kaggle HomeDepot
1.0.0
Kaggleでのホームデポ製品検索関連競争のためのチューリングテストのソリューション
| 提出 | CV RMSE | パブリックLB RMSE | プライベートLB RMSE | 位置 |
|---|---|---|---|---|
| IgorとKostiaからの簡略化された単一モデル(10の機能) | 0.44792 | 0.45072 | 0.44949 | 31 |
| IgorとKostiaの最高の単一モデル | 0.43787 | 0.44017 | 0.43895 | 11 |
| Chenglongの最高の単一モデル | 0.43832 | 0.43996 | 0.43811 | 9 |
| イゴールとコスティアの最高のアンサンブルモデル | - | 0.43819 | 0.43704 | 8 |
| Chenglongの最高のアンサンブルモデル | 0.43550 | 0.43555 | 0.43368 | 6 |
| 最高の最終アンサンブルモデル | - | 0.43433 | 0.43271 | 3 |
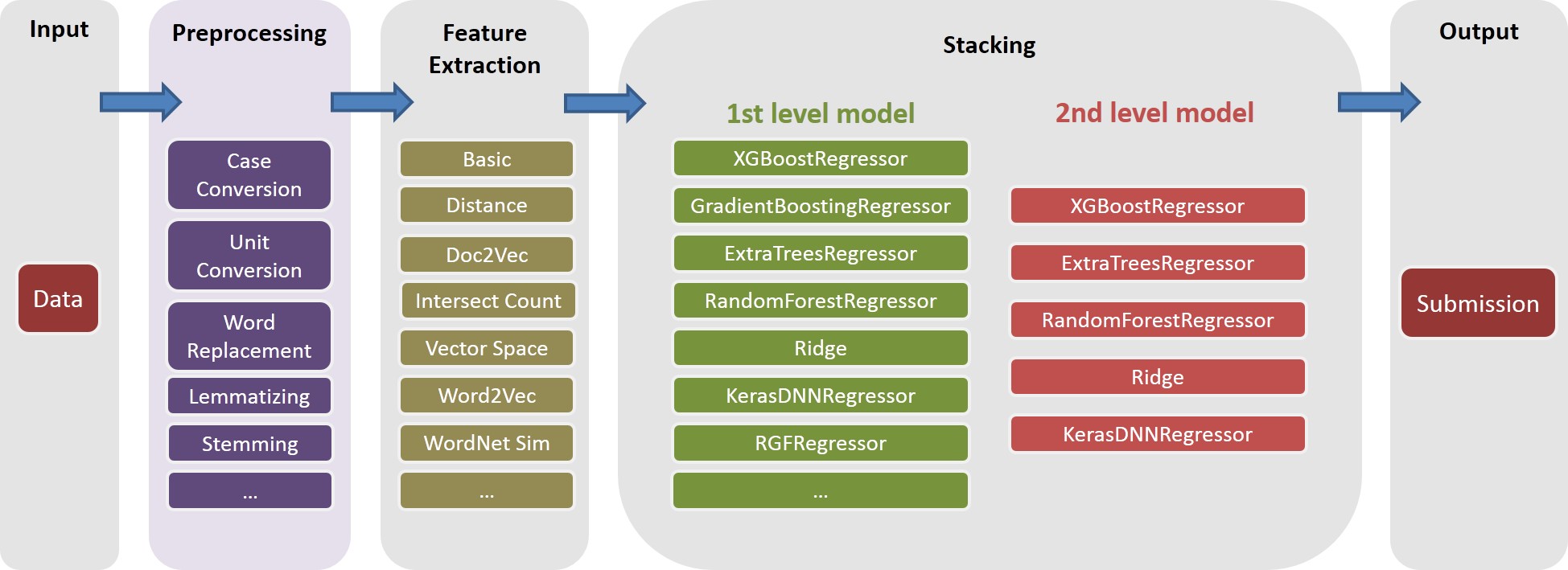
ドキュメントについては./Doc/Kaggle_HomeDepot_Turing_Test.pdfを参照してください。
先に進む前に、競争WebサイトのすべてのデータをFolder ./Dataに配置する必要があります。
以下では、すべてのコマンドとスクリプトが実行され、Directory ./Code/Chenglongで実行されていることに注意してください。
Python 3.5.1を使用し、モジュールにはAnaconda 2.4.1(64ビット)が付属しています。さらに、次のライブラリとモジュールも使用しました。
install.packages()を介してインストールされた次のパッケージを使用しました。
次のサードパーティパッケージを使用しました。
このgithubリポジトリにリストされている事前に訓練されたword2vecモデルを使用しました。具体的には:
Glove-Gensimを使用して、Gensimで簡単に使用できるように、Glove VectorsをWord2vec形式に変換しました。その後、すべてのモデルを対応するディレクトリに入れます(詳細についてはconfig.pyを参照)。
また、次の外部データも使用しました。
./Data/dict/color_data.py color_data.pyこのリポジトリ。google_spelling_checker_dict.py./Data/dict/word_replacer.csv word_replacer.csvこのレポの。nltk.download()を使用してダウンロードされたnltkコーパスおよびタガーデータ、具体的には、 stopwords.zip 、 wordnet.zip 、 maxent_treebank_pos_tagger.zip 。 データと機能を生成するには、 python run_data.py実行する必要があります。できるだけ並列性と効率的なものを作るように最善を尽くしましたが、この部分は計算能力に応じて終了するまでに1〜2日かかる場合があります。だから我慢してください:)
さまざまなテキスト処理は、多様性をアンサンブルに導入するのに役立つことに注意してください。実際のところ、最終的なソリューションからの1つの機能セット(つまり、 basic20160313 )は、Google Spelling Correction Dictionaryを使用していないタイプミスの投稿の前に生成されます。このようなバージョンの機能は、 config.pyのGOOGLE_CORRECTING_QUERYフラグをオフにすることで生成できます。
Igor&Kostiaとチームが合併した後、すべてをゼロから再構築しました。ほとんどのモデルは、Igor&Kostiaの機能のさまざまなサブセットを使用しました。このため、機能を生成する必要があります。 Igor&Kostiaの機能は.csv DataFrame形式であるため、Converter turing_test_converter.pyを提供して、使用する形式、すなわち、 .pklに変換します。
ステップ3では、数千の機能を生成しました。ただし、モデルの構築に使用されるのはそれらの一部のみです。たとえば、予測力がほとんどない機能は必要ありません(たとえば、ターゲット関連性と非常に小さな相関関係があります。)したがって、いくつかの機能選択を行う必要があります。
ソリューションでは、次の2つの連続したステップで機能の選択が有効になります。
このアプローチはget_feature_conf_*.pyとして実装されています。一般的なアイデアは、機能名のregex操作を介して特定の機能を含めるか除外することです。例えば、
MANDATORY_FEATS変数を介して含めたい機能を指定できます。COMMENT_OUT_FEATS変数を介して除外したい機能を指定することもできます( MANDATORY_FEATS COMMENT_OUT_FEATSも優先度が高い)これの出力は機能confファイルです。たとえば、次のコマンドを実行した後:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
次のステップに含まれる機能を指定する機能辞書を含む、新しい機能./conf/feature_conf_nonlinear_201605010058.pyを取得します。
MANDATORY_FEATSとCOMMENT_OUT_FEATSで遊んで、異なる機能サブセットを生成できます。 ./confには、最終的な提出から他のいくつかの機能confを含めました。その中で、 feature_conf_nonlinear_201604210409.pyは、最高の単一モデルを構築するために使用されます。
上記の機能confを使用すると、次のコマンドを介してすべての機能を機能マトリックスに組み合わせることができます。
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
上記の-t 0.05相関ベース機能の選択を有効にするために使用されます。この場合、それは次のことを意味します:ターゲット関連性と0.05未満の相関係数を持つ機能をドロップします。
Todo(Chenglong):他の機能選択戦略を探索します。
ソリューションでは、 taskは、特定のfeature ( basic_nonlinear_201604210409など)と特定のlearner (xgboostのXGBoostRegressor )のオブジェクトを複合するオブジェクトです。 task 、 feature 、 learnerの定義はtask.pyにあります。
たとえば、次のコマンドをご覧ください。
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
feature basic_nonlinear_201604210409およびlearner reg_xgb_treeを使用してtaskを実行します。task 、 learner reg_xgb_treeに最適なパラメーターを検索するために、 100のEvalのHyperoptで最適化されています。task 、CVと最終的な再調整の両方を実行します。この場合、CVには2つの目的があります。1)ハイパーオプトをガイドして最適なパラメーターを見つける、2)さらに(2番目と3番目のレベル)スタッキングのために各CV foldの予測を生成します。model_param_space.pyを参照してください。競争中に、さまざまなタスク(さまざまな機能、さまざまな学習者)を実行して、多様な第1レベルモデルライブラリを生成しています。最終提出に含めたすべてのタスクについては、 ./Log/level1_models Level1_Modelsを参照してください。
featureを生成した後、 basic_nonlinear_201604210409 (これを生成する方法を参照)を参照して、次のコマンドを実行して、最適な単一モデルを生成します。
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
これにより、ローカルCV RMSEで0.438〜0.439前後の提出が生成されるはずです。
多様な第1レベルモデルを構築した後、次のコマンドを実行して、最高のアンサンブルモデルを生成します。
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
これにより、ローカルCV RMSEが0.436前後で提出されるはずです。
先に進む前に、ファイルconfig_IgorKostia.pyの正しいパスを指定し、競合Webサイトからすべてのデータを変数DATA_DIRで指定されたフォルダーに配置する必要があります。ステップIK5からEnsemble_B再現するには、使用する機能セットを可変FEATURESETS_DIRで指定されたフォルダーに配置する必要があります。以下では、すべてのコマンドとスクリプトが実行され、Directory ./Code/Igor&Kostiaで実行されることに注意してください。
WindowsプラットフォームでPython 2.7.11を使用し、モジュールにはAnaconda 2.4.0(64ビット)が付属しています。
さらに、次のライブラリとモジュールも使用しました。
nltk.download()コマンドを使用)いくつかの記述分析と最終モデルのブレンドも、Excel 2007およびExcel 2010で行われました。
機能生成の前にすべてのテキストを前処理し、結果をファイルに保存します。異なる機能を生成するために同じ前処理手順が必要であるため、数日間のコンピューティング日を節約するのに役立ちました。
text_processing.pyを実行します。text_processing_wo_google.pyを実行します。必要な交換データは、ファイルhomedepot_functions.pyおよびgoogle_dict.pyから自動的にロードされます。
結果として次のファイルを実行する必要があります。
feature_extraction1.py 。grams_and_terms_features.py 。dld_features.py 。word2vec.py 。Google Dictionaryを使用せずに機能を生成するには、実行する必要もあります。
feature_extraction1_wo_google.py 。word2vec_without_google_dict.py 。その結果、モデル構築に必要な機能を備えたいくつかのCSVファイルがあります。
generate_feature_importances.pyを実行します。 アンサンブルEnsemble_Aの一部は、次のコードから生成されます。
generate_models.py 。generate_model_wo_google.py 。generate_ensemble_output_from_models.py 。他の部分を取得するには、 Ensemble_Bするには、これらのファイルを実行する必要があります。
ensemble_script_imitation_version.py ( ensemble_script_random_version.pyから生成されたランダム機能の選択を再現するだけです。ensemble_script_random_version.py ensemble_script_random_version.py再度実行する必要はありません)。model_selecting.py 。これらの2つの部分は、並行して生成できます。 Igor&Kostiaからの最終的な提出は、Excelで生産されました。 Output = 0.75 Ensemble_A + 0.25 Ensemble_B
そのため、さまざまな方法論を使用して2つのアンサンブルが用意されていました。私たちのアンサンブルは、データセットのさまざまな部分で異なる動作をします( part1 : id<=163700 、 part2 : 163700 < id <= 221473 、 part_3 : id > 221473 。一部の部分では、モデルの1つが公共の場よりもプライベートではるかに悪化すると仮定します。
私たちの2つの最終的な提出は、以下の表の重みでExcelで作成されました(ChenglongとIgor&Kostiaの部品の重みは1になります)。これらの両方の提出物は、プライベートリーダーボードで同じ0.43271を獲得しました。
part1およびpart2の重量Chenglong | part3の重量chenglong | パブリックLB RMSE | プライベートLB RMSE | |
|---|---|---|---|---|
| 提出1 | 0.75 | 0.8 | 0.43443 | 0.43271 |
| 提出2 | 0.6 | 0.3 | 0.43433 | 0.43271 |


