kaggle HomeDepot
1.0.0
Kaggle에서 홈 디포 제품 검색 관련 경쟁을위한 Turing Test의 솔루션
| 제출 | CV RMSE | 공개 lb rmse | 개인 LB RMSE | 위치 |
|---|---|---|---|---|
| Igor 및 Kostia의 단순화 된 단일 모델 (10 기능) | 0.44792 | 0.45072 | 0.44949 | 31 |
| Igor와 Kostia의 최고의 단일 모델 | 0.43787 | 0.44017 | 0.43895 | 11 |
| Chenglong의 최고의 단일 모델 | 0.43832 | 0.43996 | 0.43811 | 9 |
| Igor와 Kostia의 최고의 앙상블 모델 | - | 0.43819 | 0.43704 | 8 |
| Chenglong의 최고의 앙상블 모델 | 0.43550 | 0.43555 | 0.43368 | 6 |
| 최고의 최종 앙상블 모델 | - | 0.43433 | 0.43271 | 3 |
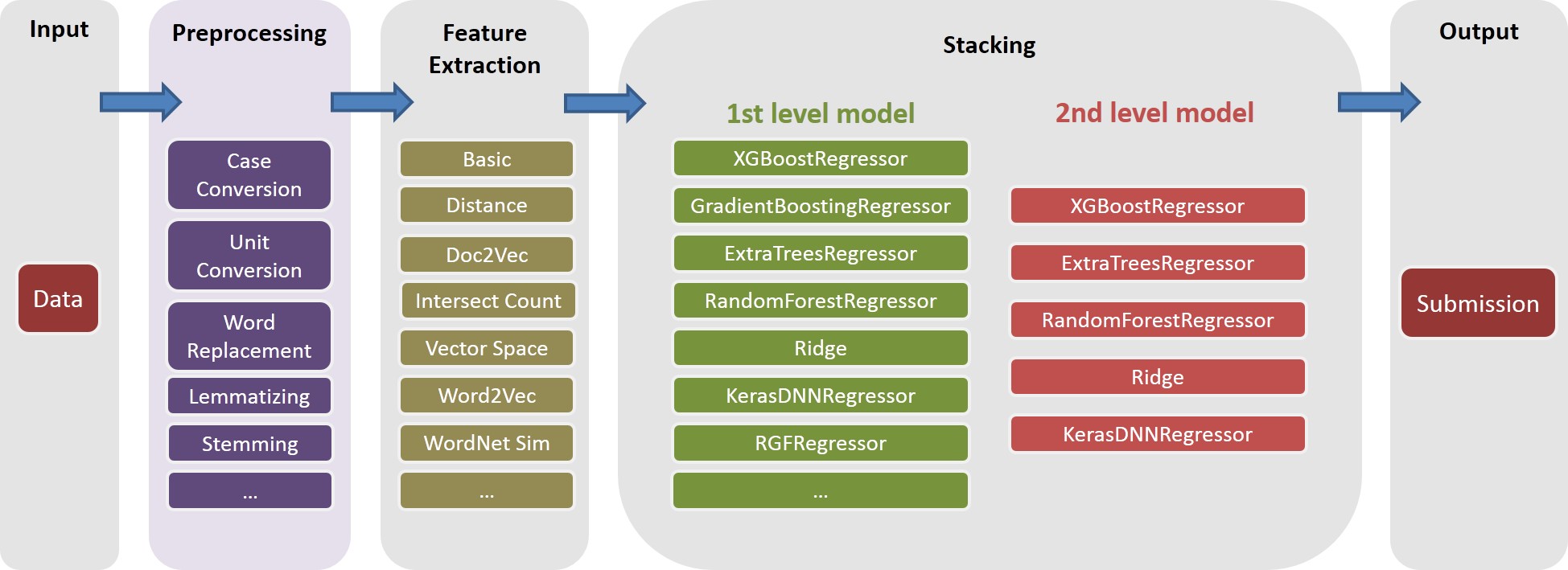
문서는 ./Doc/Kaggle_HomeDepot_Turing_Test.pdf 참조하십시오.
진행하기 전에 경쟁 웹 사이트의 모든 데이터를 폴더 ./Data 에 배치해야합니다.
다음에서 모든 명령과 스크립트는 디렉토리 ./Code/Chenglong 에서 실행되고 실행됩니다.
Python 3.5.1을 사용했으며 모듈에는 Anaconda 2.4.1 (64 비트)이 있습니다. 또한 다음 라이브러리와 모듈도 사용했습니다.
install.packages() 를 통해 설치된 다음 패키지를 사용했습니다.
우리는 다음의 타사 패키지를 사용했습니다.
우리는이 Github Repo에 나열된 미리 훈련 된 Word2Vec 모델을 사용했습니다. 구체적으로 :
Gensim을 사용하여 쉽게 사용하기 위해 장갑 ensim을 사용하여 글러브 벡터를 Word2Vec 형식으로 변환했습니다. 그런 다음 모든 모델을 해당 디렉토리에 넣으십시오 (세부 사항은 config.py 참조).
우리는 또한 다음 외부 데이터를 사용했습니다.
./Data/dict/color_data.py 의 색상 데이터.google_spelling_checker_dict.py 의 Google 철자 수정 사전이 리포지토어../Data/dict/word_replacer.csv .nltk.download() 사용하여 다운로드했습니다 : stopwords.zip , wordnet.zip 및 maxent_treebank_pos_tagger.zip . 데이터 및 기능을 생성하려면 python run_data.py 실행해야합니다. 우리는 가능한 한 평행하고 효율적으로 물건을 만들기 위해 최선을 다했지만이 부분은 계산 능력에 따라 1 ~ 2 일이 걸릴 수 있습니다. 그러니 참을성 :)
다양한 텍스트 처리는 앙상블에 다양성을 도입하는 데 유용합니다. 사실, 최종 솔루션의 한 기능 세트 (즉, basic20160313 )는 Google 철자 수정 사전을 사용하지 않고 오타 수정 게시물 이전에 생성됩니다. 이러한 버전의 기능은 config.py 에서 GOOGLE_CORRECTING_QUERY 플래그를 끄면 생성 할 수 있습니다.
팀이 Igor & Kostia와 합병 한 후, 우리는 처음부터 모든 것을 재건했으며 대부분의 모델은 Igor & Kostia의 기능의 다양한 하위 집합을 사용했습니다. 이러한 이유로 기능을 생성해야합니다. Igor & Kostia의 기능은 .csv 데이터 프레임 형식이므로 컨버터 turing_test_converter.py 제공하여 사용하는 형식 (예 : .pkl )으로 변환합니다.
3 단계에서는 수천 가지 기능을 생성했습니다. 그러나 그들 중 일부만이 모델을 구축하는 데 사용됩니다. 예를 들어, 우리는 예측력이 거의없는 기능이 필요하지 않습니다 (예 : 대상 관련성과 매우 작은 상관 관계가 있습니다) 따라서 기능 선택을 수행해야합니다.
솔루션에서 기능 선택은 다음 두 가지 연속 단계를 통해 활성화됩니다.
이 방법은 get_feature_conf_*.py 로 구현됩니다. 일반적인 아이디어는 기능 이름의 regex 작업을 통해 특정 기능을 포함 시키거나 배제하는 것입니다. 예를 들어,
MANDATORY_FEATS 변수를 통해 포함하려는 기능을 지정할 수 있습니다.COMMENT_OUT_FEATS 변수를 통해 제외 하려는 기능을 지정할 수 있습니다 ( MANDATORY_FEATS COMMENT_OUT_FEATS 보다 우선 순위가 높습니다.) 이것의 출력은 기능 conf 파일입니다. 예를 들어 다음 명령을 실행 한 후
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
우리는 다음 단계에 포함될 기능을 지정하는 기능 사전이 포함 된 새로운 기능 conf ./conf/feature_conf_nonlinear_201605010058.py 를 얻을 것입니다.
MANDATORY_FEATS 및 COMMENT_OUT_FEATS 와 함께 플레이하여 다른 기능 하위 집합을 생성 할 수 있습니다. 우리는 최종 제출물에서 ./conf 에 다른 몇 가지 다른 기능을 포함 시켰습니다. 그중에서도 feature_conf_nonlinear_201604210409.py 최고의 단일 모델을 빌드하는 데 사용됩니다.
위의 생성 된 기능 conf를 사용하면 다음 명령을 통해 모든 기능을 기능 행렬로 결합 할 수 있습니다.
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
위의 -t 0.05 상관 관계 기반 기능 선택을 가능하게하는 데 사용됩니다. 이 경우 : 대상 관련성으로 0.05 보다 낮은 상관 계수가있는 모든 기능을 떨어 뜨립니다.
Todo (Chenglong) : 기타 기능 선택 전략 (예 : Greedy Forward Feature Selection) 및 Greedy Backward Feature Selection (BFS)을 탐색하십시오.
우리의 솔루션에서 task 특정 feature (예 : basic_nonlinear_201604210409 )과 특정 learner (XGBOOST의 XGBoostRegressor )의 객체 복합재입니다. task , feature 및 learner 대한 정의는 task.py 에 있습니다.
예를 들어 다음 명령을 사용하십시오.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
feature basic_nonlinear_201604210409 및 learner reg_xgb_tree 기능으로 task 실행합니다.task learner reg_xgb_tree 위한 최상의 매개 변수를 검색하기 위해 100 EVAL에 대한 HyperOpt로 최적화됩니다.task CV와 최종 리피트를 모두 수행합니다. 이 경우 CV는 다음과 같은 두 가지 목적을 가지고 있습니다. 1) 최상의 매개 변수를 찾기위한 하이퍼 로트 가이드 및 2) 추가 (2 차 및 3 레벨) 스태킹을 위해 각 CV 폴드에 대한 예측을 생성합니다.model_param_space.py 참조하십시오. 경쟁 기간 동안, 우리는 다양한 작업 (예 : 다양한 기능 및 다양한 학습자)을 운영하여 다양한 1 레벨 모델 라이브러리를 생성했습니다. 최종 제출에 포함 된 모든 작업은 ./Log/level1_models 참조하십시오.
feature 생성 한 후 basic_nonlinear_201604210409 (4 단계를 생성하는 방법 참조) 다음 명령을 실행하여 최고의 단일 모델을 생성하십시오.
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
이는 약 0.438 ~ 0.439 정도의 지역 CV RMSE와 제출을 생성해야합니다.
다양한 1 레벨 모델을 구축 한 후 다음 명령을 실행하여 최고의 앙상블 모델을 생성하십시오.
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
이는 약 0.436의 지역 CV RMSE와 제출물을 생성해야합니다.
진행하기 전에 파일 config_IgorKostia.py 의 올바른 경로를 지정하고 경쟁 웹 사이트의 모든 데이터를 Variable DATA_DIR 로 지정된 폴더에 배치해야합니다. IK5 단계에서 Ensemble_B 재현하려면 사용 된 기능 세트를 변수 FEATURESETS_DIR 로 지정된 폴더에 배치해야합니다. 다음에서 모든 명령과 스크립트는 디렉토리 ./Code/Igor&Kostia 에서 실행되고 실행됩니다.
Windows 플랫폼에서 Python 2.7.11을 사용했으며 모듈은 다음을 포함하여 Anaconda 2.4.0 (64 비트)과 함께 제공됩니다.
또한 다음 라이브러리와 모듈도 사용했습니다.
nltk.download() 명령 사용)일부 설명 분석 및 최종 모델 블렌딩도 Excel 2007 및 Excel 2010에서 수행되었습니다.
기능 생성 전에 모든 텍스트 전처리를 수행하고 결과를 파일에 저장합니다. 다른 기능을 생성하기 위해 동일한 전처리 단계가 필요하기 때문에 몇 일 동안 컴퓨팅 일을 절약 할 수있었습니다.
text_processing.py 실행합니다.text_processing_wo_google.py 실행하십시오. 필요한 대체 데이터는 파일 homedepot_functions.py 및 google_dict.py 에서 자동으로로드됩니다.
결과적으로 다음 파일을 실행해야합니다.
feature_extraction1.py .grams_and_terms_features.py .dld_features.py .word2vec.py .Google 사전을 사용하지 않고 기능을 생성하려면 다음을 수행해야합니다.
feature_extraction1_wo_google.py .word2vec_without_google_dict.py .결과적으로 모델 구축에 필요한 기능이 포함 된 몇 가지 CSV 파일이 있습니다.
generate_feature_importances.py 실행하십시오. Ensemble Ensemble_A 의 한 부분은 다음 코드에서 생성됩니다.
generate_models.py .generate_model_wo_google.py .generate_ensemble_output_from_models.py . 다른 부분을 얻으려면 Ensemble_B 얻으려면 다음이 파일을 실행해야합니다.
ensemble_script_imitation_version.py ( ensemble_script_random_version.py 에서 생성 된 랜덤 기능의 선택 만 재현합니다. ensemble_script_random_version.py 다시 실행할 필요가 없습니다).model_selecting.py . 이 두 부분은 병렬로 생성 될 수 있습니다. Igor & Kostia로부터의 마지막 제출은 다음과 같이 Excel에 뿌려졌다 : Output = 0.75 Ensemble_A + 0.25 Ensemble_B
그래서 우리는 다른 방법론을 사용하여 준비된 두 가지 앙상블이있었습니다. 우리는 우리의 앙상블이 데이터 세트의 다른 부분에서 다르게 행동한다는 것을 관찰했습니다 ( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473 데이터에서 규칙적인 패턴을 관찰했기 때문에, 우리는 일부 부분을 막을 수 있다고 생각했습니다. 일부 부분에서는 모델 중 하나가 공공 장소보다 비공개로 훨씬 더 나빠질 것이라고 가정합니다.
우리의 두 번의 마지막 제출물은 아래 표의 가중치와 함께 Excel에서 생성되었습니다 (Chenglong과 Igor & Kostia의 부품의 중량은 1까지 추가). 이 두 제출물 모두 개인 리더 보드에서 동일한 0.43271 기록했습니다.
part1 및 part2 에 대한 체중 청정 | part3 의 중량 청소 | 공개 lb rmse | 개인 LB RMSE | |
|---|---|---|---|---|
| 제출 1 | 0.75 | 0.8 | 0.43443 | 0.43271 |
| 제출 2 | 0.6 | 0.3 | 0.43433 | 0.43271 |


