Text Summarization Repo
1.0.0
Entre los NLP, es un espacio que acumula datos de calidad relacionados con el campo Resumen de texto. Me gustaría ser una buena guía para aquellos interesados en el resumen del texto.
En primer lugar, entendemos qué temas detallados resume el texto y observamos los documentos principales que han dirigido este campo. Desde entonces, hemos enumerado el código, los conjuntos de datos y los modelos previos a la caña necesarios para crear un modelo de resumen de texto directo.
Introducción al resumen de texto
PAPELES
Recursos
Otros
Berry, Dumais y O'Brien (1995) define el resumen del texto de la siguiente manera:
El resumen del texto es el proceso de destilación de la información más importante de un texto para producir una tarea en particular y un usuario
Es un proceso de refinar solo información importante entre el texto dado en una palabra. Aquí, la expresión de la refinación y la importancia de importante es una expresión bastante abstracta y subjetiva, por lo que personalmente quiero definirlo de la siguiente manera.
f(text) = comprehensible information
En otras palabras, el resumen del texto es convertir el texto original en una información fácil y valiosa . Los humanos son difíciles de ver a un vistazo de información de texto, que es larga o dividida en varios documentos. A veces no sabes muchos términos profesionales. Es bastante valioso reflejar estos textos en una forma simple y fácil de entender mientras refleja bien el texto original. Por supuesto, lo que realmente vale la pena y cómo cambiarlo variará según el propósito de resumir o gustos personales.
Desde este punto de vista, se puede decir que el texto resume no solo las tareas que crean textos como las actas, el titular del ingeniero de periódicos, el resumen de papel y el reanudación, así como las tareas que convierten el texto en gráficos o imágenes. Por supuesto, dado que no se trata solo de resumen, es un resumen de texto , por lo que la fuente del resumen es limitada en forma de texto. (El resumen del resumen es porque no solo puede ser texto o video, así como texto. En el ejemplo, el ejemplo anterior es la subtítulos de imágenes, el último ejemplo es el resumen de video. Teniendo en cuenta la tendencia de aprendizaje profundo reciente cuando el límite entre la visión y la PNL se está volviendo borrosa, puede ser sin sentido poner 'texto' como un prefijo.
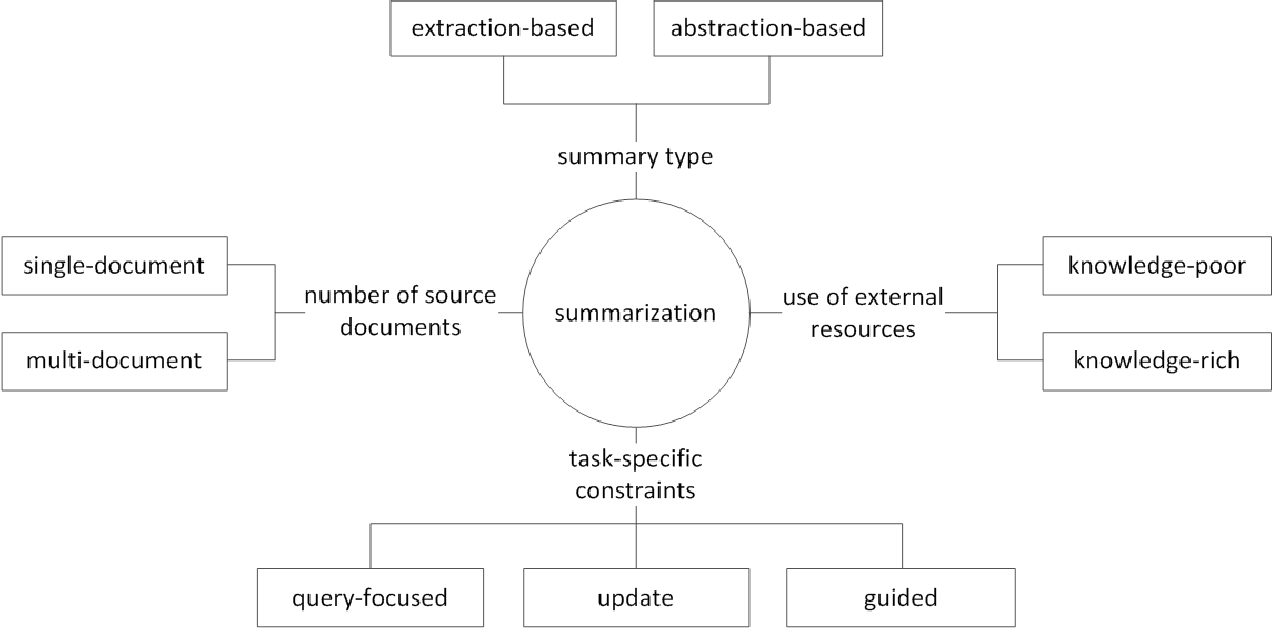
En general, la tarea de resumen del texto se divide en resumen extractivo (en adelante, denominado resumen ext) y resumen abstracto (ABS), dependiendo de cómo generen un resumen. (Gudivada, 2018)
Métodos extractivos seleccione un subconjunto de palabras, frases o oraciones existentes en el texto original para formar un resumen. Por el contrario, los métodos abstractores primero crean una representación semántica interna y el uso de tecnología generacional del lenguaje natural.
Ext generalmente obtiene la importancia de la oración, y luego la selecciona y la combina para crear un resumen. Es similar a la tarea de pintar a un marcador mientras lee. El ABS , por otro lado , se basa en el texto original, pero es un método NLG (generación de lenguaje natural) que genera un nuevo texto . Es poco probable que EXT incluya expresiones que se limitan a expresiones debido al texto en el texto original. El ABS, por otro lado, tiene la ventaja de que existe la posibilidad de crear una expresión sin precedentes porque debe crear un nuevo texto en el modelo, pero tiene enfoques más flexibles.
Además, de acuerdo con el número de textos originales, de acuerdo con la forma de texto de resumen de documentos individuales/múltiples , resumen de palabras clave/oraciones , de acuerdo con la cantidad de información externa que se usa en el proceso suma , de acuerdo con el proceso de suma, hay varias distinciones como la suma.
(G. Sizov (2010). Resumen automático basado en extracción: investigación teórica y empírica de las técnicas de resumen
Echemos un vistazo a los principales temas de investigación en el campo del resumen de texto y pensemos en qué tipo de desafío en este campo.
Resumen de documentos múltiples / largos
Como se mencionó anteriormente, la tarea de resumen es cambiar el texto incomprensible a información comprensible. Por lo tanto, cuanto más tiempo sea el texto original, o el resumen de los documentos de múltiples fuentes, no un documento, más aumenta la utilidad del resumen. El problema es que al mismo tiempo, la dificultad del resumen también aumenta.
Por esta razón, cuanto más tiempo sea el texto original, más rápidamente aumenta la complejidad computacional. Este es un problema mucho más crítico en los métodos recientes basados en la red neuronal que incluyen transformador que en métodos estadísticos como TexTrank en el pasado. En segundo lugar, cuanto más tiempo sea el texto original, más no es el núcleo del contenido, es decir, ruido. No es fácil identificar qué es el ruido y lo que es informativo. Finalmente, los textos largos y varias fuentes tienen varias perspectivas y contenidos al mismo tiempo, lo que dificulta crear un resumen que lo cubra bien.
Resumen de documentos múltiples (MDS)
MDS es un resumen de una pluralidad de documentos . A primera vista, será difícil resumir los artículos de diferentes perspectivas de varios autores que resumir un documento que describe un tema desde una tendencia y un punto de vista consistentes. Por supuesto, incluso en el caso de MDS, generalmente se basa en el mismo documento de clúster que se ocupa de temas similares, pero no es fácil identificar información importante y filtrar la información de los esquivos entre muchos documentos.
La tarea, que resume las revisiones de ciertos productos, es un ejemplo de MDS que es el más fácil de pensar. Esta tarea, generalmente llamada resumen de opinión, se caracteriza por una longitud de texto corta y una subjetividad. El trabajo de crear un documento wiki también puede considerarse como un MDS. Liu et al. (2018) es el texto original del texto del sitio web en el documento wiki, que es el texto original, que se considera un resumen, y crea un modelo de creación wiki.
Resumen de documentos largos
Liu et al. (2018) es una forma estadística de aceptar el texto largo como una entrada, creando un resumen de extractos, utilizando solo oraciones importantes y usándolo como una entrada del modelo. Además, para reducir el volumen de computación del transformador, la entrada se divide en unidades de bloque, y en este momento, la convolución 1-D utiliza el método de atensión que reduce el número de clave y valor de atención individual. El papel Big Bird (2020) presenta un mecanismo de atensión dispersa (lineal) en lugar de una combinación de todas las palabras existentes para reducir el cálculo del transformador. Como resultado, el mismo hardware de rendimiento se ha resumido hasta ocho veces más.
Gidiotis y Tsoumakas (2020), por otro lado, intentan acercarse a la división y el consumo, que no resuelve el problema de resumen de texto largo a la vez y lo convierte en varios pequeños resúmenes de texto. Entrenando el modelo cambiando el texto original y el resumen del objetivo a los múltiples pares de or-objetivo de origen más pequeños. En la inferencia, agregamos la salida de resúmenes parciales a través de este modelo para crear un resumen completo.
Mejora del rendimiento
¿Cómo puedes crear un mejor resumen?
Transferir el aprendizaje
Recientemente, el uso del modelo de previación en PNL se ha vuelto casi predeterminado. Entonces, ¿qué tipo de estructura deberíamos tener para crear un modelo previo que pueda mostrar un mejor rendimiento en el resumen de texto? ¿Qué objeto debería tener?
En Pegasus (2020), el método GSG (generación de oraciones GAP), que selecciona una oración que se considera importante en función de la puntuación Rouge, supone que más similar al proceso de resumen del texto y la objeción mostrarán el rendimiento más alto. El modelo SOTA actual, BART (2020) (transformadores bidireccionales y de auto-regresión), aprende en forma de un autoencoder que agrega ruido a parte del texto de entrada y lo restaura como un texto original.
Generación de texto mejorada por Knowedge
En la tarea de texto a texto, a menudo es difícil generar la salida deseada solo con el texto original. Por lo tanto, hay un intento de mejorar el rendimiento al proporcionar una variedad de conocimientos al modelo, así como al texto original . La fuente o provisión de estos conocimientos varía en varios tipos de palabras clave, temas, características lingüísticas, bases de conocimiento, gráficos de Knowedge y texto fundamentado.
Por ejemplo, Tan, Qin, Xing y Hu (2020) ofrece un conjunto de datos de Summry general para convertir una pluralidad del resumen basado en aspectos, y ofrece información más rica relacionada con un aspecto dado a un aspecto dado al modelo. Use Wikipedia para. Si quieres saber más, Yu et al. Lea el documento de la encuesta escrito por (2020).
Corección posterior a la edición
Sería bueno crear un buen resumen a la vez, pero no es fácil. Entonces, ¿por qué no crea un resumen y luego lo revisa y lo modifica en una variedad de criterios?
Por ejemplo, Cao, Dong, Wu y Cheung (2020) sugiere un método para reducir el error de hecho mediante la aplicación de un modelo de corrección neuronal heredado al resumen generado.
Además, también hay muchos intentos de aplicar ** Red neuronal gráfica (GNN) **, que ha recibido mucha atención recientemente.
Problema de escasez de datos
El resumen del texto es una tarea que lleva mucho tiempo, lo que no es fácil para los humanos. Por lo tanto, en comparación con otras tareas, cuesta costos relativamente mayores crear un conjunto de datos etiquetado y, por supuesto, hay una falta de datos para la capacitación.
Además del método de aprendizaje de transferencia utilizando el modelo previo mencionado anteriormente, estamos aprendiendo en métodos de aprendizaje de aprendizaje o refuerzo no supervisados o intentando un enfoque de aprendizaje de pocos disparos .
Naturalmente, hacer buenos datos de resumen también es un tema de investigación muy importante. En particular, muchos de los conjuntos de datos relacionados con resumen actuales están sesgados en tipos de noticias en el idioma inglés. Como resultado, se están creando conjuntos de datos multilingües como Wikilingua y Mlsum. Para obtener más información, eche un vistazo a Mlsum: el corpus de resumen multilingüe.
Método de métrica / evaluación
Escribí una expresión aplastante de 'bueno' antes. ¿Cuál es un 'buen resumen'? Brasinskas, Lapata y Titov (2020) usan las siguientes cinco cosas basadas en el juicio de un buen resumen.
El problema es que no es fácil medir estas partes. El indicador de medición de rendimiento más común en los resúmenes de texto es la puntuación Rouge. Hay varias variantes en la puntuación Rouge, pero básicamente '¿Cómo es la palabra de la palabra del resumen generado y el resumen de referencia?' Significa similar, pero si tiene una forma diferente o si el orden de la palabra cambia, puede obtener una puntuación más baja incluso si es un mejor resumen. En particular, tratando de elevar el puntaje Rouge, puede provocar dañar la diversidad expresiva del resumen. Esta es la razón por la cual muchos documentos proporcionan resultados de evaluación humana adicionales con dinero costoso, así como una puntuación Rouge.
Lee et al. (2020) presenta un RDASS (puntaje semántico de conciencia de referencia y documento), que es lo similar que es para el resumen de texto y referencia, y luego medido por las carreteras similares basadas en el vector. Se espera que este método aumente la precisión de la evaluación del idioma coreano, que combina palabras y diversas morfología para expresar varios significados y funciones gramaticales. Kryściński, McCann, Xiong y Socher (2020) propusieron un enfoque basado en modelos débilmente supervisado para evaluar la consistencia objetiva.
Generación de texto controlable
¿Hay solo un mejor resumen sobre un documento determinado? No lo hará. Las personas con diferentes inclinaciones pueden preferir diferentes textos de resumen para el mismo texto. Incluso si usted es la misma persona, el resumen que desea dependerá del propósito de resumir o la situación. Este método para ajustar la salida a la forma deseada de acuerdo con las condiciones especificadas por el usuario se llama generación de texto controlable . Puede proporcionar un resumen personalizado en comparación con el resumen genérico que crea el mismo resumen para un documento determinado.
El resumen que se genera no solo debe ser fácil de entender y valorar, sino también estar estrechamente relacionado con la condición que organizó.
f(text, condition ) = comprehensible information that meets the given conditions
¿Qué condición puedo agregar al modelo de resumen? ¿Y cómo puede crear un resumen que se adapte a esa condición?
Resumen basado en aspectos
Al resumir las revisiones de los usuarios de AirPod, es posible que desee resumir cada lado dividiendo la calidad del sonido, la batería y el diseño. O es posible que desee ajustar el estilo o el sentimiento de escritura en el artículo. En este texto original , el trabajo que resume solo la información relacionada con aspectos o características específicos se llama resumen basado en aspectos .
Anteriormente, solo los modelos que funcionaban solo en el aspecto predefinido, que se usaban principalmente para el aprendizaje del modelo, ahora intentaban permitir el razonamiento del aspecto arbitrario, que no se dio al aprendizaje como Tan, Qin, Xing y Hu (2020).
Resumen centrado en la consulta (QFS)
Si la condición es consulta , se llama qfs. La consulta es principalmente un lenguaje natural, por lo que la tarea principal es cómo hacer bien estas diversas expresiones y combinarlas con el texto original. Es bastante similar al sistema de control de calidad que conocemos bien.
Resumen de actualización
Los humanos son animales que continúan aprendiendo y creciendo. Por lo tanto, el valor de hoy para cierta información puede ser completamente diferente del valor de una semana después. El valor del contenido en el documento que ya he experimentado se reducirá, y el nuevo contenido que aún no se ha experimentado aún tendrá un alto valor. Desde este punto de vista, se llama resumen de actualización para crear un nuevo resumen de un nuevo contenido que sea similar al contenido del documento que el usuario experimentó anteriormente .
CtrlSum toma varias palabras clave o indicaciones descriptivas con el texto para ajustar el resumen que se genera. Es un modelo de resumen de texto controlable más general de propósito, ya que muestra los mismos resultados que se controlan para palabras clave o indicaciones que no se aprenden explícitamente en la etapa de entrenamiento. Puede usarlo fácilmente a través de la biblioteca de resumen de Koh Hyun -Woong.
Además de esto, una variedad de intentos de crear un modelo de resumen que sea adecuado para el resumen de la conversación en lugar de un tema DL típico como el modelo ** liviano, así como un resumen del diálogo en lugar de un texto estructurado como noticias o wikipedia. Hay temas.
Si conoce lo siguiente en el campo Resumen de texto, podrá estudiar más fácilmente.
Comprender el concepto básico de la PNL
Estructura de transformador/bert y comprensión objetiva de pre-entrenamiento
Muchos de los últimos documentos de PNL se basan en varios modelos previos a la preferencia, incluidos Bert, basados en Transformer, y Roberta y T5, que son variantes de este Bert. Por lo tanto, si comprende su estructura esquemática y su objetivo de pre-entrenamiento, es de gran ayuda para leer o implementar un documento.
Resumen de texto Concepto básico
Red neuronal gráfica (GNN)
Traducción automática (MT)
MT es una de las tareas más activas en el campo NLP desde la aparición de SEQ2SEQ. Si observa el proceso de resumen como un proceso de convertir un texto en un tipo diferente de texto, puede verse como una especie de MT, por lo que gran parte de los estudios e ideas relacionados con MT probablemente sean prestados o aplicados en el campo de resumen.
| Año | Papel | Palabras clave |
|---|---|---|
| 2004 Modelo | TexTrank : Traer el orden a los textos R. Mihalcea, P. Tarau Es un clásico en el sector de la extracción y todavía está activo. Suponiendo que la oración importante dentro del documento (es decir, incluida en el resumen) es un algoritmo de PageRank, la idea inicial del motor de búsqueda de Google, suponiendo que tendrá alta similidad con otras oraciones. Cada oración configura el gráfico ponderado a nivel de oración para calcular la similitud con otra oración en el documento, e incluye esta oración de alto peso en el resumen. Los métodos de aprendizaje no supervisados basados en estadística pueden ser razonables sin datos de aprendizaje separados, y el algoritmo es claro y fácil de entender. - [biblioteca] gensim.summarization (solo hay una versión 3.x disponible. Eliminar de la versión 4.x), PytexTrank - [Teoría/código] Lovit. Extracción de palabras clave utilizando TextTrank y Core Sentence Extract | Ext, Basado en gráficos (PageRank), No supervisado |
| 2019 Modelo | Bertsum : resumen de texto con codificadores pretendidos (OfficeIad) Yang Liu, Mirella lapata / EMNLP 2019 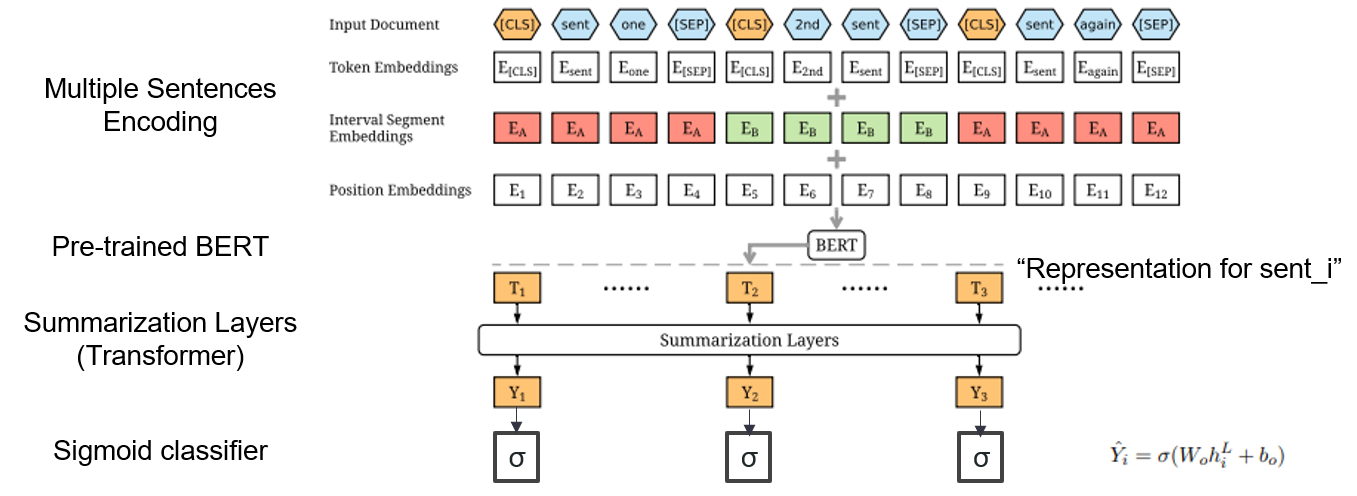 ¿Cómo puedo usar Bert pre-entrenado en resumen? ¿Cómo puedo usar Bert pre-entrenado en resumen?Bertsum sugiere incrustaciones de entrada modificadas que inserta tokens [CLS] frente a cada oración y agrega incrustaciones del segmento de intervalo para agregar múltiples oraciones a una entrada. El modelo EXT utiliza una estructura de codificador con capas de transformador en el Bert, y el modelo ABS utiliza un modelo de codificador codificador con un decodificador de transformador de 6 capas en el modelo EXT. - [Revisión] Lee Jung -hoon (Coreauniv DSBA) - [coreano] Kobertsum | Ext/ABS, Bert+Transformer, Ajustado |
| 2019 Modelo previo | BART : Precrendimiento de secuencia a secuencia de denominación para la generación de lenguaje natural, traducción y comprensión Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer / ACL 2020 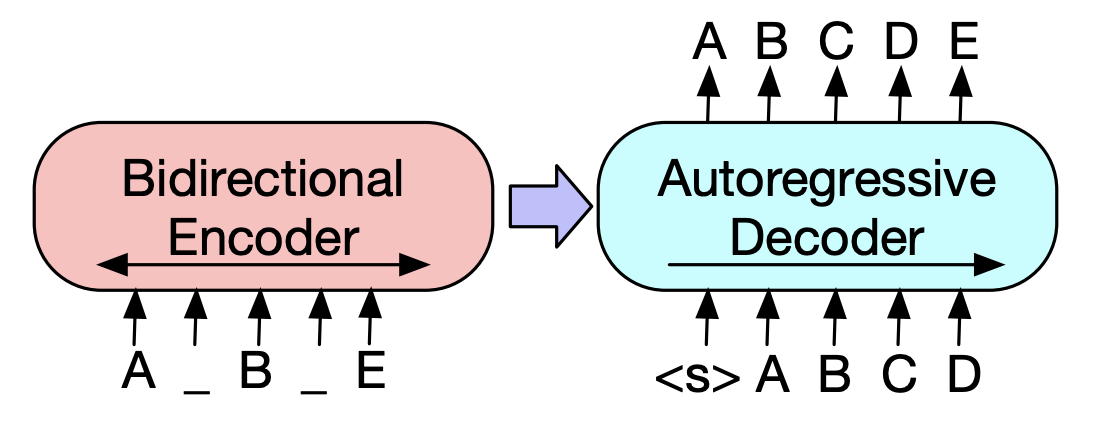 Bert es un codificador bidiréctrico, tareas débiles a generación, y GPT tiene una desventaja de que no obtiene información bidirectada con un modelo de auto-regresión. Bert es un codificador bidiréctrico, tareas débiles a generación, y GPT tiene una desventaja de que no obtiene información bidirectada con un modelo de auto-regresión.El BART tiene una forma SEQ2SEQ que los combina, por lo que puede experimentar con varias técnicas de desanimación en un modelo. Como resultado, el relleno de texto (cambia el tramo de texto a un token de máscara) y la oración que baraja (mezcla aleatoriamente la oración) muestra el rendimiento que supera el modelo Ki SOTA en el campo de resumen. - [coreano] Skt T3K. Kobart -[Revisión] Jin Myung -hoon_video, Lim Yeon -Soo_ Escrito por Jiwung Hyun_ | Abdominales, SEQ2SEQ, Denoising Autoencoder, TEXTO LLEMINACIÓN |
| 2020 Modelo | MatchSum : resumen de extracción como coincidencia de texto (oficina) Ming Zhong, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu, Xuanjing Huang / ACL 2020 - [Revisión] Yoo Kyung (Coreauniv DSBA) | Extendido |
| 2020 Técnica | Resumiendo el texto sobre cualquier aspecto: un enfoque débilmente supervisado informado por el conocimiento (código oficial) Bowen Tan, Lianhui Qin, Eric P. Xing, Zhiting Hu / EMNLP 2020 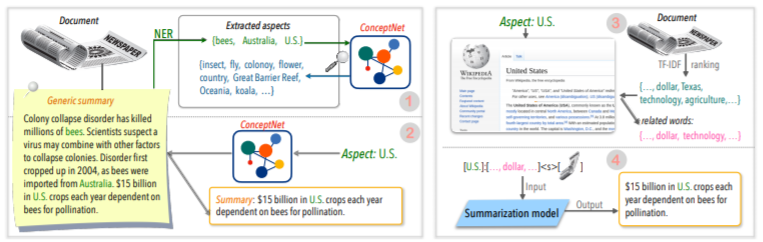 El resumen basado en los aspectos es una tarea que no es fácil porque se ejecuta solo en los aspectos predefinidos de los datos, lo que se aprende incluso si aprende el modelo, y 2) falta de múltiples datos de resúmenes basados en aspectos. Este documento utiliza fuentes de conocimiento externas para resolver este problema. -El revista dos pasos para convertir un resumen genérico en múltiples resúmenes basados en aspectos. En primer lugar, para aumentar el número de aspectos, la entidad extraída del resumen genérico es la semilla y se extrae del concepto a sus vecinos y considere a cada uno de ellos como un aspecto. Usamos Concepnet nuevamente para crear un resumen de PSEDO para cada uno de estos aspectos. Extraiga la entidad circundante conectada al aspecto correspondiente en Concepnet, y extraiga solo las oraciones que las contienen dentro del resumen general. Esto se considera un resumen para esa entidad (aspecto). -Wikipedia se utiliza para entregar información más abundante relacionada con el aspecto dado al modelo. Específicamente, entre las palabras que aparecen en el documento, la puntuación TF-IDF en el documento es alta y al mismo tiempo, y al mismo tiempo, la lista de 10 palabras en la página de Wikipedia corresponde a ese aspecto se agrega al aspecto con la entrada del modelo. De esta manera, el modelo previo al ajuste previo (BART) también fue excelente para el aspecto arbitrario con datos pequeños. | Basado en el aspecto, Rico en conocimientos |
| 2020 Revisar | ¿Qué tenemos pronto resumen de texto? Dandan Huang, Leyang Cui, Sen Yang, Guangsheng Bao, Kun Wang, Jun Xie, Yue Zhang / EMNP 2020 Además de la puntuación Rouge, se evalúan 10 modelos de resumen representativos de acuerdo con 8 métricas (Polyitope) relacionadas con la precisión y la fluidez. Para resumir los resultados, -El método basado en reglas tradicional sigue siendo válido como línea de base. Bajo entornos similares, el modelo EXT generalmente muestra un mejor rendimiento en la fielidad y la consistencia objetiva. La deficiencia principal es la inexesidad de los modelos extractivos, y la omisión y la alucinación intrínseca para los modelos abstractivos. -Las estructuras más complejas, como los transformadores para crear la representación de la oración, no son muy útiles, excepto el problema de duplicación. -Copy ( Pointer-Generator ) es un detalle de reproducción, que resuelve efectivamente el problema de duplicación de nivel de palabra al mezclarlo e intrínsecos inexactitudes. Pero tiende a causar redundancia hasta cierto punto. La cobertura es por un margen grande, lo que reduce los errores de repetición (duplicación), pero al mismo tiempo aumenta la adición e error intrínseco de inexactitud -La modelo de híbrido , que es ABS después de ext, es bueno para los retiros, pero puede haber problemas con el error de inexactitud porque genera resumen a través de algunos de los textos originales (fragmentos extraídos). El modelo previo, especialmente el modelo de codificador codificador (BART) que el modelo solo del codificador (bertsumextabs) es muy efectivo en el resumen. Esto sugiere que la prevención de toda comprensión y creación de la entrada es muy útil para la selección y combinación de contenido. Al mismo tiempo, mientras que la mayoría de los modelos de ABS se centran en la oración delantera, Bart está mirando todo el texto original, que parece ser el efecto de la oración que baraja durante la preferencia. 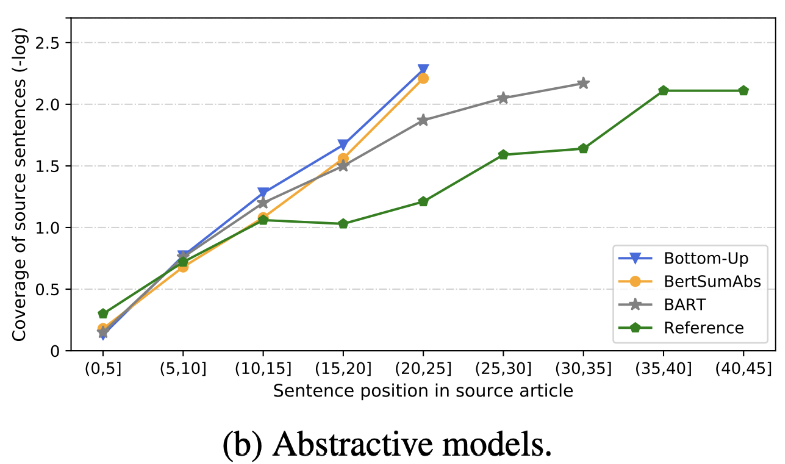 - [Revisión] Kim Han -gil, Heo Hoon | Revisar |
| 2020 Modelo | CtrlSum : Hacia el resumen genérico de texto controlable (código oficial) Junxian He, Wojciech Kryściński, Bryan McCann, Nazneen Rajani, Caiming Xiong CTRLSUM es un modelo de resumen de texto controlable que le permite ajustar las declaraciones resumidas generadas a través de palabras clave o indicaciones descriptivas. Capacitación: para crear un conjunto de datos de resumen controlable basado en palabras clave modificando los datos de resumen general, seleccione Sub-Seguidence, que es el más similar al resumen y extrae la palabra clave allí. Ponga esto en una entrada con el documento y termine el BART previo al ajuste. 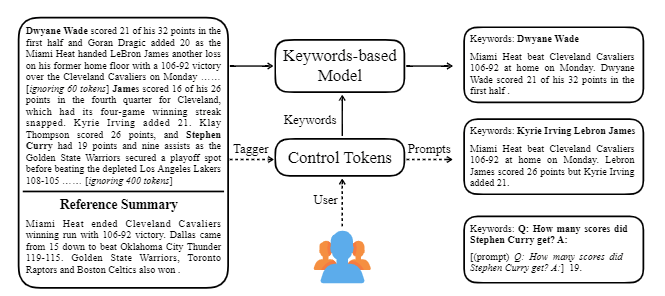 -Inperencia: como se muestra en la imagen a continuación, puede agregar un resumen del resumen, como crear un resumen de una entidad particular, ajustar la longitud de resumen o crear una respuesta a una pregunta. Es de destacar que funciona como si no estuviera aprendiendo explícitamente tales indicaciones en la etapa de modelado, pero funcionó como si fuera a comprender y generar un resumen. Similar a GPT-3. 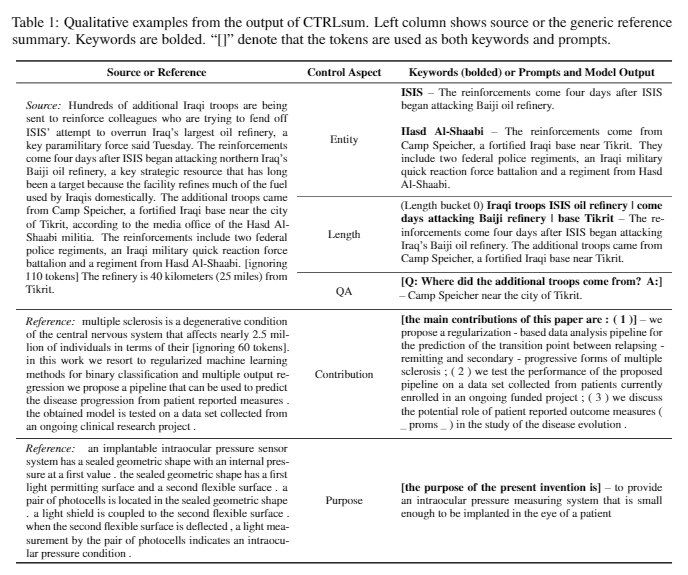 - paquete [biblioteca] para ctrlsum basado en resumen controlable | Controlable, Barbar |
Paper Digest: documentos recientes sobre resumen de texto
Documentos con código: Últimos documentos
EMNLP 2020 Documentos-sumarización
De hecho, hemos resumido los modelos de código, datos y preitrain necesarios para crear y practicar modelos de resumen. Son principalmente datos coreanos, y para materiales relacionados con el inglés, consulte la parte del código de cada artículo en el elemento de los documentos.
El significado del débil que se usa a continuación es el siguiente.
w : valor promedio del número de palabras; s : valor promedio del número promedio de oraciones
Ejemplo) 13s/214w → 1s/26w significa que proporciona un texto resumido que consiste en un promedio de 13 oraciones (promedio de 214 palabras) y un promedio de una oración (26 palabras promedio).
Resumen abs ; ext : resumen extractivo
| Conjunto de datos | Dominio / longitud | Volumen (Par) | Licencia |
|---|---|---|---|
| Resumen del documento de palabras de todos Título del texto de noticias cortos, 3 frase ABS y ext Summay Todas las palabras de todos con identificación combinados con los caballos de los periódicos, puede obtener información adicional relacionada con los subtítulos, los medios de comunicación, la fecha y el tema. | noticias -ORigin → 3s (ABS); 3s (ext) | 13,167 | Instituto Nacional de Lengua Corea (Contrato individual) |
| Texto de resumen del documento de Aihub ABS y EXT SUMMAY para artículos periodísticos, contribuciones, artículos de revistas y reseñas de la corte - [EDA] Data Notebook EDA Resumen de extracción de documentos coreanos -anexo Resumen y resumen de creación AI Concurso (~ 20.12.09) | -El artículo del periódico 300,000, 60,000 contribuciones, 10,000 artículos de revistas, fallo de la corte 30,000 13S/214W → 1S/26W (ABS); 3s/55W (ext) | 400,000 | Aihub (Contrato individual) |
| Aihub-resumen Resumen de ABS por todos y sección para documentos académicos y especificaciones de patentes | -Un documentos académicos, especificaciones de patentes -ORigin → ABS | 350,000 | Aihub (Contrato individual) |
| Resumen de datos de libros de Aihub Resumen de ABS para el libro coreano original sobre varios temas | -LiFETIME, VIDA, Tributar, Medio Ambiente, Desarrollo Comunitario, Comercio, Economía, Trabajo, etc. -300-1000 caracteres → abdominales | 200,000 | Aihub (Contrato individual) |
| sae4k | 50,000 | CC-BY-SA-4.0 | |
| Sci-News-sum-kr-50 | Noticias (TI/Ciencia) | 50 | MIT |
| Wikilingua : un conjunto de datos de resumen abstractivo multilingüe (2020) Basado en el sitio manual wikihow, 18 idiomas como coreano e inglés -Papel, cuaderno de colaboración | -HOY TO DOCS -391W → 39W | 12,189 (Kor en total 770,087) | 2020, CC BY-NC-SA 3.0 |
| Conjunto de datos | Dominio / longitud | Volumen | Licencia |
|---|---|---|---|
| Scisummnet (papel) Proporciona tres tipos de resumen para la investigación de ACL (PNL) -CL-SCISUMM 2019-TASK2 (repositorio, papel) -Cl-Scisumm @ EMNLP 2020-Task2 (Repo) | Presagio de investigación (Lingüistas computacionales, PNL) 4,417W → 110W (resumen de papel); 2s (cita); 151W (ABS) | 1,000 (ABS/ ext) | CC BY-SA 4.0 |
| Pañuelo largo Resumen de la lista relativamente larga (Publicaciones de blog relacionadas con ABS basados en Video de conferencias relacionadas) -ROGNSUMM 2020@EMNLP 2020 -ROGNSUMM 2021@ NAACL 2021 | -Tra de investigación (NLP, ML) -ORigin → 100S/1,500W (ABS); 30s/ 990W (ext) | 700 (ABS) + 1,705 (ext) | Atribución no comercial-sharealike 4.0 |
| Clysumm Proporcione una capa fácil para los no profesionales para los campos NLP y ML. -Cl-laysumm @ emnlp 2020 | -Tapado de investigación (epilepsia, arqueología, ingeniería de materiales) -ORigin → 70 ~ 100W | 600 (abdominales) | Necesidades del acuerdo individual (enviado correo electrónico a [email protected]) |
| Global Voice : Crossing Borders in Automatic News Resumen (2019) -Papel | - noticias -359W → 51W | ||
| Mlsum : el corpus de resumen multilingüe Similar al conjunto de datos CNN/Daily Mail, lo más destacado/descripción en artículos de noticias se considera un resumen y resumen para inglés, francés, alemania, español, ruso y turco de datos de compilación turca -Paper, Usar (Facefactor de Hugging) | - noticias -790W → 56W (Bas) | 1.5m (ABS) | Propósitos de investigación no comerciales solamente |
| Modelo | Pre-entrenamiento | Uso | Licencia |
|---|---|---|---|
| Bert (multilingüe) Bert-Base (parámetros de 110 m) | -Wikipedia (multilingüe) -WordPiece. -110k vocabes compartidos | BERT-Base, Multilingual Cased recomendada( --do_lower_case=false )-Tensorflow | Google (Apache 2.0) |
| Kobert Bert-Base (parámetros de 92m) | -Wikipedia (oración de 5 m), noticias (sentencia de 20 m) -SentencePiece 8,002 vocabes (sin token no utilizado) | -Pytorch -Tal disponible como biblioteca de transformadores de superficie de abrazos a través de Kobert-Transformers (Monologg), Distilkobert disponible | Cerebro skt (Apache-2.0) |
| Korbert Base | -News (10 años), Wikipedia, etc. 23 GB -TRI ANÁLISIS MORFOLÓGICO API / PISTA DE PALABRA (proporcionó dos versiones por separado) -30,349 vocabes Alfabetos latinos: carcasa - [Introducción] Lim Jun (ETRI). NLU Tech Talk con Korbert | -Pytorch, tensorflow | ETRI (Contrato individual) |
| Kcbert Bert-base/grande | -Daver News Comment (12.5GB, 8.9 millones de oraciones) (19.01.01 ~ 20.06.15 Comentarios de artículos en artículos y comentarios) -Tokenizers bertwordPiecTokenizer -30,000 vocabes | Beomi (MIT) | |
| Kobart Bart (124m) | -Wikipedia (5m) y otros (noticias, libro, palabras de todos (conversación, noticias, ...), Cheong wa petición nacional, etc. -La tokenizador BPE de personaje de Tockenizers 30,000 vocabes (incluidos) - [Ejemplo] Seujung. Kobart-Summarization (código, demostración) | -Sommary Task Especialización -Palentador de transformadores de Huggingface -Pytorch | Skt t3k (MIT modificado) |
| Año | Papel |
|---|---|
| 2018 | Una encuesta sobre métodos de resumen basados en redes neuronales Y. Dong |
| 2020 | Revisión de la técnica y métodos automáticos de resumen de texto Widyassari, AP, Rustad, S., Shidik, GF, Noersasongko, E., Syukur, A. y Affandy, A. |
| 2020 | Una encuesta de generación de texto mejorada por el conocimiento Wenhao Yu, Chenguang Zhu, Zaitang Li, Zhiting Hu, Qingyun Wang, Heng Ji, Meng Jiang |
| Año | Papel | Palabras clave |
|---|---|---|
| 1958 | Creación automática de resúmenes de literatura Ph Luhn | Género |
| 2000 | Generación principal basada en la traducción estadística M. Banko, Vo Mittal y MJ Witbrock | Gen-Abs |
| 2004 | LEXRANK : la centralidad léxica basada en gráficos como relevancia en el resumen de texto G. Erkan y Dradev, | Género |
| 2005 | Resumen de documentos individuales basados en extracción de oraciones J. Jagadeesh, P. Pingali y V. Varma | Género |
| 2010 | Generación de títulos con gramática cuasi-sincrono K. Woodsend, Y. Feng y M. Lapata, | Género |
| 2011 | Resumen de texto utilizando análisis semántico latente Mg Ozsoy, Fn Alpaslan e I. Cicekli | Género |
| Año | Papel | Palabras clave |
|---|---|---|
| 2014 | Sobre el uso de vocabulario objetivo muy grande para la traducción del automóvil neuronal S. Jean, K. Cho, R. Memisevic y Yoshua Bengio | Gen-Abs |
| 2015 Modelo | Namas : un modelo de atención neural para resumen abstractivo (código) Am Rush, S. Chopra y J. Weston / EMNLP 2015 Para ir más allá de la selección de oraciones existente y el método de combinación, introducimos la atención de objetivo a fuente en el indicador SEQ2SEQ para crear un resumen abstracto. | abdominales SEQ2SEQ con ATT |
| 2015 | Hacia el resumen abstracto utilizando representaciones semánticas Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 Modelo | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 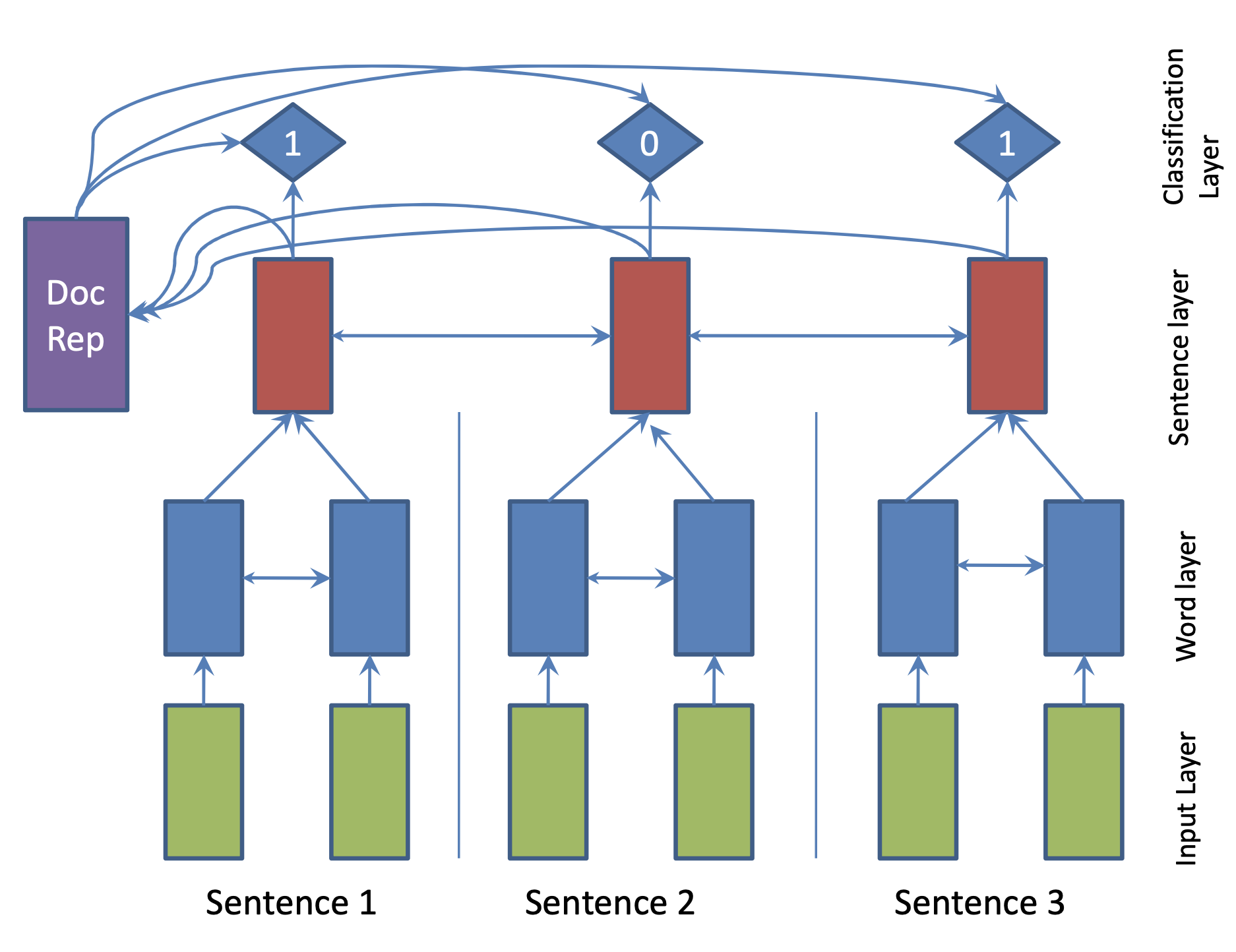 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 Modelo, Técnica | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 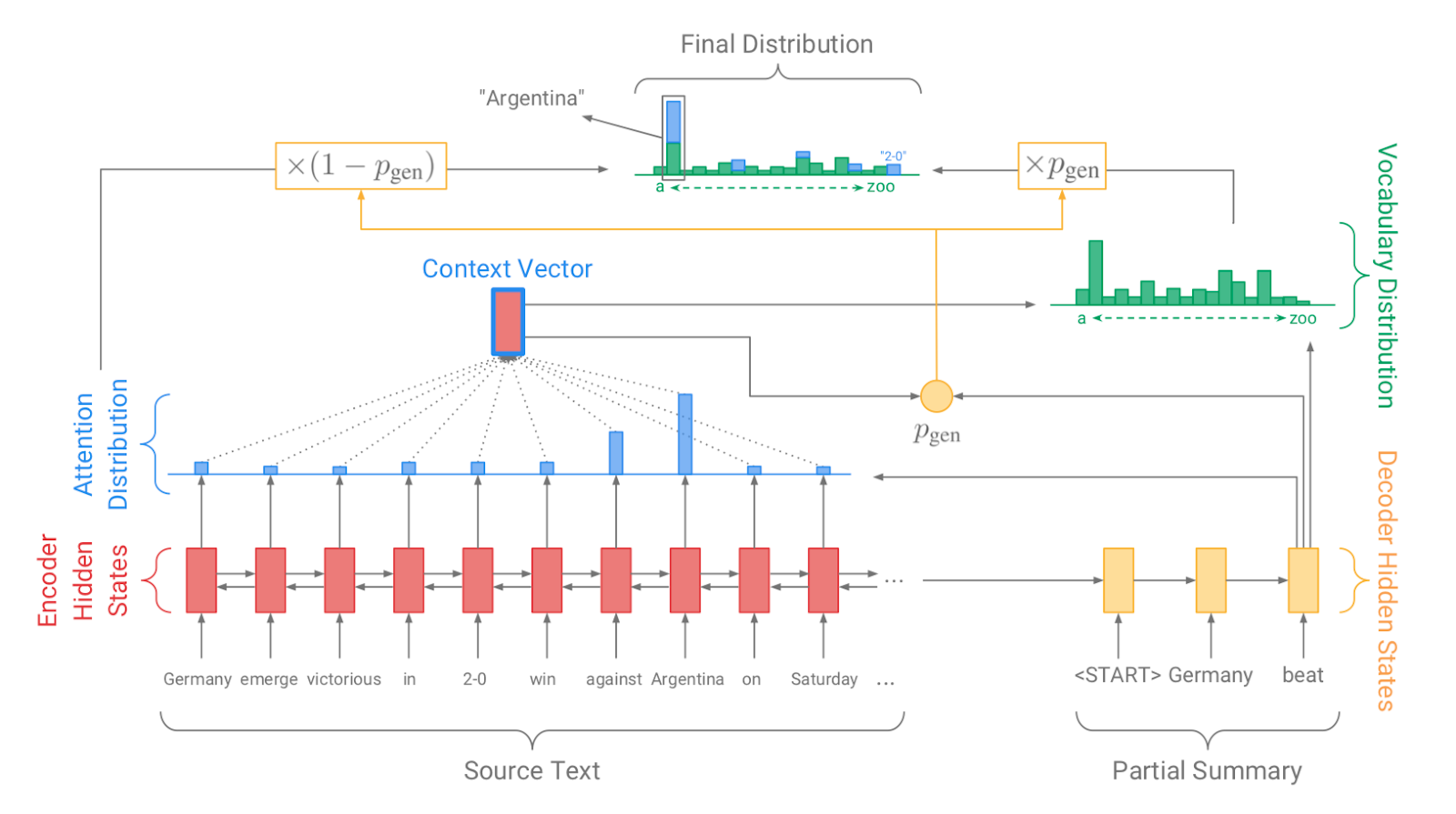 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 Modelo | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 Modelo | De abajo hacia arriba Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, Híbrido, De abajo hacia arriba |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 Modelo | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 Modelo | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 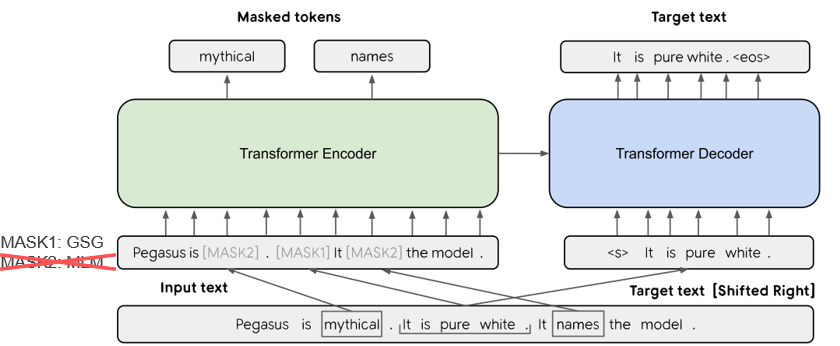 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 Modelo | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


