audio2img
1.0.0
该项目旨在微调WAV2Vec2bert音频编码器模型,以生成可以代替传统剪辑文本编码器的音频嵌入。通过集成音频嵌入,我们可以利用音频数据的独特属性来解锁稳定扩散模型的新可能性。

?拥抱脸的模型| 培训笔记本
音频包含大量信息通常未开发的信息,远远超出了我们通常想象的信息。随着潜在扩散模型的兴起及其令人印象深刻的生成能力,人们对探索各种调节技术的兴趣越来越兴趣。最常见的方法涉及使用剪辑(对比性语言图像预训练)文本编码来调节模型。但是,音频数据提供了丰富而多方面的信息来源,可以显着增强调节过程。







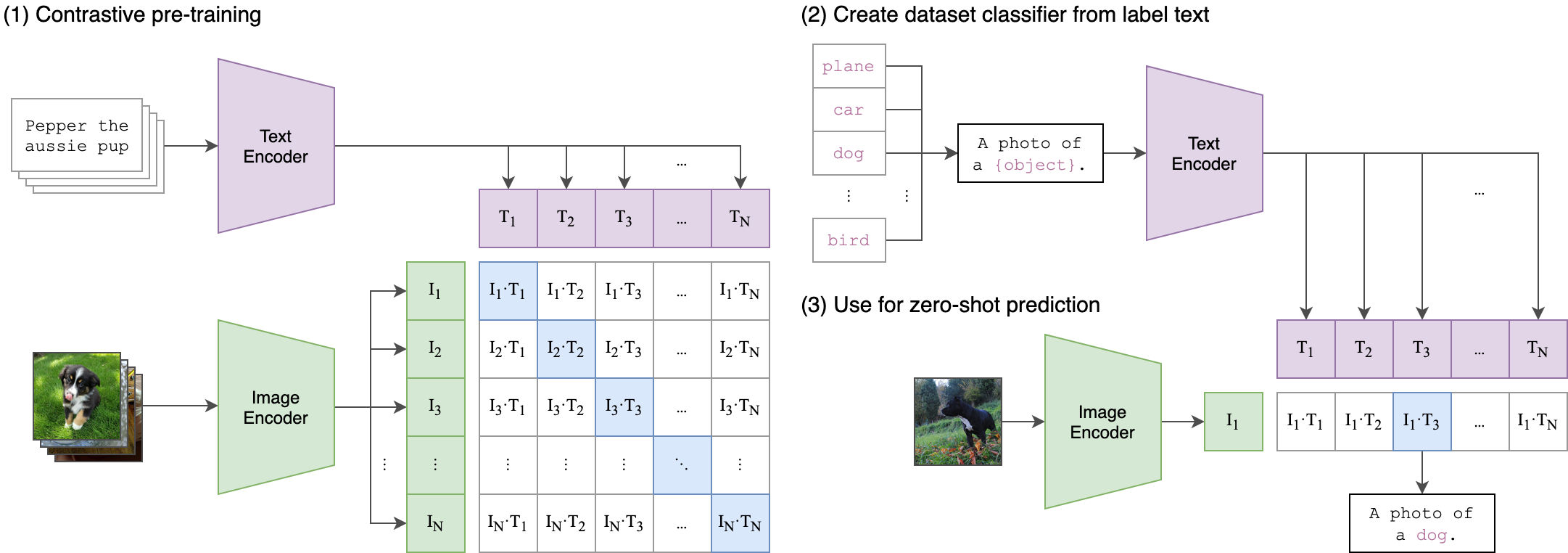
我们的培训过程背后的核心思想是使用两流体系结构实现音频和文本嵌入之间的跨模式对齐。这涉及利用强大的夹克文本模型生成文本嵌入,这些嵌入是我们的Wav2Vec2bert模型产生的音频嵌入的真实标签。这是一个详细的解释:
两流体系结构:
- 文本流:我们使用cliptextmodel生成给定文本输入的文本嵌入。这些嵌入捕获丰富的语义信息并用作地面真相标签。
- 音频流:我们的WAV2VEC2BERT模型使用卷积功能编码器,然后是变压器网络来处理音频输入并生成相应的音频嵌入。
跨模式对齐:
- objectif:训练的主要目标是将音频嵌入与共享嵌入空间中的文本嵌入保持一致。这样可以确保语义上相似的音频和文本输入彼此映射。
- 损失函数:我们使用对比度损失实现了这种对齐方式,这鼓励模型将匹配的音频文本对的嵌入到靠近的同时,同时推开非匹配对的嵌入。
这类似于原始夹模型的训练如何对齐图像文本对。不同之处在于,在OpenAI剪辑模型中,使用[CLS]令牌计算对比损失,而我们将在序列水平上应用对比度损失。
该图像可以解释这种损失背后的逻辑:
变形金刚库用于培训。 “ Facebook/w2v-bert-2.0”检查站被加载为初始验证型号。数据准备,培训细节和使用的超参数可以在train_me.ipynb笔记本中找到:
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB:批量大小是调节的至关重要的超参数,因为它定义了多少个负样本传递给模型。
pip install -r requirements.txtCKPT 1728或CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )或者
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )只要它们使用相同的夹子编码器,就可以随意使用稳定扩散,控制网或类似模型的任何变化。
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.py直接构建并运行Docker图像:
docker build -t app.py .
docker run -p 7860:7860 app.py 在训练过程中,观察到所使用的数据集的注释不佳,并依赖于通用标签。利用更多样化和良好的数据集将提高模型的性能。
此外,由于资源限制,使用了一个小的卷积适配器。使用较大的适配器匹配剪辑最大序列长度确实可以提高模型性能,因为它允许模型捕获更多信息。
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


