kaggle HomeDepot
1.0.0
图灵测试的Home Depot产品搜索相关性竞赛的解决方案Kaggle
| 提交 | CV RMSE | 公共LB RMSE | 私人LB RMSE | 位置 |
|---|---|---|---|---|
| 来自Igor和Kostia的简化单模型(10个功能) | 0.44792 | 0.45072 | 0.44949 | 31 |
| 来自Igor和Kostia的最佳单个模型 | 0.43787 | 0.44017 | 0.43895 | 11 |
| 成山的最佳单型 | 0.43832 | 0.43996 | 0.43811 | 9 |
| 来自Igor和Kostia的最佳合奏模型 | - | 0.43819 | 0.43704 | 8 |
| 成龙的最佳合奏模型 | 0.43550 | 0.43555 | 0.43368 | 6 |
| 最佳最终合奏模型 | - | 0.43433 | 0.43271 | 3 |
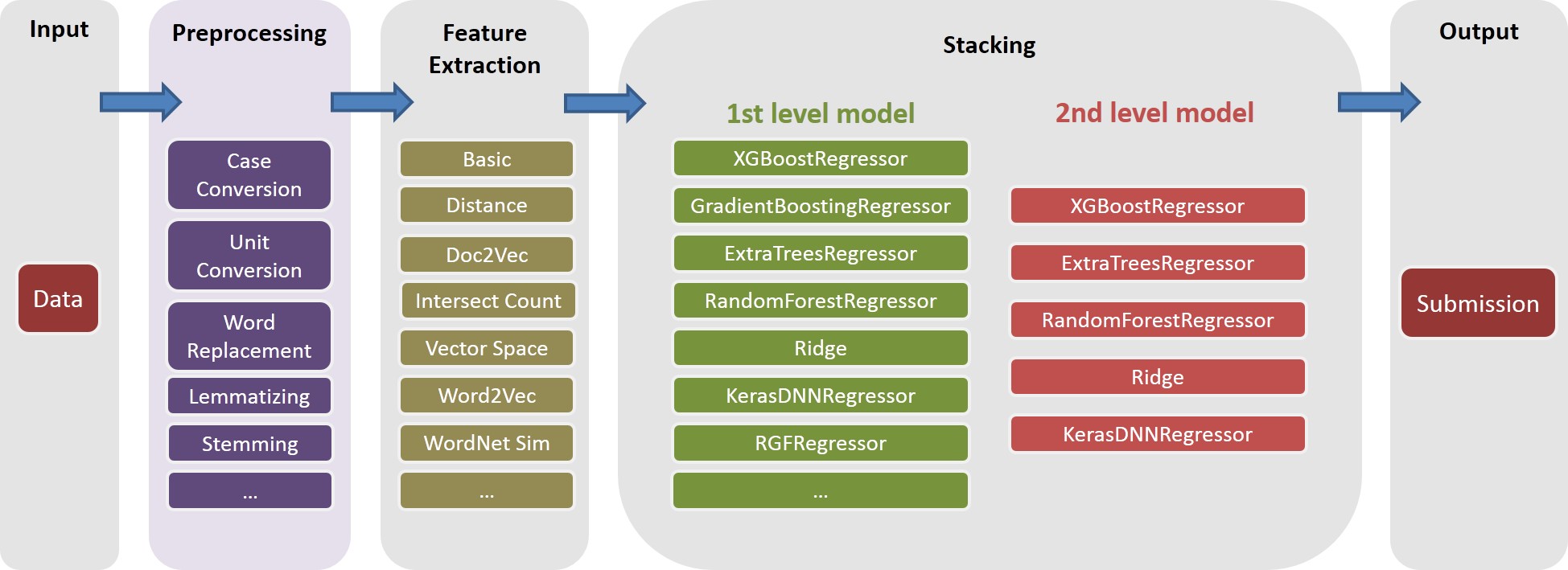
有关文档,请参见./Doc/Kaggle_HomeDepot_Turing_Test.pdf 。
在继续之前,应该将竞争网站的所有数据放入文件夹中./Data 。
请注意,在以下内容中,所有命令和脚本均已执行并在目录中执行并运行./Code/Chenglong 。
我们使用Python 3.5.1,模块带有Anaconda 2.4.1(64位)。此外,我们还使用了以下库和模块:
我们使用以下通过install.packages()安装的软件包:
我们使用以下第三部分软件包:
我们使用了此GitHub存储库中列出的预训练Word2VEC模型。具体:
我们使用Glove-Gensim将手套向量转换为Word2Vec格式,以便于Gensim使用。之后,将所有模型放入相应的目录中(有关详细信息,请参见config.py )。
我们还使用了以下外部数据:
./Data/dict/color_data.py color_data.py。google_spelling_checker_dict.py 。./Data/dict/word_replacer.csvnltk.download()下载,特别是: stopwords.zip , wordnet.zip和maxent_treebank_pos_tagger.zip 。 要生成数据和功能,应该运行python run_data.py 。尽管我们尽力使事情尽可能地进行并行性和高效,但根据计算能力,这部分可能仍需要1〜2天才能完成。所以要耐心:)
请注意,各种文本处理对于将多样性引入合奏很有用。实际上,在固定错字帖子(即,不使用Google Spelling校正词典)之前生成了最终解决方案的一个功能集(IE, basic20160313 )。可以通过关闭config.py中的GOOGLE_CORRECTING_QUERY标志来生成此类功能版本。
在与Igor&Kostia合并的团队合并后,我们从头开始重建了所有内容,我们的大多数模型都使用了Igor&Kostia功能的不同子集。因此,您还需要生成其功能。由于igor&kostia的功能以.csv dataframe格式为.csv dataframe,因此我们提供一个转换器turing_test_converter.py将它们转换为我们使用的格式,即.pkl 。
在步骤3中,我们产生了数千个功能。但是,其中只有一部分将用于构建我们的模型。例如,我们不需要那些几乎没有预测能力的功能(例如,与目标相关性具有很小的相关性。)因此,我们需要进行一些功能选择。
在我们的解决方案中,通过以下两个连续步骤启用了功能选择。
此方法被实现为get_feature_conf_*.py 。一般的想法是通过功能名称的regex操作包括或排除特定功能。例如,
MANDATORY_FEATS变量指定他想要包含的功能COMMENT_OUT_FEATS变量排除的功能,尽管它与目标相关( MANDATORY_FEATS优先级高于COMMENT_OUT_FEATS 。)输出是一个功能conf文件。例如,在运行以下命令之后:
python get_feature_conf_nonlinear.py -d 10 -o feature_conf_nonlinear_201605010058.py
我们将获得一个新功能conf ./conf/feature_conf_nonlinear_201605010058.py ,其中包含一个功能词典,指定要在下一步中包含的功能。
一个人可以使用MANDATORY_FEATS和COMMENT_OUT_FEATS来生成不同的功能子集。我们已包含在./conf中的最终提交中的其他一些功能。其中, feature_conf_nonlinear_201604210409.py用于构建最佳单个模型。
使用上述生成的功能conf,可以通过以下命令将所有功能组合到功能矩阵中:
python feature_combiner.py -l 1 -c feature_conf_nonlinear_201604210409 -n basic_nonlinear_201604210409 -t 0.05
上面的-t 0.05用于启用相关基础特征选择。在这种情况下,这意味着:删除与目标相关性低于0.05的相关系数低于0.05的功能。
TODO(Chenglong):探索其他特征选择策略,例如,贪婪的前向特征选择(FFS)和贪婪的向后特征选择(BFS)。
在我们的解决方案中, task是特定feature的对象复合(例如, basic_nonlinear_201604210409 )和特定的learner (XGBoost的XGBoostRegressor )。 task , feature和learner的定义在task.py中。
以以下命令为例。
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree -e 100
feature basic_nonlinear_201604210409和learner reg_xgb_tree运行task 。task用HyperOPT的100 EVALS优化,以搜索learner reg_xgb_tree的最佳参数。task同时执行简历和最终改装。在这种情况下,CV具有两个目的:1)指导HyperOPT找到最佳参数,而2)为每个CV折叠生成预测,以进一步(第二和第三级)堆叠。model_param_space.py 。在比赛中,我们运行了各种任务(即各种功能和各种学习者),以生成一个不同的1级模型库。请参阅./Log/level1_models以了解我们在最终提交中包含的所有任务。
生成feature basic_nonlinear_201604210409 (请参见步骤4如何生成此)后,运行以下命令以生成最佳单个模型:
python task.py -m single -f basic_nonlinear_201604210409 -l reg_xgb_tree_best_single_model -e 1
这应该在0.438〜0.439左右的本地CV RMSE产生提交。
构建了一些不同的第一级模型后,请运行以下命令以生成最佳的合奏模型:
python run_stacking_ridge.py -l 2 -d 0 -t 10 -c 1 -L reg_ensemble -o
这应该在0.436左右生成本地CV RMSE的提交。
在进行继续之前,应在文件config_IgorKostia.py中指定正确的路径,然后将竞争网站中的所有数据放入可变DATA_DIR指定的文件夹中。为了从步骤IK5重现我们的Ensemble_B ,应该将使用的功能集放入由Variabe FEATURESETS_DIR指定的文件夹中。请注意,在以下内容中,所有命令和脚本均已执行并在目录中执行并运行./Code/Igor&Kostia 。
我们在Windows平台上使用了Python 2.7.11,模块带有Anaconda 2.4.0(64位),包括:
此外,我们还使用了以下库和模块:
nltk.download()命令)在Excel 2007和Excel 2010中也进行了一些描述性分析和最终模型混合。
我们在任何功能生成之前对所有文本进行预处理,并将结果保存到文件。它帮助我们节省了几个计算日,因为需要相同的预处理步骤来生成不同的功能。
text_processing.py 。text_processing_wo_google.py 。必要的替换数据将从文件中自动加载homedepot_functions.py和google_dict.py 。
因此,我们需要运行以下文件:
feature_extraction1.py 。grams_and_terms_features.py 。dld_features.py 。word2vec.py 。要生成不使用Google词典的功能,我们还需要运行:
feature_extraction1_wo_google.py 。word2vec_without_google_dict.py 。结果,我们将拥有一些CSV文件,并具有模型构建的必要功能。
generate_feature_importances.py 。 从以下代码生成集合Ensemble_A的一部分:
generate_models.py 。generate_model_wo_google.py 。generate_ensemble_output_from_models.py 。要获得另一部分Ensemble_B ,我们需要运行以下文件:
ensemble_script_imitation_version.py (它只是重现了从ensemble_script_random_version.py生成ensemble_script_random_version.py随机特征的选择。model_selecting.py 。这两个部分可以并行生成。然后,我们从Igor&Kostia提出的最后提交的内容是在Excel中制作的,为: Output = 0.75 Ensemble_A + 0.25 Ensemble_B
因此,我们有两个使用不同方法的合奏。我们观察到,我们的团体在数据集的不同部分的行为有所不同( part1 : id<=163700 , part2 : 163700 < id <= 221473 , part_3 : id > 221473由于我们也观察到数据中的常规模式。由于我们也可以在某些地方进行过多的序列,因此我们认为其中一个尤其是在某些地方进行了序列,所以我们可以在某些地方进行过度的序列。在某些地方,其中一种模型在私人方面的行为会比在公共场合差得多。
我们的两个最终提交内容是在Excel中生产的,下表的重量(Chenglong's和Igor&Kostia的零件的重量总计为1)。这两项提交在私人排行榜上的得分均为0.43271 。
part1和part2的重量成龙 | 部分重量为part3 | 公共LB RMSE | 私人LB RMSE | |
|---|---|---|---|---|
| 提交1 | 0.75 | 0.8 | 0.43443 | 0.43271 |
| 提交2 | 0.6 | 0.3 | 0.43433 | 0.43271 |


