kaggle HomeDepot
1.0.0
Solução do teste de Turing para a concorrência de relevância da pesquisa de produtos da Home Depot em Kaggle
| Submissão | CV RMSE | Public lb rmse | Private LB RMSE | Posição |
|---|---|---|---|---|
| Modelo único simplificado da Igor e Kostia (10 recursos) | 0,44792 | 0,45072 | 0,44949 | 31 |
| Melhor modelo único de Igor e Kostia | 0,43787 | 0,44017 | 0,43895 | 11 |
| Melhor modelo único de Chenglong | 0,43832 | 0,43996 | 0.43811 | 9 |
| Melhor modelo de conjunto de Igor e Kostia | - | 0,43819 | 0,43704 | 8 |
| Melhor modelo de conjunto de Chenglong | 0,43550 | 0,43555 | 0,43368 | 6 |
| Melhor modelo de conjunto final | - | 0,43433 | 0,43271 | 3 |
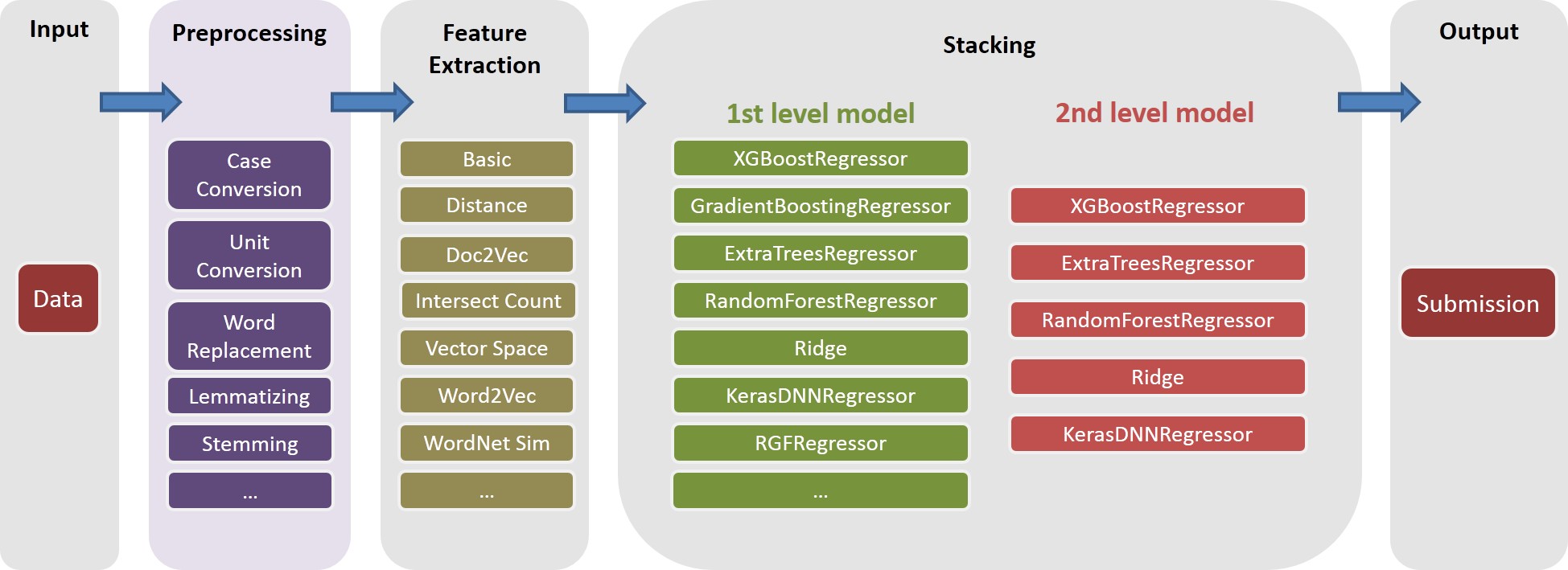
Veja ./Doc/Kaggle_HomeDepot_Turing_Test.pdf para documentação.
Antes de prosseguir, deve -se colocar todos os dados do site da concorrência na pasta ./Data .
Observe que, a seguir, todos os comandos e scripts são executados e executados no diretório ./Code/Chenglong .
Utilizamos o Python 3.5.1 e os módulos vêm com a ANACONDA 2.4.1 (64 bits). Além disso, também usamos as seguintes bibliotecas e módulos:
Usamos os seguintes pacotes instalados via install.packages() :
Usamos os seguintes pacotes de terceiros:
Utilizamos modelos pré-treinados do Word2VEC listados neste repositório do GitHub. Em específico:
Utilizamos o Glove-Gensim para converter vetores de luvas em formato Word2vec para facilitar o uso com o Gensim. Depois disso, coloque todos os modelos no diretório correspondente (consulte config.py para obter detalhes).
Também usamos os seguintes dados externos:
./Data/dict/color_data.py neste repo.google_spelling_checker_dict.py neste repositório../Data/dict/word_replacer.csv neste repo.nltk.download() , especificamente: stopwords.zip , wordnet.zip e maxent_treebank_pos_tagger.zip . Para gerar dados e recursos, deve -se executar python run_data.py . Embora tenhamos tentado o nosso melhor para tornar as coisas o mais paralelismo e eficiente possível, essa parte ainda pode levar 1 ~ 2 dias para terminar, dependendo do poder computacional. Então seja paciente :)
Observe que vários processos de texto são úteis para introduzir a diversidade no conjunto. De fato, um conjunto de recursos (ou seja, basic20160313 ) a partir de nossa solução final é gerado antes da correção de erros de digitação, ou seja, não usando o Dicionário de Correção do Google Spelling. Essa versão dos recursos pode ser gerada desligando o sinalizador GOOGLE_CORRECTING_QUERY em config.py .
Depois da equipe se fundindo com a Igor & Kostia, reconstruímos tudo do zero, e a maioria de nossos modelos usava diferentes subconjuntos de recursos da Igor & Kostia. Por esse motivo, você também deve precisar gerar seus recursos. Como os recursos da Igor & Kostia estão no formato .csv DataFrame, fornecemos um conversor turing_test_converter.py para convertê -los no formato que usamos, ou seja, .pkl .
Na etapa 3, geramos alguns milhares de recursos. No entanto, apenas parte deles será usada para construir nosso modelo. Por exemplo, não precisamos desses recursos que tenham muito pouco poder preditivo (por exemplo, têm uma pequena correlação com a relevância do alvo.) Portanto, precisamos fazer alguma seleção de recursos.
Em nossa solução, a seleção de recursos é ativada pelas duas etapas sucessivas a seguir.
Essa abordagem é implementada como get_feature_conf_*.py . A idéia geral é incluir ou excluir recursos específicos por meio de operações regex dos nomes dos recursos. Por exemplo,
MANDATORY_FEATS , apesar de sua correlação com o alvoCOMMENT_OUT_FEATS , apesar de sua correlação com o destino ( MANDATORY_FEATS tem maior prioridade do que COMMENT_OUT_FEATS .) A saída disso é um arquivo confl conf. Por exemplo, depois de executar o seguinte comando:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
Obteremos um novo recurso conf ./conf/feature_conf_nonlinear_201605010058.py , que contém um dicionário de recurso, especificando os recursos a serem incluídos na etapa a seguir.
Pode -se brincar com MANDATORY_FEATS e COMMENT_OUT_FEATS para gerar diferentes subconjuntos de recursos. Incluímos em ./conf alguns outros confs de recursos do nosso envio final. Entre eles, feature_conf_nonlinear_201604210409.py é usado para criar o melhor modelo único.
Com o recurso Gerado acima, pode -se combinar todos os recursos em uma matriz de recursos através do seguinte comando:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
O -t 0.05 acima é usado para ativar a seleção de recursos da base de correlação. Nesse caso, significa: solte qualquer recurso que tenha um coef de correlação inferior a 0.05 com a relevância do alvo.
TODO (CHENGLONG): Explore outras estratégias de seleção de recursos, por exemplo, seleção de recursos para a frente gananciosa (FFS) e seleção gananciosa de recursos para trás (BFS).
Em nossa solução, uma task é um composto de objeto de um feature específico (por exemplo, basic_nonlinear_201604210409 ) e um learner específico ( XGBoostRegressor DO XGBOOST). As definições de task , feature e learner estão em task.py .
Veja o seguinte comando, por exemplo.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
task com feature basic_nonlinear_201604210409 e learner reg_xgb_tree .task é otimizada com o Hyperopt para 100 evalas para pesquisar os melhores parâmetros para learner reg_xgb_tree .task executa o CV e a reforma final. Nesse caso, o CV possui dois propósitos: 1) Guie o hiperopt para encontrar os melhores parâmetros e 2) gerar previsões para cada dobra do CV para empilhamento adicional (2º e 3º nível).model_param_space.py . Durante a competição, executamos várias tarefas (ou seja, vários recursos e vários alunos) para gerar uma biblioteca de modelos de 1º nível diversificada. Consulte ./Log/level1_models para todas as tarefas que incluímos em nosso envio final.
Depois de gerar o feature basic_nonlinear_201604210409 (consulte a Etapa 4 Como gerar isso), execute o seguinte comando para gerar o melhor modelo único:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
Isso deve gerar um envio com CV RMSE local em torno de 0,438 ~ 0,439.
Depois de construir alguns diversos modelos de 1º nível, execute o seguinte comando para gerar o melhor modelo de conjunto:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
Isso deve gerar um envio com CV RMSE local em torno de 0,436.
Antes de prosseguir, deve -se especificar caminhos corretos no arquivo config_IgorKostia.py e colocar todos os dados do site da competição na pasta especificada por variável DATA_DIR . Para reproduzir nosso Ensemble_B da etapa ik5, deve colocar os conjuntos de recursos usados na pasta especificada pelo Variable FEATURESETS_DIR . Observe que, a seguir, todos os comandos e scripts são executados e executados no diretório ./Code/Igor&Kostia .
Utilizamos o Python 2.7.11 na plataforma Windows e os módulos vêm com a ANACONDA 2.4.0 (64 bits), incluindo:
Além disso, também usamos as seguintes bibliotecas e módulos:
nltk.download() comando)Alguma análise descritiva e mistura final do modelo também foram realizadas no Excel 2007 e no Excel 2010.
Fazemos todo o pré -processamento de texto antes de qualquer geração de recursos e salvamos os resultados nos arquivos. Isso nos ajudou a economizar alguns dias de computação, já que as mesmas etapas de pré -processamento são necessárias para gerar diferentes recursos.
text_processing.py .text_processing_wo_google.py . Os dados de substituição necessários são carregados automaticamente a partir de arquivos homedepot_functions.py e google_dict.py .
Precisamos executar consequentemente os seguintes arquivos:
feature_extraction1.py .grams_and_terms_features.py .dld_features.py .word2vec.py .Para gerar recursos sem usar o Google Dictionary, também precisamos executar:
feature_extraction1_wo_google.py .word2vec_without_google_dict.py .Como resultado, teremos alguns arquivos CSV com os recursos necessários para a construção de modelos.
generate_feature_importances.py . Uma parte do Ensemble_A conjuntos é gerada a partir do seguinte código:
generate_models.py .generate_model_wo_google.py .generate_ensemble_output_from_models.py . Para obter a outra parte Ensemble_B , precisamos executar esses arquivos:
ensemble_script_imitation_version.py (apenas reproduz a seleção de recursos aleatórios gerados a partir de ensemble_script_random_version.py . Você não precisa executar ensemble_script_random_version.py novamente).model_selecting.py . Essas duas partes podem ser geradas em paralelo. Nosso envio final da Igor & Kostia foi então produzido no Excel como: Output = 0,75 Ensemble_A + 0,25 Ensemble_B
Então, tivemos dois conjuntos preparados usando metodologias diferentes. Observamos que nossos conjuntos se comportam de maneira diferente em diferentes partes dos conjuntos de dados ( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473 Desde que os padrões regulares, que também se aplicavamos. Isso em algumas partes, um dos modelos se comportaria muito pior em particular do que em público.
Nossa duas submissão final foram produzidas no Excel com os pesos da tabela abaixo (o peso das peças de Chengglong e Igor & Kostia somam até 1). Ambas as submissões obtiveram a mesma 0.43271 na tabela de classificação privada.
Peso Chenglong para part1 e part2 | Peso Chenglong para part3 | Public lb rmse | Private LB RMSE | |
|---|---|---|---|---|
| Envio 1 | 0,75 | 0,8 | 0,43443 | 0,43271 |
| Envio 2 | 0,6 | 0,3 | 0,43433 | 0,43271 |


