kaggle HomeDepot
1.0.0
โซลูชันการทดสอบของทัวริงสำหรับการแข่งขันการค้นหาผลิตภัณฑ์ Home Depot ที่เกี่ยวข้องกับ Kaggle
| การยอมจำนน | CV RMSE | LB สาธารณะ RMSE | LB ส่วนตัว RMSE | ตำแหน่ง |
|---|---|---|---|---|
| รุ่นเดียวที่ง่ายขึ้นจาก Igor และ Kostia (10 คุณสมบัติ) | 0.44792 | 0.45072 | 0.44949 | 31 |
| รุ่นเดียวที่ดีที่สุดจาก Igor และ Kostia | 0.43787 | 0.44017 | 0.43895 | 11 |
| รุ่นเดียวที่ดีที่สุดจาก Chenglong | 0.43832 | 0.43996 | 0.43811 | 9 |
| โมเดลวงดนตรีที่ดีที่สุดจาก Igor และ Kostia | - | 0.43819 | 0.43704 | 8 |
| รุ่นที่ดีที่สุดจาก Chenglong | 0.43550 | 0.43555 | 0.43368 | 6 |
| รุ่นสุดท้ายที่ดีที่สุด | - | 0.43433 | 0.43271 | 3 |
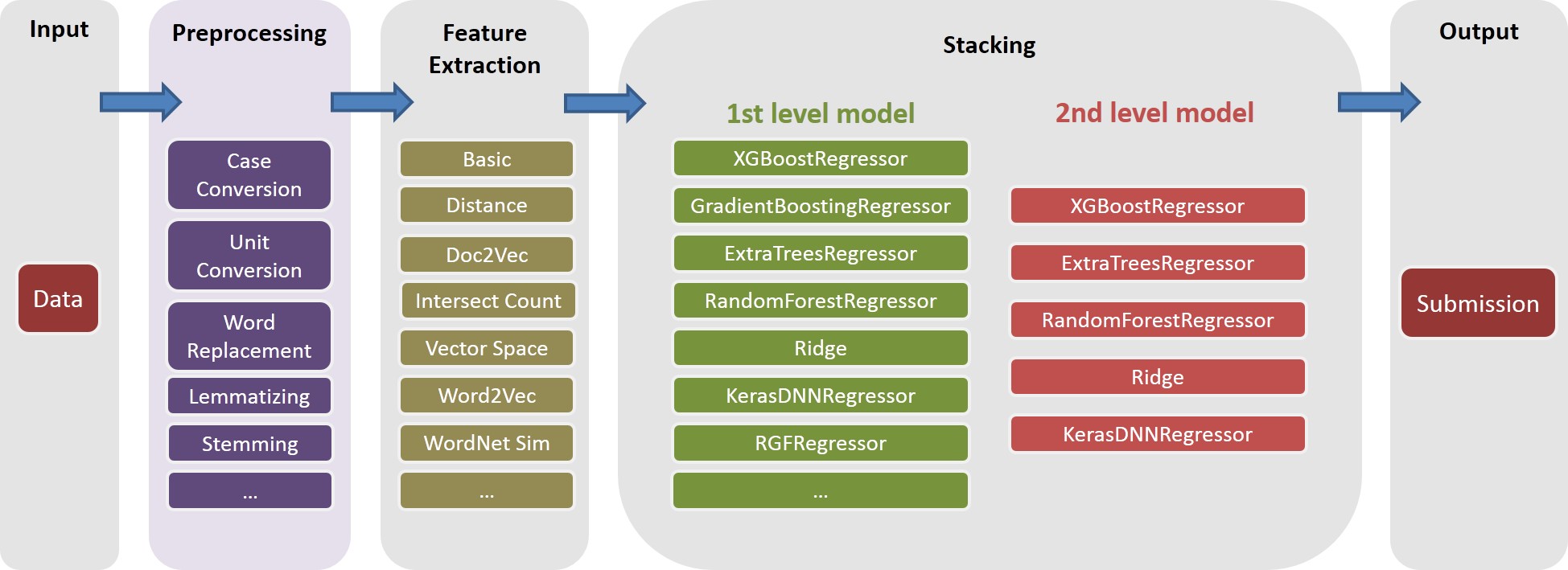
ดู ./Doc/Kaggle_HomeDepot_Turing_Test.pdf สำหรับเอกสารประกอบ
ก่อนที่จะดำเนินการเราควรวางข้อมูลทั้งหมดจากเว็บไซต์การแข่งขันลงในโฟลเดอร์ ./Data data
โปรดทราบว่าในต่อไปนี้คำสั่งและสคริปต์ทั้งหมดจะถูกดำเนินการและเรียกใช้ในไดเรกทอรี ./Code/Chenglong chenglong
เราใช้ Python 3.5.1 และโมดูลมาพร้อมกับ Anaconda 2.4.1 (64 บิต) นอกจากนี้เรายังใช้ไลบรารีและโมดูลต่อไปนี้:
เราใช้แพ็คเกจต่อไปนี้ที่ติดตั้งผ่าน install.packages() :
เราใช้แพ็คเกจที่สามต่อไปนี้:
เราใช้โมเดล Word2vec ที่ผ่านการฝึกอบรมมาแล้วที่แสดงไว้ใน repo github นี้ โดยเฉพาะ:
เราใช้ Glove-Gensim เพื่อแปลงเวกเตอร์ถุงมือเป็นรูปแบบ Word2Vec เพื่อการใช้งานที่ง่ายด้วย gensim หลังจากนั้นใส่โมเดลทั้งหมดในไดเรกทอรีที่เกี่ยวข้อง (ดู config.py สำหรับรายละเอียด)
นอกจากนี้เรายังใช้ข้อมูลภายนอกต่อไปนี้:
./Data/dict/color_data.py ใน repo นี้google_spelling_checker_dict.py ใน repo นี้./Data/dict/word_replacer.csv ใน repo นี้nltk.download() โดยเฉพาะ: stopwords.zip , wordnet.zip และ maxent_treebank_pos_tagger.zip ในการสร้างข้อมูลและคุณสมบัติหนึ่งควรเรียกใช้ python run_data.py ในขณะที่เราพยายามอย่างดีที่สุดในการทำสิ่งต่าง ๆ ให้เป็นแบบขนานและมีประสิทธิภาพเท่าที่จะทำได้ส่วนนี้อาจยังคงใช้เวลา 1 ~ 2 วันกว่าจะเสร็จสิ้นขึ้นอยู่กับพลังการคำนวณ จงอดทน :)
โปรดทราบว่าการประมวลผลข้อความต่าง ๆ มีประโยชน์สำหรับการแนะนำความหลากหลายในวงดนตรี ตามความเป็นจริงแล้วชุดคุณสมบัติหนึ่งชุด (เช่น basic20160313 ) จากโซลูชันสุดท้ายของเราถูกสร้างขึ้นก่อนการแก้ไขการพิมพ์ผิดพลาดคือไม่ได้ใช้พจนานุกรมการแก้ไขการสะกดคำของ Google คุณสมบัติเวอร์ชันดังกล่าวสามารถสร้างขึ้นได้โดยการปิดการตั้งค่าสถานะ GOOGLE_CORRECTING_QUERY ใน config.py
หลังจากทีมรวมกับ Igor & Kostia เราได้สร้างทุกอย่างขึ้นมาใหม่ตั้งแต่เริ่มต้นและโมเดลส่วนใหญ่ของเราใช้ชุดย่อยที่แตกต่างกันของคุณสมบัติของ Igor & Kostia ด้วยเหตุนี้คุณควรสร้างคุณสมบัติของพวกเขาด้วย เนื่องจากคุณสมบัติของ Igor & Kostia อยู่ในรูปแบบ .csv dataframe เราจึงให้ตัวแปลง turing_test_converter.py เพื่อแปลงเป็นรูปแบบที่เราใช้เช่น .pkl
ในขั้นตอนที่ 3 เราได้สร้างคุณสมบัติสองสามพัน อย่างไรก็ตามมีเพียงบางส่วนเท่านั้นที่จะใช้ในการสร้างแบบจำลองของเรา ตัวอย่างเช่นเราไม่ต้องการคุณสมบัติเหล่านั้นที่มีพลังการทำนายน้อยมาก (เช่นมีความสัมพันธ์เล็ก ๆ น้อย ๆ กับความเกี่ยวข้องของเป้าหมาย) ดังนั้นเราต้องทำการเลือกคุณสมบัติบางอย่าง
ในโซลูชันของเราการเลือกคุณสมบัติจะเปิดใช้งานผ่านสองขั้นตอนต่อไปนี้
วิธีการนี้ถูกนำไปใช้เป็น get_feature_conf_*.py แนวคิดทั่วไปคือการรวมหรือไม่รวมคุณสมบัติเฉพาะผ่านการดำเนินการ regex ของชื่อคุณลักษณะ ตัวอย่างเช่น,
MANDATORY_FEATS แม้จะมีความสัมพันธ์กับเป้าหมายCOMMENT_OUT_FEATS แม้จะมีความสัมพันธ์กับเป้าหมาย ( MANDATORY_FEATS มีลำดับความสำคัญสูงกว่า COMMENT_OUT_FEATS ) ผลลัพธ์ของสิ่งนี้คือไฟล์ Feature Conf ตัวอย่างเช่นหลังจากเรียกใช้คำสั่งต่อไปนี้:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
เราจะได้รับฟีเจอร์ใหม่ conf ./conf/feature_conf_nonlinear_201605010058.py ซึ่งมีพจนานุกรมคุณสมบัติที่ระบุคุณสมบัติที่จะรวมอยู่ในขั้นตอนต่อไปนี้
หนึ่งสามารถเล่นได้กับ MANDATORY_FEATS และ COMMENT_OUT_FEATS เพื่อสร้างชุดย่อยคุณสมบัติที่แตกต่างกัน เราได้รวมอยู่ใน ./conf คุณสมบัติอื่น ๆ สองสาม confs จากการส่งครั้งสุดท้ายของเรา ในหมู่พวกเขา feature_conf_nonlinear_201604210409.py ใช้เพื่อสร้างรุ่นเดียวที่ดีที่สุด
ด้วยฟีเจอร์ที่สร้างขึ้นข้างต้น conf หนึ่งสามารถรวมคุณสมบัติทั้งหมดเข้ากับเมทริกซ์คุณสมบัติผ่านคำสั่งต่อไปนี้:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
-t 0.05 ด้านบนใช้เพื่อเปิดใช้งานการเลือกคุณสมบัติฐานสหสัมพันธ์ ในกรณีนี้หมายถึง: วางคุณลักษณะใด ๆ ที่มีค่าสหสัมพันธ์ต่ำกว่า 0.05 ด้วยความเกี่ยวข้องของเป้าหมาย
TODO (Chenglong): สำรวจกลยุทธ์การเลือกคุณลักษณะอื่น ๆ เช่นการเลือกคุณสมบัติการส่งต่อ (FFS) และการเลือกคุณลักษณะย้อนหลังโลภ (BFS)
ในการแก้ปัญหาของเรา task เป็นวัตถุประกอบของ feature เฉพาะ (เช่น basic_nonlinear_201604210409 ) และ learner เฉพาะ ( XGBoostRegressor จาก xgboost) คำจำกัดความสำหรับ task feature และ learner อยู่ใน task.py
ใช้คำสั่งต่อไปนี้เช่น
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
task basic_nonlinear_201604210409 และ learner feature reg_xgb_treetask ได้รับการปรับให้เหมาะสมด้วย HyperOpt สำหรับ 100 eveals สำหรับการค้นหาพารามิเตอร์ที่ดีที่สุดสำหรับ learner reg_xgb_treetask ดำเนินการทั้ง CV และ Final Refit CV ในกรณีนี้มีสองวัตถุประสงค์: 1) คู่มือ HyperOpt เพื่อค้นหาพารามิเตอร์ที่ดีที่สุดและ 2) สร้างการทำนายสำหรับการพับ CV แต่ละครั้งเพื่อเพิ่มเติม (ระดับ 2 และ 3)model_param_space.py ในระหว่างการแข่งขันเราได้ทำงานต่าง ๆ (เช่นคุณสมบัติต่าง ๆ และผู้เรียนที่หลากหลาย) เพื่อสร้างห้องสมุดโมเดลระดับ 1 ที่หลากหลาย โปรดดู ./Log/level1_models level1_models สำหรับงานทั้งหมดที่เราได้รวมไว้ในการส่งครั้งสุดท้ายของเรา
หลังจากสร้าง feature basic_nonlinear_201604210409 (ดูขั้นตอนที่ 4 วิธีการสร้างสิ่งนี้) ให้เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างโมเดลเดียวที่ดีที่สุด:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
สิ่งนี้ควรสร้างการส่งด้วย CV RMSE ในท้องถิ่นประมาณ 0.438 ~ 0.439
หลังจากสร้างโมเดลระดับ 1 ที่หลากหลายให้ เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างโมเดลวงดนตรีที่ดีที่สุด:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
สิ่งนี้ควรสร้างการส่งด้วย CV RMSE ในท้องถิ่นประมาณ 0.436
ก่อนที่จะดำเนินการเราควรระบุเส้นทางที่ถูกต้องในไฟล์ config_IgorKostia.py และวางข้อมูลทั้งหมดจากเว็บไซต์การแข่งขันลงในโฟลเดอร์ที่ระบุโดยตัวแปร DATA_DIR ในการทำซ้ำ Ensemble_B จากขั้นตอน IK5 ควรวางชุดคุณสมบัติที่ใช้แล้วลงในโฟลเดอร์ที่ระบุโดยตัวแปร FEATURESETS_DIR โปรดทราบว่าในต่อไปนี้คำสั่งและสคริปต์ทั้งหมดจะถูกดำเนินการและเรียกใช้ในไดเรกทอรี ./Code/Igor&Kostia igor&kostia
เราใช้ Python 2.7.11 บนแพลตฟอร์ม Windows และโมดูลมาพร้อมกับ Anaconda 2.4.0 (64 บิต) รวมถึง:
นอกจากนี้เรายังใช้ไลบรารีและโมดูลต่อไปนี้:
nltk.download() )การวิเคราะห์เชิงพรรณนาและการผสมแบบจำลองขั้นสุดท้ายก็ทำใน Excel 2007 และ Excel 2010
เราทำการประมวลผลข้อความล่วงหน้าก่อนการสร้างคุณสมบัติใด ๆ และบันทึกผลลัพธ์ลงในไฟล์ มันช่วยให้เราบันทึกวันคอมพิวเตอร์ไม่กี่วันเนื่องจากขั้นตอนการประมวลผลล่วงหน้าเดียวกันเป็นสิ่งจำเป็นในการสร้างคุณสมบัติที่แตกต่างกัน
text_processing.pytext_processing_wo_google.py ข้อมูลการแทนที่ที่จำเป็นจะถูกโหลดโดยอัตโนมัติจากไฟล์ homedepot_functions.py และ google_dict.py
เราจำเป็นต้องเรียกใช้ไฟล์ต่อไปนี้:
feature_extraction1.pygrams_and_terms_features.pydld_features.pyword2vec.pyในการสร้างคุณสมบัติโดยไม่ต้องใช้พจนานุกรม Google เราต้องเรียกใช้:
feature_extraction1_wo_google.pyword2vec_without_google_dict.pyด้วยเหตุนี้เราจะมีไฟล์ CSV สองสามไฟล์พร้อมคุณสมบัติที่จำเป็นสำหรับการสร้างแบบจำลอง
generate_feature_importances.py ส่วนหนึ่งของวงดนตรีวงดนตรี Ensemble_A ถูกสร้างขึ้นจากรหัสต่อไปนี้:
generate_models.pygenerate_model_wo_google.pygenerate_ensemble_output_from_models.py ในการรับส่วนอื่น ๆ Ensemble_B เราจำเป็นต้องเรียกใช้ไฟล์เหล่านี้:
ensemble_script_imitation_version.py (มันเพิ่งทำซ้ำการเลือกคุณสมบัติแบบสุ่มที่สร้างขึ้นจาก ensemble_script_random_version.py คุณไม่จำเป็นต้องเรียกใช้ ensemble_script_random_version.py อีกครั้ง)model_selecting.py ทั้งสองส่วนนี้สามารถสร้างได้ในแบบคู่ขนาน การส่งครั้งสุดท้ายของเราจาก Igor & Kostia นั้นถูกผลิตใน Excel เป็น: Output = 0.75 Ensemble_A + 0.25 Ensemble_B
ดังนั้นเราจึงมีสองวงที่เตรียมโดยใช้วิธีการที่แตกต่างกัน เราสังเกตว่าวงดนตรีของเรามีพฤติกรรมแตกต่างกันในส่วนต่าง ๆ ของชุดข้อมูล ( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473 เนื่องจากเราสังเกตเห็นรูปแบบปกติ สมมติว่าในบางส่วนหนึ่งในแบบจำลองจะทำงานได้แย่กว่าในที่สาธารณะมากกว่าในที่สาธารณะ
การส่งครั้งสุดท้ายสองครั้งของเรานั้นผลิตใน Excel ด้วยน้ำหนักจากตารางด้านล่าง (น้ำหนักสำหรับชิ้นส่วนของ Chenglong และ Igor & Kostia เพิ่มขึ้นถึง 1) การส่งทั้งสองนี้ทำคะแนน 0.43271 เดียวกันบนกระดานผู้นำส่วนตัว
น้ำหนักเฉิงตงสำหรับ part1 และ part2 | น้ำหนักเฉิงตงสำหรับ part3 | LB สาธารณะ RMSE | LB ส่วนตัว RMSE | |
|---|---|---|---|---|
| ส่ง 1 | 0.75 | 0.8 | 0.43443 | 0.43271 |
| ส่ง 2 | 0.6 | 0.3 | 0.43433 | 0.43271 |


