kaggle HomeDepot
1.0.0
圖靈測試的Home Depot產品搜索相關性競賽的解決方案Kaggle
| 提交 | CV RMSE | 公共LB RMSE | 私人LB RMSE | 位置 |
|---|---|---|---|---|
| 來自Igor和Kostia的簡化單模型(10個功能) | 0.44792 | 0.45072 | 0.44949 | 31 |
| 來自Igor和Kostia的最佳單個模型 | 0.43787 | 0.44017 | 0.43895 | 11 |
| 成山的最佳單型 | 0.43832 | 0.43996 | 0.43811 | 9 |
| 來自Igor和Kostia的最佳合奏模型 | - | 0.43819 | 0.43704 | 8 |
| 成龍的最佳合奏模型 | 0.43550 | 0.43555 | 0.43368 | 6 |
| 最佳最終合奏模型 | - | 0.43433 | 0.43271 | 3 |
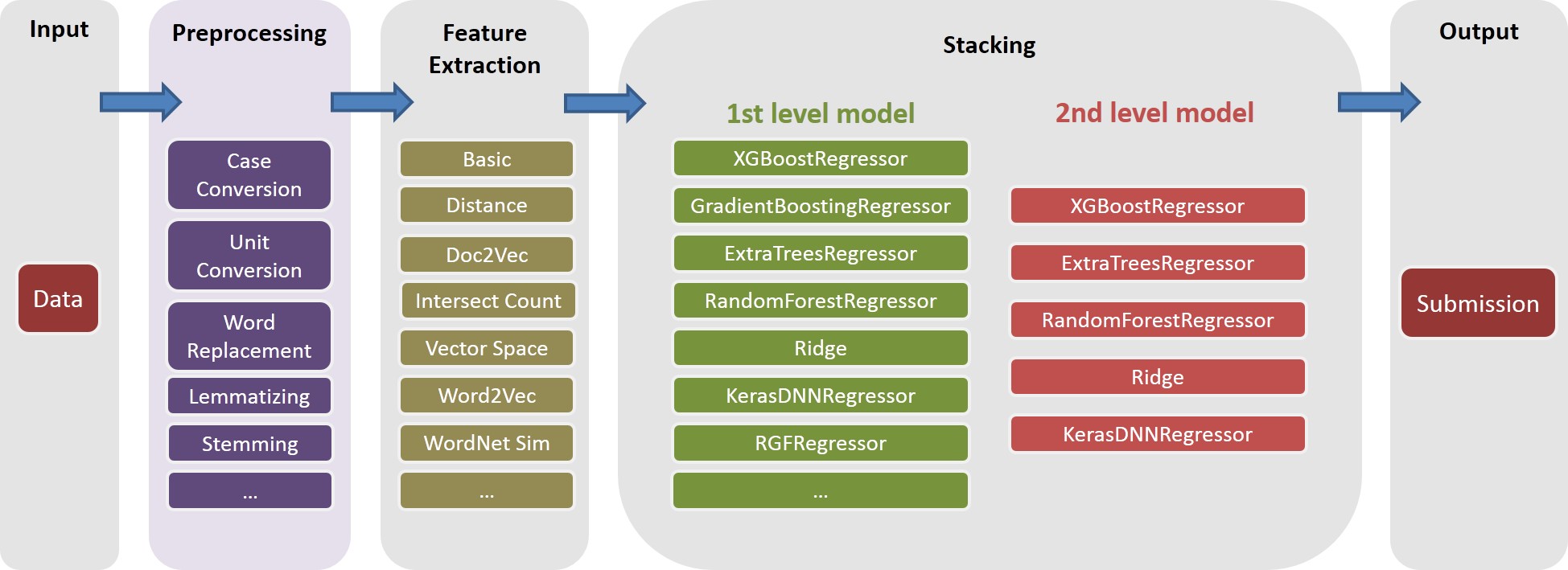
有關文檔,請參見./Doc/Kaggle_HomeDepot_Turing_Test.pdf 。
在繼續之前,應該將競爭網站的所有數據放入文件夾中./Data 。
請注意,在以下內容中,所有命令和腳本均已執行並在目錄中執行並運行./Code/Chenglong 。
我們使用Python 3.5.1,模塊帶有Anaconda 2.4.1(64位)。此外,我們還使用了以下庫和模塊:
我們使用以下通過install.packages()安裝的軟件包:
我們使用以下第三部分軟件包:
我們使用了此GitHub存儲庫中列出的預訓練Word2VEC模型。具體:
我們使用Glove-Gensim將手套向量轉換為Word2Vec格式,以便於Gensim使用。之後,將所有模型放入相應的目錄中(有關詳細信息,請參見config.py )。
我們還使用了以下外部數據:
./Data/dict/color_data.py color_data.py。google_spelling_checker_dict.py 。./Data/dict/word_replacer.csvnltk.download()下載,特別是: stopwords.zip , wordnet.zip和maxent_treebank_pos_tagger.zip 。 要生成數據和功能,應該運行python run_data.py 。儘管我們盡力使事情盡可能地進行並行性和高效,但根據計算能力,這部分可能仍需要1〜2天才能完成。所以要耐心:)
請注意,各種文本處理對於將多樣性引入合奏很有用。實際上,在固定錯字帖子(即,不使用Google Spelling校正詞典)之前生成了最終解決方案的一個功能集(IE, basic20160313 )。可以通過關閉config.py中的GOOGLE_CORRECTING_QUERY標誌來生成此類功能版本。
在與Igor&Kostia合併的團隊合併後,我們從頭開始重建了所有內容,我們的大多數模型都使用了Igor&Kostia功能的不同子集。因此,您還需要生成其功能。由於igor&kostia的功能以.csv dataframe格式為.csv dataframe,因此我們提供一個轉換器turing_test_converter.py將它們轉換為我們使用的格式,即.pkl 。
在步驟3中,我們產生了數千個功能。但是,其中只有一部分將用於構建我們的模型。例如,我們不需要那些幾乎沒有預測能力的功能(例如,與目標相關性具有很小的相關性。)因此,我們需要進行一些功能選擇。
在我們的解決方案中,通過以下兩個連續步驟啟用了功能選擇。
此方法被實現為get_feature_conf_*.py 。一般的想法是通過功能名稱的regex操作包括或排除特定功能。例如,
MANDATORY_FEATS變量指定他想要包含的功能COMMENT_OUT_FEATS變量排除的功能,儘管它與目標相關( MANDATORY_FEATS優先級高於COMMENT_OUT_FEATS 。)輸出是一個功能conf文件。例如,在運行以下命令之後:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
我們將獲得一個新功能conf ./conf/feature_conf_nonlinear_201605010058.py ,其中包含一個功能詞典,指定要在下一步中包含的功能。
一個人可以使用MANDATORY_FEATS和COMMENT_OUT_FEATS來生成不同的功能子集。我們已包含在./conf中的最終提交中的其他一些功能。其中, feature_conf_nonlinear_201604210409.py用於構建最佳單個模型。
使用上述生成的功能conf,可以通過以下命令將所有功能組合到功能矩陣中:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
上面的-t 0.05用於啟用相關基礎特徵選擇。在這種情況下,這意味著:刪除與目標相關性低於0.05的相關係數低於0.05的功能。
TODO(Chenglong):探索其他特徵選擇策略,例如,貪婪的前向特徵選擇(FFS)和貪婪的向後特徵選擇(BFS)。
在我們的解決方案中, task是特定feature的對象複合(例如, basic_nonlinear_201604210409 )和特定的learner (XGBoost的XGBoostRegressor )。 task , feature和learner的定義在task.py中。
以以下命令為例。
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
feature basic_nonlinear_201604210409和learner reg_xgb_tree運行task 。task用HyperOPT的100 EVALS優化,以搜索learner reg_xgb_tree的最佳參數。task同時執行簡歷和最終改裝。在這種情況下,CV具有兩個目的:1)指導HyperOPT找到最佳參數,而2)為每個CV折疊生成預測,以進一步(第二和第三級)堆疊。model_param_space.py 。在比賽中,我們運行了各種任務(即各種功能和各種學習者),以生成一個不同的1級模型庫。請參閱./Log/level1_models以了解我們在最終提交中包含的所有任務。
生成feature basic_nonlinear_201604210409 (請參見步驟4如何生成此)後,運行以下命令以生成最佳單個模型:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
這應該在0.438〜0.439左右的本地CV RMSE產生提交。
構建了一些不同的第一級模型後,請運行以下命令以生成最佳的合奏模型:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
這應該在0.436左右生成本地CV RMSE的提交。
在進行繼續之前,應在文件config_IgorKostia.py中指定正確的路徑,然後將競爭網站中的所有數據放入可變DATA_DIR指定的文件夾中。為了從步驟IK5重現我們的Ensemble_B ,應該將使用的功能集放入由Variabe FEATURESETS_DIR指定的文件夾中。請注意,在以下內容中,所有命令和腳本均已執行並在目錄中執行並運行./Code/Igor&Kostia 。
我們在Windows平台上使用了Python 2.7.11,模塊帶有Anaconda 2.4.0(64位),包括:
此外,我們還使用了以下庫和模塊:
nltk.download()命令)在Excel 2007和Excel 2010中也進行了一些描述性分析和最終模型混合。
我們在任何功能生成之前對所有文本進行預處理,並將結果保存到文件。它幫助我們節省了幾個計算日,因為需要相同的預處理步驟來生成不同的功能。
text_processing.py 。text_processing_wo_google.py 。必要的替換數據將從文件中自動加載homedepot_functions.py和google_dict.py 。
因此,我們需要運行以下文件:
feature_extraction1.py 。grams_and_terms_features.py 。dld_features.py 。word2vec.py 。要生成不使用Google詞典的功能,我們還需要運行:
feature_extraction1_wo_google.py 。word2vec_without_google_dict.py 。結果,我們將擁有一些CSV文件,並具有模型構建的必要功能。
generate_feature_importances.py 。 從以下代碼生成集合Ensemble_A的一部分:
generate_models.py 。generate_model_wo_google.py 。generate_ensemble_output_from_models.py 。要獲得另一部分Ensemble_B ,我們需要運行以下文件:
ensemble_script_imitation_version.py (它只是重現了從ensemble_script_random_version.py生成ensemble_script_random_version.py隨機特徵的選擇。model_selecting.py 。這兩個部分可以並行生成。然後,我們從Igor&Kostia提出的最後提交的內容是在Excel中製作的,為: Output = 0.75 Ensemble_A + 0.25 Ensemble_B
因此,我們有兩個使用不同方法的合奏。我們觀察到,我們的團體在數據集的不同部分的行為有所不同( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473由於我們也觀察到數據中的常規模式。由於我們也可以在某些地方進行過多的序列,因此我們認為其中一個尤其是在某些地方進行了序列,所以我們可以在某些地方進行過度的序列。在某些地方,其中一種模型在私人方面的行為會比在公共場合差得多。
我們的兩個最終提交內容是在Excel中生產的,下表的重量(Chenglong's和Igor&Kostia的零件的重量總計為1)。這兩項提交在私人排行榜上的得分均為0.43271 。
part1和part2的重量成龍 | 部分重量為part3 | 公共LB RMSE | 私人LB RMSE | |
|---|---|---|---|---|
| 提交1 | 0.75 | 0.8 | 0.43443 | 0.43271 |
| 提交2 | 0.6 | 0.3 | 0.43433 | 0.43271 |


