kaggle HomeDepot
1.0.0
Solución de Turing Test para la competencia de relevancia de búsqueda de productos Home Depot en Kaggle
| Envío | CV RMSE | LB Public LB RMSE | LB RMSE privado | Posición |
|---|---|---|---|---|
| Modelo único simplificado de Igor y Kostia (10 características) | 0.44792 | 0.45072 | 0.44949 | 31 |
| El mejor modelo único de Igor y Kostia | 0.43787 | 0.44017 | 0.43895 | 11 |
| El mejor modelo único de Chenglong | 0.43832 | 0.43996 | 0.43811 | 9 |
| Mejor modelo de conjunto de Igor y Kostia | - | 0.43819 | 0.43704 | 8 |
| Mejor modelo de conjunto de Chenglong | 0.43550 | 0.43555 | 0.43368 | 6 |
| El mejor modelo de conjunto final | - | 0.43433 | 0.43271 | 3 |
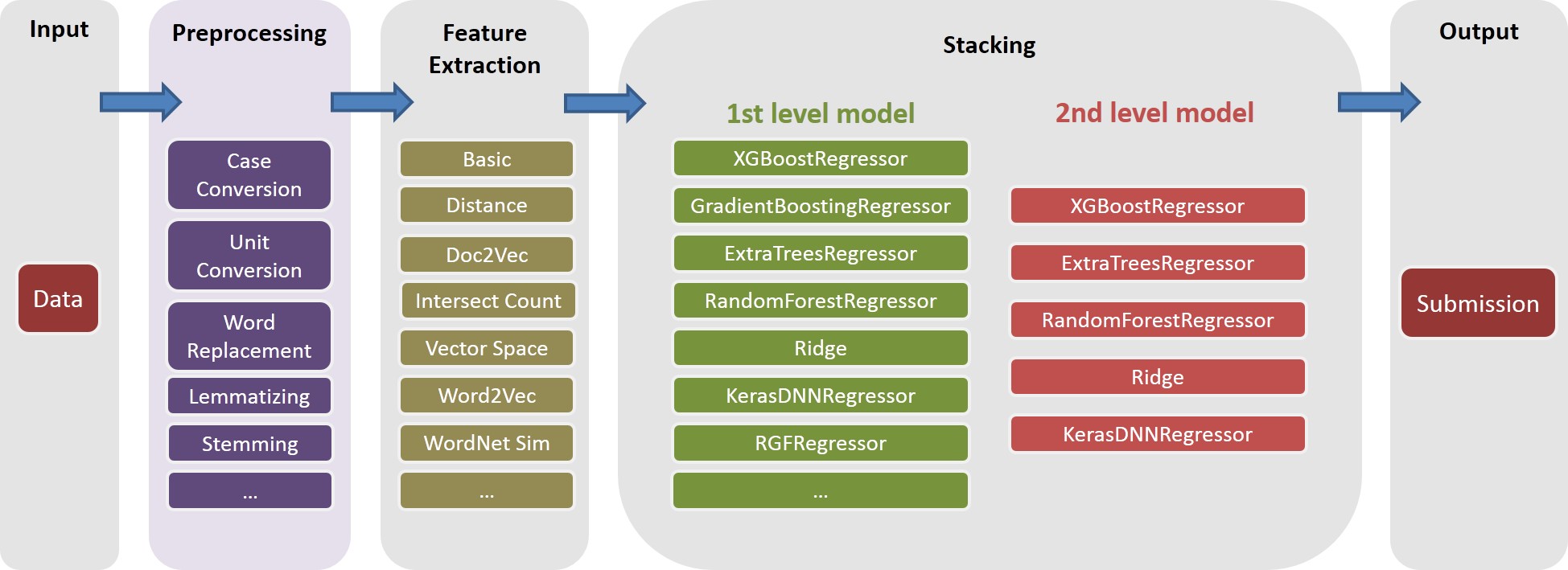
Ver ./Doc/Kaggle_HomeDepot_Turing_Test.pdf para la documentación.
Antes de continuar, uno debe colocar todos los datos del sitio web de la competencia en la carpeta ./Data .
Tenga en cuenta que al siguiente, todos los comandos y scripts se ejecutan y se ejecutan en el directorio ./Code/Chenglong .
Usamos Python 3.5.1 y los módulos vienen con Anaconda 2.4.1 (64 bits). Además, también utilizamos las siguientes bibliotecas y módulos:
Utilizamos los siguientes paquetes instalados a través de install.packages() :
Usamos los siguientes paquetes de terceros:
Utilizamos modelos Word2VEC previamente capacitados enumerados en este repositorio de GitHub. En específico:
Utilizamos Glove-Gensim para convertir los vectores de guantes en formato Word2Vec para un fácil uso con Gensim. Después de eso, coloque todos los modelos en el directorio correspondiente (ver config.py para obtener detalles).
También utilizamos los siguientes datos externos:
./Data/dict/color_data.py en este repositorio.google_spelling_checker_dict.py en este repositorio../Data/dict/word_replacer.csv en este repositorio.nltk.download() , específicamente: stopwords.zip , wordnet.zip y maxent_treebank_pos_tagger.zip . Para generar datos y características, uno debe ejecutar python run_data.py . Si bien hemos hecho todo lo posible para hacer las cosas lo más paralelismo y eficiente posible, esta parte aún podría tardar 1 ~ 2 días en terminar, dependiendo de la potencia computacional. Así que sé paciente :)
Tenga en cuenta que varios procesos de texto son útiles para introducir la diversidad en el conjunto. De hecho, un conjunto de características (es decir, basic20160313 ) a partir de nuestra solución final se genera antes de la publicación de tipos de errores, es decir, no usar el diccionario de corrección de ortografía de Google. Dicha versión de las características se puede generar apagando el indicador GOOGLE_CORRECTING_QUERY en config.py .
Después de fusionar el equipo con Igor y Kostia, hemos reconstruido todo desde cero, y la mayoría de nuestros modelos utilizaron diferentes subconjuntos de las características de Igor y Kostia. Por esta razón, también debe generar sus características. Dado que las características de Igor y Kostia están en formato .csv DataFrame, proporcionamos un convertidor turing_test_converter.py para convertirlas en el formato que utilizamos, es decir, .pkl .
En el paso 3, hemos generado algunos miles de características. Sin embargo, solo una parte de ellos se utilizará para construir nuestro modelo. Por ejemplo, no necesitamos esas características que tienen muy poca potencia predictiva (por ejemplo, tienen una correlación muy pequeña con la relevancia objetivo). Por lo tanto, necesitamos hacer alguna selección de características.
En nuestra solución, la selección de características se habilita a través de los siguientes dos pasos sucesivos.
Este enfoque se implementa como get_feature_conf_*.py . La idea general es incluir o excluir características específicas a través de operaciones regex de los nombres de características. Por ejemplo,
MANDATORY_FEATS , a pesar de su correlación con el objetivoCOMMENT_OUT_FEATS , a pesar de su correlación con el objetivo ( MANDATORY_FEATS tiene mayor prioridad que COMMENT_OUT_FEATS ). La salida de esto es un archivo de confirmación de características. Por ejemplo, después de ejecutar el siguiente comando:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
Obtendremos una nueva función conf ./conf/feature_conf_nonlinear_201605010058.py que contiene un diccionario de características que especifica las características que se incluirán en el siguiente paso.
Se puede jugar con MANDATORY_FEATS y COMMENT_OUT_FEATS para generar diferentes subconjuntos de características. Hemos incluido en ./conf algunos otros confirmos de características de nuestra presentación final. Entre ellos, feature_conf_nonlinear_201604210409.py se utiliza para construir el mejor modelo único.
Con el conteo de características generado anteriormente, uno puede combinar todas las características en una matriz de funciones a través del siguiente comando:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
El -t 0.05 anterior se usa para habilitar la selección de características de la base de correlación. En este caso, significa: suelte cualquier característica que tenga un coef de correlación inferior a 0.05 con la relevancia objetivo.
TODO (Chenglong): explore otras estrategias de selección de características, por ejemplo, selección de características de avance codicioso (FFS) y selección de características atrasadas (BFS).
En nuestra solución, una task es un compuesto de objeto de una feature específica (por ejemplo, basic_nonlinear_201604210409 ) y un learner específico ( XGBoostRegressor de xgboost). Las definiciones de task , feature y learner están en task.py .
Tome el siguiente comando por ejemplo.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
task con feature basic_nonlinear_201604210409 y learner reg_xgb_tree .task se optimiza con HypertoPt para 100 Evals para buscar los mejores parámetros para learner reg_xgb_tree .task realiza CV y REEMPLETO FINAL. El CV en este caso tiene dos propósitos: 1) Guía de Hypertopt para encontrar los mejores parámetros, y 2) generar predicciones para cada pliegue CV para una apilamiento adicional (segundo y tercer nivel).model_param_space.py . Durante la competencia, hemos realizado varias tareas (es decir, varias características y diversos alumnos) para generar una diversa biblioteca de modelos de primer nivel. Consulte ./Log/level1_models para ver todas las tareas que hemos incluido en nuestra presentación final.
Después de generar la feature basic_nonlinear_201604210409 (consulte el paso 4 Cómo generar esto), ejecute el siguiente comando para generar el mejor modelo único:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
Esto debería generar una sumisión con CV RMSE local alrededor de 0.438 ~ 0.439.
Después de construir algunos modelos diversos de primer nivel, ejecute el siguiente comando para generar el mejor modelo de conjunto:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
Esto debería generar una sumisión con CV RMSE local alrededor de 0.436.
Antes de continuar, se debe especificar rutas correctas en el archivo config_IgorKostia.py y colocar todos los datos del sitio web de la competencia en la carpeta especificada por variable DATA_DIR . Para reproducir nuestro Ensemble_B desde el paso IK5, se debe colocar los conjuntos de características usados en la carpeta especificadas por variable FEATURESETS_DIR . Tenga en cuenta que al siguiente, todos los comandos y scripts se ejecutan y se ejecutan en el directorio ./Code/Igor&Kostia .
Utilizamos Python 2.7.11 en la plataforma de Windows y los módulos vienen con Anaconda 2.4.0 (64 bits), que incluyen:
Además, también utilizamos las siguientes bibliotecas y módulos:
nltk.download() )Algunos análisis descriptivos y la mezcla final del modelo también se realizaron en Excel 2007 y Excel 2010.
Hacemos todo el preprocesamiento de texto antes de cualquier generación de funciones y guardamos los resultados en los archivos. Nos ayudó a ahorrar algunos días informáticos ya que son necesarios los mismos pasos de preprocesamiento para generar diferentes características.
text_processing.py .text_processing_wo_google.py . Los datos de reemplazo necesarios se cargan automáticamente desde los archivos homedepot_functions.py y google_dict.py .
Necesitamos ejecutar en consecuencia los siguientes archivos:
feature_extraction1.py .grams_and_terms_features.py .dld_features.py .word2vec.py .Para generar funciones sin usar el Diccionario de Google, también necesitamos ejecutar:
feature_extraction1_wo_google.py .word2vec_without_google_dict.py .Como resultado, tendremos algunos archivos CSV con las características necesarias para la construcción de modelos.
generate_feature_importances.py . Se genera una parte del conjunto Ensemble_A a partir del siguiente código:
generate_models.py .generate_model_wo_google.py .generate_ensemble_output_from_models.py . Para obtener la otra parte Ensemble_B , necesitamos ejecutar estos archivos:
ensemble_script_imitation_version.py (simplemente reproduce la selección de características aleatorias generadas desde ensemble_script_random_version.py . No necesita ejecutar ensemble_script_random_version.py nuevamente).model_selecting.py . Estas dos partes se pueden generar en paralelo. Nuestra presentación final de Igor & Kostia se produjo en Excel como: Output = 0.75 Ensemble_A + 0.25 Ensemble_B
Entonces, teníamos dos conjuntos preparados utilizando diferentes metodologías. Observamos que nuestros conjuntos se comportan de manera diferente en diferentes partes de los conjuntos de datos ( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473 Dado que observamos los patrones regulares en los datos, también pensamos que uno de los de los Arsembles podría ser especialmente predeterminado a Over -Fitting. Suponiendo que en algunas partes uno de los modelos se comportaría mucho peor en privado que en público.
Nuestras dos sumisiones finales se produjeron en Excel con los pesos de la tabla a continuación (el peso para las piezas de Chenglong e Igor & Kostia se suma hasta 1). Ambas presentaciones obtuvieron el mismo 0.43271 en la clasificación privada.
Peso chenglong para part1 y part2 | Peso chenglong para part3 | LB Public LB RMSE | LB RMSE privado | |
|---|---|---|---|---|
| Presentación 1 | 0.75 | 0.8 | 0.43443 | 0.43271 |
| Presentación 2 | 0.6 | 0.3 | 0.43433 | 0.43271 |


