Satz konfiguriert das gewichtete Diagramm auf Satzebene, um die Ähnlichkeit mit einem anderen Satz im Dokument zu berechnen, und enthält diesen hohen Gewichtssatz in die Zusammenfassung. Statistical -basierte unbeaufsichtigte Lernmethoden können ohne separate Lerndaten vernünftig sein, und der Algorithmus ist klar und leicht zu verstehen. - [Bibliothek] Gensim.Summarization (nur 3.x Version ist verfügbar. Löschen aus Version 4.x), Pytextrank - [Theorie/Code] Lovit. Schlüsselwort -Extraktion mithilfe von Texttrank und Kernsatzextrakt | Ext, ext, Graph-basierte (PageRank), Unbeaufsichtigt |
| 2019 Modell | Bertsum : Textübersicht mit vorgetäuschten Encodern (Officeiad) Yang Liu, Mirella Lapata / EMNLP 2019 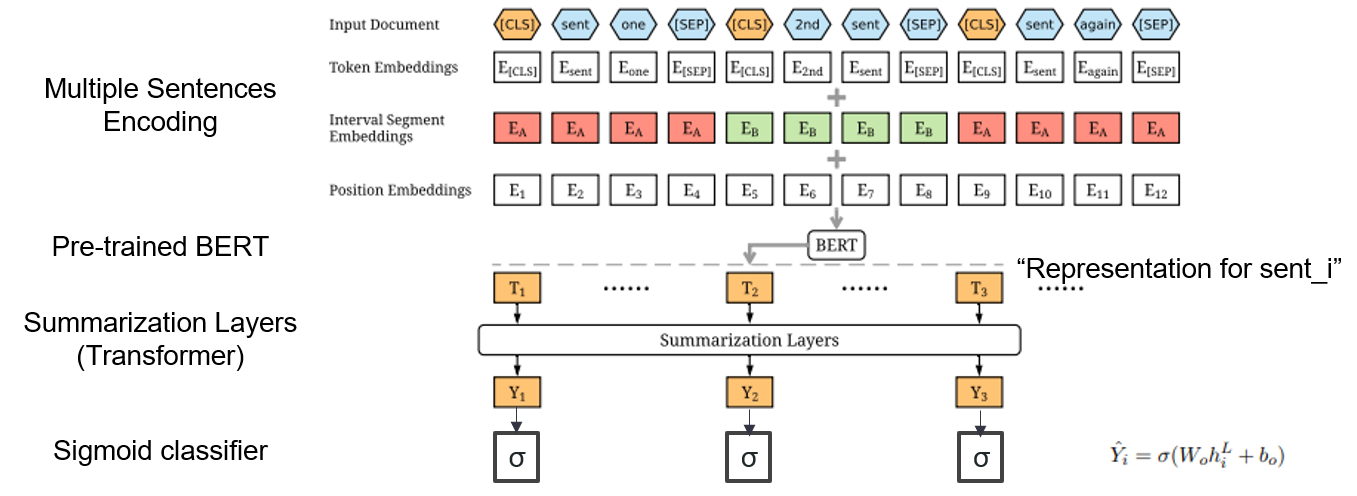 Wie kann ich zusammen ausgebildetes Bert zusammenfassend verwenden? Wie kann ich zusammen ausgebildetes Bert zusammenfassend verwenden?Bertsum schlägt modifizierte Eingangsbettdings vor, die [CLS] -Token vor jedem Satz einfügt, und fügt Intervallsegment -Einbetten hinzu, um einen mehrfacher Satz in einen Eingang hinzuzufügen. Das EXT-Modell verwendet eine Encoderstruktur mit einem Transformatorschicht auf der Bert, und das ABS-Modell verwendet ein Encoder-Decoder-Modell mit einem 6-Schicht-Decodierer auf dem Ext-Modell. - [Rezension] Lee Jung -Hoon (Koreuniv DSBA) - [Koreanisch] Kobertsum | Ext/ABS, Bert+Transformator, 2-inszenierte Feinabstimmung |
| 2019 Vorabmodell | BART : Denoising Sequenz-zu-Sequenz-Vorausbildung für die Erzeugung, Übersetzung und das Verständnis der natürlichen Sprache Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer / ACL 2020 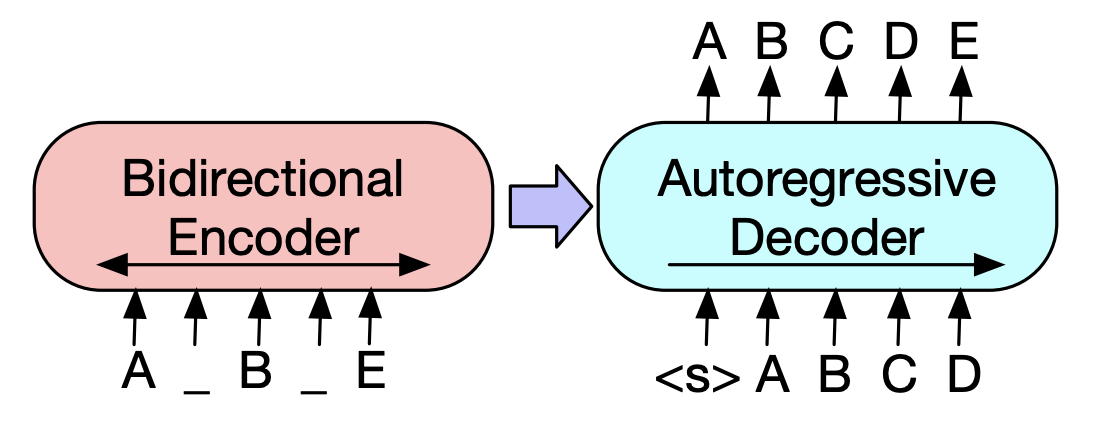 Bert ist ein bidirektrischer Encoder, schwach für Erzeugungsaufgaben, und GPT hat einen Nachteil, dass er keine bidiredierten Informationen mit einem Auto-Regressionsmodell erhält. Bert ist ein bidirektrischer Encoder, schwach für Erzeugungsaufgaben, und GPT hat einen Nachteil, dass er keine bidiredierten Informationen mit einem Auto-Regressionsmodell erhält.Der BART hat eine SEQ2SEQ -Form, die sie kombiniert, sodass Sie mit verschiedenen Denosing -Techniken in einem Modell experimentieren können. Infolgedessen zeigt der Textfischen (ändert die Textspanne auf ein Masken -Token) und das Satzschluff (zufällig mischt der Satz) die Leistung, die das Ki -SOTA -Modell im Bereich der Zusammenfassung übertrifft. - [Koreanisch] Skt T3K. Kbart -[Rezension] Jin Myung -hoon_video, lim yeon -soo_ geschrieben von jiwung hyun_ | ABS, SEQ2SEQ, Denoising Autocoder, Text füllen |
| 2020 Modell | Übereinstimmungen : Extraktionsübersicht als Textübereinstimmung (Office) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang / ACL 2020 - [Rezension] Yoo Kyung (Koreuniv DSBA) | Ext |
| 2020 Technik | Zusammenfassen des Textes zu allen Aspekten: Ein wissensgeformtes, schwach übertriebener Ansatz (offizieller Code) Bowen Tan, Lianhui Qin, Eric P. Xing, Zhiting Hu / EMNLP 2020 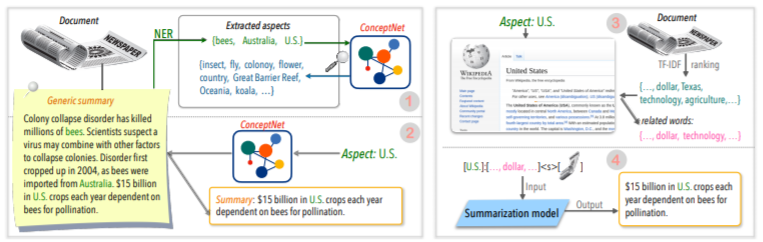 Aspektbasierte Zusammenfassung ist eine Aufgabe, die insofern nicht einfach ist, als sie nur in den vordefinierten Aspekten von Daten ausgeführt wird, was auch dann gelernt wird, wenn Sie das Modell lernen, und 2) mangelnde fehlende Aspektbasis-Zusammenfassungsdaten. In diesem Artikel werden externe Wissensquellen verwendet, um dieses Problem zu lösen. -Es durchläuft zwei Schritte, um eine generische Zusammenfassung in mehrere Aspektbasierte Zusammenfassungen umzuwandeln. Um die Anzahl der Aspekte zu erhöhen, wird die aus der generische Zusammenfassung extrahierte Entität Samen und aus dem Concepnet an seine Nachbarn extrahiert und betrachten jeden von ihnen als Aspekt. Wir verwenden Concepnet erneut, um für jeden dieser Aspekte eine PSEDO -Zusammenfassung zu erstellen. Extrahieren Sie die umgebende Einheit, die mit dem entsprechenden Aspekt in Concepnet verbunden ist, und extrahieren Sie nur die Sätze, die sie innerhalb der allgemeinen Zusammenfassung enthalten. Dies wird als Zusammenfassung für diese Entität (Aspekt) angesehen. -Wikipedia wird verwendet, um reichlich vorhandene Informationen zum angegebenen Aspekt zum Modell zu liefern. Insbesondere unter den Wörtern, die im Dokument erscheinen, ist die TF-IDF-Punktzahl im Dokument hoch und gleichzeitig, und gleichzeitig entspricht die Liste der 10 Wörter in der Wikipedia-Seite diesem Aspekt dem Aspekt mit der Modelleingabe. Auf diese Weise war das Vorab-Vorabmodell (BART) (BART) auch für willkürliche Aspekte mit kleinen Daten hervorragend. | Aspektbasierte, Wissensreich |
| 2020 Rezension | Was haben wir bald eine SMS -Zusammenfassung? Dandan Huang, Leyang Cui, Sen Yang, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang / EMNP 2020 Zusätzlich zum Rouge -Score werden 10 repräsentative Zusammenfassungsmodelle gemäß 8 Metriken (Polytope) bewertet, die sich auf Genauigkeit und Flüssigkeit beziehen. Um die Ergebnisse zusammenzufassen, -Die herkömmliche regelbasierte Methode ist immer noch als Grundlinie gültig. Unter ähnlichen Umgebungen zeigt das EXT- Modell im Allgemeinen eine bessere Leistung in der Gläubigkeit und der Faktenkonsistenz. Der Hauptmangel ist die Unermäßigkeit für extraktive Modelle sowie die Auslassung und die intrinsische Halluzination für abstraktische Modelle. -Die komplexeren Strukturen wie Transformatoren zur Erstellung der Satzdarstellung sind außer dem Duplizierungsproblem nicht sehr hilfreich. -Copy ( Zeigergenerator ) ist ein Reproduktionsdetail, das das Problem der Wortebene effektiv löst, indem es sowohl intrinsisch ist. Aber neigt dazu, bis zu einem gewissen Grad Redundanz zu verursachen. Die Abdeckung erfolgt mit einem großen Rand, wodurch die Wiederholungsfehler (Duplizierung) verringert werden, aber gleichzeitig den Intrinsic -Fehler der Addition und der Ungenauigkeit erhöht -Hybridmodell , das nach ext ist, ist gut für Rückrufe, aber es kann Probleme mit Ungenauigkeitsfehlern geben, da es eine Zusammenfassung durch einen Teil des Originaltextes (extrahierte Snippets) erzeugt. Vorausbildung, insbesondere das Encoder-Decoder-Modell (BART) als das Modell nur des Encoder-Modells (BertsUMEXTABs), ist in der Zusammenfassung sehr effektiv. Dies deutet darauf hin, dass die Vorbereitung des Verständnisses und der Erstellung von Eingaben für die Auswahl und Kombination von Inhalten sehr nützlich ist. Gleichzeitig, während sich die meisten ABS -Modelle auf den vorderen Satz konzentrieren, betrachtet Bart den gesamten Originaltext, was die Auswirkung des Satzes beim Vorbereiten zu sein scheint. 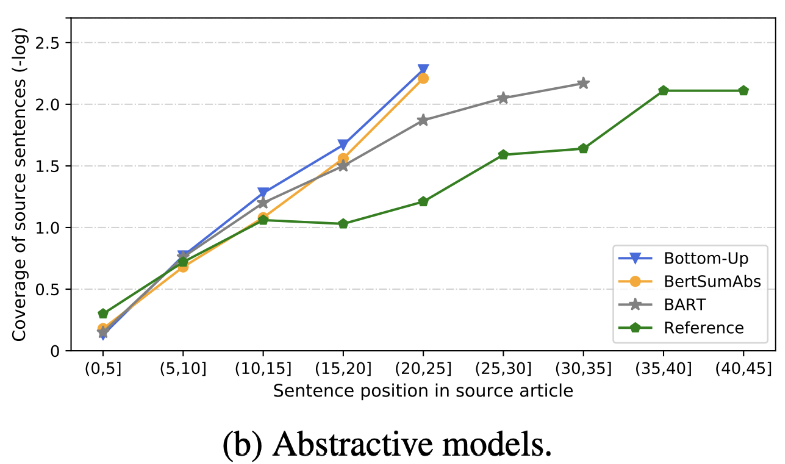 - [Rezension] Kim Han -Gil, Heo Hoon | Rezension |
| 2020 Modell | Strlsum : Auf dem Weg zu generischen kontrollierbaren Textübersicht (offizieller Code) Junxian HE, Wojciech Kryściński, Bryan McCann, Nazneen Rajani, Caiming Xiong Strlsum ist ein kontrollierbares Textübersichtsmodell, mit dem Sie die zusammenfassenden Anweisungen anpassen können, die durch Schlüsselwörter oder beschreibende Eingabeaufforderungen generiert werden. Training: Um einen keyword-basierten kontrollierbaren Zusammenfassungsdatensatz zu erstellen, indem allgemeine Zusammenfassungsdaten geändert werden, wählen Sie Untersequenzen aus, was der Zusammenfassung am ähnlichsten ist, und extrahieren Sie das Schlüsselwort dort. Stellen Sie dies in einen Eingang mit dem Dokument ein und beenden Sie den vorabstimmenden Bart. 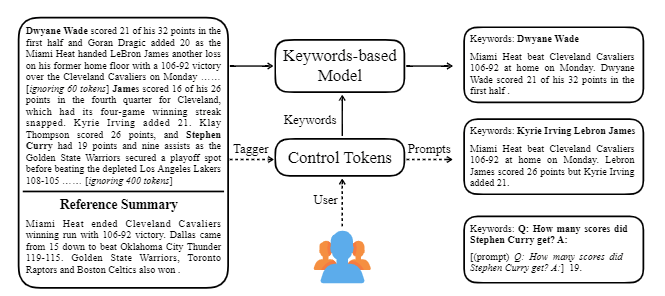 -Imperenz: Wie im Bild unten gezeigt, können Sie eine Zusammenfassung der Zusammenfassung hinzufügen, z. B. eine Zusammenfassung einer bestimmten Entität, die Anpassung der Zusammenfassungslänge oder das Erstellen einer Antwort auf eine Frage. Es ist bemerkenswert, dass es so funktioniert, als würde es in der Modellierungsphase solche Eingabeaufforderungen nicht explizit gelernt, aber es funktionierte, als wäre es so, als wäre es eine Zusammenfassung zu verstehen und eine Zusammenfassung zu erstellen. Ähnlich wie GPT-3. 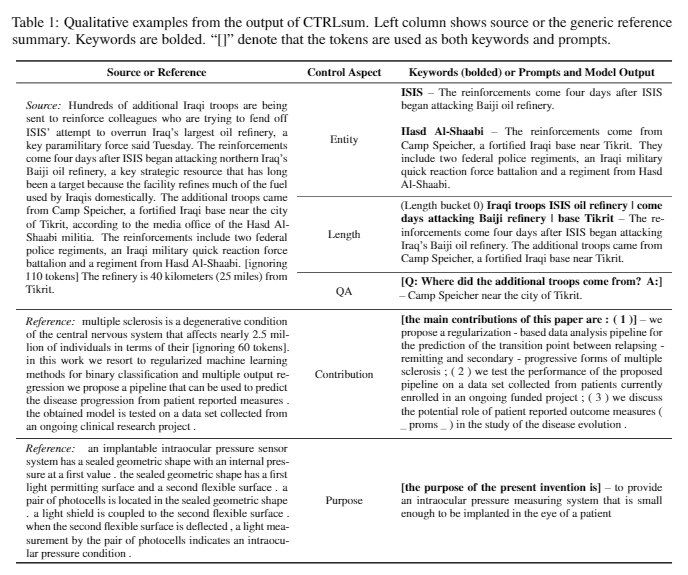 - [Bibliothek] Paket für kontrollierbare zusammenfassbare Strlsum | Steuerbar, Bart |
Paper Digest: Neueste Arbeiten zur Summarierung von Text
Papiere mit Code: Neueste Papiere
EMNLP 2020 Papers-Summarization
Tatsächlich haben wir die Code-, Daten- und Präeitrain -Modelle zusammengefasst, die zum Erstellen und Üben von Zusammenfassungsmodellen erforderlich sind. Es handelt sich hauptsächlich um koreanische Daten, und für englischbezogene Materialien finden Sie den Code -Teil jedes Papiers im Artikel über die Papiere.
Die Bedeutung der folgenden Schwachen lautet wie folgt.
w : Durchschnittswert der Anzahl der Wörter; s : Durchschnittswert der durchschnittlichen Anzahl von Sätzen
Beispiel) 13s/214w → 1s/26w bedeutet, dass es einen zusammenfassenden Text enthält, der aus durchschnittlich 13 Sätzen (durchschnittliche 214 Wörter) und durchschnittlich einen Satz (26 Wörter durchschnittlich) besteht.
abs ; ext : Rohstoff Zusammenfassung
| Datensatz | Domäne / Länge | Volumen (Paar) | Lizenz |
|---|---|---|---|
| Die Zusammenfassung der Wortdokumente jedermanns Titel des kurzen Nachrichtentextes, 3 Satz ABS und Ext Summe Alle Wörter aller, die mit den Zeitungspferden mit ID-Combiniertem mit den Untertiteln, Medien, Datum und Thema zusätzliche Informationen erhalten. | Nachricht -Origin → 3s (ABS); 3s (ext) | 13.167 | Nationales Institut für koreanische Sprache (Einzelvertrag) |
| AIHUB-Dokument Zusammenfassung Text ABS und Ext Summay für Zeitungsartikel, Beiträge, Zeitschriftenartikel und Gerichtsbewertungen - [EDA] Daten Eda Notebook -Gunierte Korean Dokumentextraktion Zusammenfassung und Erstellung Zusammenfassung AI -Wettbewerb (~ 20.12.09) | -Die Zeitung Artikel 300.000, 60.000 Beiträge, 10.000 Zeitschriftenartikel, Gerichtsurteil 30.000 13S/214W → 1S/26W (ABS); 3S/55W (Durchwahl) | 400.000 | Aihub (Einzelvertrag) |
| Aihub-summary ABS -Zusammenfassung nach allen und Abschnitt für akademische Papiere und Patentspezifikationen | -A akademische Arbeiten, Patentspezifikationen -ORIGIN → ABS | 350.000 | Aihub (Einzelvertrag) |
| AIHUB-Book-Datenübersicht ABS -Zusammenfassung für das ursprüngliche koreanische Buch zu verschiedenen Themen | -Lifetime, Leben, Steuer, Umwelt, Gemeindeentwicklung, Handel, Wirtschaft, Arbeitskräfte usw. -300-1000 Zeichen → ABS | 200.000 | Aihub (Einzelvertrag) |
| sae4k | 50.000 | Cc-by-sa4.0 | |
| Sci-News-Sum-KR-50 | Nachrichten (IT/Science) | 50 | MIT |
| Wikilingua : Ein mehrsprachiger abstrakter Summarierungs -Datensatz (2020) Basierend auf der manuellen Website WikiHow, 18 Sprachen wie Koreanisch und Englisch -Paper, Collab -Notebook | -Wie zu Dokumenten -391W → 39W | 12.189 (KOR Insgesamt 770.087) | 2020, CC BY-NC-SA 3.0 |
| Datensatz | Domäne / Länge | Volumen | Lizenz |
|---|---|---|---|
| Skisummnet (Papier) Bietet drei Arten von Zusammenfassungen für die ACL (NLP) -Schirurgie -Cl-SCISUMM 2019-TASK2 (Repo, Papier) -Cl-scisumm @ emnlp 2020-task2 (repo) | -Researchpapier (Computerlinguisten, NLP) 4,417W → 110W (Paper Abstract); 2S (Zitat); 151W (ABS) | 1.000 (ABS/ Ext) | CC BY-SA 4.0 |
| Longsumm Relativ langlistige Zusammenfassung (verwandte Blog -Beiträge -basierte ABS, verwandte Konferenzen Videogespräche) -Longsumm 2020@emnlp 2020 -Longsumm 2021@ naacl 2021 | -Researchpapier (NLP, ML) -Origin → 100S/1.500W (ABS); 30S/ 990W (Durchwahl) | 700 (ABS) + 1.705 (ext) | Attribution-Noncommercial-Sharealike 4.0 |
| Cl-Laysumm Stellen Sie eine einfache Schicht für Nichtprofessionals für NLP- und ML -Felder bereit. -Cl-Laysumm @ emnlp 2020 | -Research -Papier (Epilepsie, Archäologie, Materialentwicklung) -Origin → 70 ~ 100w | 600 (ABS) | Individuelle Vereinbarung (E -Mail an [email protected] gesendet) |
| Global Voice : Crossing Borders in automatic News Summarization (2019) -Papier | - Nachricht -359W → 51W | ||
| MLSUM : Der mehrsprachige Summar -Korpus Ähnlich wie bei CNN/Daily Mail -Datensatz werden die Highlights/Beschreibung in Nachrichtenartikeln als Zusammenfassung und Zusammenfassung für Englisch, Französisch, Deutschland, Spanisch, Russisch, türkischer Aufbaudatensatz angesehen -Paper, benutze (Umarmung) | - Nachricht -790W → 56W (EN Basis) | 1,5 m (ABS) | Nur nichtkommerzielle Forschungszwecke |
| Modell | Vorausbildung | Verwendung | Lizenz |
|---|---|---|---|
| Bert (mehrsprachig) Bert-Base (110 m Parameter) | -Wikipedia (mehrsprachig) -Wordstück. -110K Shared Vocabs | BERT-Base, Multilingual Cased Empfohlene Version( --do_lower_case=false Option)-Tensorflow | Google (Apache 2.0) |
| Kobert Bert-Base (92m Parameter) | -Wikipedia (5m Sätze), Nachrichten (20 m Satz) -Entierenziefe 8.002 Vokabeln (kein unbenutztes Token) | -Pytorch -Alle als Huggingface-Transformers-Bibliothek über Kobert-Transformers (Monologg), Distilkobert verfügbar | Sktbrain (Apache-2.0) |
| Korbert Bert-Base | -News (10 Jahre), Wikipedia usw. 23 GB -Etri Morphologische Analyse API / Wortstück (bereitgestellt zwei Versionen separat) -30,349 Vokabellen Lateinische Alphabete: Gehäuse - [Einführung] Lim Jun (etri). NLU -Tech -Gespräch mit Korbert | -Pytorch, Tensorflow | ETRI (Einzelvertrag) |
| Kcbert Bert-Base/groß | -Daver News Kommentar (12,5 GB, 8,9 Millionen Sätze) (19.01.01 ~ 20.06.15 Kommentare aus Artikeln in Artikeln und Kommentaren) -Tokenizers BertwordPeceteokenizer -30.000 Vokabellen | Beomi (MIT) | |
| Kbart Bart (124 m) | -Wikipedia (5m) und andere (Nachrichten, Buch, alle Worte (Gespräch, Nachrichten, ...), Cheong Wa Dae National Petition usw. -Tockenizer -Charakter BPE -Tokenizer 30.000 Vokabellen (enthalten) - [Beispiel] Seujung. Kbart-Sumarization (Code, Demo) | -Summarische Aufgabenspezialisierung -Huggingface Transformers Library Support -Pytorch | Skt T3K (modifizierter MIT) |
| Jahr | Papier |
|---|---|
| 2018 | Eine Umfrage zu neuronalen netzwerkbasierten Zusammenfassungsmethoden Y. Dong |
| 2020 | Überprüfung der automatischen Textübersichtstechnik und der Methoden Widyassari, AP, S. Rustad, Shidik, GF, Noersasongko, E., Syukur, A. & Affandy, A. |
| 2020 | Eine Übersicht über die kenntnisverstärkte Textgenerierung Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng JI, Meng Jiang |
| Jahr | Papier | Schlüsselwörter |
|---|---|---|
| 1958 | Automatische Schaffung von Literaturabträgen Ph Luhn | Gen-ex |
| 2000 | Schlagzeilengenerierung basierend auf statistischer Übersetzung M. Banko, Vo Mittal und MJ Witbrock | Gen-Abs |
| 2004 | Lexrank : Diagrammbasierte lexikalische Zentralität als Salience in der Textübersicht G. Erkan und Dradev, | Gen-ex |
| 2005 | Satzextraktionsbasierter Einzeldokumenten Zusammenfassung J. Jagadeesh, P. Pingali und V. Varma | Gen-ex |
| 2010 | Titelgenerierung mit quasi-synchroner Grammatik K. Woodsend, Y. Feng und M. Lapata, | Gen-ex |
| 2011 | Textübersicht unter Verwendung der latenten semantischen Analyse Mg Ozsoy, FN Alpaslan und I. Cicekli | Gen-ex |
| Jahr | Papier | Schlüsselwörter |
|---|---|---|
| 2014 | Bei der Verwendung eines sehr großen Zielvokabulars für die neuronale maschinelle Übersetzung S. Jean, K. Cho, R. Memisevic und Yoshua Bengio | Gen-Abs |
| 2015 Modell | NAMAs : Ein neuronales Aufmerksamkeitsmodell für die abstraktive Zusammenfassung (Code) Am Rush, S. Chopra und J. Weston / EMNLP 2015 Um über die vorhandene Satzauswahl und Kombinationsmethode hinauszugehen, führen wir die Aufmerksamkeit von Target-to-Source in das Flag-SEQ2SEQ ein, um eine abtraktive Zusammenfassung zu erstellen. | ABS SEQ2SEQ mit ATT |
| 2015 | Auf eine abstraktive Zusammenfassung unter Verwendung semantischer Darstellungen Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 Modell | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 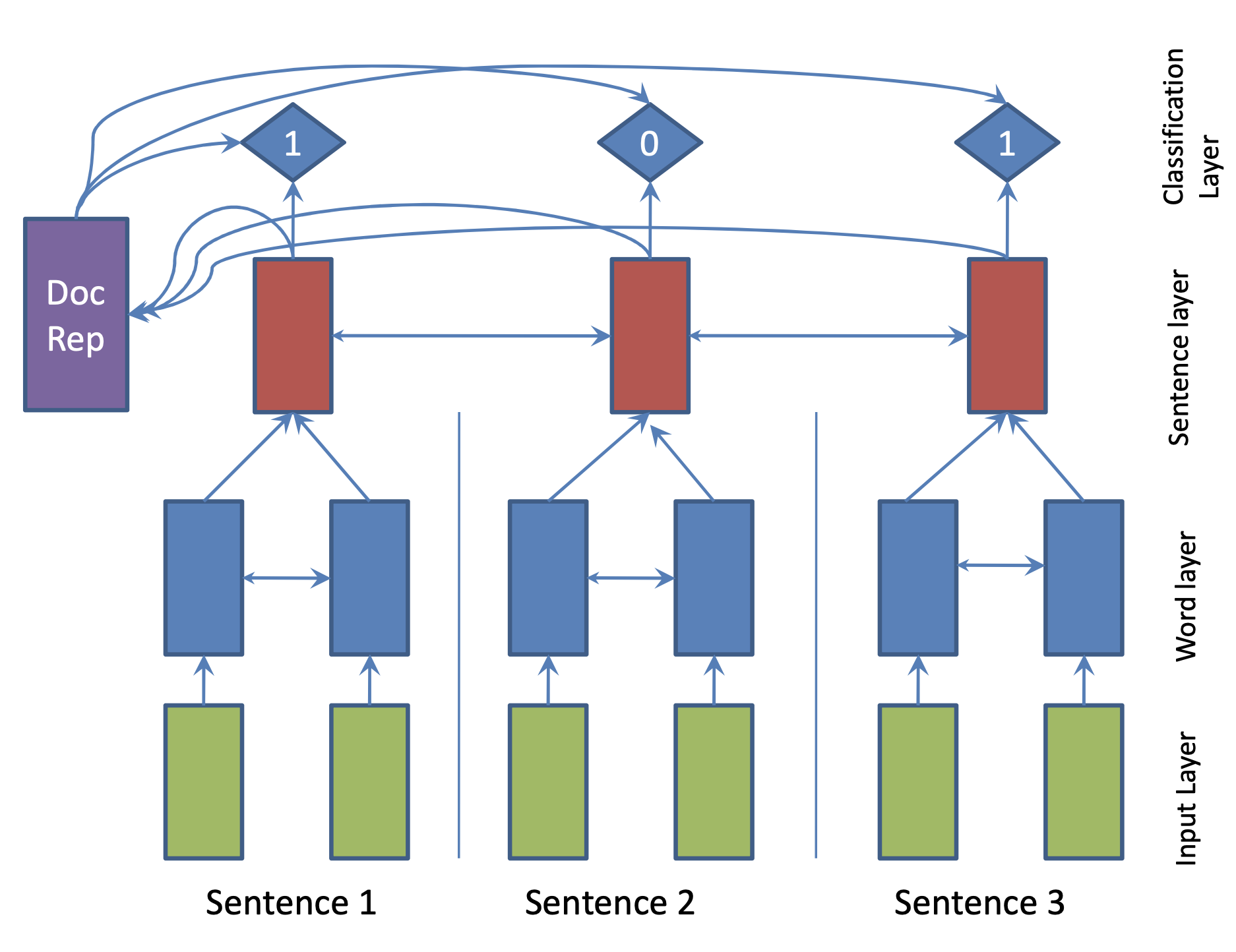 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 Modell, Technik | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 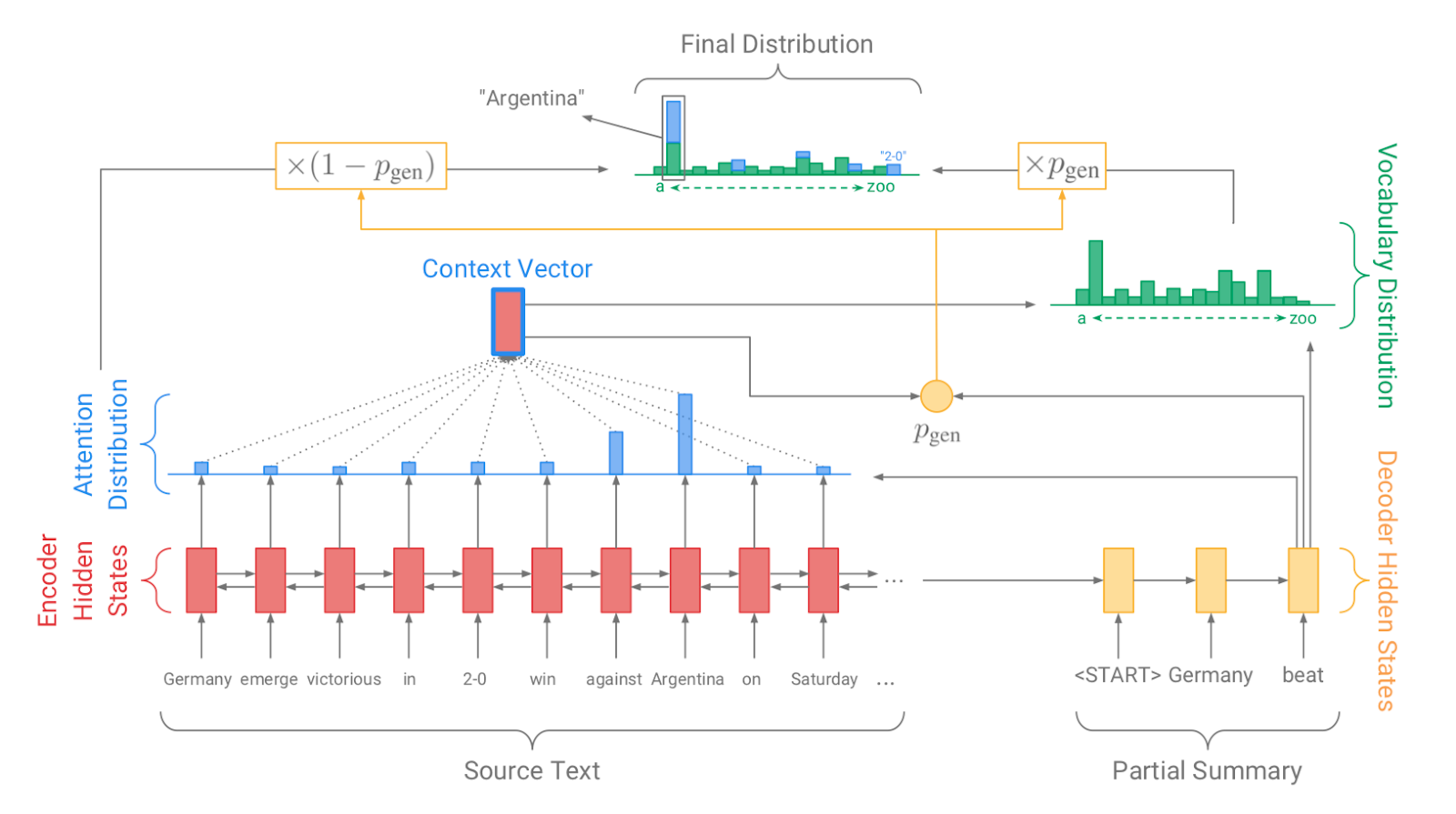 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 Modell | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 Modell | Von unten nach oben Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, hybrid, Von unten nach oben |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 Modell | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 Modell | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 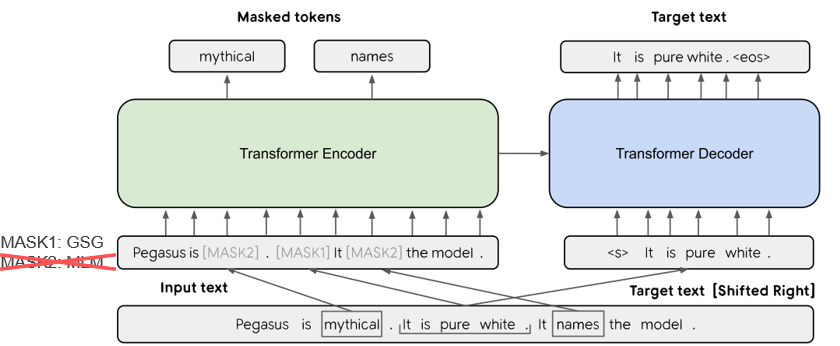 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 Modell | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


