kaggle HomeDepot
1.0.0
Решение Turing Test для Home Depot Product Product Search Competition на Kaggle
| Подчинение | CV RMSE | Public LB RMSE | Частный LB RMSE | Позиция |
|---|---|---|---|---|
| Упрощенная единственная модель от Igor и Kostia (10 функций) | 0,44792 | 0,45072 | 0,44949 | 31 |
| Лучшая единственная модель от Игоря и Костии | 0,43787 | 0,44017 | 0,43895 | 11 |
| Лучшая единственная модель от Чэнлонга | 0,43832 | 0,43996 | 0,43811 | 9 |
| Лучшая ансамблевая модель от Игоря и Костии | - | 0,43819 | 0,43704 | 8 |
| Лучшая ансамблевая модель от Чэнлонга | 0,43550 | 0,43555 | 0,43368 | 6 |
| Лучшая окончательная модель ансамбля | - | 0,43433 | 0,43271 | 3 |
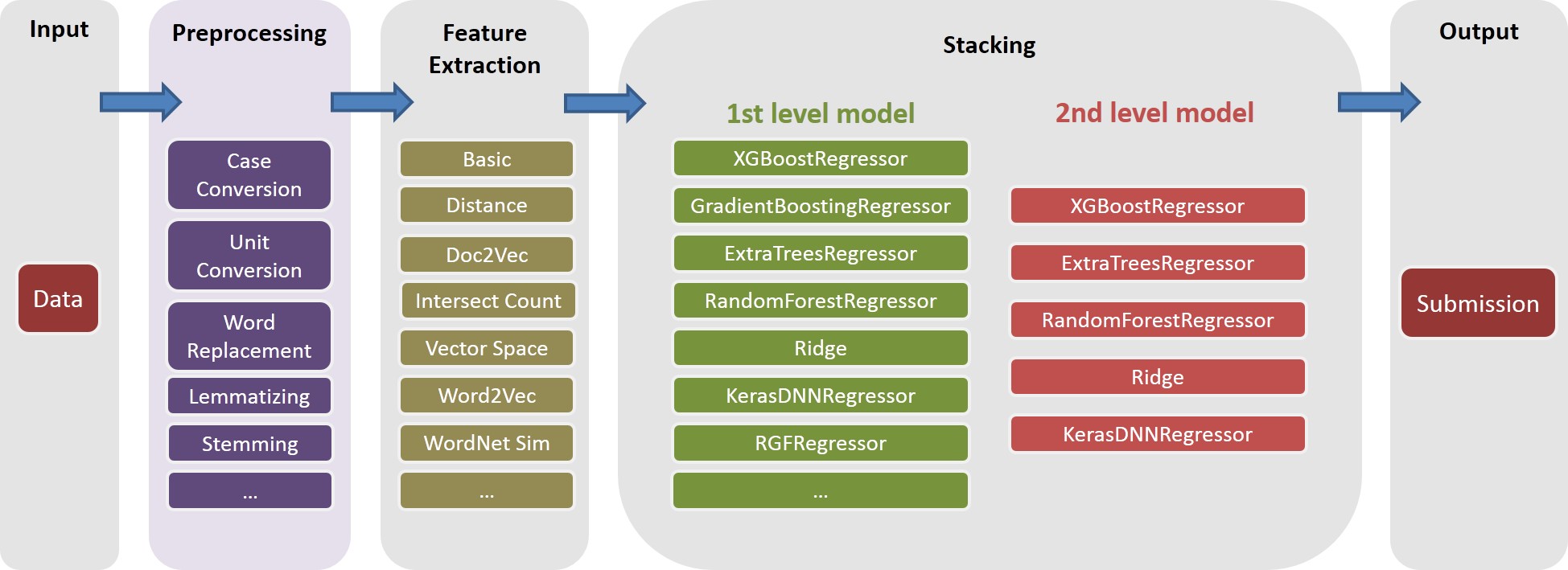
См ./Doc/Kaggle_HomeDepot_Turing_Test.pdf
Прежде чем продолжить, нужно разместить все данные с веб -сайта конкурса в папку ./Data .
Обратите внимание, что в дальнейшем все команды и сценарии выполняются и запускаются в каталоге ./Code/Chenglong .
Мы использовали Python 3.5.1, а модули поставляются с Anaconda 2.4.1 (64-бит). Кроме того, мы также использовали следующие библиотеки и модули:
Мы использовали следующие пакеты, установленные через install.packages() :
Мы использовали следующие сторонние пакеты:
Мы использовали предварительно обученные модели Word2VEC, перечисленные в этом репо GitHub. В конкретном:
Мы использовали перчатки-Gensim, чтобы преобразовать перчатки в формат Word2VEC для легкого использования с Gensim. После этого поместите все модели в соответствующий каталог (см. Подробности см. config.py ).
Мы также использовали следующие внешние данные:
./Data/dict/color_data.py в этом репо.google_spelling_checker_dict.py в этом репо../Data/dict/word_replacer.csv в этом репо.nltk.download() , в частности: stopwords.zip , wordnet.zip и maxent_treebank_pos_tagger.zip . Чтобы сгенерировать данные и функции, следует запустить python run_data.py . Хотя мы старались изо всех сил, чтобы сделать вещи максимально параллелизмом и эффективными, эта часть может по -прежнему занять 1 ~ 2 дня, в зависимости от вычислительной мощности. Так что будь терпелив :)
Обратите внимание, что различные текстовые обработки полезны для введения разнообразия в ансамбль. На самом деле, один набор функций (т. Е. basic20160313 ) из нашего окончательного решения генерируется до того, как пост исправлены опечатки, то есть, не используя словарь коррекции орфографии Google. Такая версия функций может быть сгенерирована, отключив флаг GOOGLE_CORRECTING_QUERY в config.py .
После того, как команда слилась с Igor & Kostia, мы перестроили все с нуля, и большинство наших моделей использовали различные подмножества функций Igor & Kostia. По этой причине вам также необходимо генерировать их функции. Поскольку функции Igor & Kostia находятся в формате DataFrame .csv , мы предоставляем конвертер turing_test_converter.py , чтобы преобразовать их в формат, который мы используем, то есть .pkl .
На шаге 3 мы сгенерировали несколько тысяч функций. Однако только их часть будет использоваться для создания нашей модели. Например, нам не нужны те функции, которые имеют очень небольшую прогнозирующую силу (например, имеют очень небольшую корреляцию с целевой актуальностью.) Таким образом, нам нужно сделать некоторый выбор функций.
В нашем решении выбор функции включен через следующие два последовательных шага.
Этот подход реализован как get_feature_conf_*.py . Общая идея состоит в том, чтобы включить или исключить конкретные функции с помощью операций regex имен функций. Например,
MANDATORY_FEATS , несмотря на ее корреляцию с цельюCOMMENT_OUT_FEATS , несмотря на ее корреляцию с целью ( MANDATORY_FEATS имеет более высокий приоритет, чем COMMENT_OUT_FEATS .) Вывод этого - это файл COFF функции. Например, после выполнения следующей команды:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
Мы получим новую функцию conf ./conf/feature_conf_nonlinear_201605010058.py , который содержит словарь функций, указывающий функции, которые должны быть включены в следующий шаг.
Можно поиграть с MANDATORY_FEATS и COMMENT_OUT_FEATS чтобы генерировать различные подмножество функций. Мы включили в ./conf Среди них feature_conf_nonlinear_201604210409.py используется для создания лучшей единственной модели.
С помощью приведенной выше функции CONF можно объединить все функции в матрицу функций с помощью следующей команды:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
Приведенный выше -t 0.05 используется для включения выбора базовой функции корреляции. В этом случае это означает: сбросьте любую функцию, которая имеет корреляционный коф, ниже 0.05 с целевой актуальностью.
TODO (Chenglong): Исследуйте другие стратегии выбора функций, например, жадный выбор функций вперед (FFS) и жадный выбор обратной функции (BFS).
В нашем решении task представляет собой композицию объекта конкретной feature (например, basic_nonlinear_201604210409 ) и конкретного learner ( XGBoostRegressor от xgboost). Определения для task , feature и learner находятся в task.py .
Возьмите следующую команду, например.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
task с feature basic_nonlinear_201604210409 и learner reg_xgb_tree .task оптимизирована с помощью Hyperopt для 100 Evals для поиска лучших параметров для learner reg_xgb_tree .task выполняет как резюме, так и окончательный ремонт. CV в этом случае имеет две цели: 1) направляйте гипериопт, чтобы найти лучшие параметры, и 2) генерировать прогнозы для каждого сгиба CV для дальнейшего (2 -й и 3 -й уровень).model_param_space.py . Во время конкурса мы выполняли различные задачи (т.е. различные функции и различные ученики) для создания разнообразной библиотеки модели 1 -го уровня. Пожалуйста, смотрите ./Log/level1_models для всех задач, которые мы включили в нашу последнюю подчинение.
После генерации feature basic_nonlinear_201604210409 (см. Шаг 4, как это генерировать), запустите следующую команду, чтобы создать лучшую единственную модель:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
Это должно генерировать подчинение с локальным CV RMSE около 0,438 ~ 0,439.
После создания некоторых разнообразных моделей 1 -го уровня запустите следующую команду, чтобы создать лучшую модель ансамбля:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
Это должно генерировать представление с местным CV RMSE около 0,436.
Прежде чем продолжить, следует указать правильные пути в файле config_IgorKostia.py и поместить все данные с веб -сайта конкуренции в папку, указанные переменной DATA_DIR . Чтобы воспроизвести наш Ensemble_B с шага IK5, нужно разместить используемые наборы функций в папку, указанные переменными FEATURESETS_DIR . Обратите внимание, что в дальнейшем все команды и сценарии выполняются и запускаются в каталоге ./Code/Igor&Kostia .
Мы использовали Python 2.7.11 на платформе Windows и модулях поставляются с Anaconda 2.4.0 (64-бит), включая:
Кроме того, мы также использовали следующие библиотеки и модули:
nltk.download() )Некоторый описательный анализ и окончательное смешивание модели также были сделаны в Excel 2007 и Excel 2010.
Мы делаем всю предварительную обработку текста перед каким -либо генерацией функций и сохраняем результаты в файлы. Это помогло нам сэкономить несколько вычислительных дней, так как те же шаги предварительной обработки необходимы для создания различных функций.
text_processing.py .text_processing_wo_google.py . Необходимые данные замены загружаются автоматически из файлов homedepot_functions.py и google_dict.py .
Следовательно, нам нужно запустить следующие файлы:
feature_extraction1.py .grams_and_terms_features.py .dld_features.py .word2vec.py .Чтобы сгенерировать функции без использования словаря Google, нам также нужно запустить:
feature_extraction1_wo_google.py .word2vec_without_google_dict.py .В результате у нас будет несколько файлов CSV с необходимыми функциями для построения модели.
generate_feature_importances.py . Одна часть ансамблевого Ensemble_A генерируется из следующего кода:
generate_models.py .generate_model_wo_google.py .generate_ensemble_output_from_models.py . Чтобы получить другую часть Ensemble_B , нам нужно запустить эти файлы:
ensemble_script_imitation_version.py (он просто воспроизводит выбор случайных функций, сгенерированных из ensemble_script_random_version.py . Вам не нужно запускать ensemble_script_random_version.py снова).model_selecting.py . Эти две части могут быть сгенерированы параллельно. Наше окончательное представление Igor & Kostia было затем подушено в Excel AS: Output = 0,75 Ensemble_A + 0,25 Ensemble_B
Итак, у нас было два ансамбля, подготовленные с использованием различных методологий. Мы заметили, что наши ансамбли ведут себя по -разному в разных частях наборов данных ( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473 Поскольку мы наблюдали регулярные паттерны в данных, мы думали, что один из ансамблей может быть особенно подверженным постоянным в некоторых частях. Пока, в то время как мы, в то время как они были в конечном итоге. Предполагая, что в некоторых частях одна из моделей будет вести себя намного хуже наедине, чем на публике.
Наши два последних подчинения были получены в Excel с весами из приведенной ниже таблицы (вес для частей Ченглонга и Игоря и Костии составлял до 1). Оба эти представления набрали одинаковые 0.43271 в частной таблице лидеров.
Вес Chenglong для part1 и part2 | Вес Чэнлонг для part3 | Public LB RMSE | Частный LB RMSE | |
|---|---|---|---|---|
| Подчинение 1 | 0,75 | 0,8 | 0,43443 | 0,43271 |
| Подчинение 2 | 0,6 | 0,3 | 0,43433 | 0,43271 |


