kaggle HomeDepot
1.0.0
Turing Test -Lösung für Home Depot -Produktsuche Relevanz Wettbewerb auf Kaggle
| Vorlage | CV RMSE | Öffentliche LB RMSE | Privat LB RMSE | Position |
|---|---|---|---|---|
| Vereinfachtes Einzelmodell von Igor und Kostia (10 Merkmale) | 0,44792 | 0,45072 | 0,44949 | 31 |
| Bestes Einzelmodell aus Igor und Kostia | 0,43787 | 0,44017 | 0,43895 | 11 |
| Bestes Einzelmodell aus Chglong | 0,43832 | 0,43996 | 0,43811 | 9 |
| Bestes Ensemble -Modell aus Igor und Kostia | - - | 0,43819 | 0,43704 | 8 |
| Bestes Ensemble -Modell aus Chenglong | 0,43550 | 0,43555 | 0,43368 | 6 |
| Bestes endgültiges Ensemble -Modell | - - | 0,43433 | 0,43271 | 3 |
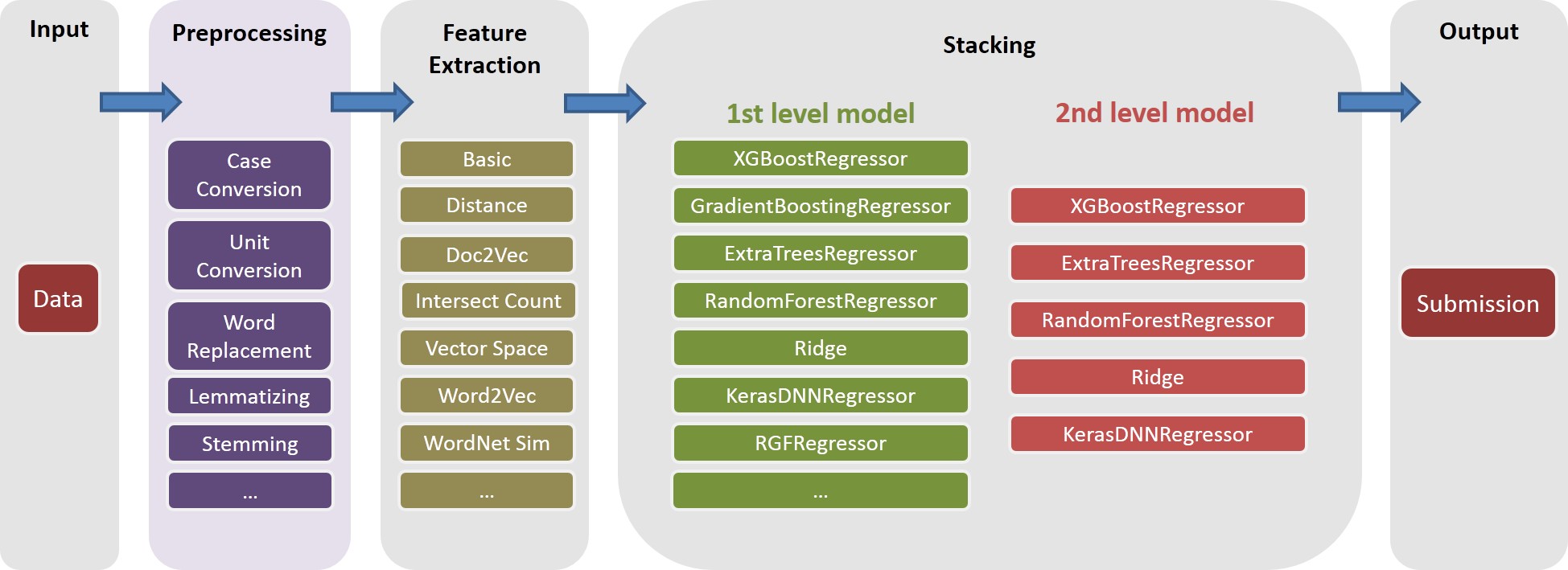
Siehe ./Doc/Kaggle_HomeDepot_Turing_Test.pdf zur Dokumentation.
Vor dem Fortfahren sollte man alle Daten von der Wettbewerbswebsite in den Ordner ./Data einbringen.
Beachten Sie, dass im Folgenden alle Befehle und Skripte im Verzeichnis ausgeführt und ausgeführt werden ./Code/Chenglong .
Wir haben Python 3.5.1 verwendet und die Module sind mit Anaconda 2.4.1 (64-Bit) geliefert. Darüber hinaus haben wir auch die folgenden Bibliotheken und Module verwendet:
Wir haben die folgenden Pakete verwendet, die über install.packages() installiert wurden:
Wir haben die folgenden Drittanteilspakete verwendet:
Wir haben vorgebildete Word2VEC-Modelle verwendet, die in diesem GitHub-Repo aufgeführt sind. In spezifisch:
Wir haben Handschuhgensim verwendet, um Handschuhvektoren in das Word2VEC-Format umzuwandeln, um mit Gensim eine einfache Verwendung zu verwenden. Stellen Sie danach alle Modelle in das entsprechende Verzeichnis (siehe Details siehe config.py ).
Wir haben auch die folgenden externen Daten verwendet:
./Data/dict/color_data.py in diesem Repo.google_spelling_checker_dict.py ../Data/dict/word_replacer.csv in diesem Repo.nltk.download() heruntergeladen wurden, speziell: stopwords.zip , wordnet.zip und maxent_treebank_pos_tagger.zip . Um Daten und Funktionen zu generieren, sollte man python run_data.py ausführen. Obwohl wir unser Bestes versucht haben, die Dinge so Parallelität und effizient wie möglich zu machen, kann dieser Teil je nach Rechenleistung immer noch 1 ~ 2 Tage dauern. Also sei geduldig :)
Beachten Sie, dass verschiedene Textverarbeitung nützlich ist, um die Vielfalt in das Ensemble einzuführen. Tatsächlich wird ein Feature -Set (dh basic20160313 ) aus unserer endgültigen Lösung vor dem Fixing -Tippfehler -Beitrag generiert, dh nicht das Google Spelling Correction Dictionary. Eine solche Version der Funktionen kann generiert werden, indem das Flagg GOOGLE_CORRECTING_QUERY in config.py ausgeschaltet wird.
Nachdem das Team mit Igor & Kostia zusammengeführt wurde, haben wir alles von Grund auf neu aufgebaut, und die meisten unserer Modelle verwendeten verschiedene Untergruppen von Igor & Kostia. Aus diesem Grund sollten Sie auch ihre Funktionen generieren müssen. Da die Funktionen von Igor & Kostia im .csv -Datenfreame -Format sind, stellen wir einen Konverter turing_test_converter.py zur Verfügung, um sie in das von uns verwendete Format, dh .pkl zu konvertieren.
In Schritt 3 haben wir ein paar tausend Funktionen generiert. Es werden jedoch nur ein Teil von ihnen verwendet, um unser Modell zu erstellen. Zum Beispiel benötigen wir nicht die Merkmale, die nur sehr wenig Vorhersagekraft haben (z. B. eine sehr geringe Korrelation mit der Zielrelevanz.) Daher müssen wir einige Merkmalsauswahl treffen.
In unserer Lösung wird die Feature -Auswahl über die folgenden zwei aufeinanderfolgenden Schritte aktiviert.
Dieser Ansatz wird als get_feature_conf_*.py implementiert. Die allgemeine Idee besteht darin, bestimmte Funktionen über regex -Operationen der Feature -Namen einzubeziehen oder auszuschließen. Zum Beispiel,
MANDATORY_FEATS einbeziehen möchte, trotz seiner Korrelation mit dem ZielCOMMENT_OUT_FEATS ausschließen möchte, trotz seiner Korrelation mit dem Ziel ( MANDATORY_FEATS hat eine höhere Priorität als COMMENT_OUT_FEATS .) Die Ausgabe davon ist eine Feature Conf -Datei. Zum Beispiel nach dem Ausführen des folgenden Befehls:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
Wir erhalten ein neues Feature Conf ./conf/feature_conf_nonlinear_201605010058.py , das ein Feature -Wörterbuch enthält, das die Funktionen angibt, die in den folgenden Schritt enthalten sind.
Man kann mit MANDATORY_FEATS und COMMENT_OUT_FEATS herumspielen, um eine unterschiedliche Feature -Teilmenge zu generieren. Wir haben in ./conf ein paar andere Feature Confs aus unserer endgültigen Einreichung aufgenommen. Unter ihnen wird feature_conf_nonlinear_201604210409.py verwendet, um das beste Einzelmodell zu erstellen.
Mit der oben generierten Feature Conf -Feature -Feature kann man alle Funktionen über den folgenden Befehl in eine Funktionsmatrix kombinieren:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
Die oben genannten -t 0.05 wird verwendet, um die Auswahl der Korrelationsbasisfunktion zu aktivieren. In diesem Fall bedeutet dies: Lassen Sie alle Merkmale mit einer Korrelations -COEF von weniger als 0.05 mit der Zielrelevanz fallen.
TODO (Chenglong): Erforschen Sie andere Feature -Auswahlstrategien, z. B. die Auswahl der Greedy Forward -Feature (FFS) und die Greedy Backward -Feature -Auswahl (BFS).
In unserer Lösung ist eine task ein Objekt zusammengesetzt, das eine bestimmte feature (z. B. basic_nonlinear_201604210409 ) und einen bestimmten learner ( XGBoostRegressor von Xgboost) zusammengesetzt ist. Die Definitionen für task , feature und learner sind in task.py
Nehmen Sie zum Beispiel den folgenden Befehl.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
task mit feature basic_nonlinear_201604210409 und learner reg_xgb_tree ausgeführt.task wird mit Hyperopt für 100 Evals optimiert, um die besten Parameter für learner reg_xgb_tree zu durchsuchen.task führt sowohl den Lebenslauf als auch die endgültige Überholung durch. Der Lebenslauf hat in diesem Fall zwei Zwecke: 1) Leitfaden Hyperopt, um die besten Parameter zu finden, und 2) Vorhersagen für jede CV -Faltung für eine weitere Stapelung (2. und 3. Ebene) erzeugen.model_param_space.py . Während des Wettbewerbs haben wir verschiedene Aufgaben (dh verschiedene Funktionen und verschiedene Lernende) ausgeführt, um eine vielfältige Modellbibliothek auf der ersten Ebene zu generieren. Bitte siehe ./Log/level1_models
Führen Sie den feature Befehl aus, um das beste basic_nonlinear_201604210409 zu generieren:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
Dies sollte eine Einreichung mit lokalem Lebenslauf um 0,438 ~ 0,439 erzeugen.
Führen Sie nach dem Erstellen einiger verschiedener Modelle der ersten Ebene den folgenden Befehl aus, um das beste Ensemble -Modell zu generieren:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
Dies sollte eine Einreichung mit lokalem Lebenslauf um 0,436 erzeugen.
Vor dem Fortfahren sollte man korrekte Pfade in der Datei config_IgorKostia.py angeben und alle Daten von der Wettbewerbswebsite in den Ordner, das durch variable DATA_DIR angegeben ist, eingeben. Um unser Ensemble_B aus Schritt IK5 zu reproduzieren, sollte man die verwendeten Featuressätze in den Ordner einfügen, der durch variable FEATURESETS_DIR angegeben ist. Beachten Sie, dass im Folgenden alle Befehle und Skripte im Verzeichnis ausgeführt und ausgeführt werden ./Code/Igor&Kostia .
Wir haben Python 2.7.11 auf Windows-Plattform verwendet und Module sind mit Anaconda 2.4.0 (64-Bit) geliefert, einschließlich:
Darüber hinaus haben wir auch die folgenden Bibliotheken und Module verwendet:
nltk.download() )Einige deskriptive Analysen und die endgültige Modellmischung wurden auch in Excel 2007 und Excel 2010 durchgeführt.
Wir machen alle Textvorbereitungen vor jeder Funktion Erzeugung und speichern die Ergebnisse in Dateien. Es hat uns geholfen, einige Computertage zu sparen, da dieselben Vorverarbeitungsschritte erforderlich sind, um unterschiedliche Funktionen zu generieren.
text_processing.py ausführen.text_processing_wo_google.py aus. Die erforderlichen Ersatzdaten werden automatisch aus Dateien geladen homedepot_functions.py und google_dict.py .
Wir müssen folglich die folgenden Dateien ausführen:
feature_extraction1.py .grams_and_terms_features.py .dld_features.py .word2vec.py .Um Funktionen zu generieren, ohne das Google Dictionary zu verwenden, müssen wir auch ausführen:
feature_extraction1_wo_google.py .word2vec_without_google_dict.py .Infolgedessen haben wir einige CSV -Dateien mit den erforderlichen Funktionen für die Modellbildung.
generate_feature_importances.py . Ein Teil des Ensemble Ensemble_A wird aus dem folgenden Code generiert:
generate_models.py .generate_model_wo_google.py .generate_ensemble_output_from_models.py . Um das andere Teil Ensemble_B zu erhalten, müssen wir diese Dateien ausführen:
ensemble_script_imitation_version.py (es reproduziert nur die Auswahl zufälliger Funktionen ensemble_script_random_version.py die aus ensemble_script_random_version.py generiert werden.model_selecting.py . Diese beiden Teile können parallel erzeugt werden. Unsere endgültige Einreichung von Igor & Kostia wurde dann in Excel als: Output = 0,75 Ensemble_A + 0,25 Ensemble_B produziert
Wir hatten also zwei Ensembles mit verschiedenen Methoden vorbereitet. Wir beobachteten, dass sich unsere Ensembles in verschiedenen Teilen der Datensätze unterschiedlich verhalten ( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473 Da wir auch regelmäßige Muster beobachteten, die auch in den Daten regelmäßig Muster beobachteten, machten wir auch, dass ein der Ensembles zu einem Abschluss war. Angenommen, in einigen Teilen würde sich eines der Modelle privat viel schlechter als in der Öffentlichkeit verhalten.
Unsere beiden endgültigen Einreichungen wurden in Excel mit den Gewichten aus der folgenden Tabelle erzeugt (das Gewicht für Chenglongs und Igor & Kostias Teile summieren sich zu 1). Beide Einsendungen erzielten in der privaten Rangliste die gleichen 0.43271 .
Gewicht Chenglong für part1 und part2 | Gewicht Chenglong für part3 | Öffentliche LB RMSE | Privat LB RMSE | |
|---|---|---|---|---|
| Einreichung 1 | 0,75 | 0,8 | 0,43443 | 0,43271 |
| Einreichung 2 | 0,6 | 0,3 | 0,43433 | 0,43271 |


