audio2img
1.0.0
Ce projet vise à affiner un modèle d'encodeur audio WAV2VEC2BERT pour générer des incorporations audio qui peuvent être utilisées à la place de l'encodeur de texte à clip traditionnel. En intégrant les incorporations audio, nous pouvons tirer parti des propriétés uniques des données audio pour déverrouiller de nouvelles possibilités de modèles de diffusion stables .

? Modèle sur le visage étreint | Cahier de formation
L'audio contient une mine d'informations qui se déroule souvent, s'étendant bien au-delà de ce que nous imaginons généralement. Avec la montée des modèles de diffusion latente et leurs capacités génératives impressionnantes, il y a un intérêt croissant à explorer diverses techniques de conditionnement. L'approche la plus courante consiste à utiliser des encodeurs de texte Clip (pré-formation de langage contrasté) pour conditionner le modèle. Cependant, les données audio offrent une source riche et multiforme d'informations qui peuvent améliorer considérablement le processus de conditionnement.







L'idée principale derrière notre processus de formation est d'atteindre l'alignement intermodal entre les incorporations audio et du texte à l'aide d'une architecture à deux voies . Cela implique de tirer parti du puissant ClipTextModel pour générer des incorporations de texte qui servent de véritables étiquettes pour les incorporations audio produites par notre modèle WAV2VEC2BERT . Voici une explication détaillée:
Architecture à deux voies:
- Stream de texte: nous utilisons le ClipTextModel pour générer des incorporations de texte pour les entrées de texte données. Ces intérêts capturent des informations sémantiques riches et servent les étiquettes de vérité au sol .
- Stream audio: notre modèle WAV2VEC2BERT utilise un codeur de fonctionnalité convolutionnelle suivi d'un réseau de transformateur pour traiter les entrées audio et générer des incorporations audio correspondantes.
Alignement inter-modalité:
- Objectif: Le principal objectif de la formation est d'aligner les incorporations audio avec les incorporations de texte dans un espace d'incorporation partagé . Cela garantit que des entrées audio et de texte sémantiquement similaires sont mappées près les unes des autres.
- Fonction de perte: nous réalisons cet alignement en utilisant une perte contrastive qui encourage le modèle à rapprocher les intégres de paires de texte audio correspondant tout en éloignant des intégres de paires non correspondantes.
Ceci est similaire à la façon dont le modèle de clip d'origine a été formé pour aligner les paires de texte d'image. La différence est que dans le modèle de clip openai , la perte contrastive a été calculée à l'aide du jeton [CLS] , tandis que nous appliquerons une perte contrastive au niveau de la séquence .
Cette image peut expliquer la logique derrière cette perte:
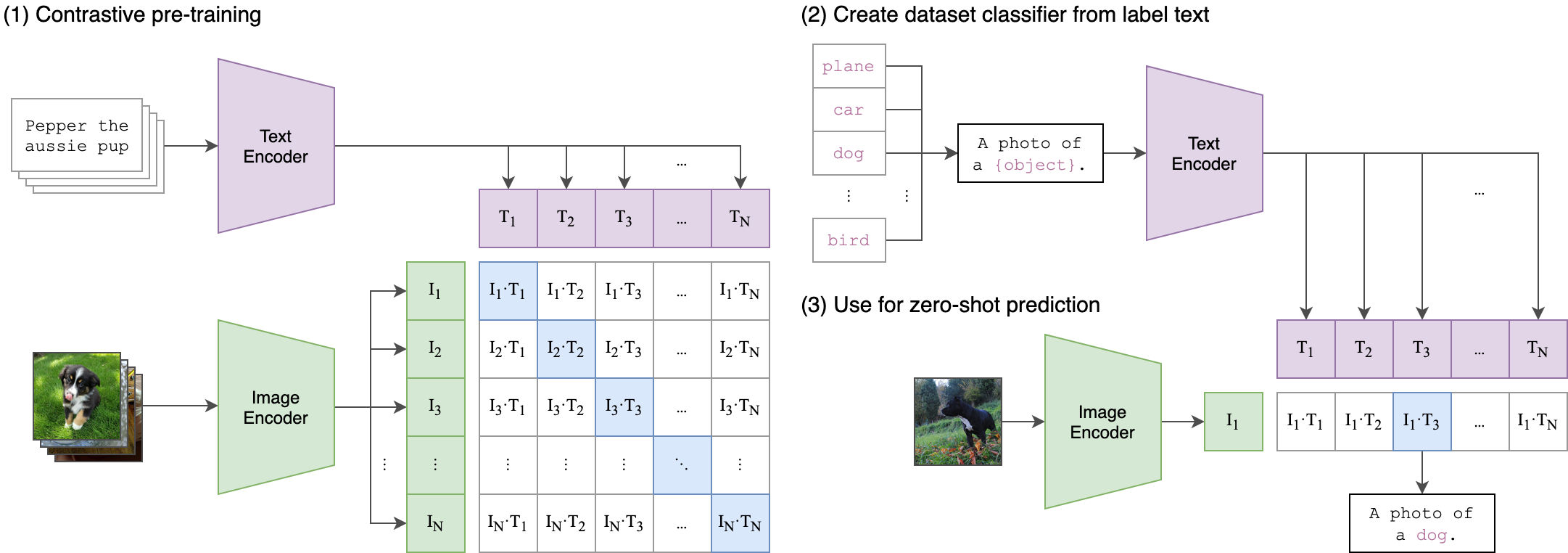
La bibliothèque Transformers a été utilisée pour la formation. Le point de contrôle "Facebook / W2V-BERT-2.0" a été chargé comme modèle initial pré-entraîné . La préparation des données, les détails de la formation et les hyperparamètres utilisés peuvent être trouvés dans le cahier Train_me.ipynb :
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB: La taille du lot est un hyperparamètre crucial à régler, car il définit le nombre d'échantillons négatifs passés au modèle.
pip install -r requirements.txtCKPT 1728 ou CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )ou
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )N'hésitez pas à utiliser toute variation de diffusion stable , de contrôle de contrôle ou de modèles similaires, tant qu'ils utilisent le même codeur de clip .
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyConstruire et exécuter directement l'image docker:
docker build -t app.py .
docker run -p 7860:7860 app.py Pendant l'entraînement, il a été observé que l'ensemble de données utilisé était mal annoté et s'appuyait sur des étiquettes génériques. L'utilisation d'un ensemble de données plus diversifié et plus élaboré améliorera les performances du modèle.
De plus, en raison des limitations des ressources, un petit adaptateur de convolution a été utilisé. L'utilisation d'un adaptateur plus grand pour correspondre à la longueur de séquence maximale du clip peut en effet améliorer les performances du modèle, car elle permet au modèle de capturer plus d'informations.
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformrs/en/model_doc/wav2vec2-bert


