Text Summarization Repo
1.0.0
在NLP中,它是一个累积与文本摘要字段相关的质量数据的空间。我想成为那些对文本摘要感兴趣的人的好指南。
首先,我们了解文本总结的详细主题是组成的,并查看引导该领域的主要论文。从那以后,我们列出了创建直接文本摘要模型所需的代码,数据集和前才木模型。
文本摘要介绍
文件
资源
其他的
Berry,Dumais和O'Brien(1995)定义了文本摘要如下:
文本摘要是从文本中提取最重要信息以产生特定任务和用户的过程
这是一个仅在单词中给出的文本中仅完善重要信息的过程。在这里,精炼的表达和重要的重要性是一种相当抽象的主观表达,因此我个人想将其定义如下。
f(text) = comprehensible information
换句话说,文本摘要是将原始文本转换为简单而有价值的信息。很难一目了然地看到人类的文本信息,这些信息长期或分为几个文档。有时您不知道很多专业条款。在很好地反映原始文本的同时,将这些文本反映成一种简单而简单的理解形式是非常有价值的。当然,真正值得的以及如何更改它会因总结或个人品味的目的而有所不同。
从这个角度来看,可以说文本不仅概述了创建文本的任务,例如会议记录,报纸工程师的标题,纸张摘要和简历,以及将文本转换为图形或图像的任务。当然,由于它不仅是摘要,因此是文本摘要,因此摘要的来源以文本形式有限。 (摘要的摘要是因为它不仅可以是文本或视频以及文本。
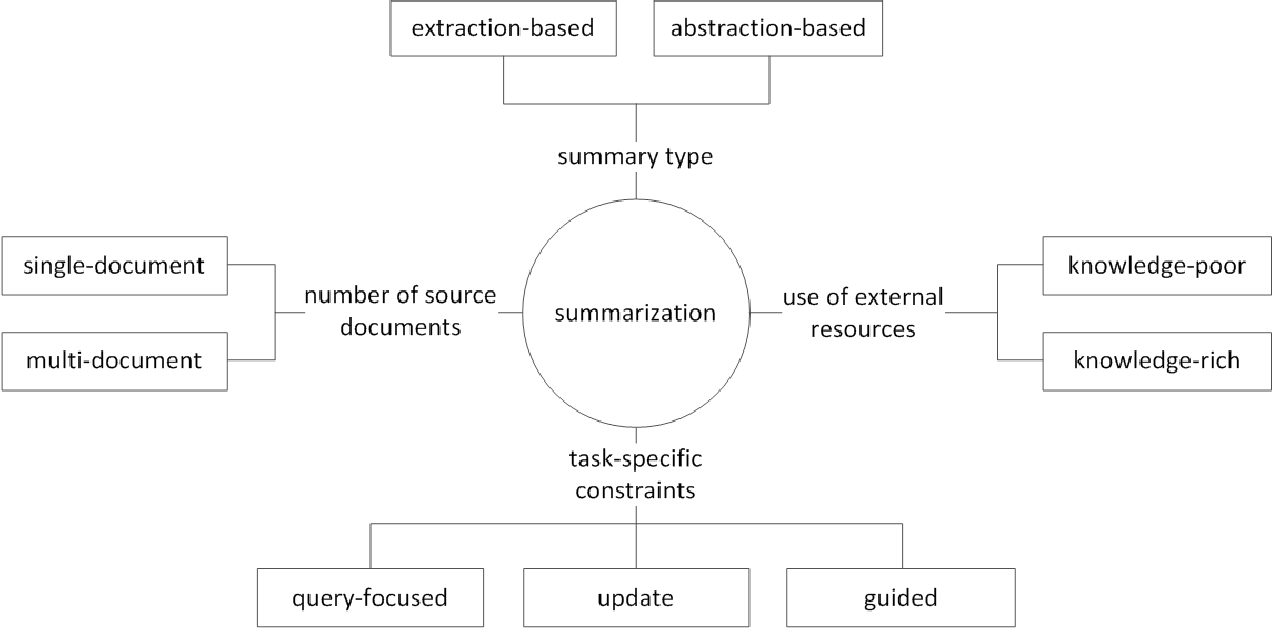
通常,根据它们如何生成摘要,将文本摘要任务分为提取性摘要(以下称为ext)和抽象性摘要(ABS)。 (古迪瓦达,2018年)
提取方法在原始文本中选择现有单词,短语或句子的子集以形成摘要。相比之下,抽象方法首先构建了内部语义表示和使用自然语言世代技术。
EXT通常会得分句子的重要性,然后选择并结合起来以创建摘要。这类似于在阅读时绘制荧光笔的任务。另一方面, ABS基于原始文本,但是一种生成新文本的NLG(自然语言生成)方法。由于原始文本中的文本,Ext不太可能包括限于表达式的表达式。另一方面,ABS具有创建前所未有的表达式的可能性,因为它必须在模型中创建一个新文本,但是它具有更灵活的方法。
此外,根据原始文本的数量,根据单/多文档摘要的文本形式,关键字/句子摘要,根据摘要过程中使用了多少外部信息,根据摘要过程,例如摘要等各种区别。
(G。Sizov(2010)。基于提取的自动摘要:摘要技术的理论和经验研究
让我们看一下文本摘要领域的主要研究主题,并思考该领域的哪种挑战。
多 /长文档摘要
如前所述,摘要任务是将不可理解的文本更改为可理解的信息。因此,原始文本或多个来源文档的摘要越长,不是一个文档,摘要的实用性越多。问题在于,同时,摘要的困难也增加了。
因此,原始文本越长,计算复杂性的增加就越快。在最近的基于神经网络的方法(包括变压器)中,这比过去的统计方法(例如Textrank)更为关键问题。其次,原始文本的时间越长,内容核心的核心越多,即噪声。确定什么是噪音和内容丰富的内容并不容易。最后,长文本和各种来源同时具有各种观点和内容,因此很难创建一个涵盖它的摘要。
多文档摘要(MDS)
MDS是多个文件的摘要。乍一看,要总结各种作者不同观点的文章,而不是总结一个文档,该文档从一致的趋势和观点中描述一个主题。当然,即使在MDS的情况下,它通常也基于涉及类似主题的同一集群文档,但是在许多文档中识别重要信息并过滤了Outluge信息并不容易。
总结某些产品的评论的任务是最容易想到的MD的一个例子。该任务通常称为意见摘要,其特征是短期长度和主观性。创建Wiki文档的工作也可以视为MDS。刘等。 (2018年)是Wiki文档上网站文本的原始文本,这是原始文本,这被认为是摘要,它创建了Wiki创建模型。
长文件摘要
刘等。 (2018)是一种接受长文本作为输入,创建外推摘要,仅使用重要句子并将其用作模型输入的统计方法。另外,为了减少变压器计算量,输入分为块单元,此时,1D卷积使用的方法使用了减少单个注意力键和值的数量。 Big Bird(2020)论文引入了稀疏的赋形机制(线性),而不是所有现有单词的组合以减少变压器的计算。结果,相同的性能硬件总结了长达八倍的长度。
另一方面,Gidiotis&Tsoumakas(2020)试图接近分界线,这并不能一次解决长期摘要问题,并将其变成几个小文本摘要。通过将原始文本和目标摘要更改为多个小较小的源目标对来训练模型。在推论中,我们通过此模型汇总了部分摘要输出,以创建一个完整的摘要。
绩效提高
您如何创建更好的摘要?
转移学习
最近,在NLP中使用预训练模型几乎已成为默认设置。那么,我们应该必须创建哪种结构来创建一个可以在文本摘要中显示出更好性能的预先模型?我应该有什么对象?
在Pegasus(2020)中,GSG(GAP句子生成)方法选择了一个基于Rouge分数认为重要的句子,假定与文本摘要过程更相似,并且反对意见将显示更高的性能。当前的SOTA模型BART(2020)(双向和自动回归变压器)以自动编码器的形式学习,该自动编码器将噪声添加到某些输入文本并将其恢复为原始文本。
知识增强的文本生成
在文本到文本任务中,通常很难单独使用原始文本生成所需的输出。因此,通过为模型以及原始文本提供各种知识,试图提高性能。这些知识范围的来源或提供在各种类型的关键字,主题,语言特征,知识库,知识范围和接地文本方面有所不同。
例如,TAN,QIN,XING和HU(2020)提供了一个通用的峰顶数据集来转换多个基于方面的摘要,并提供了与给定方面相关的更多丰富信息。使用Wikipedia。如果您想进一步了解更多,Yu等人。阅读(2020)撰写的调查文件。
后编辑圆环
立即创建一个好的摘要会很高兴,但这并不容易。那么,为什么不创建摘要,然后以各种标准进行审查和修改呢?
例如,CAO,Dong,Wu和Cheung(2020)提出了一种通过在生成的摘要中应用预先的神经校正器模型来减少事实错误的方法。
此外,还有许多尝试应用**图神经网络(GNN)**的尝试,最近一直受到很多关注。
数据稀缺问题
文本摘要是一项需要大量时间的任务,对于人类而言,这并不容易。因此,与其他任务相比,创建标记的数据集的成本相对较大,当然,缺乏培训数据。
除了使用先前提到的预处理模型的转移学习方法外,我们还以无监督的学习或强化学习方法学习或尝试了几次学习方法。
自然,制作良好的摘要数据也是一个非常重要的研究主题。特别是,当前许多相关的数据集都以英语的新闻类型偏见。结果,正在创建多语言数据集,例如Wikilingua和Mlsum。有关更多信息,请查看MLSUM:多语言摘要语料库。
公制/评估方法
我早些时候写了一个“好”的表情。什么是“好的摘要”? Brazinskas,Lapata和Titov(2020)根据良好摘要的判断使用以下五件事。
问题在于测量这些部分并不容易。文本摘要中最常见的性能测量指标是胭脂分数。 Rouge分数中有各种各样的变体,但基本上是“生成的摘要和参考摘要的单词如何?”这意味着相似,但是如果您的形式不同或单词订单更改,即使是更好的摘要,也可以获得较低的分数。特别是,试图提高胭脂分数,可能会损害摘要的表达多样性。这就是为什么许多论文以昂贵的钱和胭脂分数提供其他人类评估结果的原因。
Lee等。 (2020)提出了一个rdass(参考和文档意识语义分数),这与文本和参考摘要的相似之处,然后由基于向量的类似道路进行衡量。预计这种方法将提高韩国语言评估的准确性,该方法结合了单词和各种形态,以表达各种含义和语法功能。 Kryściński,McCann,Xiong和Socher(2020)提出了评估事实一致性的弱监督,基于模型的方法。
可控文本生成
关于给定文件只有一个最好的摘要吗?不会。具有不同倾向的人可能更喜欢同一文本的不同摘要文本。即使您是同一个人,您想要的摘要也将取决于总结或情况的目的。这种根据用户指定的条件将输出调整为所需形式的方法称为可控文本生成。与通用摘要相比,您可以提供个性化的摘要,该摘要为给定文档创建相同的摘要。
生成的摘要不仅应该易于理解和价值,而且还与您在一起的条件密切相关。
f(text, condition ) = comprehensible information that meets the given conditions可理解信息
我可以在摘要模型中添加什么条件?您如何创建适合该条件的摘要?
基于方面的摘要
总结AirPod用户评论时,您可能需要通过将声音质量,电池和设计分配来汇总每一方面。或者,您可能想调整文章中的写作风格或情感。在此原始文本中,仅总结与特定方面或特征有关的信息的工作称为基于方面的摘要。
以前,仅在主要用于模型学习的预定义方面起作用的模型现在试图允许进行任意方面的推理,而这些方面并未用于学习,例如TAN,QIN,QIN,XING和HU(2020)。
查询集中摘要(QFS)
如果条件是查询,则称为QFS。查询主要是自然语言,因此主要的任务是如何很好地执行这些各种表达方式并与原始文本匹配。它与我们知道的质量检查系统非常相似。
更新摘要
人类是继续学习和成长的动物。因此,今天的某些信息的价值可能与一周后的价值完全不同。我已经经历过的文档中内容的价值将被降低,尚未经历的新内容仍然具有很高的价值。从这个角度来看,称为“更新摘要” ,以创建与用户以前经历的文档内容相似的新内容的新摘要。
Ctrlsum使用文本采用各种关键字或描述性提示,以调整生成的摘要。这是一个更通用的可使用的可控文本摘要模型,因为它显示出与在培训阶段未明确学习的关键字或提示所控制的结果相同的结果。您可以通过Koh Hyun -Woong的摘要库轻松使用它。
除此之外,还尝试创建适合对话摘要的摘要模型的各种尝试,而不是**模型轻量级等典型的DL主题,以及对话的摘要,而不是诸如新闻或Wikipedia之类的结构化文本。有主题。
如果您知道文本摘要字段中的以下内容,则可以更轻松地学习。
了解NLP基本概念
变压器/BERT结构和训练前客观理解
许多最新的NLP论文都是基于几种预先了解的模型,包括基于变形金刚的Bert,以及Roberta和T5,这些模型是该BERT的变体。因此,如果您了解他们的示意性结构和预训练目标,那么这对于阅读或实施论文是一个很大的帮助。
文本摘要基本概念
图神经网络(GNN)
机器翻译(MT)
MT是自SEQ2SEQ出现以来NLP字段中最活跃的任务之一。如果您将摘要过程视为将一个文本转换为不同类型文本的过程,则可以将其视为一种MT,那么与MT相关的研究和想法很可能在摘要字段中借用或应用。
| 年 | 纸 | 关键字 |
|---|---|---|
| 2004 模型 | Textrank :将命令纳入文本 R. Mihalcea,P。Tarau 它是提取领域的经典,仍然是活跃的。假设文档中的重要句子(IE,摘要中包含)是Pagerank算法,即Google搜索引擎的初始想法,假设它将与其他句子具有很高的典型性。每个句子都配置了句子级的加权图,以计算文档中的另一句话的相似性,并在摘要中包括此高权重句。 没有单独的学习数据,基于统计的无监督学习方法可以是合理的,并且算法清晰易于理解。 - [库] Gensim.summarization(只有3.x版本。从版本4.x删除),pytextrank - [理论/代码] Lovit。使用文本trank和核心句子提取的关键字提取 | ext, 基于图的(Pagerank), 无监督 |
| 2019 模型 | Bertsum :带有预言编码器(OfficeIAD)的文本摘要 Yang Liu,Mirella Lapata / Emnlp 2019 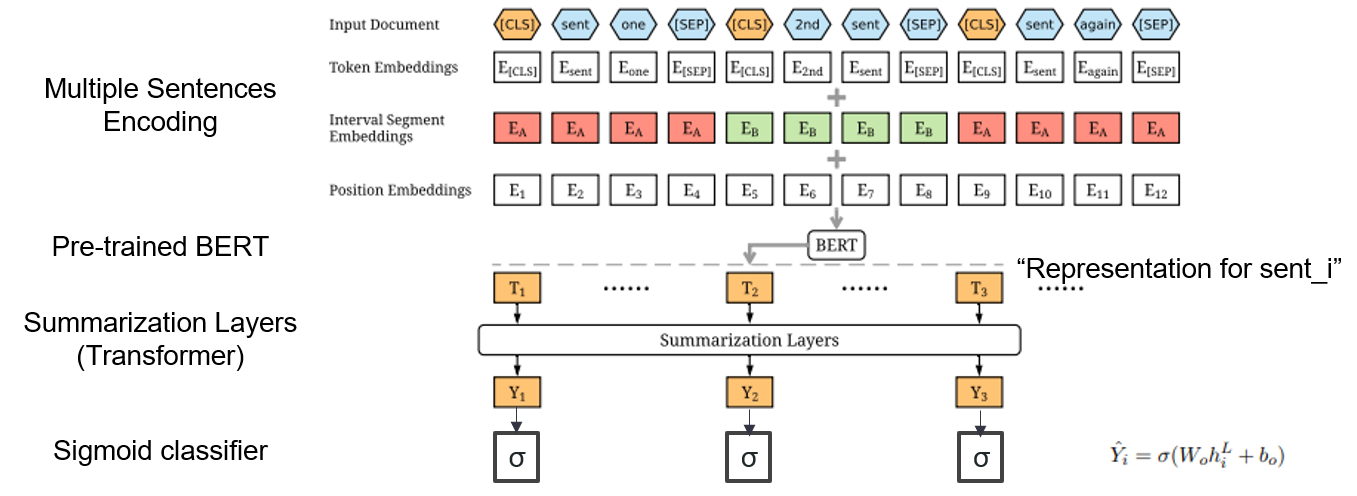 我如何在摘要中使用预训练的BERT? 我如何在摘要中使用预训练的BERT?Bertsum建议修改后的输入嵌入,将[Cls]令牌插入每个句子的前面,并添加间隔段嵌入,以在一个输入中添加多个句子。 EXT模型使用BERT上具有变压器层的编码器结构,ABS模型使用EXT模型上的6层变压器解码器的编码器码头模型。 - [评论] Lee Jung -Hoon(Koreauniv DSBA) - [韩国人] Kobertsum | ext/abs, BERT+变压器, 2阶段的微调 |
| 2019 预训练模型 | 巴特:自然语言生成,翻译和理解的序列前训练序列前训练 Mike Lewis,Yinhan Liu,Naman Goyal,Marjan Ghazvininejad,Abdelrahman Mohamed,Omer Levy,Ves Stoyanov,Luke Zettlemoyer / ACL 2020 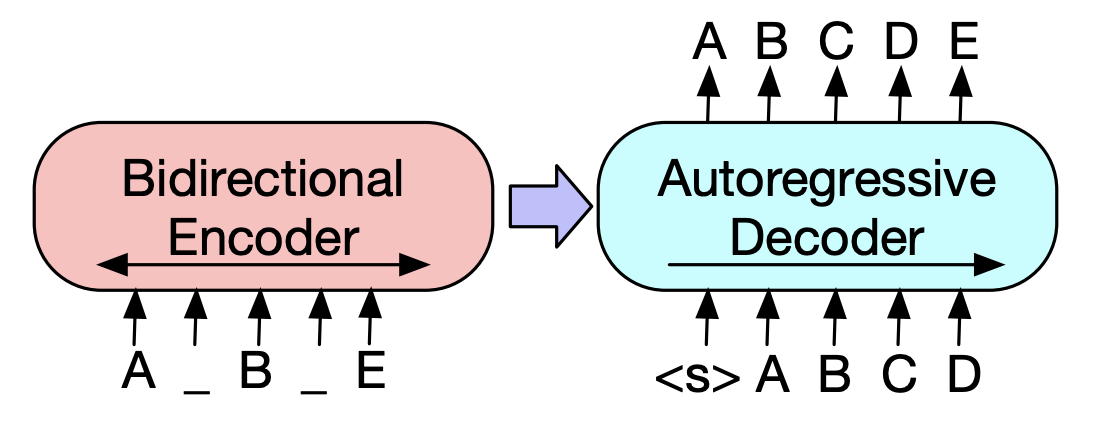 Bert是双向编码器,对生成任务较弱,而GPT的缺点是,它不会通过自动回归模型获得双向信息。 Bert是双向编码器,对生成任务较弱,而GPT的缺点是,它不会通过自动回归模型获得双向信息。BART具有将它们结合在一起的SEQ2SEQ形式,因此您可以在一个模型中尝试各种否定的技术。结果,文本填充(将文本跨度更改为一个掩码令牌),句子改组(随机混合句子)显示了超过摘要领域Ki Sota模型的性能。 - [韩语] SKT T3K。科巴特 - [评论] Jin Myung -Hoon_Video,lim Yeon -soo_ jiwung Hyun_撰写 | 腹部, seq2seq, Denoising AutoCoder, 文字填充 |
| 2020 模型 | 火柴:提取摘要作为文本匹配(Office) 明·宗,李·刘,伊兰·陈,王王,Xipeng Qiu,Xuanjing Huang / acl 2020 - [评论] Yoo Kyung(Koreauniv DSBA) | 分机 |
| 2020 技术 | 总结任何方面的文本:知识知识的弱监督方法(官方代码) Bowen Tan,Lianhui Qin,Eric P. Xing,zhiting hu / emnlp 2020 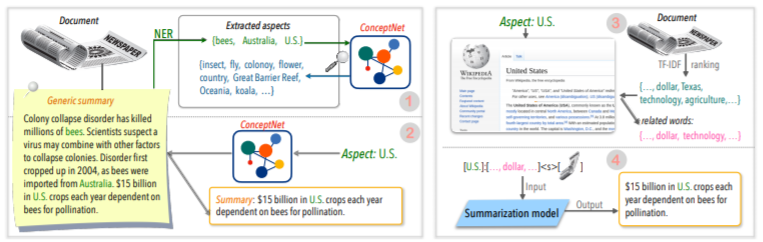 基于方面的摘要是一项不容易的任务,因为它仅在数据的预定方面运行,即使您学习了模型,也可以学到,2)缺乏多个基于方面的摘要数据。 本文利用外部知识来源解决此问题。 - 通过两个步骤将通用摘要转换为基于多个方面的摘要。首先,为了增加从通用摘要中提取的实体是种子,并从concepnet提取到其邻居,并将每个实体视为一个方面。我们再次使用concepnet为每个方面创建psedo摘要。提取连接到Concepnet中相应方面的周围实体,并仅提取一般摘要中包含它们的句子。这被认为是该实体(方面)的摘要。 - Wikipedia用于传递与模型给定方面相关的更多丰富信息。具体而言,在文档中出现的单词中,文档中的TF-IDF分数很高,同时,与此同时,Wikipedia页面中10个单词的列表与该方面相对应,并与模型输入相对应。 通过这种方式,使用较小的数据的任意方面也非常适合进行调整预先介绍模型(BART)。 | 基于方面的, 知识丰富 |
| 2020 审查 | 我们很快发短信摘要? Dandan Huang,Leyang Cui,Sen Yang,Guangsheng Bao,Kun Wang,Jun Xie,Yue Zhang / emnp 2020 除胭脂评分外,根据与准确性和流利度有关的8个指标(Polytope)评估了10个代表性摘要模型。总结结果, - 基于规则的传统方法仍然有效作为基线。 在类似的设置下,EXT模型通常在忠实和事实矛盾方面表现出更好的表现。主要的缺点是提取模型的不可行性,而抽象模型的遗漏和内在幻觉。 - 除了重复问题之外,更复杂的结构(例如用于创建句子表示的变压器)不是很有帮助。 - 副本(指针生成器)是一个复制的细节,它通过混合以及不准确性的固有来有效地解决了级别的重复问题。但是倾向于在一定程度上引起冗余。 覆盖范围很大,这减少了重复错误(重复),但同时增加了添加和不准确的固有错误 - 杂交模型(在EXT之后是ABS)非常适合召回,但是不准确误差可能存在问题,因为它通过一些原始文本(提取的片段)生成摘要。 与仅编码器模型(bertsamextabs)相比,预训练,尤其是编码器模型(BART)在摘要中非常有效。这表明,对所有理解和创建的所有理解和创建对于内容选择和组合非常有用。同时,尽管大多数ABS模型都集中在正面句子上,但Bart正在研究所有原始文本,这似乎是句子在预先介绍过程中的效果。 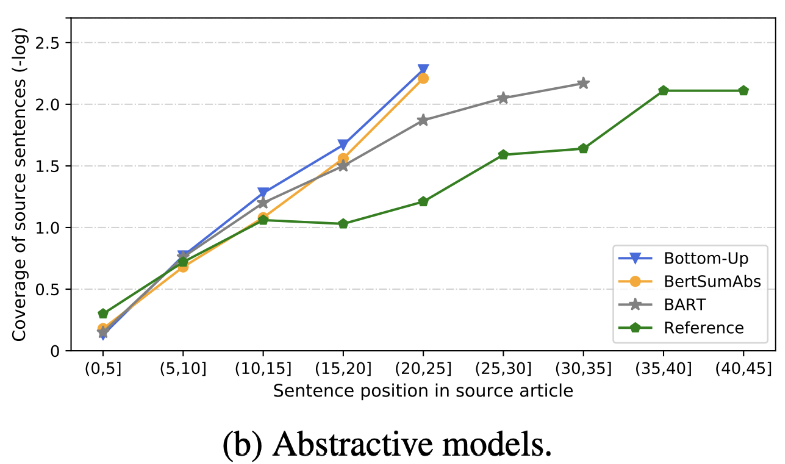 - [评论] Kim Han -Gil,Heo Hoon | 审查 |
| 2020 模型 | CTRLSUM :迈向通用可控文本摘要(官方代码) Junxian He,WojciechKryściński,Bryan McCann,Nazneen Rajani,Caiming Xim CTRLSUM是一个可控的文本摘要模型,它允许您调整通过关键字或描述性提示生成的摘要语句。 培训:为了通过修改一般摘要数据来创建一个基于关键字的可控制摘要数据集,请选择与摘要最相似的子序列,并在此处提取关键字。将其放入文档的输入中,然后完成预启动巴特。 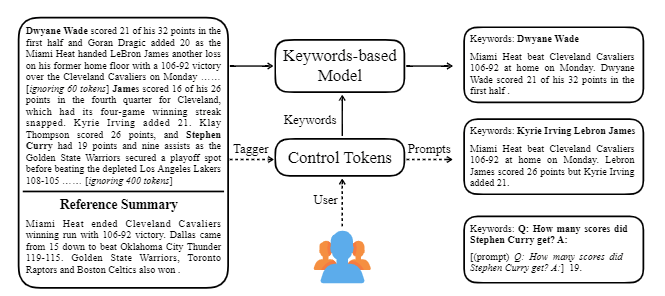 - 启示:如下图所示,您可以添加摘要的摘要,例如创建特定实体的摘要,调整摘要长度或对问题的回答。值得注意的是,它好像不是在建模阶段明确学习此类提示一样,但是它好像是在理解提示并产生摘要一样起作用。类似于GPT-3。 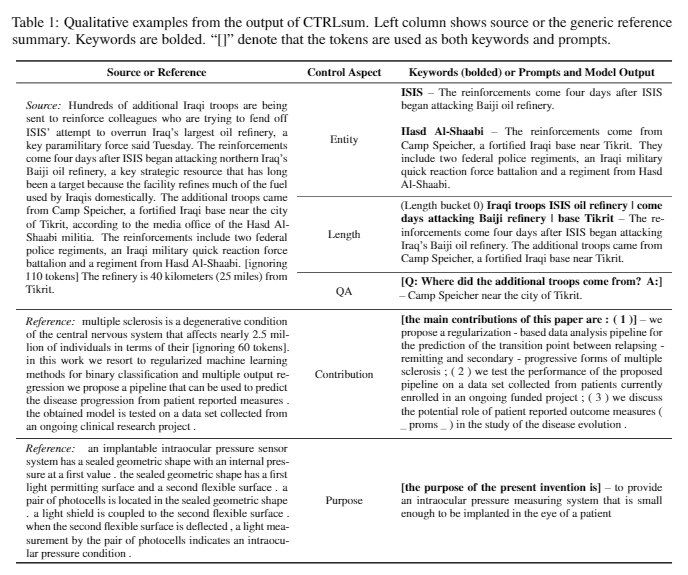 - [库]基于可控摘要的ctrlsum的软件包 | 可控, 巴特 |
纸摘要:有关文本摘要的最新论文
用代码的论文:最新论文
EMNLP 2020论文 - 夏季化
实际上,我们总结了创建和练习摘要模型所需的代码,数据和preitrain模型。它主要是韩国数据,对于与英语相关的材料,请参阅论文项目中每个论文的代码部分。
下面使用的弱的含义如下。
w :单词数的平均值; s :平均句子的平均值
示例) 13s/214w → 1s/26w意味着它提供了一个摘要文本,该文本由13个句子(平均214个单词)和平均句子(平均26个单词)组成。
abs摘要; ext :提取性摘要
| 数据集 | 域 /长度 | 体积 (一对) | 执照 |
|---|---|---|---|
| 每个人的单词文件摘要 简短新闻文字的标题,3句ABS和Ext Summay 每个人的所有单词都与ID与报纸马相结合,您可以获得与字幕,媒体,日期和主题有关的其他信息。 | 消息 -origin→3s(ABS); 3s(ext) | 13,167 | 韩国国家学院 (个人合同) |
| AIHUB文档摘要文本 报纸文章,贡献,杂志文章和法院审查的ABS和Ext Summay - [EDA]数据EDA笔记本 - 韩国文档提取摘要摘要和创建摘要AI竞赛(〜20.12.09) | - 报纸第300,000条,60,000款,10,000份杂志,法院裁决30,000 13S/214W→1S/26W(ABS); 3S/55W(EXT) | 400,000 | aihub (个人合同) |
| aihub-summary 所有的ABS摘要和部分的学术论文和专利规格 | - 学术论文,专利规格 -origin→ABS | 350,000 | aihub (个人合同) |
| Aihub-Book数据摘要 关于各种主题的原始书籍的ABS摘要 | - 长期,生命,税收,环境,社区发展,贸易,经济,劳动等。 -300-1000个字符→ABS | 200,000 | aihub (个人合同) |
| SAE4K | 50,000 | cc-by-sa-4.0 | |
| 科幻-News-SUM-KR-50 | 新闻(IT/科学) | 50 | 麻省理工学院 |
| Wikilingua :多语言抽象摘要数据集(2020) 根据手动网站Wikihow,韩语和英语等18种语言 - 纸,合作笔记本 | - 如何进行文档 -391W→39W | 12,189 (Kor总共770,087) | 2020年, CC BY-NC-SA 3.0 |
| 数据集 | 域 /长度 | 体积 | 执照 |
|---|---|---|---|
| Scisummnet (纸) 为ACL(NLP)研究提供了三种类型的摘要 -cl-scisumm 2019-task2(回购,纸) -cl-scisumm @ emnlp 2020-task2(repo) | - 研究论文 (计算语言学家,NLP) 4,417W→110W(纸张摘要); 2s(引用); 151W(ABS) | 1,000(ABS/ EXT) | CC BY-SA 4.0 |
| Longsumm NLP 및 ML 분야 Research paper에 대한 상대적으로 장문의 summary(관련 blog posts 기반 abs, 관련 conferences videos talks 기반 ext) 제공 - LongSumm 2020@EMNLP 2020 - LongSumm 2021@ NAACL 2021 | - Research paper(NLP, ML) - origin → 100s/1,500w(abs); 30s/ 990w(ext) | 700(abs) + 1,705(ext) | Attribution-NonCommercial-ShareAlike 4.0 |
| CL-LaySumm NLP 및 ML 분야 Research paper에 대해 비전문가를 위한 쉬운(lay) summary 제공 - CL-LaySumm @ EMNLP 2020 | - Research paper(epilepsy, archeology, materials engineering) - origin → 70~100w | 600(abs) | 개별약정 필요([email protected] 로 이메일을 송부) |
| Global Voices : Crossing Borders in Automatic News Summarization (2019) - Paper | - 消息 - 359w→ 51w | ||
| MLSUM : The Multilingual Summarization Corpus CNN/Daily Mail dataset과 유사하게 news articles 내 highlights/description을 summary로 간주하여 English, French, German, Spanish, Russian,Turkish에 대한 summary dataset을 구축 - Paper, 이용(huggingface) | - 消息 - 790w→ 56w (en 기준) | 1.5M(abs) | non-commercial research purposes only |
| 模型 | Pre-training | 用法 | License |
|---|---|---|---|
| BERT(multilingual) BERT-Base(110M parameters) | - Wikipedia(multilingual) - WordPiece. - 110k shared vocabs | - BERT-Base, Multilingual Cased 버전 권장( --do_lower_case=false 옵션 넣어주기)- Tensorflow | 谷歌 (Apache 2.0) |
| KOBERT BERT-Base(92M parameters) | - 위키백과(문장 5M개), 뉴스(문장 20M개) - SentencePiece - 8,002 vocabs(unused token 없음) | - PyTorch - KoBERT-Transformers(monologg)를 통해 Huggingface Transformers 라이브러리로 이용 가능, DistilKoBERT 이용 가능 | SKTBrain (Apache-2.0) |
| KorBERT BERT-Base | - 뉴스(10년 치), 위키백과 등 23GB - ETRI 형태소분석 API / WordPiece(두 버전을 별도로 제공) - 30,349 vocabs - Latin alphabets: Cased - [소개] 임준(ETRI). NLU Tech Talk with KorBERT | - PyTorch, Tensorflow | ETRI (개별 약정) |
| KcBERT BERT-Base/Large | - 네이버 뉴스 댓글(12.5GB, 8.9천만개 문장) (19.01.01 ~ 20.06.15 기사 중 댓글 많은 기사 내 댓글과 대댓글) - tokenizers의 BertWordPieceTokenizer - 30,000 vocabs | Beomi (MIT) | |
| KoBART BART(124M) | - 위키백과(5M), 기타(뉴스, 책, 모두의 말뭉치 (대화, 뉴스, ...), 청와대 국민청원 등 0.27B) - tokenizers의 Character BPE tokenizer - 30,000 vocabs( 포함) - [Example] seujung. KoBART-summarization(Code, Demo) | - 요약 task에 특화 - Huggingface Transformers 라이브러리 지원 - PyTorch | SKT T3K (modified MIT) |
| 年 | 纸 |
|---|---|
| 2018 | A Survey on Neural Network-Based Summarization Methods Y. Dong |
| 2020 | Review of Automatic Text Summarization Techniques & Methods Widyassari, AP, Rustad, S., Shidik, GF, Noersasongko, E., Syukur, A., & Affandy, A. |
| 2020 | A Survey of Knowledge-Enhanced Text Generation Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, Meng Jiang |
| 年 | 纸 | Keywords |
|---|---|---|
| 1958年 | Automatic creation of literature abstracts PH Luhn | gen-ext |
| 2000 | Headline Generation Based on Statistical Translation M. Banko, VO Mittal, and MJ Witbrock | gen-abs |
| 2004 | LexRank : graph-based lexical centrality as salience in text summarization G. Erkan, and DR Radev, | gen-ext |
| 2005 | Sentence Extraction Based Single Document Summarization J. Jagadeesh, P. Pingali, and V. Varma | gen-ext |
| 2010 | Title generation with quasi-synchronous grammar K. Woodsend, Y. Feng, and M. Lapata, | gen-ext |
| 2011 | Text summarization using Latent Semantic Analysis MG Ozsoy, FN Alpaslan, and I. Cicekli | gen-ext |
| 年 | 纸 | Keywords |
|---|---|---|
| 2014 | On using very large target vocabulary for neural machine translation S. Jean, K. Cho, R. Memisevic, and Yoshua Bengio | gen-abs |
| 2015 模型 | NAMAS : A Neural Attention Model for Abstractive Sentence Summarization (Code) AM Rush, S. Chopra, and J. Weston / EMNLP 2015 기존의 문장 선택 및 조합 방식을 넘어서기 위해 기 Seq2Seq에 target-to-source attention을 도입하여 abstractive summary를 생성합니다. | abs Seq2Seq with att |
| 2015 | Toward Abstractive Summarization Using Semantic Representations Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 模型 | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 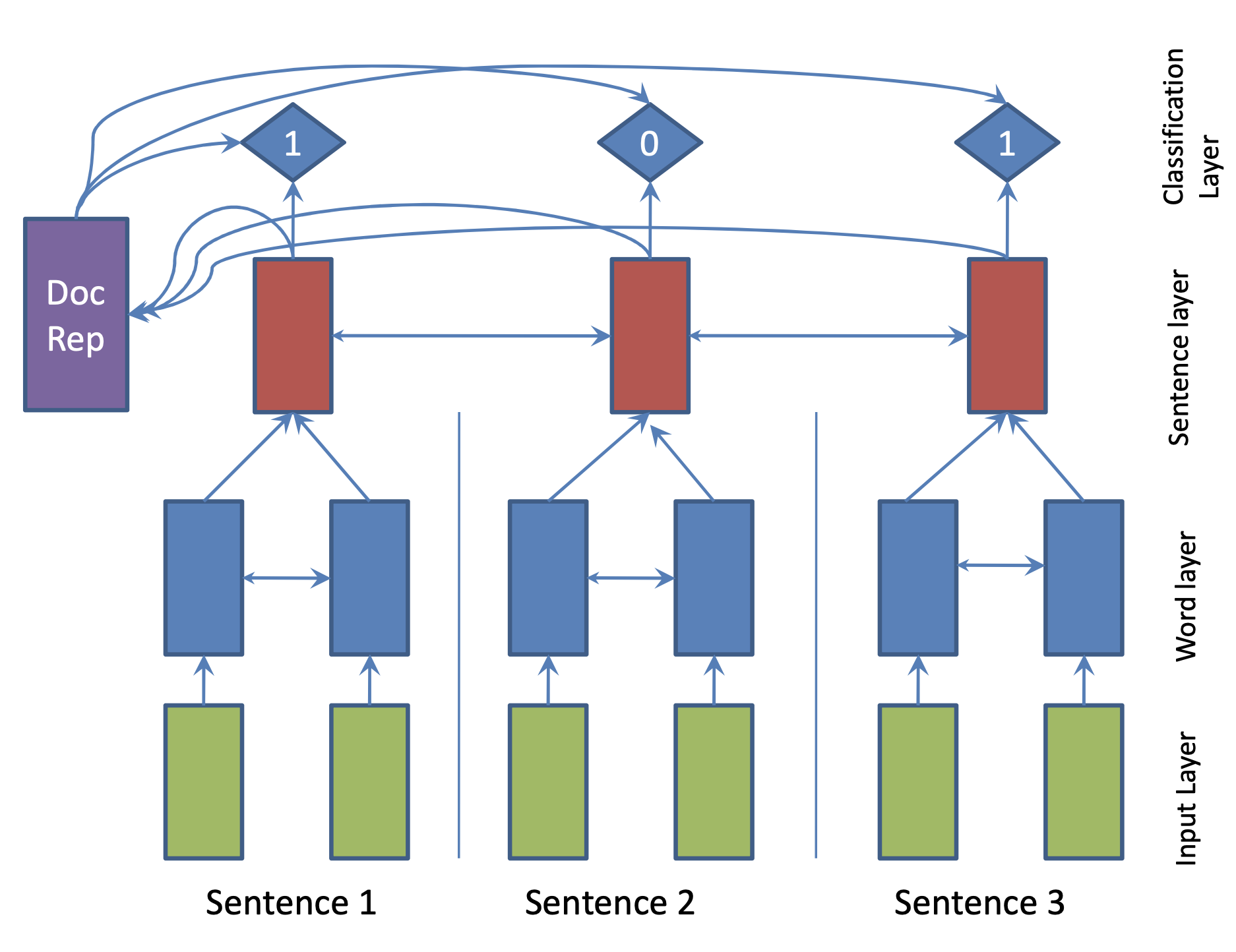 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 Model, 技术 | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 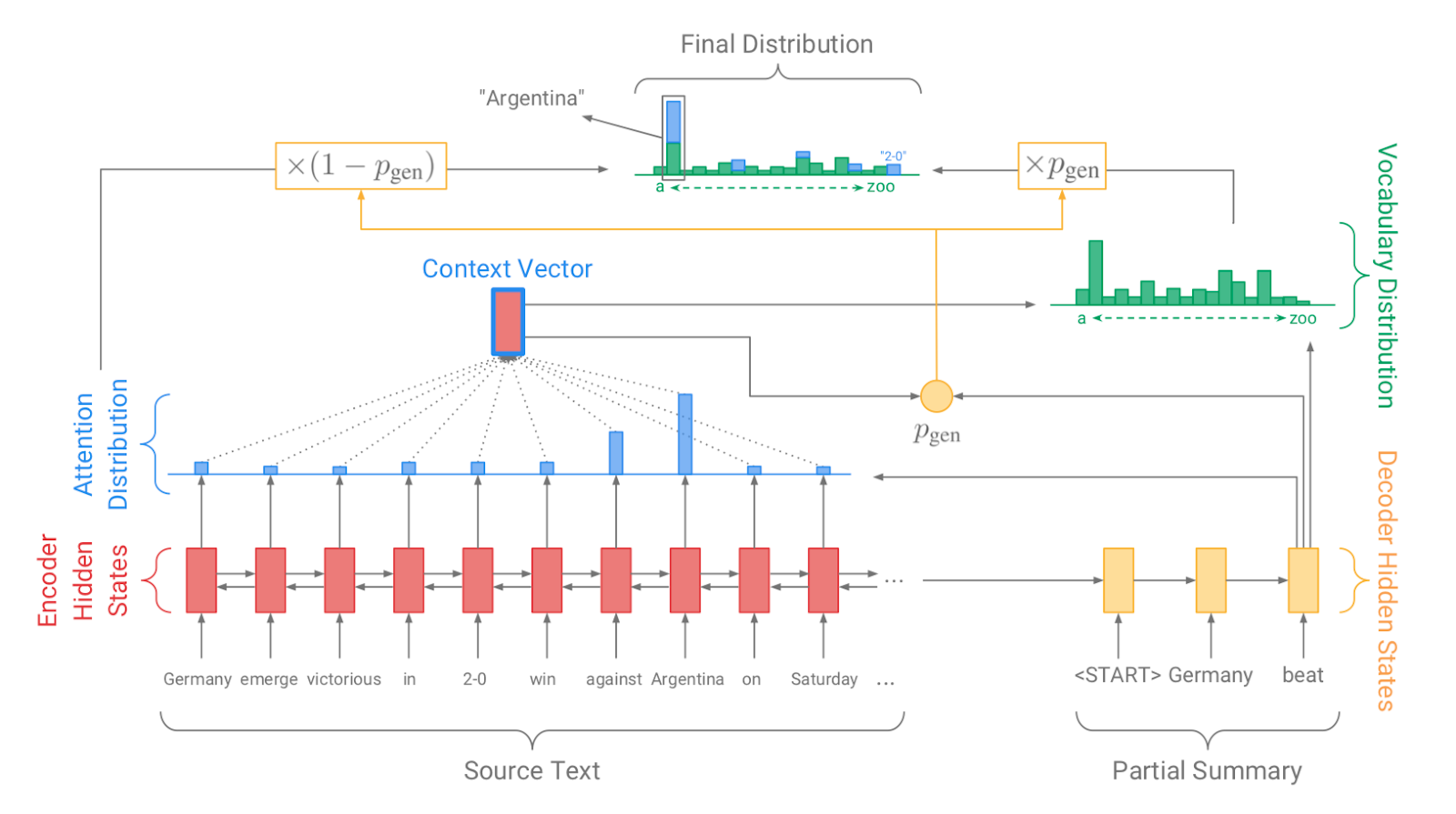 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 模型 | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 模型 | Bottom-Up Abstractive Summarization Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, hybrid, bottom-up attention |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 模型 | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 模型 | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 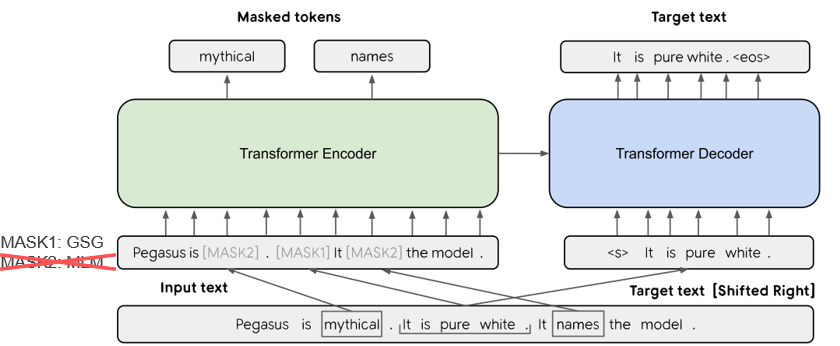 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 模型 | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


