kaggle HomeDepot
1.0.0
Solusi Turing Test untuk Kompetisi Relevansi Pencarian Produk Home Depot di Kaggle
| Penyerahan | CV RMSE | PUBLIK LB RMSE | Private LB RMSE | Posisi |
|---|---|---|---|---|
| Model tunggal yang disederhanakan dari Igor dan Kostia (10 fitur) | 0.44792 | 0.45072 | 0.44949 | 31 |
| Model tunggal terbaik dari Igor dan Kostia | 0.43787 | 0.44017 | 0.43895 | 11 |
| Model tunggal terbaik dari Chenglong | 0.43832 | 0.43996 | 0.43811 | 9 |
| Model Ensemble Terbaik dari Igor dan Kostia | - | 0.43819 | 0.43704 | 8 |
| Model Ensemble Terbaik dari Chenglong | 0.43550 | 0.43555 | 0.43368 | 6 |
| Model Ensemble Akhir Terbaik | - | 0.43433 | 0.43271 | 3 |
Lihat ./Doc/Kaggle_HomeDepot_Turing_Test.pdf untuk dokumentasi.
Sebelum melanjutkan, seseorang harus menempatkan semua data dari situs web kompetisi ke folder ./Data .
Perhatikan bahwa di berikut ini, semua perintah dan skrip dieksekusi dan dijalankan di direktori ./Code/Chenglong .
Kami menggunakan Python 3.5.1 dan modul hadir dengan Anaconda 2.4.1 (64-bit). Selain itu, kami juga menggunakan pustaka dan modul berikut:
Kami menggunakan paket berikut yang diinstal melalui install.packages() :
Kami menggunakan paket pihak ketiga berikut:
Kami menggunakan model Word2VEC pra-terlatih yang tercantum dalam repo GitHub ini. Secara spesifik:
Kami menggunakan Glove-Gensim untuk mengonversi vektor sarung tangan menjadi format Word2VEC untuk penggunaan yang mudah dengan gensim. Setelah itu, masukkan semua model di direktori yang sesuai (lihat config.py untuk detail).
Kami juga menggunakan data eksternal berikut:
./Data/dict/color_data.py dalam repo ini.google_spelling_checker_dict.py dalam repo ini../Data/dict/word_replacer.csv dalam repo ini.nltk.download() , khususnya: stopwords.zip , wordnet.zip dan maxent_treebank_pos_tagger.zip . Untuk menghasilkan data dan fitur, seseorang harus menjalankan python run_data.py . Meskipun kami telah mencoba yang terbaik untuk menjadikan hal -hal sebagai paralelisme dan seefisien mungkin, bagian ini mungkin masih membutuhkan 1 ~ 2 hari untuk menyelesaikan, tergantung pada kekuatan komputasi. Jadi bersabarlah :)
Perhatikan bahwa berbagai pemrosesan teks berguna untuk memperkenalkan keragaman ke dalam ansambel. Faktanya, satu set fitur (yaitu, basic20160313 ) dari solusi akhir kami dihasilkan sebelum posting Typos yang memperbaiki, yaitu, tidak menggunakan kamus koreksi ejaan Google. Versi fitur semacam itu dapat dihasilkan dengan mematikan flag GOOGLE_CORRECTING_QUERY di config.py .
Setelah tim bergabung dengan Igor & Kostia, kami telah membangun kembali semuanya dari awal, dan sebagian besar model kami menggunakan subset berbeda dari fitur Igor & Kostia. Untuk alasan ini, Anda juga harus menghasilkan fitur mereka. Karena fitur Igor & Kostia berada dalam format .csv DataFrame, kami menyediakan konverter turing_test_converter.py untuk mengonversinya ke format yang kami gunakan, yaitu, .pkl .
Pada Langkah 3, kami telah menghasilkan beberapa ribu fitur. Namun, hanya sebagian dari mereka yang akan digunakan untuk membangun model kami. Misalnya, kami tidak memerlukan fitur -fitur yang memiliki kekuatan prediktif yang sangat sedikit (misalnya, memiliki korelasi yang sangat kecil dengan relevansi target.) Dengan demikian kami perlu melakukan beberapa pemilihan fitur.
Dalam solusi kami, pemilihan fitur diaktifkan melalui dua langkah berturut -turut berikut.
Pendekatan ini diimplementasikan sebagai get_feature_conf_*.py . Gagasan umum adalah untuk memasukkan atau mengecualikan fitur spesifik melalui operasi regex dari nama fitur. Misalnya,
MANDATORY_FEATS , meskipun ada korelasinya dengan targetCOMMENT_OUT_FEATS , meskipun ada korelasinya dengan target ( MANDATORY_FEATS memiliki prioritas yang lebih tinggi daripada COMMENT_OUT_FEATS .) Output dari ini adalah file conf fitur. Misalnya, setelah menjalankan perintah berikut:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
Kami akan mendapatkan fitur baru conf ./conf/feature_conf_nonlinear_201605010058.py yang berisi kamus fitur yang menentukan fitur yang akan dimasukkan dalam langkah berikut.
Seseorang dapat bermain -main dengan MANDATORY_FEATS dan COMMENT_OUT_FEATS untuk menghasilkan subset fitur yang berbeda. Kami telah memasukkan dalam ./conf beberapa fitur lainnya dari kiriman akhir kami. Di antara mereka, feature_conf_nonlinear_201604210409.py digunakan untuk membangun model tunggal terbaik.
Dengan conf fitur yang dihasilkan di atas, seseorang dapat menggabungkan semua fitur menjadi matriks fitur melalui perintah berikut:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
-t 0.05 di atas digunakan untuk memungkinkan pemilihan fitur basis korelasi. Dalam hal ini, itu berarti: Jatuhkan fitur apa pun yang memiliki coef korelasi lebih rendah dari 0.05 dengan relevansi target.
TODO (Chenglong): Jelajahi strategi pemilihan fitur lainnya, misalnya, seleksi fitur maju yang serakah (FFS) dan seleksi fitur mundur serakah (BFS).
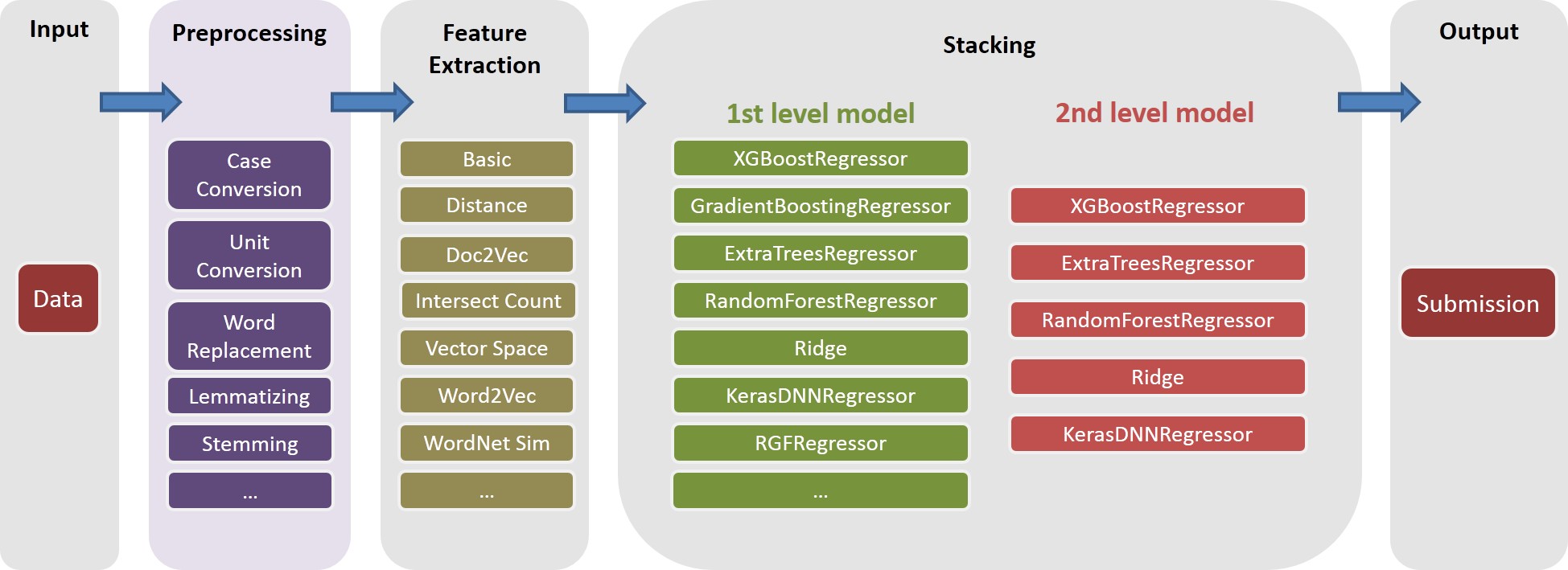
Dalam solusi kami, task adalah komposit objek dari feature tertentu (misalnya, basic_nonlinear_201604210409 ) dan learner tertentu ( XGBoostRegressor dari XGBoost). Definisi untuk task , feature , dan learner ada di task.py
Ambil perintah berikut misalnya.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
task dengan feature basic_nonlinear_201604210409 dan learner reg_xgb_tree .task ini dioptimalkan dengan hyperopt untuk 100 eval untuk mencari parameter terbaik untuk learner reg_xgb_tree .task melakukan reparasi CV dan final. CV dalam hal ini memiliki dua tujuan: 1) Panduan Hyperopt untuk menemukan parameter terbaik, dan 2) menghasilkan prediksi untuk setiap lipatan CV untuk penumpukan lebih lanjut (level 2 dan 3).model_param_space.py . Selama kompetisi, kami telah menjalankan berbagai tugas (yaitu, berbagai fitur dan berbagai pelajar) untuk menghasilkan perpustakaan model tingkat 1 yang beragam. Silakan lihat ./Log/level1_models untuk semua tugas yang telah kami sertakan dalam pengiriman akhir kami.
Setelah menghasilkan feature basic_nonlinear_201604210409 (lihat Langkah 4 Cara Menghasilkan Ini), jalankan perintah berikut untuk menghasilkan model tunggal terbaik:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
Ini harus menghasilkan pengiriman dengan CV RMSE lokal sekitar 0,438 ~ 0,439.
Setelah membangun beberapa model level 1 yang beragam , jalankan perintah berikut untuk menghasilkan model ensemble terbaik:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
Ini harus menghasilkan pengiriman dengan CV RMSE lokal sekitar 0,436.
Sebelum melanjutkan, seseorang harus menentukan jalur yang benar di file config_IgorKostia.py dan menempatkan semua data dari situs web kompetisi ke dalam folder yang ditentukan oleh variabel DATA_DIR . Untuk mereproduksi Ensemble_B kami dari langkah IK5, seseorang harus menempatkan set fitur yang digunakan ke dalam folder yang ditentukan oleh variabel FEATURESETS_DIR . Perhatikan bahwa di berikut ini, semua perintah dan skrip dieksekusi dan dijalankan di direktori ./Code/Igor&Kostia .
Kami menggunakan Python 2.7.11 pada platform Windows dan modul hadir dengan Anaconda 2.4.0 (64-bit), termasuk:
Selain itu, kami juga menggunakan pustaka dan modul berikut:
nltk.download() )Beberapa analisis deskriptif dan pencampuran model akhir juga dilakukan di Excel 2007 dan Excel 2010.
Kami melakukan semua preprocessing teks sebelum pembuatan fitur apa pun dan menyimpan hasilnya ke file. Ini membantu kami menghemat beberapa hari komputasi karena langkah -langkah preprocessing yang sama diperlukan untuk menghasilkan fitur yang berbeda.
text_processing.py .text_processing_wo_google.py . Data penggantian yang diperlukan dimuat secara otomatis dari file homedepot_functions.py dan google_dict.py .
Kita perlu menjalankan file berikut:
feature_extraction1.py .grams_and_terms_features.py .dld_features.py .word2vec.py .Untuk menghasilkan fitur tanpa menggunakan Google Dictionary, kita juga perlu menjalankan:
feature_extraction1_wo_google.py .word2vec_without_google_dict.py .Akibatnya, kami akan memiliki beberapa file CSV dengan fitur yang diperlukan untuk pembuatan model.
generate_feature_importances.py . Salah satu bagian dari Ensemble Ensemble_A dihasilkan dari kode berikut:
generate_models.py .generate_model_wo_google.py .generate_ensemble_output_from_models.py . Untuk mendapatkan bagian lain Ensemble_B , kita perlu menjalankan file -file ini:
ensemble_script_imitation_version.py (itu hanya mereproduksi pemilihan fitur acak yang dihasilkan dari ensemble_script_random_version.py . Anda tidak perlu menjalankan ensemble_script_random_version.py lagi).model_selecting.py . Kedua bagian ini dapat dihasilkan secara paralel. Pengajuan terakhir kami dari Igor & Kostia kemudian diusir dalam Excel sebagai: Output = 0,75 Ensemble_A + 0,25 Ensemble_B
Jadi, kami memiliki dua ansambel yang disiapkan menggunakan metodologi yang berbeda. Kami mengamati bahwa ansambel kami berperilaku berbeda di berbagai bagian dataset ( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473 Karena kami mengamati pola -pola reguler dalam beberapa bagian. bahwa di beberapa bagian salah satu model akan berperilaku jauh lebih buruk secara pribadi daripada di depan umum.
Dua pengiriman terakhir kami diproduksi di Excel dengan bobot dari tabel di bawah ini (bobot untuk bagian Chenglong dan Igor & Kostia bertambah hingga 1). Kedua pengiriman ini mencetak 0.43271 yang sama di papan peringkat pribadi.
Berat Chenglong untuk part1 dan part2 | Berat chenglong untuk part3 | PUBLIK LB RMSE | Private LB RMSE | |
|---|---|---|---|---|
| Pengajuan 1 | 0,75 | 0.8 | 0.43443 | 0.43271 |
| Pengajuan 2 | 0.6 | 0.3 | 0.43433 | 0.43271 |


