audio2img
1.0.0
該項目旨在微調WAV2Vec2bert音頻編碼器模型,以生成可以代替傳統剪輯文本編碼器的音頻嵌入。通過集成音頻嵌入,我們可以利用音頻數據的獨特屬性來解鎖穩定擴散模型的新可能性。

?擁抱臉的模型| 培訓筆記本
音頻包含大量信息通常未開發的信息,遠遠超出了我們通常想像的信息。隨著潛在擴散模型的興起及其令人印象深刻的生成能力,人們對探索各種調節技術的興趣越來越興趣。最常見的方法涉及使用剪輯(對比性語言圖像預訓練)文本編碼來調節模型。但是,音頻數據提供了豐富而多方面的信息來源,可以顯著增強調節過程。







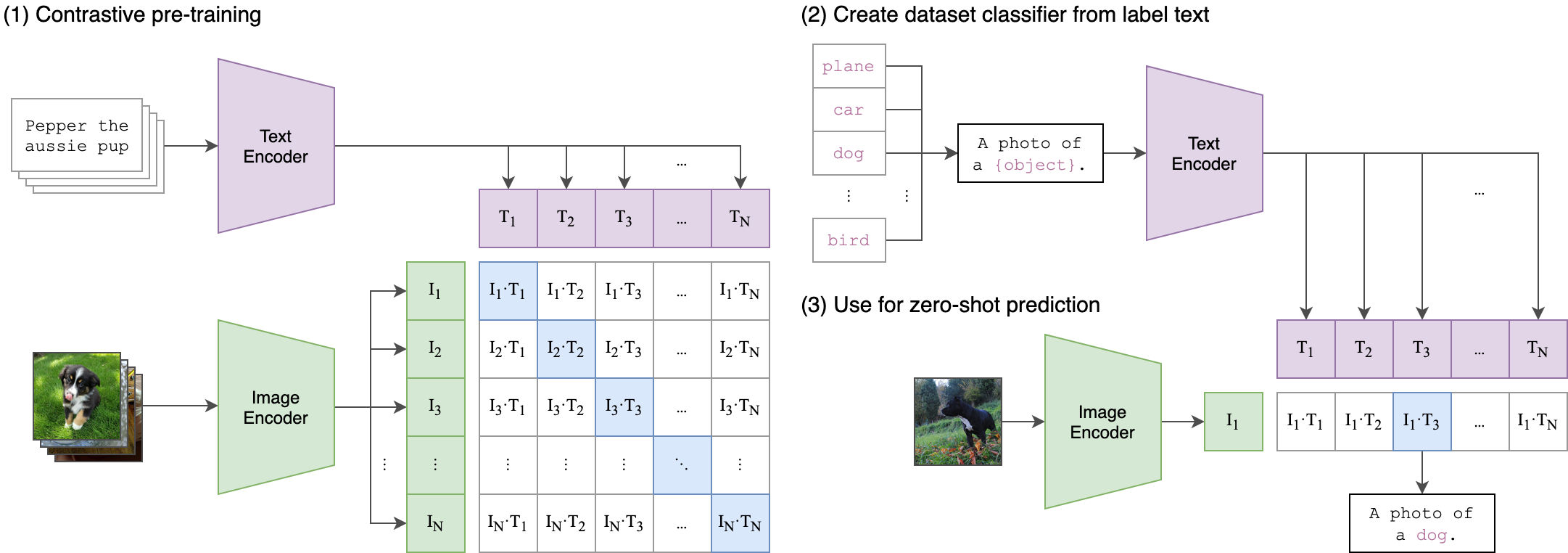
我們的培訓過程背後的核心思想是使用兩流體系結構實現音頻和文本嵌入之間的跨模式對齊。這涉及利用強大的夾克文本模型生成文本嵌入,這些嵌入是我們的Wav2Vec2bert模型產生的音頻嵌入的真實標籤。這是一個詳細的解釋:
兩流體系結構:
- 文本流:我們使用cliptextmodel生成給定文本輸入的文本嵌入。這些嵌入捕獲豐富的語義信息並用作地面真相標籤。
- 音頻流:我們的WAV2VEC2BERT模型使用卷積功能編碼器,然後是變壓器網絡來處理音頻輸入並生成相應的音頻嵌入。
跨模式對齊:
- objectif:訓練的主要目標是將音頻嵌入與共享嵌入空間中的文本嵌入保持一致。這樣可以確保語義上相似的音頻和文本輸入彼此映射。
- 損失函數:我們使用對比度損失實現了這種對齊方式,這鼓勵模型將匹配的音頻文本對的嵌入到靠近的同時,同時推開非匹配對的嵌入。
這類似於原始夾模型的訓練如何對齊圖像文本對。不同之處在於,在OpenAI剪輯模型中,使用[CLS]令牌計算對比損失,而我們將在序列水平上應用對比度損失。
該圖像可以解釋這種損失背後的邏輯:
變形金剛庫用於培訓。 “ Facebook/w2v-bert-2.0”檢查站被加載為初始驗證型號。數據準備,培訓細節和使用的超參數可以在train_me.ipynb筆記本中找到:
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB:批量大小是調節的至關重要的超參數,因為它定義了多少個負樣本傳遞給模型。
pip install -r requirements.txtCKPT 1728或CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )或者
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )只要它們使用相同的夾子編碼器,就可以隨意使用穩定擴散,控製網或類似模型的任何變化。
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.py直接構建並運行Docker圖像:
docker build -t app.py .
docker run -p 7860:7860 app.py 在訓練過程中,觀察到所使用的數據集的註釋不佳,並依賴於通用標籤。利用更多樣化和良好的數據集將提高模型的性能。
此外,由於資源限制,使用了一個小的捲積適配器。使用較大的適配器匹配剪輯最大序列長度確實可以提高模型性能,因為它允許模型捕獲更多信息。
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


