kaggle HomeDepot
1.0.0
حل Turing Test for Home Depot Product Assoce Competition على kaggle
| استسلام | السيرة الذاتية RMSE | LB RMSE العامة | LB RMSE الخاص | موضع |
|---|---|---|---|---|
| نموذج واحد مبسط من Igor و Kostia (10 ميزات) | 0.44792 | 0.45072 | 0.44949 | 31 |
| أفضل نموذج واحد من Igor و Kostia | 0.43787 | 0.44017 | 0.43895 | 11 |
| أفضل نموذج واحد من Chenglong | 0.43832 | 0.43996 | 0.43811 | 9 |
| أفضل نموذج فرقة من Igor و Kostia | - | 0.43819 | 0.43704 | 8 |
| أفضل مجموعة فرقة من Chenglong | 0.43550 | 0.43555 | 0.43368 | 6 |
| أفضل نموذج الفرقة النهائي | - | 0.43433 | 0.43271 | 3 |
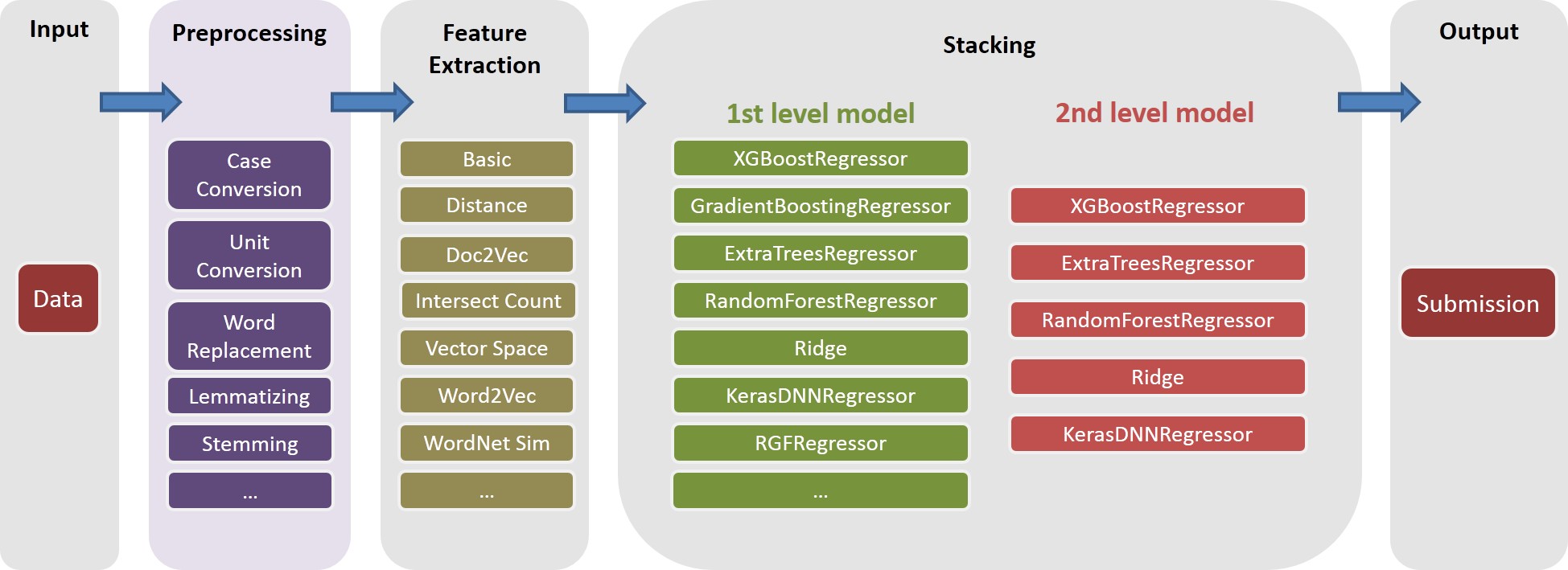
انظر ./Doc/Kaggle_HomeDepot_Turing_Test.pdf للتوثيق.
قبل المتابعة ، يجب على المرء أن يضع جميع البيانات من موقع المنافسة في مجلد ./Data .
لاحظ أنه في ما يلي ، يتم تنفيذ جميع الأوامر والبرامج النصية وتشغيلها في الدليل ./Code/Chenglong .
استخدمنا Python 3.5.1 والوحدات النمطية تأتي مع Anaconda 2.4.1 (64 بت). بالإضافة إلى ذلك ، استخدمنا أيضًا المكتبات والوحدات النمطية التالية:
استخدمنا الحزم التالية المثبتة عبر install.packages() :
استخدمنا حزم الطرف الثالث التالي:
استخدمنا نماذج Word2Vec المدربة مسبقًا المدرجة في هذا Github Repo. بالتحديد:
استخدمنا قفاز-جينسيم لتحويل ناقلات القفازات إلى تنسيق Word2VEC لسهولة الاستخدام مع Gensim. بعد ذلك ، ضع جميع النماذج في الدليل المقابل (انظر config.py للحصول على التفاصيل).
استخدمنا أيضًا البيانات الخارجية التالية:
./Data/dict/color_data.py في هذا الريبو.google_spelling_checker_dict.py في هذا الريبو../Data/dict/word_replacer.csv في هذا الريبو.nltk.download() ، على وجه التحديد: stopwords.zip ، wordnet.zip و maxent_treebank_pos_tagger.zip . لإنشاء البيانات والميزات ، ينبغي للمرء تشغيل python run_data.py . على الرغم من أننا بذلنا قصارى جهدنا لجعل الأشياء بالتوازي والفعالة قدر الإمكان ، إلا أن هذا الجزء قد لا يزال يستغرق 1 ~ يومين حتى النهاية ، اعتمادًا على القوة الحسابية. لذا كن صبورًا :)
لاحظ أن معالجة النص المختلفة مفيدة لإدخال التنوع في الفرقة. في الواقع ، يتم إنشاء مجموعة ميزات واحدة (أي basic20160313 ) من حلنا النهائي قبل منشور الأخطاء المطبعية ، أي عدم استخدام قاموس تصحيح Google Spelling. يمكن إنشاء هذا الإصدار من الميزات عن طريق إيقاف تشغيل علامة GOOGLE_CORRECTING_QUERY في config.py .
بعد دمج الفريق مع Igor & Kostia ، قمنا بإعادة بناء كل شيء من نقطة الصفر ، واستخدمت معظم نماذجنا مجموعات فرعية مختلفة من ميزات Igor & Kostia. لهذا السبب ، يجب أن تحتاج أيضًا إلى إنشاء ميزاتها. نظرًا لأن ميزات Igor & Kostia موجودة في تنسيق DataFrame .csv ، فإننا نقدم محول turing_test_converter.py لتحويلها إلى التنسيق الذي نستخدمه ، أي ، .pkl .
في الخطوة 3 ، أنشأنا بضعة آلاف من الميزات. ومع ذلك ، سيتم استخدام جزء منهم فقط لبناء نموذجنا. على سبيل المثال ، لا نحتاج إلى تلك الميزات التي لها قوة تنبؤية قليلة جدًا (على سبيل المثال ، لها علاقة صغيرة جدًا بأهمية الهدف.) وبالتالي نحتاج إلى القيام ببعض اختيار الميزات.
في حلنا ، يتم تمكين اختيار الميزات من خلال الخطوتين التاليتين المتتاليتين.
يتم تنفيذ هذا النهج كـ get_feature_conf_*.py . تتمثل الفكرة العامة في تضمين أو استبعاد ميزات محددة عبر عمليات regex لأسماء الميزات. على سبيل المثال،
MANDATORY_FEATS ، على الرغم من ارتباطه بالهدفCOMMENT_OUT_FEATS ، على الرغم من ارتباطه بالهدف (يكون MANDATORY_FEATS أولوية أعلى من COMMENT_OUT_FEATS .) إخراج هذا هو ملف conf ميزة. على سبيل المثال ، بعد تشغيل الأمر التالي:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
سنحصل على ميزة جديدة conf ./conf/feature_conf_nonlinear_201605010058.py
يمكن للمرء أن يلعب مع MANDATORY_FEATS و COMMENT_OUT_FEATS لإنشاء مجموعة فرعية مختلفة للميزات. لقد أدرجنا في ./conf بعض الميزات الأخرى من التقديم النهائي لدينا. من بينها ، feature_conf_nonlinear_201604210409.py يستخدم لبناء أفضل طراز واحد.
مع الميزة التي تم إنشاؤها أعلاه ، يمكن للمرء أن يجمع بين جميع الميزات في مصفوفة ميزة عبر الأمر التالي:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
يتم استخدام -t 0.05 أعلاه لتمكين اختيار ميزة قاعدة الارتباط. في هذه الحالة ، يعني ذلك: إسقاط أي ميزة لها ارتباط أقل من 0.05 مع أهمية الهدف.
TODO (Chenglong): استكشاف استراتيجيات اختيار الميزات الأخرى ، على سبيل المثال ، اختيار ميزة الأمام الجشع (FFS) واختيار الميزات المتخلفة الجشع (BFS).
في حلنا ، تعد task مركبًا كائنًا feature محددة (على سبيل المثال ، basic_nonlinear_201604210409 ) learner معين ( XGBoostRegressor من xgboost). تعاريف task feature learner في task.py
خذ الأمر التالي على سبيل المثال.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
task مع feature basic_nonlinear_201604210409 learner reg_xgb_tree .task باستخدام HyperOPT لـ 100 Evals للبحث في أفضل المعلمات learner reg_xgb_tree .task تؤدي كل من السيرة الذاتية والتجديد النهائي. تحتوي السيرة الذاتية في هذه الحالة على غرضين: 1) توجيه Hyperopt للعثور على أفضل المعلمات ، و 2) إنشاء تنبؤات لكل طية سيرة ذاتية لمزيد من التراص (المستوى الثاني والثالث).model_param_space.py . خلال المسابقة ، قمنا بإدارة مهام مختلفة (أي الميزات المختلفة ومتعلمين مختلفين) لإنشاء مكتبة نموذجية من المستوى الأول. يرجى الاطلاع على ./Log/level1_models لجميع المهام التي قمنا بتضمينها في تقديمنا النهائي.
بعد إنشاء feature basic_nonlinear_201604210409 (انظر الخطوة 4 كيفية إنشاء هذا) ، قم بتشغيل الأمر التالي لإنشاء أفضل نموذج واحد:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
هذا يجب أن يولد تقديم مع CV RMSE المحلية حوالي 0.438 ~ 0.439.
بعد بناء بعض نماذج المستوى الأول المتنوع ، قم بتشغيل الأمر التالي لإنشاء أفضل نموذج لمجموعة:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
هذا يجب أن يولد تقديم مع CV RMSE محلي حوالي 0.436.
قبل المتابعة ، يجب على المرء تحديد المسارات الصحيحة في ملف config_IgorKostia.py ووضع جميع البيانات من موقع المنافسة إلى مجلد محدد بواسطة متغير DATA_DIR . لإعادة إنتاج Ensemble_B من الخطوة IK5 ، يجب على المرء وضع مجموعات الميزات المستخدمة في مجلد محدد بواسطة FEATURESETS_DIR . لاحظ أنه في ما يلي ، يتم تنفيذ جميع الأوامر والبرامج النصية وتشغيلها في الدليل ./Code/Igor&Kostia .
استخدمنا Python 2.7.11 على نظام Windows ووحداته يأتي مع Anaconda 2.4.0 (64 بت) ، بما في ذلك:
بالإضافة إلى ذلك ، استخدمنا أيضًا المكتبات والوحدات النمطية التالية:
nltk.download() )تم أيضًا إجراء بعض التحليل الوصفي ومزج النموذج النهائي في Excel 2007 و Excel 2010.
نقوم بجميع المعالجة المسبقة للنص قبل أي توليد ميزة وحفظ النتائج للملفات. لقد ساعدنا ذلك في توفير بضعة أيام الحوسبة لأن نفس خطوات المعالجة المسبقة ضرورية لإنشاء ميزات مختلفة.
text_processing.py .text_processing_wo_google.py . يتم تحميل بيانات الاستبدال اللازمة تلقائيًا من الملفات homedepot_functions.py و google_dict.py .
نحتاج إلى تشغيل الملفات التالية:
feature_extraction1.py .grams_and_terms_features.py .dld_features.py .word2vec.py .لإنشاء ميزات دون استخدام قاموس Google ، نحتاج أيضًا إلى تشغيل:
feature_extraction1_wo_google.py .word2vec_without_google_dict.py .نتيجة لذلك ، سيكون لدينا عدد قليل من ملفات CSV مع الميزات اللازمة لبناء النماذج.
generate_feature_importances.py . يتم إنشاء جزء واحد من مجموعة Ensemble_A من الكود التالي:
generate_models.py .generate_model_wo_google.py .generate_ensemble_output_from_models.py . للحصول على الجزء الآخر Ensemble_B ، نحتاج إلى تشغيل هذه الملفات:
ensemble_script_imitation_version.py (إنه يستنسخ فقط اختيار الميزات العشوائية التي تم إنشاؤها من ensemble_script_random_version.py . أنت لا تحتاج إلى تشغيل ensemble_script_random_version.py مرة أخرى).model_selecting.py . يمكن إنشاء هذين الجزأين بالتوازي. بعد ذلك تم تقديم تقديمنا النهائي من Igor & Kostia في Excel As: Output = 0.75 Ensemble_A + 0.25 Ensemble_B
لذلك ، كان لدينا مجموعتان تم إعدادهما باستخدام منهجيات مختلفة. لاحظنا أن مجموعاتنا تتصرف بشكل مختلف في أجزاء مختلفة من مجموعات البيانات ( part1 : id<=163700 ، part2 : 163700 < id <= 221473 ، part_3 : id > 221473 نظرًا لأننا لاحظنا أنماطًا منتظمة في بعض الأجزاء ، فقد قمنا باختلافها ، في بعض الأجزاء التي نلتزم بها ، نمتزج إلى أنماطنا. على افتراض أنه في بعض الأجزاء ، كان أحد النماذج يتصرف أسوأ بكثير من القطاع الخاص منه في الأماكن العامة.
تم إنتاج اثنين من التقديم النهائي لدينا في Excel مع الأوزان من الطاولة أدناه (وزن أجزاء Chenglong's و Igor & Kostia تضيف ما يصل إلى 1). سجل كل من هذه التقديمات نفس 0.43271 على لوحة المتصدرين الخاصة.
وزن Chenglong لـ part1 و part2 | وزن Chenglong لـ part3 | LB RMSE العامة | LB RMSE الخاص | |
|---|---|---|---|---|
| التقديم 1 | 0.75 | 0.8 | 0.43443 | 0.43271 |
| التقديم 2 | 0.6 | 0.3 | 0.43433 | 0.43271 |


