kaggle HomeDepot
1.0.0
Solution du test Turing pour la compétition de pertinence de recherche de produits Home Depot sur Kaggle
| Soumission | CV RMSE | Public LB RMSE | LB privé RMSE | Position |
|---|---|---|---|---|
| Modèle unique simplifié d'Igor et Kostia (10 caractéristiques) | 0.44792 | 0,45072 | 0.44949 | 31 |
| Meilleur modèle unique d'Igor et Kostia | 0.43787 | 0.44017 | 0,43895 | 11 |
| Meilleur modèle unique de Chenglong | 0,43832 | 0.43996 | 0,43811 | 9 |
| Meilleur modèle d'ensemble d'Igor et Kostia | - | 0.43819 | 0,43704 | 8 |
| Meilleur modèle d'ensemble de Chenglong | 0,43550 | 0,43555 | 0,43368 | 6 |
| Meilleur modèle d'ensemble final | - | 0,43433 | 0.43271 | 3 |
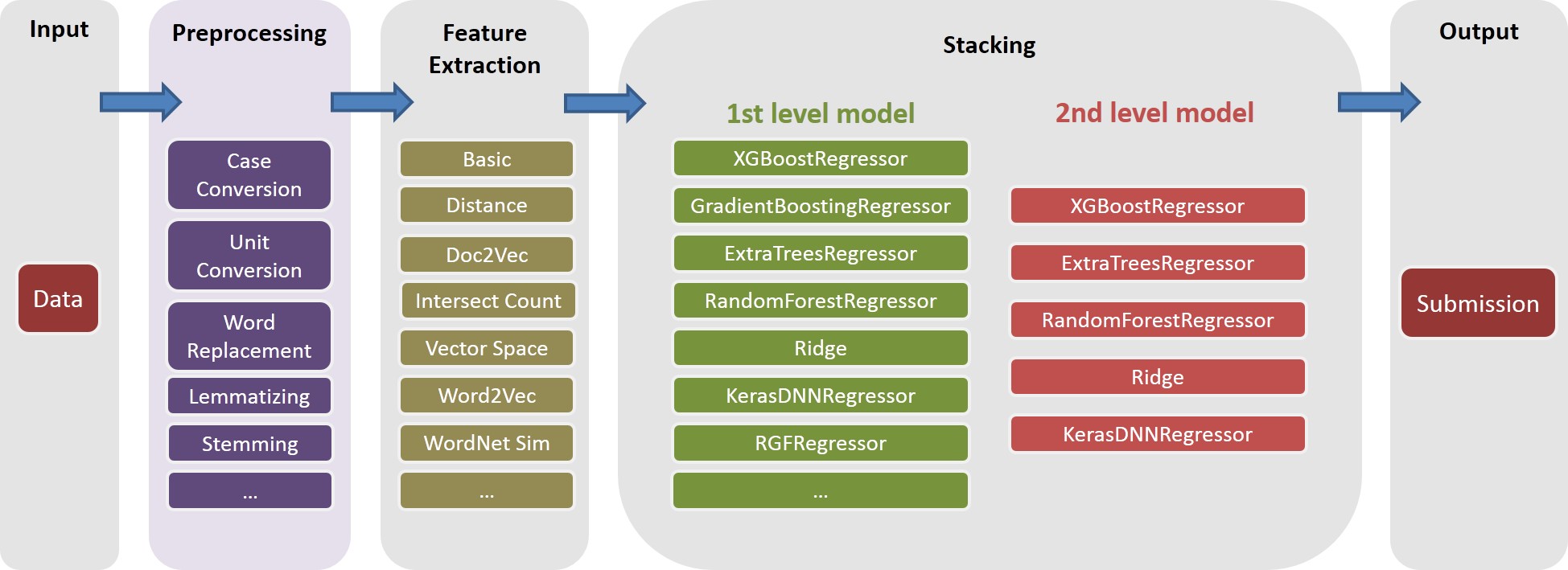
Voir ./Doc/Kaggle_HomeDepot_Turing_Test.pdf pour la documentation.
Avant de continuer, il faut placer toutes les données du site Web du concours dans le dossier ./Data .
Notez que dans ce qui suit, toutes les commandes et scripts sont exécutés et exécutés dans le répertoire ./Code/Chenglong .
Nous avons utilisé Python 3.5.1 et les modules sont livrés avec Anaconda 2.4.1 (64 bits). De plus, nous avons également utilisé les bibliothèques et modules suivants:
Nous avons utilisé les packages suivants installés via install.packages() :
Nous avons utilisé les packages tiers suivants:
Nous avons utilisé des modèles Word2Vec pré-formés répertoriés dans ce repo GitHub. En particulier:
Nous avons utilisé Glove-Gensim pour convertir des vecteurs de gants en format Word2Vec pour une utilisation facile avec Gensim. Après cela, mettez tous les modèles dans le répertoire correspondant (voir config.py pour le détail).
Nous avons également utilisé les données externes suivantes:
./Data/dict/color_data.py dans ce repo.google_spelling_checker_dict.py dans ce dépôt../Data/dict/word_replacer.csv dans ce repo.nltk.download() , spécifiquement: stopwords.zip , wordnet.zip et maxent_treebank_pos_tagger.zip . Pour générer des données et des fonctionnalités, il faut exécuter python run_data.py . Bien que nous ayons fait de notre mieux pour rendre les choses aussi parallélisme et efficaces que possible, cette partie pourrait encore prendre 1 ~ 2 jours pour terminer, selon la puissance de calcul. Alors soyez patient :)
Notez que divers traitements de texte sont utiles pour introduire la diversité dans l'ensemble. En fait, un ensemble de fonctionnalités (c.-à-d. basic20160313 ) de notre solution finale est généré avant la publication de frappe de fixation, c'est-à-dire n'utilisant pas le dictionnaire de correction d'orthographe Google. Une telle version des fonctionnalités peut être générée en éteignant l'indicateur GOOGLE_CORRECTING_QUERY dans config.py .
Après la fusion d'équipe avec Igor & Kostia, nous avons tout reconstruit à partir de zéro, et la plupart de nos modèles ont utilisé différents sous-ensembles de fonctionnalités d'Igor & Kostia. Pour cette raison, vous devriez également avoir besoin de générer leurs fonctionnalités. Étant donné que les fonctionnalités d'Igor & Kostia sont au format .csv dataframe, nous fournissons un convertisseur turing_test_converter.py pour les convertir au format que nous utilisons, c'est-à-dire .pkl .
À l'étape 3, nous avons généré quelques milliers de fonctionnalités. Cependant, seule une partie d'entre eux sera utilisée pour construire notre modèle. Par exemple, nous n'avons pas besoin de ces fonctionnalités qui ont très peu de pouvoir prédictif (par exemple, ont une très petite corrélation avec la pertinence cible.) Nous devons donc faire une sélection de fonctionnalités.
Dans notre solution, la sélection des fonctionnalités est activée via les deux étapes successives suivantes.
Cette approche est implémentée comme get_feature_conf_*.py . L'idée générale est d'inclure ou d'exclure des fonctionnalités spécifiques via des opérations regex des noms de fonctionnalités. Par exemple,
MANDATORY_FEATS , malgré sa corrélation avec la cibleCOMMENT_OUT_FEATS , malgré sa corrélation avec la cible ( MANDATORY_FEATS a une priorité plus élevée que COMMENT_OUT_FEATS .) La sortie de ceci est un fichier de confort de fonctionnalité. Par exemple, après avoir exécuté la commande suivante:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
Nous obtiendrons une nouvelle fonctionnalité conf ./conf/feature_conf_nonlinear_201605010058.py qui contient un dictionnaire de fonctionnalités spécifiant les fonctionnalités à inclure dans l'étape suivante.
On peut jouer avec MANDATORY_FEATS et COMMENT_OUT_FEATS pour générer différents sous-ensembles de fonctionnalités. Nous avons inclus ./conf Quelques autres confs de fonctionnalités de notre soumission finale. Parmi eux, feature_conf_nonlinear_201604210409.py est utilisé pour construire le meilleur modèle unique.
Avec la fonction générée ci-dessus, on peut combiner toutes les fonctionnalités dans une matrice de fonctionnalité via la commande suivante:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
Le -t 0.05 ci-dessus est utilisé pour permettre la sélection des fonctionnalités de base de corrélation. Dans ce cas, cela signifie: supprimer toute fonctionnalité qui a un coef de corrélation inférieur à 0.05 avec la pertinence cible.
TODO (Chenglong): explorez d'autres stratégies de sélection de fonctionnalités, par exemple, la sélection des fonctionnalités avant gourmands (FFS) et la sélection de fonctionnalités arrière gourmand (BFS).
Dans notre solution, une task est un composite d'objet d'une feature spécifique (par exemple, basic_nonlinear_201604210409 ) et un learner spécifique ( XGBoostRegressor de xgboost). Les définitions de task , feature et learner sont dans task.py
Prenez la commande suivante par exemple.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
task avec feature basic_nonlinear_201604210409 et learner reg_xgb_tree .task est optimisée avec Hyperopt pour 100 Evals pour rechercher les meilleurs paramètres de learner reg_xgb_tree .task effectue à la fois CV et Final Refit. Le CV dans ce cas a deux objectifs: 1) guider Hyperopt pour trouver les meilleurs paramètres, et 2) générer des prédictions pour chaque pli CV pour un empilement supplémentaire (2e et 3e niveau).model_param_space.py . Pendant la compétition, nous avons effectué diverses tâches (c'est-à-dire diverses fonctionnalités et divers apprenants) pour générer une bibliothèque de modèles diversifiée de 1er niveau. Veuillez voir ./Log/level1_models pour toutes les tâches que nous avons incluses dans notre soumission finale.
Après avoir généré la feature basic_nonlinear_201604210409 (voir l'étape 4 Comment générer ceci), exécutez la commande suivante pour générer le meilleur modèle unique:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
Cela devrait générer une soumission avec le CV RMSE local autour de 0,438 ~ 0,439.
Après avoir construit certains modèles de 1er niveau, exécutez la commande suivante pour générer le meilleur modèle d'ensemble:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
Cela devrait générer une soumission avec le CV RMSE local autour de 0,436.
Avant de poursuivre, il faut spécifier des chemins corrects dans le fichier config_IgorKostia.py et placer toutes les données du site Web du concours dans le dossier spécifié par variable DATA_DIR . Pour reproduire notre Ensemble_B à partir de Step IK5, il faut placer les ensembles de fonctionnalités utilisés dans le dossier spécifié par variable FEATURESETS_DIR . Notez que dans ce qui suit, toutes les commandes et scripts sont exécutés et exécutés dans le répertoire ./Code/Igor&Kostia .
Nous avons utilisé Python 2.7.11 sur la plate-forme Windows et les modules sont livrés avec Anaconda 2.4.0 (64 bits), y compris:
De plus, nous avons également utilisé les bibliothèques et modules suivants:
nltk.download() )Une analyse descriptive et un mélange final du modèle ont également été effectués dans Excel 2007 et Excel 2010.
Nous effectuons tout le prétraitement du texte avant toute génération de fonctionnalités et enregistrons les résultats dans les fichiers. Cela nous a aidés à économiser quelques jours informatiques car les mêmes étapes de prétraitement sont nécessaires pour générer différentes fonctionnalités.
text_processing.py .text_processing_wo_google.py . Les données de remplacement nécessaires sont chargées automatiquement à partir de fichiers homedepot_functions.py et google_dict.py .
Nous devons exécuter par conséquent les fichiers suivants:
feature_extraction1.py .grams_and_terms_features.py .dld_features.py .word2vec.py .Pour générer des fonctionnalités sans utiliser le dictionnaire Google, nous devons également s'exécuter:
feature_extraction1_wo_google.py .word2vec_without_google_dict.py .En conséquence, nous aurons quelques fichiers CSV avec les fonctionnalités nécessaires pour la construction de modèles.
generate_feature_importances.py . Une partie de l'ensemble Ensemble_A est générée à partir du code suivant:
generate_models.py .generate_model_wo_google.py .generate_ensemble_output_from_models.py . Pour obtenir l'autre pièce Ensemble_B , nous devons exécuter ces fichiers:
ensemble_script_imitation_version.py (il reproduit simplement la sélection des fonctionnalités aléatoires générées à partir de ensemble_script_random_version.py . Vous n'avez pas besoin d'exécuter à nouveau ensemble_script_random_version.py ).model_selecting.py . Ces deux parties peuvent être générées en parallèle. Notre dernière soumission d'Igor & Kostia a ensuite été produite dans Excel comme: Output = 0,75 Ensemble_A + 0,25 Ensemble_B
Ainsi, nous avions deux ensembles préparés en utilisant différentes méthodologies. Nous avons observé que nos ensembles se comportent différemment dans différentes parties des ensembles de données ( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473 Étant donné que nous avons observé des modèles réguliers dans les données aussi, alors que nous pensons que l'un des ensembles pourrait être particulièrement soumis à des têtes. En supposant que dans certaines parties, l'un des modèles se comporterait bien pire en privé qu'en public.
Nos deux dernières soumission ont été produites à Excel avec les poids du tableau ci-dessous (le poids des pièces de Chenglong et Igor & Kostia augmente jusqu'à 1). Ces deux soumissions ont marqué le même 0.43271 dans le classement privé.
Poids Chenglong pour part1 et part2 | Poids Chenglong pour part3 | Public LB RMSE | LB privé RMSE | |
|---|---|---|---|---|
| Soumission 1 | 0,75 | 0.8 | 0,43443 | 0.43271 |
| Soumission 2 | 0.6 | 0.3 | 0,43433 | 0.43271 |


