Text Summarization Repo
1.0.0
من بين NLPs ، إنها مساحة تتراكم بيانات الجودة المتعلقة بحقل ملخص النص. أود أن أكون دليلًا جيدًا لأولئك المهتمين بملخص النص.
بادئ ذي بدء ، نحن نفهم الموضوعات المفصلة التي يلخصها النص الذي يتكون وننظر إلى الأوراق الرئيسية التي قادت هذا الحقل. منذ ذلك الحين ، قمنا بإدراج الكود ومجموعات البيانات ونماذج ما قبل الرافعة اللازمة لإنشاء نموذج ملخص نص مباشر.
مقدمة لتلخيص النص
أوراق
موارد
آحرون
يحدد بيري ، دوميس ، وأوبراين (1995) ملخص النص على النحو التالي:
تلخيص النص هو عملية تقطير أهم المعلومات من نص لإنتاج مهمة ومستخدم معين
إنها عملية تحسين المعلومات المهمة فقط بين النص الوارد في كلمة ما. هنا ، إن التعبير عن التكرير وأهمية المهمة هو تعبير مجردة وذاتية إلى حد ما ، لذلك أريد شخصياً تحديده على النحو التالي.
f(text) = comprehensible information
بمعنى آخر ، يتمثل ملخص النص في تحويل النص الأصلي إلى معلومات سهلة وقيمة . من الصعب رؤية البشر في لمحة عن معلومات النص ، والتي يتم تقسيمها إلى عدة مستندات. في بعض الأحيان لا تعرف الكثير من المصطلحات المهنية. من المهم للغاية أن تعكس هذه النصوص في شكل بسيط وسهل التفاهم مع عكس النص الأصلي جيدًا. بالطبع ، ما هو جدير بالاهتمام حقًا وكيفية تغييره سوف يختلف باختلاف الغرض من تلخيص الأذواق الشخصية أو الأذواق الشخصية.
من وجهة النظر هذه ، يمكن القول أن النص لا يلخص فقط المهام التي تنشئ نصوصًا مثل الدقائق ، وعنوان مهندس الصحف ، وملخص الورق ، واستئناف ، وكذلك المهام التي تقوم بتحويل النص إلى رسومات بيانية أو صور. بالطبع ، نظرًا لأنه ليس مجرد تلخيص ، فهو تلخيص نص ، وبالتالي فإن مصدر الملخص محدود في شكل نص. (ملخص الملخص هو أنه لا يمكن أن يكون فقط نصًا أو فيديوًا بالإضافة إلى نص. على سبيل المثال ، المثال السابق هو توضيح الصورة ، المثال الأخير هو تلخيص الفيديو. بالنظر إلى اتجاه التعلم العميق الأخير عندما يكون الحدود بين الرؤية و NLP تصبح ضبابية ، قد يكون من غير المعقول وضع "نص".
بشكل عام ، تنقسم مهمة ملخص النص إلى تلخيص استخراجي (يشار إليه فيما يلي باسم Ext) والتلخيص الجذاب (ABS) ، اعتمادًا على كيفية توليد ملخص. (Gudivada ، 2018)
الطرق الاستخراجية ، حدد مجموعة فرعية من الكلمات أو العبارات أو الجمل الموجودة في النص الأصلي لتشكيل ملخص. على النقيض من ذلك ، تقوم الأساليب الجذابة أولاً ببناء تمثيل دلالي داخلي واستخدام تقنية الأجيال الطبيعية.
عادة ما يسجل Ext أهمية الجملة ، ثم يختارها وتجمعها لإنشاء ملخص. إنه مشابه لمهمة رسم أداة تمييز أثناء القراءة. من ناحية أخرى ، تعتمد ABS على النص الأصلي ، ولكنها طريقة NLG (توليد اللغة الطبيعية) التي تولد نصًا جديدًا . من غير المرجح أن تتضمن EXT تعبيرات تقتصر على التعبيرات بسبب النص في النص الأصلي. ABS ، من ناحية أخرى ، تتمتع بميزة أن هناك إمكانية لإنشاء تعبير غير مسبوق لأنه يجب أن ينشئ نصًا جديدًا في النموذج ، لكن له مقاربات أكثر مرونة.
بالإضافة إلى ذلك ، وفقًا لعدد النصوص الأصلية ، وفقًا لنموذج النص لتلخيص الوثيقة الفردية/المتعددة ، والكلمة الرئيسية/تلخيص الجملة ، وفقًا لمقدار المعلومات الخارجية المستخدمة في عملية الملخص ، وفقًا لعملية الملخصات ، توجد فروق مختلفة مثل التلخيص.
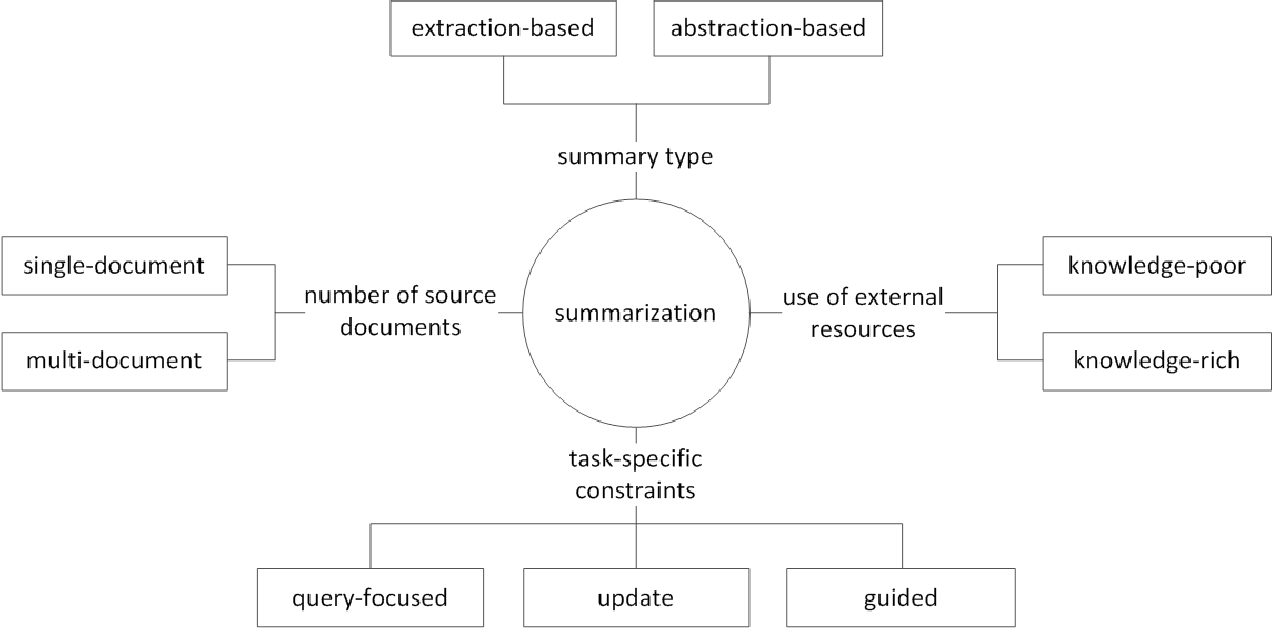
(G. Sizov (2010). تلخيص أوتوماتيكي يستند إلى الاستخراج: التحقيق النظري والتجريبي لتقنيات التلخيص
دعونا نلقي نظرة على موضوعات البحث الرئيسية في مجال تلخيص النص وفكر في نوع التحدي في هذا المجال.
تلخيص المستندات المتعددة / الطويلة
كما ذكرنا سابقًا ، تتمثل المهمة الموجزة في تغيير النص غير المفهوم إلى معلومات مفهومة. لذلك ، كلما طال الوقت النص الأصلي ، أو ملخص مستندات مصادر متعددة ، وليس وثيقة واحدة ، كلما زادت فائدة الملخص. المشكلة هي أنه في الوقت نفسه ، تزداد صعوبة الملخص أيضًا.
لهذا السبب ، كلما طال الوقت النص الأصلي ، زادت سرعة التعقيد الحسابي. هذه مشكلة أكثر أهمية في الأساليب الحديثة التي تعتمد على الشبكة العصبية بما في ذلك المحول من الأساليب الإحصائية مثل Textrank في الماضي. ثانياً ، كلما طال الوقت النص الأصلي ، كلما لم يكن جوهر المحتويات ، أي الضوضاء. ليس من السهل تحديد ما هو الضوضاء وما هو مفيد. أخيرًا ، تحتوي النصوص الطويلة والمصادر المختلفة على وجهات نظر ومحتويات مختلفة في نفس الوقت ، مما يجعل من الصعب إنشاء ملخص يغطيه جيدًا.
تلخيص الوثائق المتعددة (MDS)
MDS هو ملخص لعدد الوثائق . للوهلة الأولى ، سيكون من الصعب تلخيص مقالات وجهات النظر المختلفة لمختلف المؤلفين من تلخيص وثيقة تصف موضوع واحد من اتجاه ثابت ووجهة نظر. بالطبع ، حتى في حالة MDS ، فإنه يعتمد عادةً على نفس المستند العناسي الذي يتعامل مع مواضيع مماثلة ، لكن ليس من السهل تحديد المعلومات المهمة وتصفية المعلومات الخارجية بين العديد من المستندات.
المهمة ، التي تلخص المراجعات على بعض المنتجات ، هي مثال على MDS التي هي الأسهل للتفكير. تتميز هذه المهمة ، التي تسمى عادةً تلخيص الرأي ، بطول نص قصير وذاتية. يمكن أيضًا اعتبار عمل إنشاء وثيقة ويكي بمثابة MDS. ليو وآخرون. (2018) هو النص الأصلي لنص موقع الويب على مستند Wiki ، وهو النص الأصلي ، والذي يعتبر ملخصًا ، ويخلق نموذج إنشاء ويكي.
الوثائق الطويلة تلخيص
ليو وآخرون. (2018) هي وسيلة إحصائية لقبول النص الطويل كمدخلات ، وإنشاء ملخص مقترح ، باستخدام جمل مهمة فقط واستخدامه كمدخل للنموذج. بالإضافة إلى ذلك ، من أجل تقليل حجم الحوسبة المحول ، يتم تقسيم المدخلات إلى وحدات كتلة ، وفي هذا الوقت ، يستخدم الالتفاف 1-D طريقة ATTENSION التي تقلل من عدد مفتاح الاهتمام الفردي والقيمة. تقدم ورقة Big Bird (2020) آلية Attension متفرقًا (خطية) بدلاً من مجموعة من جميع الكلمات الموجودة لتقليل حساب المحول. نتيجة لذلك ، تم تلخيص نفس أجهزة الأداء حتى ثماني مرات أطول.
من ناحية أخرى ، يحاول Gidiotis & Tsoumakas (2020) الاقتراب من الفجوة والقهر ، والتي لا تحل مشكلة ملخص النص الطويلة في وقت واحد وتحولها إلى عدة ملخصات نصية صغيرة. تدريب النموذج عن طريق تغيير النص الأصلي والملخص المستهدف إلى أزواج متعددة أصغر المصدر المستهدفة. في الاستدلال ، نقوم بتجميع الملخصات الجزئية إخراج من خلال هذا النموذج لإنشاء ملخص كامل.
تحسين الأداء
كيف يمكنك إنشاء ملخص أفضل؟
نقل التعلم
في الآونة الأخيرة ، أصبح استخدام نموذج pretRaining في NLP افتراضيًا تقريبًا. إذن ما نوع الهيكل الذي يجب أن ننشئه نموذجًا لتمثيل التجميل يمكنه إظهار أداء أفضل في تلخيص النص؟ ما هو الشيء الذي يجب أن أمتلكه؟
في Pegasus (2020) ، تفترض طريقة GSG (جمل جمل GAP) ، والتي تختار جملة تعتبر مهمة استنادًا إلى درجة Rouge ، أنه كلما كان أكثر تشابهًا مع عملية ملخص النص ، سيظهر الاعتراض الأداء الأعلى. يتعلم نموذج SOTA الحالي ، BART (2020) (محولات الانحدار ثنائية الاتجاه وذات التلقائي) ، في شكل مشفر تلقائي يضيف ضوضاء إلى بعض نص الإدخال ويستعيده كنص أصلي.
جيل النص المعروف المعروف
في مهمة النص إلى النص ، غالبًا ما يكون من الصعب إنشاء الإخراج المطلوب مع النص الأصلي وحده. لذلك ، هناك محاولة لتحسين الأداء من خلال توفير مجموعة متنوعة من التعرف على النموذج وكذلك النص الأصلي . يختلف مصدر أو توفير هذه المعرفة في أنواع مختلفة من الكلمات الرئيسية ، والمواضيع ، والميزات اللغوية ، وقواعد المعرفة ، والرسوم البيانية المعروفة ، والنص الأساسي.
على سبيل المثال ، يقدم Tan و Qin و Xing و Hu (2020) مجموعة بيانات عامة للاستدعاء لتحويل مجموعة من الملخصات المستندة إلى الجانب ، وتقدم معلومات أكثر ثراءً تتعلق بجانب معين إلى جانب معين للنموذج. استخدم ويكيبيديا ل. إذا كنت تريد معرفة المزيد ، يو وآخرون. اقرأ ورقة المسح التي كتبها (2020).
بعد التحرير
سيكون من الجيد إنشاء ملخص جيد في وقت واحد ، لكن الأمر ليس بالأمر السهل. فلماذا لا تقوم بإنشاء ملخص ثم مراجعة وتعديله في مجموعة متنوعة من المعايير؟
على سبيل المثال ، يقترح CAO و Dong و Wu و Cheung (2020) طريقة للحد من الخطأ الواقعية من خلال تطبيق نموذج المصاحب العصبي المذاهر على الملخص الذي تم إنشاؤه.
بالإضافة إلى ذلك ، هناك أيضًا العديد من المحاولات لتطبيق ** Graph Neural Network (GNN) ** ، والتي كانت تحصل على الكثير من الاهتمام مؤخرًا.
مشكلة ندرة البيانات
ملخص النص هو مهمة تستغرق الكثير من الوقت ، وهو أمر ليس من السهل على البشر. لذلك ، بالمقارنة مع المهام الأخرى ، فإنه يكلف تكاليف أكبر نسبيًا لإنشاء مجموعة بيانات ذات علامات ، وبالطبع ، هناك نقص في البيانات للتدريب.
بالإضافة إلى طريقة التعلم النقل باستخدام نموذج ما قبل الرصاص المذكور مسبقًا ، فإننا نتعلم في أساليب التعلم أو التعلم غير الخاضع للإشراف أو محاولة نهج التعلم قليلًا .
وبطبيعة الحال ، يعد إنشاء بيانات ملخص جيدة أيضًا موضوع بحث مهم للغاية. على وجه الخصوص ، العديد من مجموعات البيانات المتعلقة بالتلخيص الحالية منحازة في أنواع الأخبار في اللغة الإنجليزية. نتيجة لذلك ، يتم إنشاء مجموعات بيانات متعددة اللغات مثل Wikilingua و MLSUM. لمزيد من المعلومات ، ألقِ نظرة على MLSUM: مجموعة التلخيص متعددة اللغات.
طريقة القياس / التقييم
كتبت تعبيرًا ساحقًا عن "الخير" في وقت سابق. ما هو "ملخص جيد"؟ Brazinskas ، Lapata ، & Titov (2020) تستخدم الأشياء الخمسة التالية بناءً على حكم ملخص جيد.
المشكلة هي أنه ليس من السهل قياس هذه الأجزاء. مؤشر قياس الأداء الأكثر شيوعًا في ملخصات النص هو درجة Rouge. هناك العديد من المتغيرات في درجة Rouge ، ولكن في الأساس "كيف هي كلمة كلمة الملخص الذي تم إنشاؤه والملخص المرجعي؟" هذا يعني مشابهًا ، ولكن إذا كان لديك نموذج مختلف أو إذا تغير ترتيب الكلمة ، فيمكنك الحصول على درجة أقل حتى لو كان ملخصًا أفضل. على وجه الخصوص ، في محاولة لرفع درجة Rouge ، يمكن أن يؤدي إلى إيذاء التنوع التعبيري للملخص. هذا هو السبب في أن العديد من الأوراق توفر نتائج تقييم بشرية إضافية بأموال باهظة الثمن بالإضافة إلى درجة Rouge.
لي وآخرون. (2020) يعرض RDASS (النتيجة الدلالية المرجعية والوثيقة) ، وهو ما يشبهه مع الملخص النص والمرجع ، ثم تقاس بطرق مماثلة قائمة على المتجه. من المتوقع أن تزيد هذه الطريقة من دقة تقييم اللغة الكورية ، والتي تجمع بين الكلمات والمورفولوجيا المختلفة للتعبير عن المعاني المختلفة والوظائف النحوية. اقترح Kryściński و McCann و Xiong و Socher (2020) نهجًا ضعيفًا قائمًا على النموذج لتقييم الاتساق الواقعية.
توليد نص يمكن التحكم فيه
هل هناك أفضل ملخص واحد فقط عن وثيقة معينة؟ لن يفعل ذلك. يمكن للأشخاص ذوي الميول المختلفة أن يفضلوا نصوص موجزة مختلفة لنفس النص. حتى لو كنت نفس الشخص ، فإن الملخص الذي تريده سيعتمد على الغرض من تلخيص أو الموقف. تسمى طريقة ضبط الإخراج على النموذج المطلوب وفقًا للشروط المحددة من قبل المستخدم توليد النص القابل للتحكم . يمكنك توفير ملخص مخصص مقارنة بالتلخيص العام الذي يخلق نفس الملخص لمستند معين.
لا ينبغي أن يكون الملخص الذي يتم إنشاؤه سهلاً فحسب ، بل يرتبط أيضًا ارتباطًا وثيقًا بالشرط الذي تضعه معًا.
f(text, condition ) = comprehensible information that meets the given conditions
ما هي الحالة التي يمكنني إضافتها إلى نموذج الموجزة؟ وكيف يمكنك إنشاء ملخص يناسب هذا الشرط؟
تلخيص قائم على الجانب
عند تلخيص مراجعات مستخدمي AirPod ، قد ترغب في تلخيص كل جانب بتقسيم جودة الصوت والبطارية والتصميم. أو قد ترغب في ضبط نمط الكتابة أو المشاعر في المقالة. في هذا النص الأصلي ، يسمى العمل الذي يلخص فقط المعلومات المتعلقة بالجوانب أو الميزات المحددة الملخص القائم على الجانب .
في السابق ، تم الآن محاولة النماذج التي عملت فقط في الجانب المحدد مسبقًا ، والتي تم استخدامها بشكل أساسي للتعلم النموذجي ، للسماح بتفكير الجانب التعسفي ، والذي لم يتم منحه للتعلم مثل Tan و Qin و Xing و Hu (2020).
تلخيص تركيز الاستعلام (QFS)
إذا كانت الحالة استعلامًا ، فسيسمى QFS. يعد الاستعلام لغة طبيعية بشكل أساسي ، وبالتالي فإن المهمة الرئيسية هي كيفية القيام بهذه التعبيرات المختلفة بشكل جيد وتطابقها مع النص الأصلي. إنه مشابه تمامًا لنظام ضمان الجودة الذي نعرفه جيدًا.
تحديث تلخيص
البشر حيوانات لا تزال تتعلم وتنمو. لذلك ، يمكن أن تكون قيمة اليوم لبعض المعلومات مختلفة تمامًا عن قيمة أسبوع بعد ذلك. سيتم تخفيض قيمة المحتويات في المستند الذي مررت به بالفعل ، وسيظل المحتويات الجديدة التي لم يتم خبرةها ذات قيمة عالية. من وجهة النظر هذه ، يطلق عليه اسم "تلخيص التحديث" لإنشاء ملخص جديد لمحتوى جديد يشبه محتويات المستند التي عانى منها المستخدم سابقًا .
يأخذ Ctrlsum العديد من الكلمات الرئيسية أو المطالبات الوصفية مع النص لضبط الملخص الذي تم إنشاؤه. إنه نموذج تلخيص نص أكثر عمومية يمكن التحكم فيه من حيث أنه يظهر نفس النتائج التي يتم التحكم فيها في الكلمات الرئيسية أو المطالبات التي لم يتم تعلمها بشكل صريح في مرحلة التدريب. يمكنك بسهولة استخدامه من خلال مكتبة ملخص Koh Hyun -Woong.
بالإضافة إلى ذلك ، فإن مجموعة متنوعة من المحاولات لإنشاء نموذج موجز مناسب لتلخيص المحادثة بدلاً من موضوع DL النموذجي مثل ** Model Lightweight ، بالإضافة إلى ملخص للحوار بدلاً من نص منظم مثل الأخبار أو ويكيبيديا. هناك مواضيع.
إذا كنت تعرف ما يلي في حقل ملخص النص ، فستتمكن من الدراسة بسهولة أكبر.
فهم مفهوم NLP الأساسي
هيكل المحول/بيرت وفهم موضوعية ما قبل التدريب
تعتمد العديد من أحدث أوراق NLP على العديد من النماذج المسبقة ، بما في ذلك BERT ، استنادًا إلى Transformer و Roberta و T5 ، وهي متغيرات من هذا Bert. لذلك ، إذا فهمت هيكلها التخطيطي وهدف ما قبل التدريب ، فهي مساعدة كبيرة في قراءة أو تنفيذ ورقة.
تلخيص النص المفهوم الأساسي
الشبكة العصبية الرسم البياني (GNN)
الترجمة الآلية (MT)
MT هي واحدة من أكثر المهام نشاطًا في حقل NLP منذ ظهور SEQ2Seq. إذا نظرت إلى عملية التلخيص كعملية لتحويل نص واحد إلى نوع مختلف من النص ، فيمكن اعتباره نوعًا من MT ، من المحتمل أن يتم استعارة أو تطبيق الكثير من الدراسات والأفكار المتعلقة بـ MT في حقل التلخيص.
| سنة | ورق | الكلمات الرئيسية |
|---|---|---|
| 2004 نموذج | Textrank : إحضار النظام إلى النصوص R. Mihalcea ، P. Tarau إنه كلاسيكي في قطاع الاستخراج ولا يزال نشطًا. في افتراض أن الجملة المهمة داخل الوثيقة (أي ، المدرجة في الملخص) هي خوارزمية Pagerank ، الفكرة الأولية لمحرك بحث Google ، على افتراض أنه سيكون لها تشكيلات عالية مع جمل أخرى. تقوم كل جملة بتكوين رسم بياني مرجح على مستوى الجملة لحساب التشابه مع جملة أخرى في المستند ، ويتضمن هذه الجملة عالية الوزن في الملخص. يمكن أن تكون أساليب التعلم غير الخاضعة للرقابة الإحصائية معقولة بدون بيانات تعليمية منفصلة ، والخوارزمية واضحة وسهلة الفهم. - [Library] Gensim.Summarization (إصدار 3.x فقط متاح. حذف من الإصدار 4.x) ، pytextrank - [نظرية/رمز] Lovit. استخراج الكلمات الرئيسية باستخدام TextTrank و Core Secence Extract | تحويلة ، يعتمد على الرسم البياني (Pagerank) ، غير خاضع للإشراف |
| 2019 نموذج | بيرتسوم : تلخيص النص مع المشفرات المذاعفة (Officeiad) يانغ ليو ، ميريلا لاباتا / EMNLP 2019 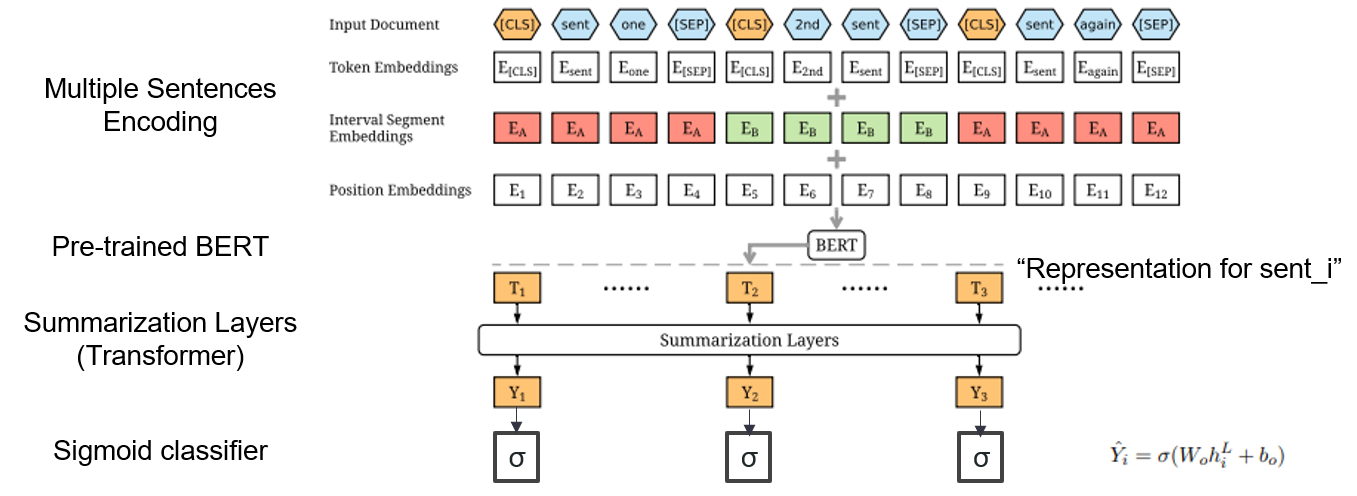 كيف يمكنني استخدام BERT مسبقًا في ملخص؟ كيف يمكنني استخدام BERT مسبقًا في ملخص؟يقترح Bertsum تضمينات مدخلات معدلة تدخل الرموز [CLS] أمام كل جملة وتضيف تضمينات فاصل فاصل لإضافة جملة متعددة إلى إدخال واحد. يستخدم نموذج EXT بنية تشفير مع طبقات محول على BERT ، ويستخدم طراز ABS نموذج ترميز التشفير مع وحدة فك ترميز محول 6 طبقات على نموذج EXT. - [مراجعة] لي يونج -هيون (كوريونيف DSBA) - [كوري] كوبرتسيوم | Ext/ABS ، Bert+Transformer ، 2 صقل غرامة |
| 2019 نموذج ما قبل | بارت : تقليل التسلسل إلى التسلسل قبل التدريب لتوليد اللغة الطبيعية وترجمة والفهم مايك لويس ، يينهان ليو ، نامان جويال ، مارجان غازفينجاد ، عبد الرحمن محمد ، عمر ليفي ، فيس ستويانوف ، لوك زيتلموير / ACL 2020 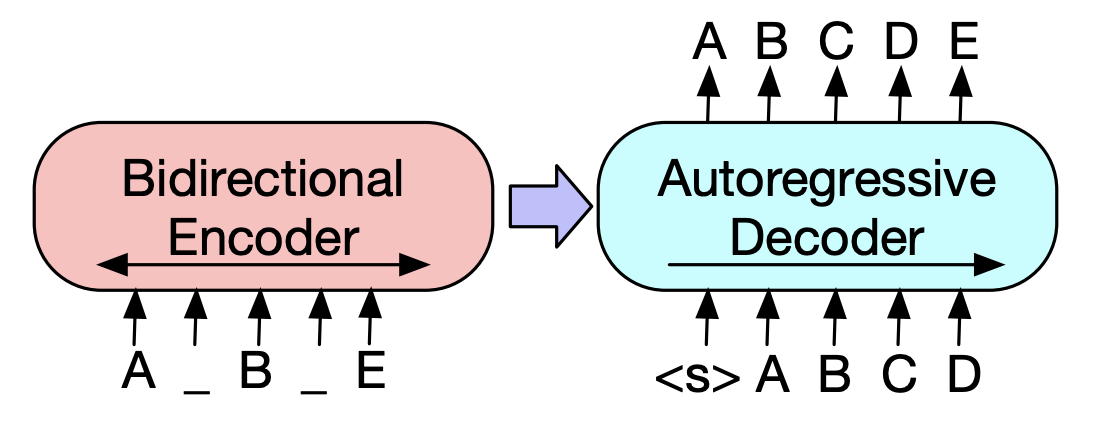 BERT هو مشفر ثنائي الطر ، ضعيف في مهام التوليد ، و GPT لديه عيب على أنه لا يحصل على معلومات تم تجميعها مع نموذج الانحدار التلقائي. BERT هو مشفر ثنائي الطر ، ضعيف في مهام التوليد ، و GPT لديه عيب على أنه لا يحصل على معلومات تم تجميعها مع نموذج الانحدار التلقائي.يحتوي BART على نموذج SEQ2SEQ يجمع بينها ، بحيث يمكنك تجربة العديد من التقنيات التي تنكر في نموذج واحد. ونتيجة لذلك ، فإن النصوص النصية (يغير امتداد النص إلى رمز قناع واحد) ويظهر الجملة خلط (خلط عشوائي الجملة) الأداء الذي يتجاوز نموذج Ki Sota في مجال التلخيص. - [الكورية] SKT T3K. كوبارت -[مراجعة] Jin Myung -Hoon_Video ، Lim Yeon -SO_ كتبه Jiwung Hyun_ | القيمة المطلقة ، seq2seq ، دقة تلقائية ، نصوص النص |
| 2020 نموذج | Matchsum : تلخيص الاستخراج كمطابقة نصية (Office) Ming Zhong ، Pengfei Liu ، Yiran Chen ، Danqing Wang ، Xipeng Qiu ، Xuanjing Huang / ACL 2020 - [مراجعة] يو كيونغ (كوريونيف DSBA) | تحويلة |
| 2020 تقنية | تلخيص النص على أي جوانب: نهج إشراف ضعيف المعرفة (الكود الرسمي) Bowen Tan ، Lianhui Qin ، Eric P. Xing ، Zhiting Hu / Emnlp 2020 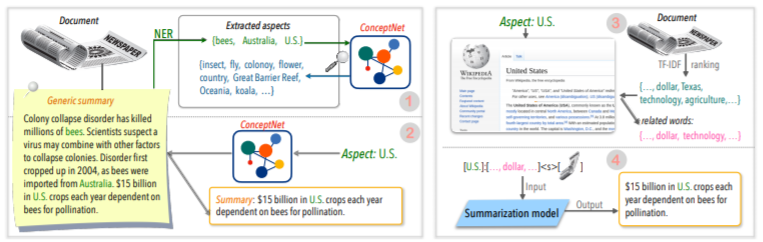 الملخص القائم على الجانب هو مهمة ليست سهلة من حيث أنها تعمل فقط في الجوانب المحددة مسبقًا للبيانات ، والتي يتم تعلمها حتى لو تعلمت النموذج ، و 2) عدم وجود بيانات متعددة تستند إلى جانب الجوانب. تستخدم هذه الورقة مصادر المعرفة الخارجية لحل هذه المشكلة. -يمر بخطوتين لتحويل ملخص عام إلى ملخصات متعددة تستند إلى جانب. بادئ ذي بدء ، لزيادة عدد الجوانب ، فإن الكيان المستخرج من ملخص عام يتم استخلاصه من concepnet إلى جيرانه والنظر في كل واحد منهم كجانب. نستخدم concepnet مرة أخرى لإنشاء ملخص psedo لكل من هذه الجوانب. استخراج الكيان المحيط المتصل بالجانب المقابل في concepnet ، واستخرج الجمل فقط التي تحتوي عليها ضمن ملخص عام. يعتبر هذا ملخصًا لهذا الكيان (الجانب). -يتم استخدام Wikipedia لتقديم المزيد من المعلومات الوفيرة المتعلقة بالجانب المحدد للنموذج. على وجه التحديد ، من بين الكلمات التي تظهر في المستند ، تتوافق درجة TF-IDF في المستند وفي نفس الوقت ، وفي الوقت نفسه ، تتوافق قائمة 10 كلمات في صفحة ويكيبيديا مع هذا الجانب مع الجانب مع إدخال النموذج. وبهذه الطريقة ، كان نموذج التمثيل المسبق للضوء (BART) ممتازًا أيضًا للجانب التعسفي مع بيانات صغيرة. | قائم على الجانب ، غني نولج |
| 2020 مراجعة | ماذا سرعان ما نرسل النص؟ Dandan Huang ، Leyang Cui ، Sen Yang ، Guangsheng Bao ، Kun Wang ، Jun Xie ، Yue Zhang / EMNP 2020 بالإضافة إلى درجة Rouge ، يتم تقييم 10 نماذج ملخص تمثيلية وفقًا لـ 8 مقاييس (polytope) المتعلقة بالدقة والطلاقة. لتلخيص النتائج ، -الطريقة التقليدية القائمة على القواعد لا تزال صالحة كخط أساسي. في ظل إعدادات مماثلة ، يُظهر نموذج EXT عمومًا أداءً أفضل في المؤمنين والإجازة الواقعية. القصور الرئيسي هو عدم التغلب على النماذج الاستخراجية ، والإغفال والهلوسة الجوهرية للنماذج المفعمة بالحيوية. -الهياكل الأكثر تعقيدًا مثل المحولات لإنشاء تمثيل الجملة ليست مفيدة للغاية باستثناء مشكلة الازدواجية. -Copy ( المولد المؤشر ) هو تفاصيل إعادة إنتاج ، والتي تحل بشكل فعال مشكلة ازدواجية مستوى الكلمة عن طريق مزجها وكذلك عدم الدقة جوهرية. ولكن يميل إلى التسبب في التكرار إلى حد ما. التغطية هي بهامش كبير ، مما يقلل من أخطاء التكرار (الازدواجية) ، ولكن في نفس الوقت يزيد من الخطأ الجوهري وعدم الدقة -نموذج Hybrid ، وهو ABS بعد تحويلة ، مفيد للاستدعاءات ، ولكن قد تكون هناك مشاكل مع خطأ في عدم الدقة لأنه يولد ملخصًا من خلال بعض النص الأصلي (المقتطفات المستخرجة). ما قبل التدريب ، وخاصة نموذج التشفير-ترميز (BART) من نموذج التشفير فقط (BertSumextabs) فعال للغاية في الملخص. هذا يشير إلى أن خلل كل فهم وإنشاء الإدخال مفيد للغاية لاختيار المحتوى والمجموع. في الوقت نفسه ، في حين تركز معظم نماذج ABS على الجملة الأمامية ، فإن Bart يبحث في جميع النص الأصلي ، والذي يبدو أنه تأثير الجملة الخلطية أثناء التجهيز.  - [مراجعة] كيم هان -جيل ، هيو هون | مراجعة |
| 2020 نموذج | Ctrlsum : نحو تلخيص النص العام (الكود الرسمي) Junxian He ، Wojciech Kryściński ، Bryan McCann ، Nazneen Rajani ، Caiming Xiong Ctrlsum هو نموذج لتلخيص النص يمكن التحكم فيه يتيح لك ضبط عبارات الملخص التي تم إنشاؤها من خلال الكلمات الرئيسية أو المطالبات الوصفية. التدريب: من أجل إنشاء مجموعة بيانات ملخصية يمكن التحكم فيها في الكلمات الرئيسية عن طريق تعديل بيانات الموجزة العامة ، وتحديد التسلسلات الفرعية ، والتي تشبه الملخص ، واستخراج الكلمة الرئيسية هناك. ضع هذا في مدخلات مع المستند وإنهاء BART قبل الضبط. 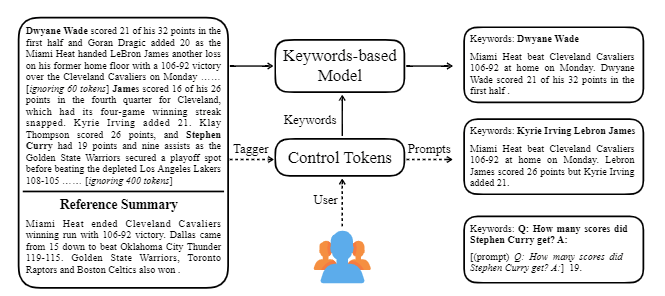 -Inperence: كما هو موضح في الصورة أدناه ، يمكنك إضافة ملخص للملخص ، مثل إنشاء ملخص لكيان معين ، أو ضبط طول الملخص ، أو إنشاء رد على سؤال. من الجدير بالملاحظة أنه يعمل كما لو أنه لم يتعلم بشكل صريح مثل هذه المطالبات في مرحلة النمذجة ، لكنه عمل كما لو كان يفهم المطالبة وتوليد ملخص. على غرار GPT-3. 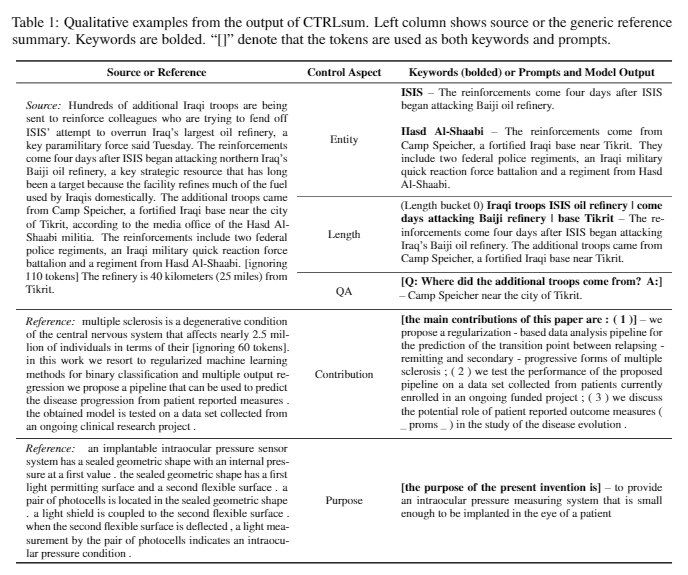 - [مكتبة] حزمة ل ctrlsum القابلة للتصوير القابلة للتحكم | يمكن السيطرة عليها ، بارت |
Paper Digest: الأوراق الحديثة حول تلخيص النص
أوراق مع رمز: أحدث الأوراق
EMNLP 2020 الأوراق
في الواقع ، لقد قمنا بتلخيص النماذج الكود والبيانات و pretrain اللازمة لإنشاء نماذج ملخص وممارسة. إنها البيانات الكورية بشكل أساسي ، وبالنسبة للمواد ذات الصلة باللغة الإنجليزية ، يرجى الرجوع إلى جزء الكود من كل ورقة في عنصر الأوراق.
معنى الضعيف المستخدم أدناه كما يلي.
w : متوسط قيمة عدد الكلمات ؛ s : متوسط قيمة متوسط عدد الجمل
مثال) 13s/214w → 1s/26w يعني أنه يوفر نصًا موجزًا يتكون من 13 جملة (متوسط 214 كلمة) ومتوسط جملة واحدة (متوسط 26 كلمة).
ملخص abs ؛ ext : ملخص استخراجي
| مجموعة البيانات | المجال / الطول | مقدار (زوج) | رخصة |
|---|---|---|---|
| ملخص كلمات الجميع عنوان نص الأخبار القصير ، 3 جملة ABS و Sext Summay جميع كلمات كل شخص مع معرف معرف مع خيول الصحف ، يمكنك الحصول على معلومات إضافية تتعلق بالترجمات والوسائط والتاريخ والموضوع. | أخبار -الأوريغن → 3s (ABS) ؛ 3S (تحويلة) | 13167 | المعهد الوطني للغة الكورية (العقد الفردي) |
| نص ملخص Aihub-Document ABS و EXT Summay لمقالات الصحف ، والمساهمات ، ومقالات المجلات ، ومراجعات المحكمة - [EDA] دفتر EDA Data -ملخص ملخص لاستخراج الوثائق الكورية وملخص الخلق مسابقة AI (حوالي 20.12.09) | -صحيفة المادة 300،000 ، 60،000 مساهمات ، 10000 مقالة مجلة ، حكم المحكمة 30،000 13S/214W → 1S/26W (ABS) ؛ 3S/55W (تحويلة) | 400000 | aihub (العقد الفردي) |
| aihub-summary ملخص ABS من قبل الجميع وقسم الأوراق الأكاديمية ومواصفات براءات الاختراع | -أوراق أكاديمية ومواصفات براءات الاختراع -الأوريغن → ABS | 350،000 | aihub (العقد الفردي) |
| ملخص بيانات AIHub-Book ملخص ABS للكتاب الكوري الأصلي حول مواضيع مختلفة | -lifetime ، الحياة ، الضرائب ، البيئة ، تنمية المجتمع ، التجارة ، الاقتصاد ، العمالة ، إلخ. -300-1000 حرف → ABS | 200000 | aihub (العقد الفردي) |
| SAE4K | 50000 | CC-BY-SA-4.0 | |
| Sci-News-Sum-KR-50 | أخبار (IT/Science) | 50 | معهد ماساتشوستس للتكنولوجيا |
| Wikilingua : مجموعة بيانات تلخيص متعددة اللغات (2020) بناءً على الموقع اليدوي ويكيهو ، 18 لغة مثل الكورية والإنجليزية -ورق ، دفتر الملاحظات | -كيف للمستندات -391W → 39W | 12،189 (Kor في المجموع 770،087) | 2020 ، CC BY-NC-SA 3.0 |
| مجموعة البيانات | المجال / الطول | مقدار | رخصة |
|---|---|---|---|
| Scisummnet (ورقة) يوفر ثلاثة أنواع من الملخص لأبحاث ACL (NLP) -CL-SCISUMM 2019-TASK2 (repo ، paper) -CL-SCISUMM @ EMNLP 2020-TASK2 (REPO) | ورقة البحث (اللغويين الحسابيين ، NLP) 4،417W → 110W (Paper Abstract) ؛ 2S (الاقتباس) ؛ 151W (ABS) | 1000 (ABS/ EXT) | CC BY-SA 4.0 |
| Longsumm ملخص طويل نسبيًا (منشورات المدونة ذات الصلة -ABS المستندة إلى ABS ، محادثات الفيديو المؤتمرات ذات الصلة) -longsumm 2020@emnlp 2020 -longsumm 2021@ NAACL 2021 | -ورقة البحث (NLP ، ML) -Rigin → 100S/1500W (ABS) ؛ 30S/ 990W (تحويلة) | 700 (ABS) + 1،705 (تحويلة) | إسناد--Noncommercial-sharealike 4.0 |
| CL-Laysumm توفير طبقة سهلة لغير المهنيين لحقول NLP و ML. -cl-laysumm @ emnlp 2020 | ورقة البحث (الصرع ، علم الآثار ، هندسة المواد) -الأوريغن → 70 ~ 100W | 600 (ABS) | احتياجات الاتفاق الفردية (أرسل بريدًا إلكترونيًا إلى [email protected]) |
| الصوت العالمي : عبور الحدود في تلخيص الأخبار التلقائي (2019) -ورق | - أخبار -359W → 51W | ||
| MLSUM : مجموعة التلخيص متعدد اللغات على غرار مجموعة بيانات CNN/Daily Mail ، تعتبر النقاط البارزة/الوصف في المقالات الإخبارية ملخصًا وملخصًا للغة الإنجليزية والفرنسية وألمانيا والإسبانية والروسية والتركية التركية -ورق ، استخدم (Huggingface) | - أخبار -790W → 56W (أساس) | 1.5m (ABS) | أغراض البحث غير التجارية فقط |
| نموذج | قبل التدريب | الاستخدام | رخصة |
|---|---|---|---|
| بيرت (متعدد اللغات) Bert-Base (110m المعلمات) | -wikipedia (متعدد اللغات) -الويس. -10K مشتركة المفردات | BERT-Base, Multilingual Cased( --do_lower_case=false )-tensorflow | جوجل (Apache 2.0) |
| كوبرت bert-base (92m معلمات) | -wikipedia (جملة 5 أمتار) ، الأخبار (جملة 20M) -جنة 8،002 مفردات (لا يوجد رمز غير مستخدم) | -pytorch -كل ذلك متاح كمكتبة Luggingface Transformers من خلال kobert-transformers (monologg) ، distilkobert المتاحة | Sktbrain (Apache-2.0) |
| كوربيرت bert-base | -News (10 سنوات) ، ويكيبيديا ، إلخ. 23 جيجابايت -etri التحليل المورفولوجي API / Wordpiece (شريطة نسختين بشكل منفصل) -30،349 المفردات الأبجدية اللاتينية: غلاف - [مقدمة] LIM JUN (ETRI). NLU Tech Talk مع Korbert | -Pytorch ، Tensorflow | etri (العقد الفردي) |
| كبرت bert-base/كبير | تعليق الأخبار (12.5 جيجا بايت ، 8.9 مليون جملة) (19.01.01 ~ 20.06.15 تعليقات خارج المقالات في المقالات والتعليقات) -الطائرات bertwordpiecetokenizer -30،000 مفردات | بيومي (MIT) | |
| كوبارت بارت (124 م) | -wikipedia (5M) وغيرها (الأخبار ، الكتاب ، كلمات الجميع (المحادثة ، الأخبار ، ...) ، Cheong wa dae الوطنية ، إلخ. -الطرف BPE حرف Tockenizers 30000 مفردات (متضمنة) - [مثال] Seujung. Kobart-Summarization (Code ، Demo) | -تخصص المهمة في الطمث -دعم مكتبة المحولات -pytorch | SKT T3K (معهد ماساتشوستس للتكنولوجيا المعدل) |
| سنة | ورق |
|---|---|
| 2018 | دراسة استقصائية عن أساليب تلخيص الشبكة العصبية ي. دونغ |
| 2020 | مراجعة تقنية تلخيص النص التلقائي Widyassari ، AP ، Rustad ، S. ، Shidik ، GF ، Noersasongko ، E. ، Syukur ، A. ، & Affandy ، A. |
| 2020 | دراسة استقصائية لتوليد النصوص المعززة للمعرفة Wenhao Yu ، Chenguang Zhu ، Zaitang Li ، Zhiting HU ، Qingyun Wang ، Heng JI ، Meng Jiang |
| سنة | ورق | الكلمات الرئيسية |
|---|---|---|
| 1958 | إنشاء تلقائي لملخصات الأدب Ph Luhn | الجنرال |
| 2000 | توليد العنوان بناء على الترجمة الإحصائية M. Banko و Vo Mittal و MJ Witbrock | الجنرال |
| 2004 | Lexrank : مركزية معجمية قائمة على الرسم البياني كعلم في تلخيص النص ج. إركان ، ودراديف ، | الجنرال |
| 2005 | استخراج الجملة القائمة على تلخيص الوثيقة الفردية J. Jagadeesh و P. Pingali و V. Varma | الجنرال |
| 2010 | توليد اللقب مع قواعد اللغة شبه المتزامنة K. Woodsend ، Y. Feng ، and M. Lapata ، | الجنرال |
| 2011 | تلخيص النص باستخدام التحليل الدلالي الكامن Mg Ozsoy ، FN Alpaslan ، و I. Cicekli | الجنرال |
| سنة | ورق | الكلمات الرئيسية |
|---|---|---|
| 2014 | على استخدام المفردات المستهدفة الكبيرة جدًا للترجمة الآلية العصبية S. Jean ، K. Cho ، R. Memisevic ، and Yoshua Bengio | الجنرال |
| 2015 نموذج | ناماس : نموذج اهتمام عصبي لتلخيص جذاب (رمز) Am Rush و S. Chopra و J. Weston / Emnlp 2015 من أجل تجاوز طريقة اختيار الجملة الحالية وطريقة الجمل ، نقدم اهتمامًا مستهدفًا إلى مصدر في Flag SEQ2Seq لإنشاء ملخص جذاب. | القيمة المطلقة Seq2Seq مع ATT |
| 2015 | Toward Abstractive Summarization Using Semantic Representations Fei Liu,Jeffrey Flanigan,Sam Thomson,Norman M. Sadeh,Noah A. Smith / NAA-CL | abs, task-event, arch-graph |
| 2016 | Neural Summarization by Extracting Sentences and Words Jianpeng Cheng,Mirella Lapata / ACL | gen-2stage |
| 2016 | Abstractive sentence summarization with attentive recurrent neural networks S. Chopra, M. Auli, and AM Rush / NAA-CL | gen-abs, RNN,CNN, arch-att |
| 2016 | Abstractive text summarization using sequence-to-sequence RNNs and beyond R. Nallapati, B. Zhou, C. dos Santos, C. Gulcehre, and B. Xiang / CoNLL | gen-abs, data-new |
| 2017 نموذج | SummaRuNNer : A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents R. Nallapati, F. Zhai and B. Zhou 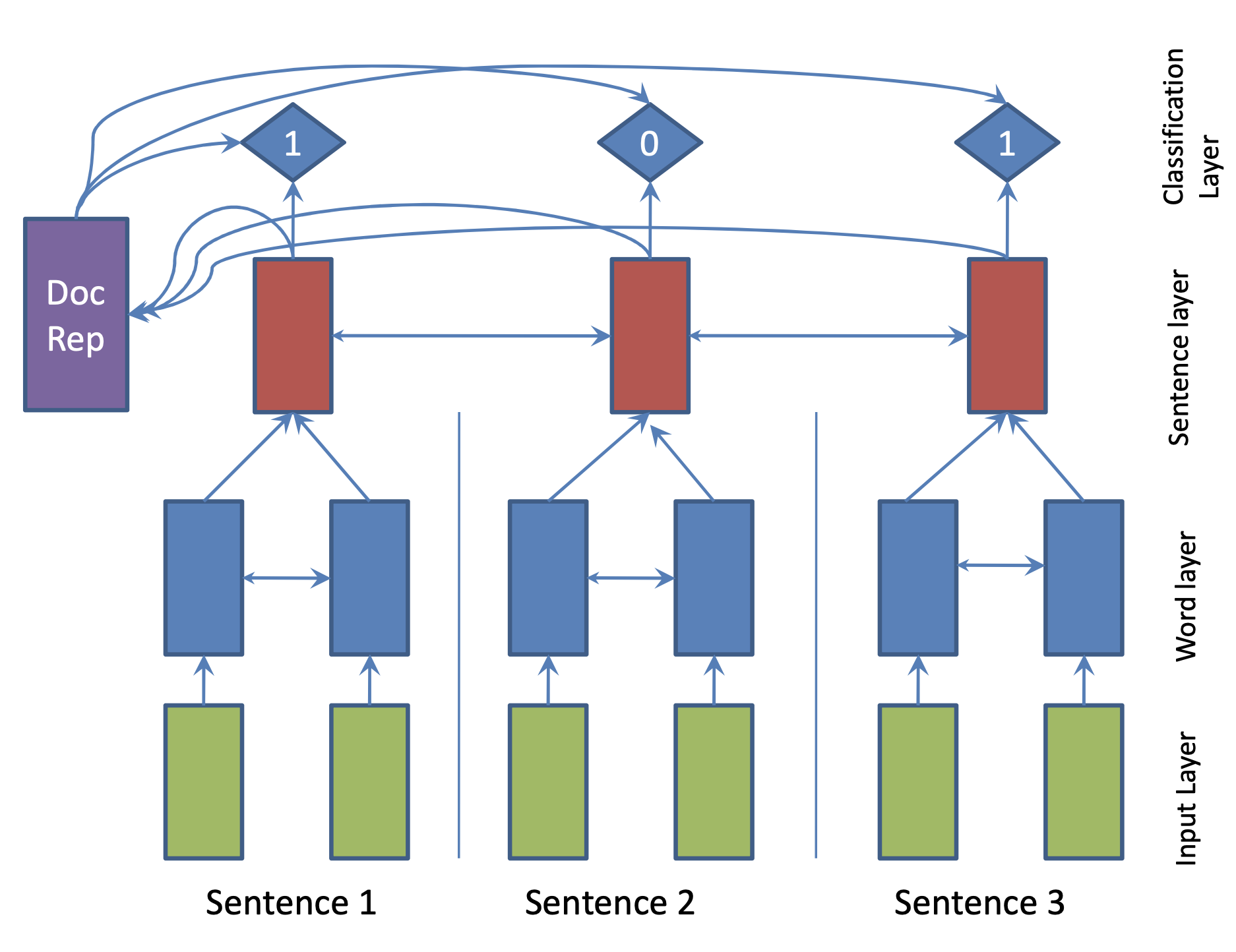 Hierarchical BiGRU 구조로 문서를 인코딩합니다. 우선 sentence별로 첫 번째 BiGRU에 word 단위로 입력하여 sentence vector를 만들고, 이를 다시 BiGRU에 통과시켜 문장별 임베딩(hidden states)을 생성합니다. 이 개별 문장 임베딩과 이들을 wighted sum한 doc vectort를 logistic classifier에 입력해 해당 문장이 요약에 포함시킬지 여부를 판단합니다. | ext, RNN (hierarchical BiGRU) |
| 2017 نموذج، تقنية | Pointer-generator : Get to the point: Summarization with pointergenerator networks (Code) A. See, PJ Liu, and CD Manning / ACL 2017 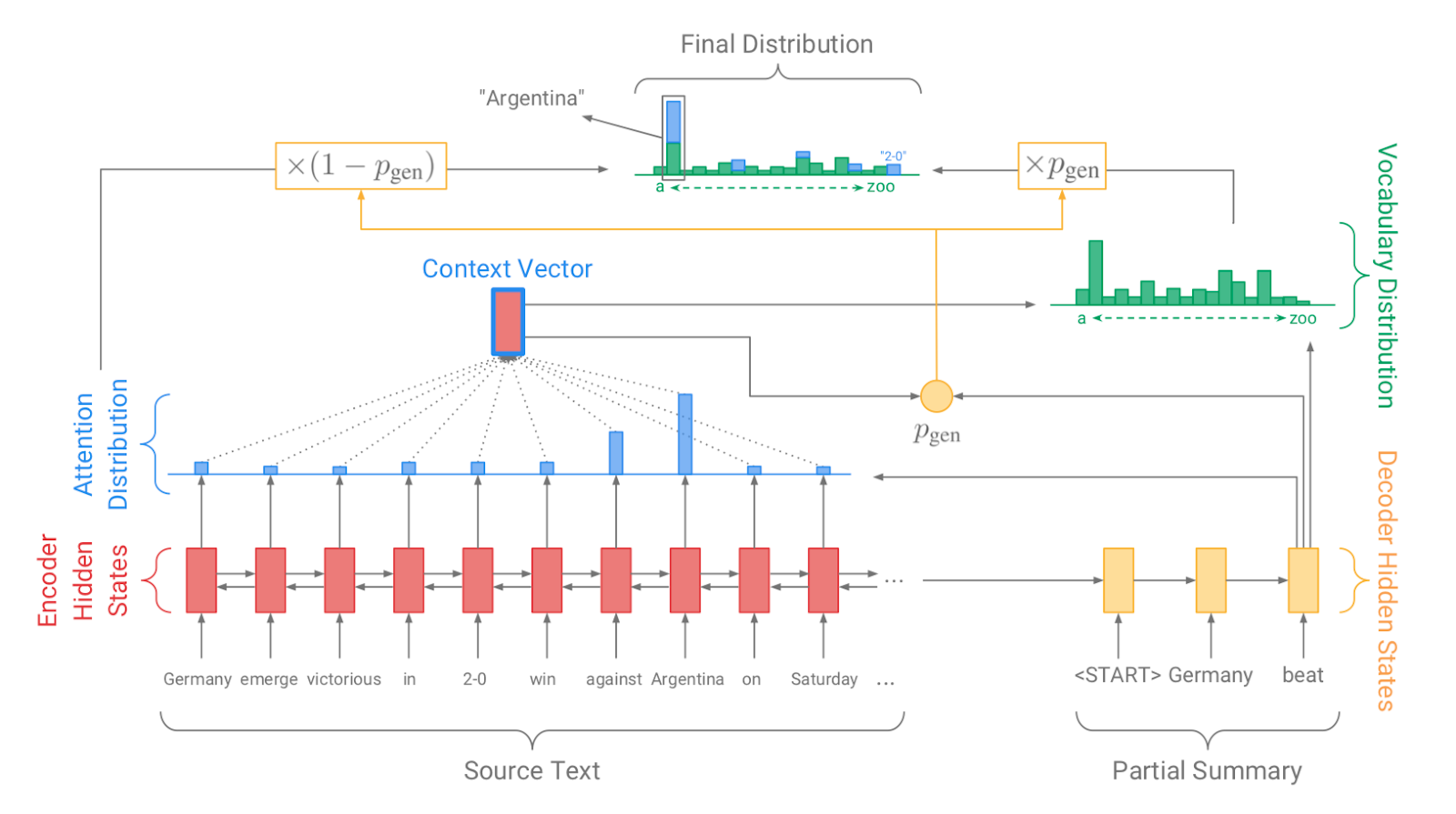 Generator를 통해 vocabulary distrubution을 생성하고, pointer를 통해 원문의 어떤 단어를 copy할 지를 나타내는 attention distribution을 생성한 후, 학습된 생성 확률(Pgen)에 따라 weighted-sum하여 최종 단어 생성분포를 결정합니다. Abstactive 방식인 generator와 extractive 방식인 attention을 결합한 hybrid 방식으로 기 Seq2Seq with Attention 방식이 factual consistency가 낮던 문제를 보완합니다. 또한 특정 단어가 반복해서 생성되는 문제를 해결하고자, 현재까지 사용된 단어별 누적 attention distribution값(coverage vector c)에 기반한 repetition penalty term을 loss에 포함합니다. - [Review] 김형석(KoreaUniv DSBA) | ext/abs, Pointer-Generator, Coverage loss |
| 2017 | A deep reinforced model for abstractive summarization R. Paulus, C. Xiong, and R. Socher | gen-ext/abs |
| 2017 | Abstractive Document Summarization with a Graph-Based Attentional Neural Model Jiwei Tan,Xiaojun Wan,Jianguo Xiao / ACL | ext, abs, arch-graph, arch-att |
| 2017 | Deep Recurrent Generative Decoder for Abstractive Text Summarization Piji Li,Wai Lam,Lidong Bing,Zihao W. Wang / EMNLP | latent-vae |
| 2017 | Generative Adversarial Network for Abstractive Text Summarization | |
| 2018 | Controlling Decoding for More Abstractive Summaries with Copy-Based Networks N. Weber, L. Shekhar, N. Balasubramanian, and K. Cho | ext/abs |
| 2018 نموذج | Generating Wikipedia by Summarizing Long Sequences PJ Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer / ICLR | ext/abs |
| 2018 | Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models T. Baumel, M. Eyal, and M. Elhadad | ext/abs |
| 2018 نموذج | تصاعدي Sebastian Gehrmann,Yuntian Deng,Alexander M. Rush / EMNLP 2018 요약에 사용될만한 단어들을 먼저 추출(ext)한 후, 이를 기반으로 요약을 생성(abs)하는 대표적인 2staged 모델입니다.* | abs, هجين، تصاعدي |
| 2018 | Deep Communicating Agents for Abstractive Summarization Asli Çelikyilmaz,Antoine Bosselut,Xiaodong He,Yejin Choi / **NAA-CL | abs, task-longtext, arch-graph |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting Y. Chen, M. Bansal | gen-ext/abs arch-graph |
| 2018 | Ranking Sentences for Extractive Summarization with Reinforcement Learning Shashi Narayan,Shay B. Cohen,Mirella Lapata | ext, abs, RNN,CNN, nondif-reinforce |
| 2018 | BanditSum: Extractive Summarization as a Contextual Bandit Yue Dong,Yikang Shen,Eric Crawford,Herke van Hoof,Jackie Chi Kit Cheung | ext, abs, RNN, nondif-reinforce |
| 2018 | Content Selection in Deep Learning Models of Summarization Chris Kedzie,Kathleen McKeown,Hal Daumé | ext, task-knowledge |
| 2018 | Faithful to the Original: Fact Aware Neural Abstractive Summarization | |
| 2018 | A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization | |
| 2018 | Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization | |
| 2018 | Global Encoding for Abstractive Summarization | |
| 2018 | Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting | |
| 2018 | Neural Document Summarization by Jointly Learning to Score and Select Sentences | |
| 2018 | Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization | |
| 2019 نموذج | Fine-tune BERT for Extractive Summarization Y. Liu | gen-ext |
| 2019 | Pretraining-Based Natural Language Generation for Text Summarization H. Zhang, J. Xu and J. Wang | gen-abs |
| 2019 | Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization Sangwoo Cho,Logan Lebanoff,Hassan Foroosh,Fei Liu / ACL | task-multiDoc |
| 2019 | HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization Xingxing Zhang,Furu Wei,Ming Zhou / ACL | arch-transformer |
| 2019 | Searching for Effective Neural Extractive Summarization: What Works and What's Next Ming Zhong,Pengfei Liu,Danqing Wang,Xipeng Qiu,Xuanjing Huang / ACL | gen-ext |
| 2019 | BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle Peter West,Ari Holtzman,Jan Buys,Yejin Choi / EMNLP | gen-ext, sup-sup, sup-unsup, arch-transformer |
| 2019 | Scoring Sentence Singletons and Pairs for Abstractive Summarization Logan Lebanoff,Kaiqiang Song,Franck Dernoncourt,Doo Soon Kim,Seokhwan Kim,Walter Chang,Fei Liu | gen-abs, arch-cnn |
| 2019 نموذج | PEGASUS : Pre-training with Extracted Gap-sentences for Abstractive Summarization (Code) Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu / ICML 2020 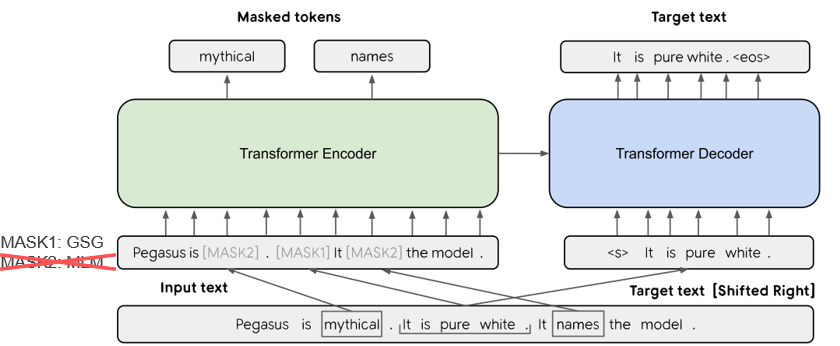 PEGASUS는 Pretraining objective가 텍스트 요약 과정과 흡사할수록 높은 성능을 보여줄 것이라는 가정하에 ROUGE score에 기반하여 중요하다고 판단되는 문장을 골라 문장 단위로 마스킹하는 GSG(Gap Sentences Generation) 방식을 사용했습니다. - [Review] 김한길. 영상, 발표자료 | |
| 2020 نموذج | TLDR: Extreme Summarization of Scientific Documents (Code, Demo) Isabel Cachola, Kyle Lo, Arman Cohan, Daniel S. Weld | gen-ext/abs |


