Text Summarization Repo
1.0.0
Di antara NLP, ini adalah ruang yang mengumpulkan data kualitas yang terkait dengan bidang ringkasan teks. Saya ingin menjadi panduan yang baik bagi mereka yang tertarik dengan ringkasan teks.
Pertama -tama, kami memahami topik terperinci apa yang dirangkum teks tersebut disusun dan melihat makalah utama yang telah memimpin bidang ini. Sejak itu, kami telah mendaftarkan model kode, dataset, dan pra -crane yang diperlukan untuk membuat model ringkasan teks langsung.
Intro to Text Summarisasi
DOKUMEN
Sumber daya
Yang lain
Berry, Dumais, & O'Brien (1995) mendefinisikan ringkasan teks sebagai berikut:
Ringkasan teks adalah proses penyulingan informasi paling penting dari teks untuk menghasilkan tugas dan pengguna tertentu
Ini adalah proses menyempurnakan hanya informasi penting di antara teks yang diberikan dalam sebuah kata. Di sini, ekspresi pemurnian dan pentingnya penting adalah ekspresi yang agak abstrak dan subyektif, jadi saya pribadi ingin mendefinisikannya sebagai berikut.
f(text) = comprehensible information
Dengan kata lain, ringkasan teks adalah untuk mengubah teks asli menjadi informasi yang mudah dan berharga . Manusia sulit dilihat sekilas informasi teks, yang panjang atau dibagi menjadi beberapa dokumen. Terkadang Anda tidak tahu banyak istilah profesional. Sangat berharga untuk mencerminkan teks -teks ini menjadi bentuk yang sederhana dan mudah -untuk -memahami sambil mencerminkan teks asli dengan baik. Tentu saja, apa yang benar -benar bermanfaat dan bagaimana mengubahnya akan bervariasi tergantung pada tujuan meringkas atau selera pribadi.
Dari sudut pandang ini, dapat dikatakan bahwa teks tersebut merangkum tidak hanya tugas -tugas yang membuat teks seperti menit, tajuk insinyur koran, abstrak kertas, dan resume, serta tugas yang mengubah teks menjadi grafik atau gambar. Tentu saja, karena ini bukan hanya ringkasan, itu adalah ringkasan teks , sehingga sumber ringkasan terbatas dalam bentuk teks. (Ringkasan ringkasan adalah karena tidak hanya teks atau video serta teks. Sebagai contoh, contoh sebelumnya adalah captioning gambar, contoh terakhir adalah ringkasan video. Mempertimbangkan tren pembelajaran mendalam baru -baru ini ketika batas antara visi dan NLP semakin buram, mungkin tidak ada artinya untuk menempatkan 'teks' sebagai awalan.)
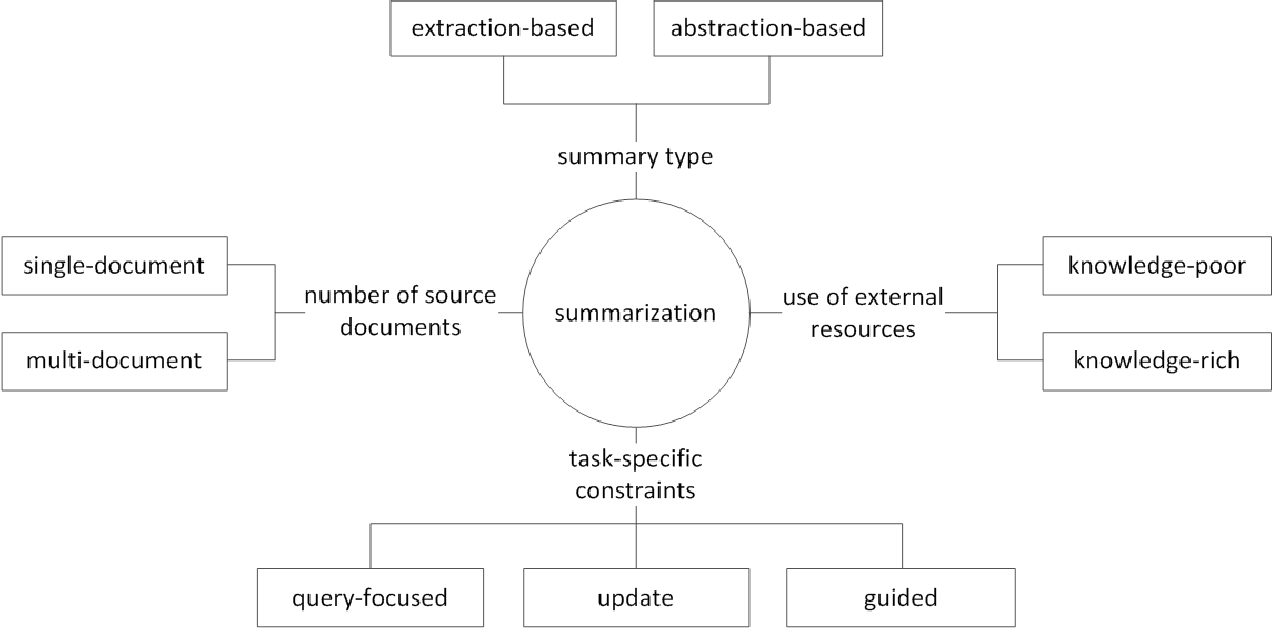
Secara umum, tugas ringkasan teks dibagi menjadi ringkasan ekstraktif (selanjutnya disebut sebagai ext) dan ringkasan abstraktif (ABS), tergantung pada bagaimana mereka menghasilkan ringkasan. (Gudivada, 2018)
Metode Ekstraktif Pilih subset dari kata, frasa, atau kalimat yang ada dalam teks asli untuk membentuk ringkasan. Sebaliknya, metode abstraktif pertama -tama membangun representasi semantik internal dan penggunaan teknologi generasi bahasa alami.
Ext biasanya mencetak pentingnya kalimat, dan kemudian memilih dan menggabungkannya untuk membuat ringkasan. Ini mirip dengan tugas mengecat stabilo saat membaca. ABS , di sisi lain , didasarkan pada teks asli, tetapi merupakan metode NLG (pembuatan bahasa alami) yang menghasilkan teks baru . Ext tidak mungkin menyertakan ekspresi yang terbatas pada ekspresi karena teks dalam teks asli. ABS, di sisi lain, memiliki keuntungan bahwa ada kemungkinan menciptakan ekspresi yang belum pernah terjadi sebelumnya karena harus membuat teks baru dalam model, tetapi memiliki pendekatan yang lebih fleksibel.
Selain itu, sesuai dengan jumlah teks asli, sesuai dengan bentuk teks ringkasan dokumen tunggal/multi , kata kunci/ringkasan kalimat , sesuai dengan berapa banyak informasi eksternal yang digunakan dalam proses ringkasan , menurut proses ringkasan ada berbagai perbedaan seperti ringkasan.
(G. Sizov (2010). Ringkasan Otomatis Berbasis Ekstraksi: Investigasi Teoritis dan Empiris Teknik Peringkasan
Mari kita lihat topik penelitian utama di bidang ringkasan teks dan pikirkan tentang tantangan seperti apa di bidang ini.
Ringkasan dokumen multi / panjang
Seperti yang disebutkan sebelumnya, tugas ringkasan adalah mengubah teks yang tidak dapat dipahami menjadi informasi yang dapat dipahami. Oleh karena itu, semakin lama teks asli, atau ringkasan dokumen berbagai sumber, bukan satu dokumen, semakin banyak kegunaan ringkasan meningkat. Masalahnya adalah bahwa pada saat yang sama, kesulitan ringkasan juga meningkat.
Untuk alasan ini, semakin lama teks asli, semakin cepat kompleksitas komputasi meningkat. Ini adalah masalah yang jauh lebih kritis dalam metode berbasis jaringan saraf baru -baru ini termasuk transformator daripada dalam metode statistik seperti Textrank di masa lalu. Kedua, semakin lama teks asli, semakin bukan inti dari isinya, yaitu noise. Tidak mudah untuk mengidentifikasi apa itu kebisingan dan apa yang informatif. Akhirnya, teks panjang dan berbagai sumber memiliki berbagai perspektif dan konten pada saat yang sama, sehingga sulit untuk membuat ringkasan yang menutupinya dengan baik.
Multi Documents Summarisasi (MDS)
MDS adalah ringkasan dari sejumlah dokumen . Sekilas, akan sulit untuk meringkas artikel dari berbagai perspektif dari berbagai penulis daripada merangkum dokumen yang menjelaskan satu tema dari tren dan sudut pandang yang konsisten. Tentu saja, bahkan dalam kasus MDS, biasanya didasarkan pada dokumen kluster yang sama yang membahas topik yang sama, tetapi tidak mudah untuk mengidentifikasi informasi penting dan memfilter informasi penginapan di antara banyak dokumen.
Tugas, yang merangkum ulasan tentang produk -produk tertentu, adalah contoh MDS yang paling mudah dipikirkan. Tugas ini, biasanya disebut ringkasan opini, ditandai dengan panjang teks pendek dan subjektivitas. Pekerjaan membuat dokumen wiki juga dapat dianggap sebagai MDS. Liu et al. (2018) adalah teks asli dari teks situs web pada dokumen wiki, yang merupakan teks asli, yang dianggap sebagai ringkasan, dan membuat model pembuatan wiki.
Ringkasan Dokumen Panjang
Liu et al. (2018) adalah cara statistik untuk menerima teks panjang sebagai input, menciptakan ringkasan ekstraksi, hanya menggunakan kalimat penting dan menggunakannya sebagai input dari model. Selain itu, untuk mengurangi volume komputasi transformator, input dibagi menjadi unit blok, dan pada saat ini, konvolusi 1-D menggunakan metode attensi yang mengurangi jumlah kunci dan nilai perhatian individu. Makalah Big Bird (2020) memperkenalkan mekanisme atensi yang jarang (linier) alih -alih kombinasi dari semua kata yang ada untuk mengurangi perhitungan transformator. Akibatnya, perangkat keras kinerja yang sama telah dirangkum hingga delapan kali lebih lama.
Gidiotis & Tsoumakas (2020), di sisi lain, berupaya mendekati divide-and-conquer, yang tidak menyelesaikan masalah ringkasan teks panjang sekaligus dan mengubahnya menjadi beberapa ringkasan teks kecil. Melatih model dengan mengubah teks asli dan ringkasan target ke beberapa pasangan target sumber kecil yang lebih kecil. Dalam inferensi, kami mengumpulkan ringkasan parsial output melalui model ini untuk membuat ringkasan lengkap.
Peningkatan Kinerja
Bagaimana Anda bisa membuat ringkasan yang lebih baik?
Transfer pembelajaran
Baru -baru ini, menggunakan model pretraining di NLP telah menjadi hampir default. Jadi jenis struktur apa yang harus kita miliki untuk membuat model prerealing yang dapat menunjukkan kinerja yang lebih baik dalam ringkasan teks? Objek apa yang harus saya miliki?
Dalam Pegasus (2020), metode GSG (GAP Kalimat), yang memilih kalimat yang dianggap penting berdasarkan skor Rouge, mengasumsikan bahwa yang lebih mirip dengan proses ringkasan teks dan keberatan akan menunjukkan kinerja yang lebih tinggi. Model SOTA saat ini, BART (2020) (transformator dua arah dan regresi otomatis), belajar dalam bentuk autoencoder yang menambahkan noise ke beberapa teks input dan mengembalikannya sebagai teks asli.
Generasi teks yang disempurnakan-knowedge
Dalam tugas teks-ke-teks, seringkali sulit untuk menghasilkan output yang diinginkan dengan teks asli saja. Jadi, ada upaya untuk meningkatkan kinerja dengan memberikan berbagai pengetahuan untuk model serta teks aslinya . Sumber atau ketentuan KnowEdge ini bervariasi dalam berbagai jenis kata kunci, topik, fitur linguistik, basis pengetahuan, grafik knowedge, dan teks ground.
Misalnya, Tan, Qin, Xing, & Hu (2020) memberikan dataset panggilan umum untuk mengonversi pluralitas ringkasan berbasis aspek, dan memberikan informasi yang lebih kaya terkait dengan aspek tertentu dengan aspek yang diberikan pada model. Gunakan wikipedia untuk. Jika Anda ingin tahu lebih banyak lagi, Yu et al. Baca makalah survei yang ditulis oleh (2020).
Corection pasca-pengeditan
Akan menyenangkan untuk menciptakan ringkasan yang baik sekaligus, tetapi tidak mudah. Jadi mengapa Anda tidak membuat ringkasan dan kemudian meninjau dan memodifikasinya dalam berbagai kriteria?
Misalnya, CAO, Dong, Wu, & Cheung (2020) menyarankan metode pengurangan kesalahan faktual dengan menerapkan model korektor saraf pretated ke ringkasan yang dihasilkan.
Selain itu, ada juga banyak upaya untuk menerapkan ** grafik Neural Network (GNN) **, yang telah menerima banyak perhatian baru -baru ini.
Masalah kelangkaan data
Ringkasan teks adalah tugas yang membutuhkan banyak waktu, yang tidak mudah bagi manusia. Oleh karena itu, dibandingkan dengan tugas -tugas lain, biaya yang relatif lebih besar untuk membuat dataset berlabel, dan tentu saja, ada kekurangan data untuk pelatihan.
Selain metode pembelajaran transfer menggunakan model pretraining yang disebutkan sebelumnya, kami belajar dalam metode pembelajaran pembelajaran atau penguatan yang tidak diawasi atau mencoba beberapa pendekatan pembelajaran .
Secara alami, membuat data ringkasan yang baik juga merupakan topik penelitian yang sangat penting. Secara khusus, banyak dataset terkait peringkasan saat ini bias dalam jenis berita dalam bahasa Inggris. Akibatnya, set data multibahasa seperti Wikilingua dan MLSUM sedang dibuat. Untuk informasi lebih lanjut, lihatlah MLSUM: Corpus peringkasan multibahasa.
Metode metrik / evaluasi
Saya menulis ekspresi hancur 'baik' sebelumnya. Apa itu 'ringkasan bagus'? Brazinskas, Lapata, & Titov (2020) menggunakan lima hal berikut berdasarkan penilaian ringkasan yang baik.
Masalahnya adalah tidak mudah untuk mengukur bagian -bagian ini. Indikator pengukuran kinerja yang paling umum dalam ringkasan teks adalah skor Rouge. Ada berbagai varian dalam skor Rouge, tetapi pada dasarnya 'Bagaimana kata dari kata ringkasan dan ringkasan referensi yang dihasilkan?' Ini berarti serupa, tetapi jika Anda memiliki bentuk yang berbeda atau jika urutan kata berubah, Anda bisa mendapatkan skor yang lebih rendah bahkan jika itu adalah ringkasan yang lebih baik. Secara khusus, mencoba meningkatkan skor Rouge, itu dapat mengakibatkan membahayakan keragaman ringkasan ekspresif. Inilah sebabnya mengapa banyak makalah memberikan hasil evaluasi manusia tambahan dengan uang mahal serta skor Rouge.
Lee et al. (2020) menyajikan skor semantik RDASS (referensi dan dokumen), yang serupa dengan ringkasan teks dan referensi, dan kemudian diukur dengan jalan serupa berbasis vektor. Metode ini diharapkan untuk meningkatkan keakuratan evaluasi bahasa Korea, yang menggabungkan kata -kata dan berbagai morfologi untuk mengekspresikan berbagai makna dan fungsi tata bahasa. Kryściński, McCann, Xiong, & Socher (2020) mengusulkan pendekatan berbasis model yang diawasi dengan lemah untuk mengevaluasi konsistensi faktual.
Pembuatan teks yang dapat dikendalikan
Apakah hanya ada satu ringkasan terbaik tentang dokumen yang diberikan? Itu tidak akan. Orang dengan kecenderungan yang berbeda dapat lebih suka teks ringkasan yang berbeda untuk teks yang sama. Bahkan jika Anda adalah orang yang sama, ringkasan yang Anda inginkan akan tergantung pada tujuan meringkas atau situasinya. Metode untuk menyesuaikan output ke formulir yang diinginkan sesuai dengan kondisi yang ditentukan oleh pengguna disebut pembuatan teks yang dapat dikendalikan . Anda dapat memberikan ringkasan yang dipersonalisasi dibandingkan dengan ringkasan generik yang menciptakan ringkasan yang sama untuk dokumen yang diberikan.
Ringkasan yang dihasilkan seharusnya tidak hanya mudah dipahami dan dihargai, tetapi juga terkait erat dengan kondisi yang Anda kumpulkan.
f(text, condition ) = comprehensible information that meets the given conditions
Kondisi apa yang dapat saya tambahkan ke model ringkasan? Dan bagaimana Anda bisa membuat ringkasan yang sesuai dengan kondisi itu?
Ringkasan berbasis aspek
Saat merangkum ulasan pengguna AirPod, Anda mungkin ingin merangkum masing -masing sisi dengan membagi kualitas suara, baterai, dan desain. Atau Anda mungkin ingin menyesuaikan gaya penulisan atau sentimen dalam artikel. Dalam teks asli ini , karya yang merangkum hanya informasi yang terkait dengan aspek atau fitur tertentu disebut ringkasan berbasis aspek .
Sebelumnya, hanya model yang hanya bekerja dalam aspek yang telah ditentukan, yang terutama digunakan untuk pembelajaran model, sekarang berusaha untuk memungkinkan penalaran aspek sewenang-wenang, yang tidak diberikan untuk belajar seperti Tan, Qin, Xing, & Hu (2020).
Perangkapan Fokus Permintaan (QFS)
Jika kondisinya kueri , itu disebut QFS. Kueri terutama adalah bahasa alami, jadi tugas utamanya adalah bagaimana melakukan berbagai ekspresi ini dengan baik dan mencocokkannya dengan teks asli. Ini sangat mirip dengan sistem QA yang kita kenal dengan baik.
Perbarui ringkasan
Manusia adalah hewan yang terus belajar dan tumbuh. Oleh karena itu, nilai hari ini untuk informasi tertentu dapat sangat berbeda dari nilai seminggu kemudian. Nilai konten dalam dokumen yang telah saya alami akan diturunkan, dan konten baru yang belum dialami masih akan memiliki nilai tinggi. Dari sudut pandang ini, ini disebut pembaruan ringkasan untuk membuat ringkasan baru konten baru yang mirip dengan konten dokumen yang dialami pengguna sebelumnya .
Ctrlsum mengambil berbagai kata kunci atau permintaan deskriptif dengan teks untuk menyesuaikan ringkasan yang dihasilkan. Ini adalah model ringkasan teks yang dapat dikendalikan yang lebih umum karena menunjukkan hasil yang sama dengan dikendalikan untuk kata kunci atau petunjuk yang tidak dipelajari secara eksplisit dalam tahap pelatihan. Anda dapat dengan mudah menggunakannya melalui Perpustakaan Summarizers Koh Hyun -Woong.
Selain itu, berbagai upaya untuk membuat model ringkasan yang cocok untuk peringkasan percakapan daripada topik DL khas seperti ** model ringan, serta ringkasan dialog daripada teks terstruktur seperti berita atau wikipedia. Ada topik.
Jika Anda tahu yang berikut di bidang Ringkasan Teks, Anda akan dapat belajar lebih mudah.
Memahami Konsep Dasar NLP
Struktur Transformer/Bert dan Pemahaman Tujuan Pra-Pelatihan
Banyak makalah NLP terbaru didasarkan pada beberapa model prerealing, termasuk Bert, berdasarkan Transformer, dan Roberta dan T5, yang merupakan varian dari Bert ini. Oleh karena itu, jika Anda memahami struktur skematis dan tujuan pra-pelatihan mereka, itu sangat membantu dalam membaca atau mengimplementasikan makalah.
Konsep Dasar Ringkasan Teks
Grafik Neural Network (GNN)
Terjemahan Mesin (MT)
MT adalah salah satu tugas paling aktif di bidang NLP karena munculnya SEQ2SEQ. Jika Anda melihat proses peringkasan sebagai proses mengubah satu teks menjadi jenis teks yang berbeda, itu dapat dilihat sebagai semacam MT, sehingga banyak studi dan ide terkait MT cenderung dipinjam atau diterapkan di bidang peringkasan.
| Tahun | Kertas | Kata kunci |
|---|---|---|
| 2004 Model | Textrank : Membawa pesanan ke dalam teks R. Mihalcea, P. Tarau Ini adalah klasik di sektor ekstraksi dan masih aktif. Dengan asumsi bahwa kalimat penting dalam dokumen (yaitu, termasuk dalam ringkasan) adalah algoritma PageRank, gagasan awal mesin pencari Google, dengan asumsi bahwa ia akan memiliki similitas tinggi dengan kalimat lain. Setiap kalimat mengkonfigurasi grafik tertimbang tingkat kalimat untuk menghitung kesamaan dengan kalimat lain dalam dokumen, dan termasuk kalimat berat yang tinggi ini dalam ringkasan. Metode pembelajaran tanpa pengawasan berbasis statistik dapat masuk akal tanpa data pembelajaran yang terpisah, dan algoritma jelas dan mudah dimengerti. - [PERPUSTAKAAN] GENSIM.Summarization (Hanya versi 3.x yang tersedia. Hapus dari versi 4.x), Pytextrank - [Teori/Kode] Lovit. Ekstraksi Kata Kunci Menggunakan TextTrank dan Ekstrak Kalimat Inti | Ext, Berbasis Grafik (PageRank), Tanpa pengawasan |
| 2019 Model | Bertsum : Ringkasan Teks dengan Encoders Pretated (Officeiad) Yang Liu, Mirella Lapata / EMNLP 2019 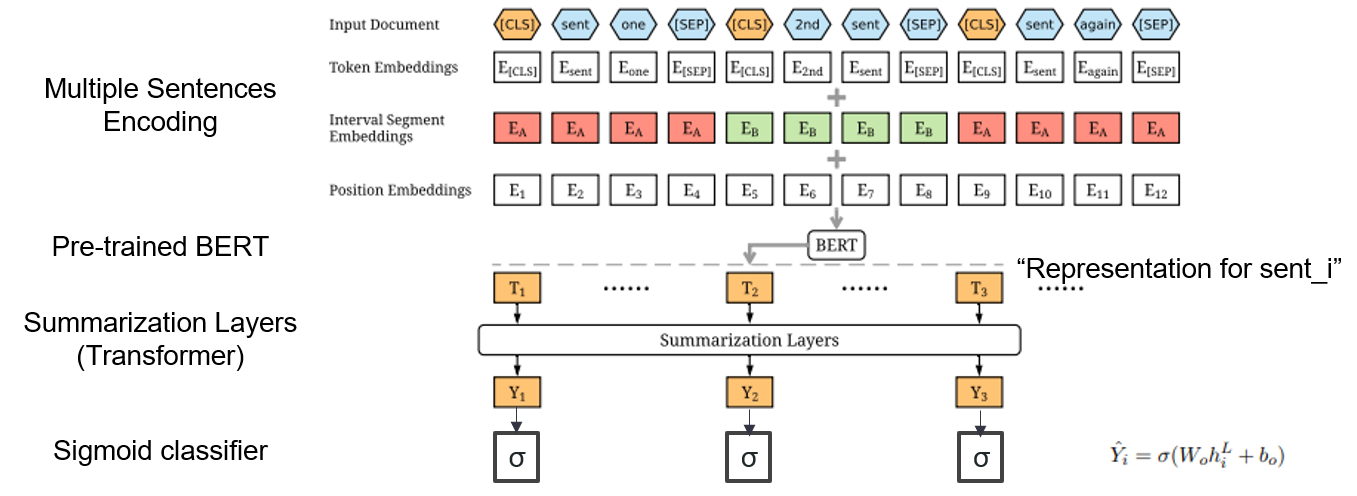 Bagaimana cara menggunakan Bert pra-terlatih dalam ringkasan? Bagaimana cara menggunakan Bert pra-terlatih dalam ringkasan?Bertsum menyarankan embeddings input yang dimodifikasi yang memasukkan token [CLS] di depan setiap kalimat dan menambahkan embeddings segmen interval untuk menambahkan beberapa kalimat ke dalam satu input. Model EXT menggunakan struktur enkoder dengan lapisan transformator pada Bert, dan model ABS menggunakan model encoder-decoder dengan decoder transformator 6-lapis pada model EXT. - [Ulasan] Lee Jung -hoon (Koreauniv DSBA) - [Korea] Kobertsum | Ext/abs, Bert+Transformer, Fine-tuning 2-stag |
| 2019 Model pretraining | Bart : Denoising Sequence-to-Sequence Pra-Pelatihan untuk Generasi Bahasa Alami, Terjemahan, dan Pemahaman Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer / ACL 2020 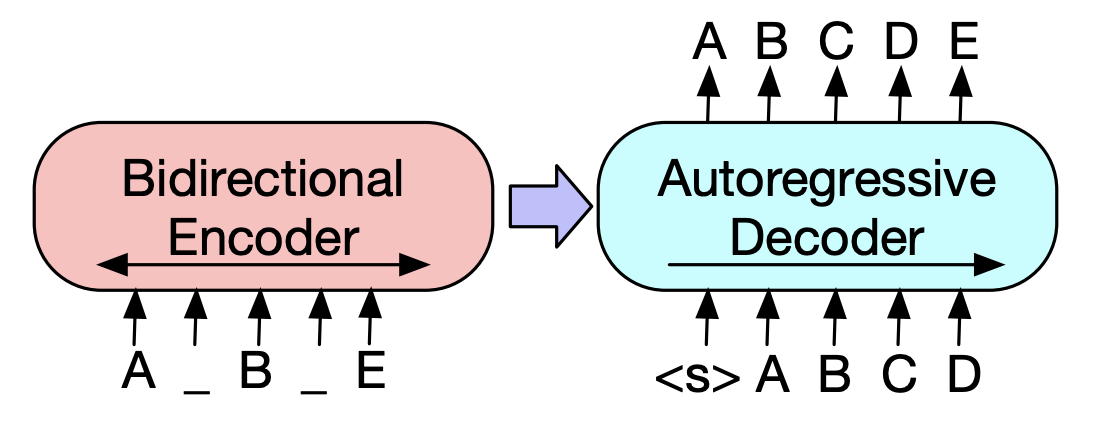 Bert adalah encoder dua arah, tugas yang lemah untuk generasi, dan GPT memiliki kelemahan yang tidak mendapatkan informasi dua arah dengan model regresi otomatis. Bert adalah encoder dua arah, tugas yang lemah untuk generasi, dan GPT memiliki kelemahan yang tidak mendapatkan informasi dua arah dengan model regresi otomatis.BART memiliki bentuk SEQ2SEQ yang menggabungkannya, sehingga Anda dapat bereksperimen dengan berbagai teknik denosing dalam satu model. Akibatnya, pengisi teks (mengubah rentang teks menjadi satu token topeng) dan kalimat mengocok (secara acak mencampur kalimat) menunjukkan kinerja yang melampaui model Ki Sota di bidang peringkasan. - [Korea] SKT T3K. Kobart -[Ulasan] Jin Myung -Hoon_Video, lim yeon -soo_ ditulis oleh jiwung hyun_ | Abs, Seq2seq, Denoising Autoencoder, Pengisi teks |
| 2020 Model | Matchsum : Ringkasan Ekstraksi sebagai Pencocokan Teks (Office) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang / ACL 2020 - [Ulasan] Yoo Kyung (Koreauniv DSBA) | Ext |
| 2020 Teknik | Meringkas teks tentang aspek apa pun: Pendekatan yang diawasi dengan lemah-informasi (kode resmi) Bowen Tan, Lianhui Qin, Eric P. Xing, Zhiting Hu / EMNLP 2020 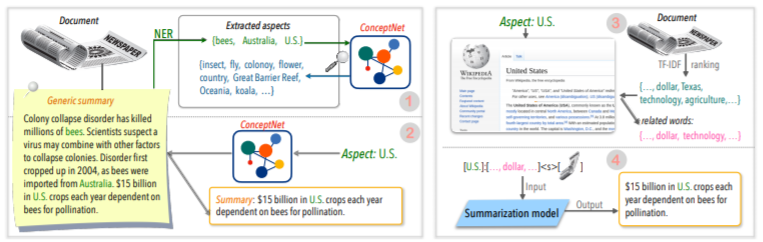 Ringkasan berbasis aspek adalah tugas yang tidak mudah karena hanya berjalan dalam aspek data yang telah ditentukan sebelumnya, yang dipelajari bahkan jika Anda mempelajari model, dan 2) kurangnya data ringkasan berbasis aspek. Makalah ini menggunakan sumber pengetahuan eksternal untuk menyelesaikan masalah ini. -Ini melewati dua langkah untuk mengonversi ringkasan generik ke beberapa ringkasan berbasis aspek. Pertama -tama, untuk meningkatkan jumlah aspek, entitas yang diekstraksi dari ringkasan generik adalah biji dan diekstraksi dari concepnet ke tetangganya dan menganggap masing -masing sebagai aspek. Kami menggunakan Concepnet lagi untuk membuat ringkasan PSEDO untuk masing -masing aspek ini. Ekstrak entitas di sekitarnya yang terhubung ke aspek yang sesuai di Concepnet, dan hanya mengekstrak kalimat yang mengandungnya dalam ringkasan umum. Ini dianggap sebagai ringkasan untuk entitas itu (aspek). -Wikipedia digunakan untuk memberikan informasi yang lebih banyak terkait dengan aspek yang diberikan pada model. Secara khusus, di antara kata-kata yang muncul dalam dokumen, skor TF-IDF dalam dokumen tinggi dan pada saat yang sama, dan pada saat yang sama, daftar 10 kata di halaman Wikipedia sesuai dengan aspek tersebut ditambahkan ke aspek dengan input model. Dengan cara ini, model pra-tuning prealing (BART) juga sangat baik untuk aspek sewenang-wenang dengan data kecil. | Berbasis aspek, Kaya knowlege |
| 2020 Tinjauan | Apa yang telah segera kami ringkas teks? Dandan Huang, Leyang Cui, Sen Yang, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang / EMNP 2020 Selain skor rouge, 10 model ringkasan representatif dievaluasi sesuai dengan 8 metrik (polytope) yang terkait dengan akurasi dan kelancaran. Untuk meringkas hasilnya, -Metode berbasis aturan tradisional masih valid sebagai garis dasar. Di bawah pengaturan yang sama, model EXT umumnya menunjukkan kinerja yang lebih baik dalam kesetiaan dan konsistensi faktual. Kekurangan utama adalah ketidakmampuan untuk model ekstraktif, dan Halusinasi Kelalaian dan Intrinsik untuk Model Abstraktif. -Struktur yang lebih kompleks seperti transformator untuk membuat representasi kalimat tidak terlalu membantu kecuali masalah duplikasi. -Copy ( pointer-generator ) adalah detail yang mereproduksi, yang secara efektif memecahkan masalah duplikasi level kata dengan mencampurkannya serta ketidakakuratan intrinsik. Tetapi cenderung menyebabkan redundansi ke tingkat tertentu. Cakupan adalah margin besar, yang mengurangi kesalahan pengulangan (duplikasi), tetapi pada saat yang sama meningkatkan penambahan dan kesalahan intrinsik ketidakakuratan -Hybrid Model , yang ABS setelah EXT, baik untuk penarikan, tetapi mungkin ada masalah dengan kesalahan ketidaktepatan karena menghasilkan ringkasan melalui beberapa teks asli (cuplikan yang diekstraksi). Pra-pelatihan, terutama model encoder-decoder (BART) daripada model Encoder Only (Bertsumextabs) sangat efektif dalam ringkasan. Ini menunjukkan bahwa preraining semua pemahaman dan pembuatan input sangat berguna untuk pemilihan dan kombinasi konten. Pada saat yang sama, sementara sebagian besar model ABS fokus pada kalimat depan, Bart melihat semua teks asli, yang tampaknya menjadi efek dari pengocokan kalimat selama prerealing. 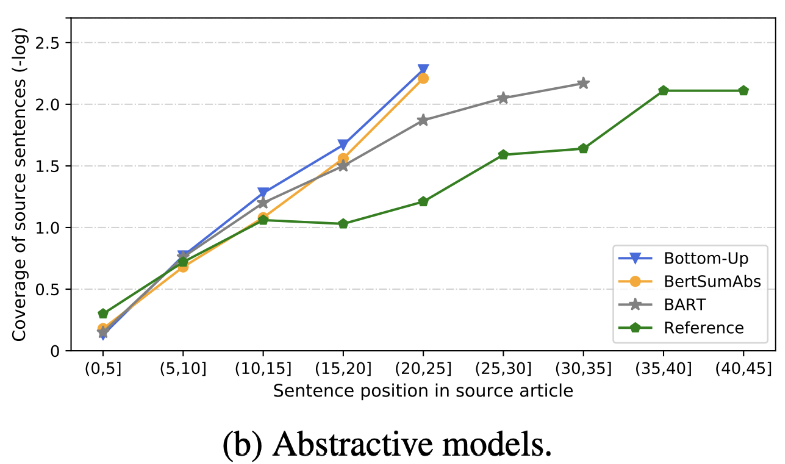 - [Ulasan] Kim Han -Gil, Heo Hoon | Tinjauan |
| 2020 Model | Ctrlsum : Menuju Ringkasan Teks yang Dapat Dikontrol Generik (Kode Resmi) Junxian He, Wojciech Kryściński, Bryan McCann, Nazneen Rajani, Caiming Xiong Ctrlsum adalah model ringkasan teks yang dapat dikendalikan yang memungkinkan Anda menyesuaikan pernyataan ringkasan yang dihasilkan melalui kata kunci atau prompt deskriptif. Pelatihan: Untuk membuat dataset ringkasan yang dapat dikendalikan oleh kata kunci dengan memodifikasi data ringkasan umum, pilih sub-sequences, yang paling mirip dengan ringkasan, dan mengekstrak kata kunci di sana. Masukkan ini ke dalam input dengan dokumen dan selesaikan bart pra-tuning. 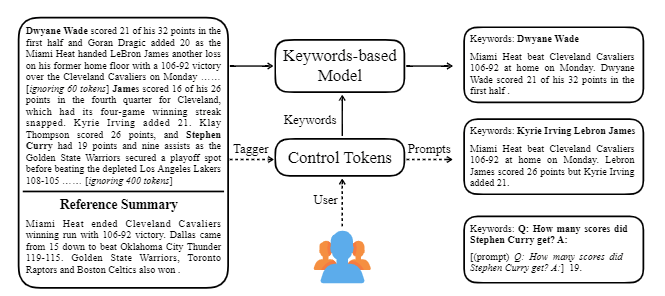 -Inperence: Seperti yang ditunjukkan pada gambar di bawah ini, Anda dapat menambahkan ringkasan ringkasan, seperti membuat ringkasan entitas tertentu, menyesuaikan panjang ringkasan, atau membuat respons terhadap pertanyaan. Perlu dicatat bahwa itu berfungsi seolah -olah tidak secara eksplisit mempelajari petunjuk seperti itu dalam tahap pemodelan, tetapi bekerja seolah -olah itu untuk memahami cepat dan menghasilkan ringkasan. Mirip dengan GPT-3. 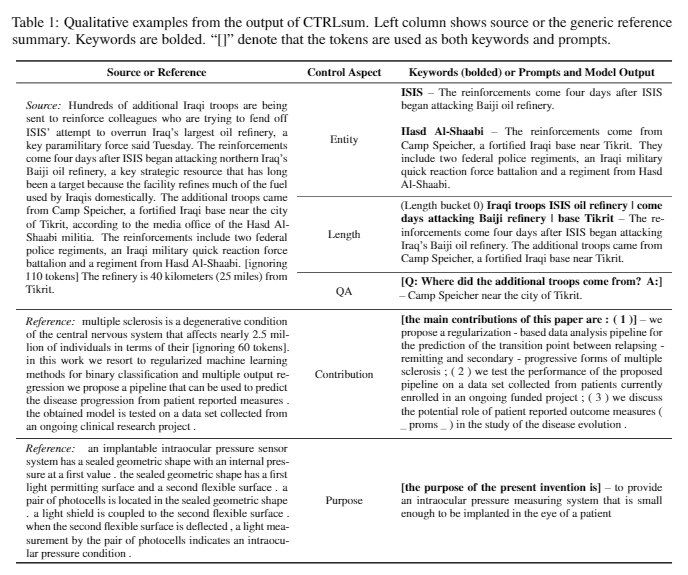 - Paket [Perpustakaan] untuk Ctrlsum berbasis ringkasan yang dapat dikendalikan | Terkendali, Bart |
Paper Digest: Makalah Terbaru tentang Ringkasan Teks
Makalah dengan kode: makalah terbaru
EMNLP 2020 Makalah-Summarisasi
Bahkan, kami telah merangkum model kode, data, dan preitrain yang diperlukan untuk membuat dan mempraktikkan model ringkasan. Ini terutama data Korea, dan untuk materi yang berhubungan dengan bahasa Inggris, silakan merujuk ke bagian kode dari setiap makalah dalam item makalah.
Arti dari lemah yang digunakan di bawah ini adalah sebagai berikut.
w : Nilai rata -rata jumlah kata; s : Nilai rata -rata jumlah rata -rata kalimat
Contoh) 13s/214w → 1s/26w berarti memberikan ringkasan teks yang terdiri dari rata -rata 13 kalimat (rata -rata 214 kata) dan rata -rata satu kalimat (rata -rata 26 kata).
Ringkasan abs ; ext : Ringkasan Ekstraktif
| Dataset | Domain / panjang | Volume (Pasangan) | Lisensi |
|---|---|---|---|
| Ringkasan kata-kata setiap orang Judul teks berita pendek, 3 kalimat abs dan ext summay Semua kata semua orang dengan ID-combined dengan kuda koran, Anda bisa mendapatkan informasi tambahan terkait dengan subtitle, media, tanggal, dan topik. | berita -Origin → 3s (ABS); 3s (ext) | 13.167 | Institut Nasional Bahasa Korea (Kontrak individu) |
| Teks Ringkasan Dokumen AIHUB ABS dan Ext Summay untuk artikel surat kabar, kontribusi, artikel majalah, dan ulasan pengadilan - [EDA] Data EDA Notebook -Ringkasan Ekstraksi Dokumen Korea Ringkasan dan Ringkasan Penciptaan Ringkasan Kontes AI (~ 20.12.09) | -Terpas surat kabar 300.000, 60.000 kontribusi, 10.000 artikel majalah, pengadilan yang memutuskan 30.000 13S/214W → 1S/26W (ABS); 3S/55W (ext) | 400.000 | Aihub (Kontrak individu) |
| AIHUB-SUMBARY Ringkasan abs oleh semua dan bagian untuk makalah akademik dan spesifikasi paten | -Sebuah makalah akademik, spesifikasi paten -Origin → Abs | 350.000 | Aihub (Kontrak individu) |
| Ringkasan Data Buku AIHUB Ringkasan abs untuk buku asli Korea tentang berbagai topik | -Lifetime, kehidupan, pajak, lingkungan, pengembangan masyarakat, perdagangan, ekonomi, tenaga kerja, dll. -300-1000 karakter → abs | 200.000 | Aihub (Kontrak individu) |
| SAE4K | 50.000 | CC-BY-SA-4.0 | |
| Sci-News-Sum-KR-50 | Berita (IT/Sains) | 50 | Mit |
| Wikilingua : Dataset Ringkasan Abstrak Multilingual (2020) Berdasarkan situs manual Wikihow, 18 bahasa seperti Korea dan Inggris -Paper, Collab Notebook | -Bosa-kepada Docs -391W → 39W | 12.189 (KOR Total 770.087) | 2020, CC BY-NC-SA 3.0 |
| Dataset | Domain / panjang | Volume | Lisensi |
|---|---|---|---|
| Scisummnet (kertas) Menyediakan tiga jenis ringkasan untuk penelitian ACL (NLP) -Cl-scisumm 2019-Task2 (repo, kertas) -Cl-scisumm @ emnlp 2020-Task2 (repo) | -Keret penelitian (Komputasi ahli bahasa, NLP) 4.417W → 110W (abstrak kertas); 2s (kutipan); 151W (ABS) | 1.000 (abs/ ext) | CC BY-SA 4.0 |
| Longsumm Ringkasan Daftar Relatif Panjang (Posting Blog Terkait -ABS Berbasis ABS, Konferensi Terkait Pembicaraan Video) -Longsumm 2020@emnlp 2020 -Longsumm 2021@ NAACL 2021 | -Research Paper (NLP, ML) -Origin → 100S/1.500W (ABS); 30S/ 990W (ext) | 700 (abs) + 1.705 (ext) | Atribusi-nonkomersial-Sharealike 4.0 |
| Cl-Laysumm Berikan lapisan mudah untuk non -profesional untuk bidang NLP dan ML. -Cl-laysumm @ emnlp 2020 | Kertas -rESearch (epilepsi, arkeologi, rekayasa bahan) -Origin → 70 ~ 100W | 600 (abs) | Kebutuhan Perjanjian Individu (Dikirim Email ke [email protected]) |
| Global Voice : Crossing Borders in Automatic News Summarisasi (2019) -Kertas | - Berita -359W → 51W | ||
| MLSUM : Corpus Peringkasan Multilingual Mirip dengan dataset CNN/Daily Mail, highlight/deskripsi dalam artikel berita dianggap sebagai ringkasan dan ringkasan untuk bahasa Inggris, Prancis, Jerman, Spanyol, Rusia, Dataset Build Turki -Paper, use (huggingface) | - Berita -790W → 56W (En basis) | 1.5m (abs) | Tujuan penelitian non-komersial saja |
| Model | Pra-pelatihan | Penggunaan | Lisensi |
|---|---|---|---|
| Bert (multibahasa) Bert-Base (parameter 110m) | -Wikipedia (multibahasa) -Wordpiece. -110k Vocab bersama | BERT-Base, Multilingual Cased Versi yang disarankan( --do_lower_case=false )-Tensorflow | Google (Apache 2.0) |
| Kobert Bert-Base (parameter 92m) | -Wikipedia (Kalimat 5m), Berita (Kalimat 20m) -SentencePiece 8.002 Vocab (tidak ada token yang tidak digunakan) | -Pytorch -Semua tersedia sebagai pustaka Transformers Huggingface melalui Kobert-Transformers (Monologg), Distilkobert tersedia | Sktbrain (Apache-2.0) |
| Korbert Bert-base | -News (10 tahun), wikipedia, dll. 23GB -Etri analisis morfologis API / Wordpiece (disediakan dua versi secara terpisah) -30.349 Vocabs Latin Happabets: Cased - [Pendahuluan] Lim Jun (ETRI). NLU Tech Talk dengan Korbert | -Pytorch, tensorflow | ETRI (Kontrak individu) |
| Kcbert Bert-base/besar | Komentar Berita -Daver (12.5GB, 8,9 juta kalimat) (19.01.01 ~ 20.06.15 Komentar dari artikel dalam artikel dan komentar) -Tokenizers BertwordPiecetokenizer -30.000 Vocab | Beomi (MIT) | |
| Kobart Bart (124m) | -Wikipedia (5m) dan lainnya (berita, buku, kata -kata semua orang (percakapan, berita, ...), petisi nasional Cheong wa dae, dll. Tokenizer BPE Tokenizer -Tockenizers 30.000 Vocab (termasuk) - [Contoh] Seujung. Kobart-Summarisasi (kode, demo) | -S spesialisasi tugas kerumitan -Mukal Perpustakaan Transformersface Transformers -Pytorch | SKT T3K (MIT yang dimodifikasi) |
| Tahun | Kertas |
|---|---|
| 2018 | Survei tentang Metode Ringkasan Berbasis Jaringan Saraf Y. Dong |
| 2020 | Tinjauan Teknik & Metode Ringkasan Teks Otomatis Widyassari, AP, Rustad, S., Shidik, GF, Noersasongko, E., Syukur, A., & Affandy, A. |
| 2020 | Survei generasi teks yang ditingkatkan pengetahuan Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng JI, Meng Jiang |
| Tahun | Kertas | Kata kunci |
|---|---|---|
| 1958 | Penciptaan abstrak literatur otomatis Ph Luhn | Gen-ex |
| 2000 | Pembuatan judul berdasarkan terjemahan statistik M. Banko, Vo Mittal, dan MJ Witbrock | Gen-abs |
| 2004 | LEXRANK : Sentralitas Leksikal Berbasis Grafik sebagai arti-penting dalam ringkasan teks G. Erkan, dan Dradev, | Gen-ex |
| 2005 | Ringkasan Dokumen Tunggal Berbasis Ekstraksi Kalimat J. Jagadeesh, P. Pingali, dan V. Varma | Gen-ex |
| 2010 | Generasi judul dengan tata bahasa kuasi-sinkron K. Woodsend, Y. Feng, dan M. Lapata, | Gen-ex |
| 2011 | Ringkasan Teks Menggunakan Analisis Semantik Laten Mg ozsoy, fn alpaslan, dan I. cicekli | Gen-ex |
| Tahun | Kertas | Kata kunci |
|---|---|---|
| 2014 | Menggunakan kosakata target yang sangat besar untuk terjemahan mesin saraf S. Jean, K. Cho, R. Memisevic, dan Yoshua Bengio | Gen-abs |
| 2015 Model | NAMAS : Model perhatian saraf untuk ringkasan abstraktif (kode) Am Rush, S. Chopra, dan J. Weston / EMNLP 2015 Untuk melampaui metode pemilihan dan kombinasi kalimat yang ada, kami memperkenalkan perhatian target-ke-sumber di bendera seq2seq untuk membuat ringkasan abstrak. | abs Seq2seq dengan att |
| 2015 | Toward Abstractive Summarization Using Semantic Representations Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 Model | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 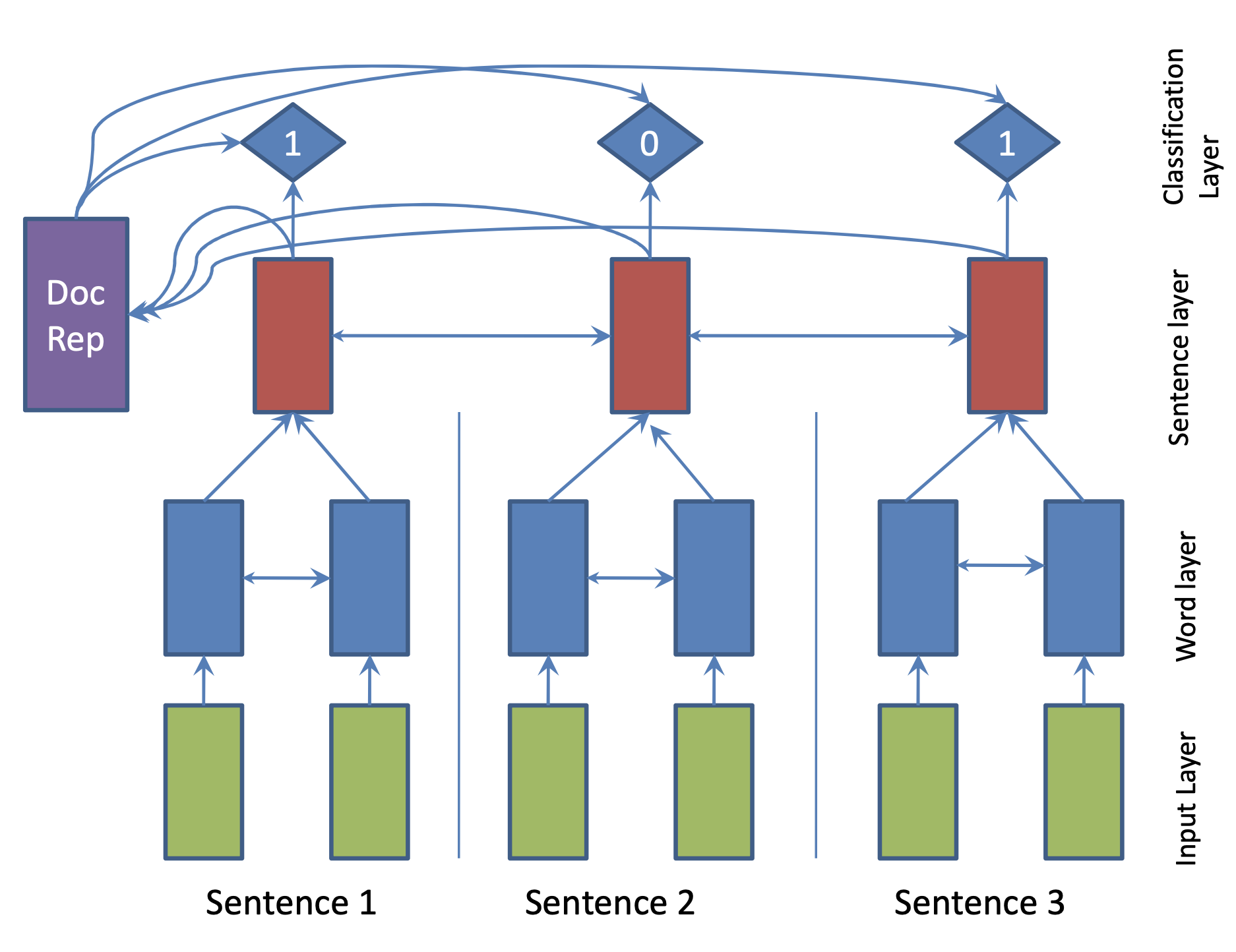 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 Model, Teknik | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 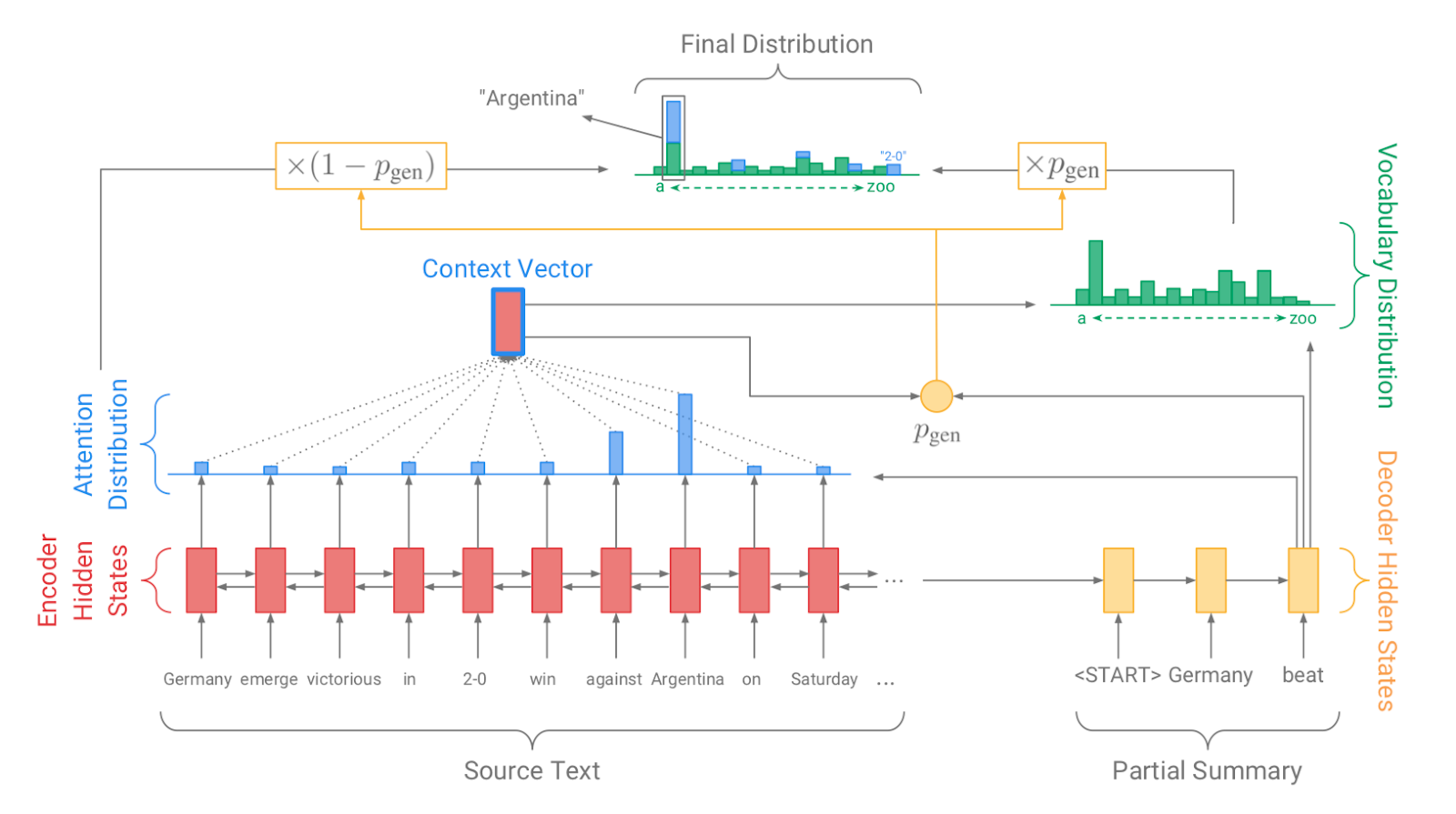 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 Model | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 Model | Bottom-Up Abstractive Summarization Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, Hibrida, bottom-up attention |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 Model | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 Model | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 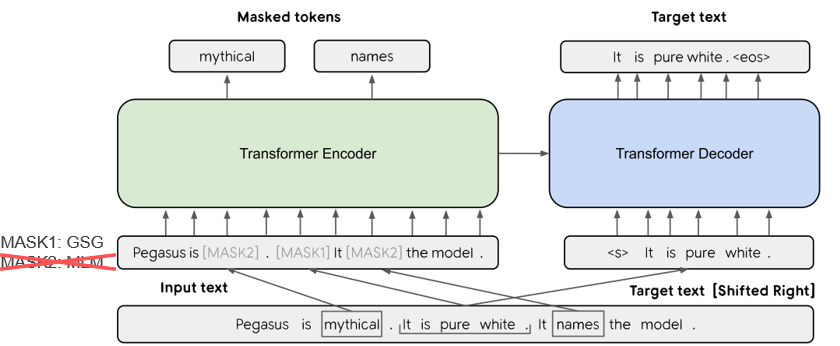 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 Model | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


