audio2img
1.0.0
このプロジェクトの目的は、 WAV2VEC2BERBERBERBERTオーディオエンコーダーモデルを微調整して、従来のクリップテキストエンコーダの代わりに使用できるオーディオエンゲッジを生成することです。オーディオ埋め込みを統合することにより、オーディオデータの一意のプロパティを活用して、安定した拡散モデルの新しい可能性のロックを解除できます。

?顔を抱きしめるモデル| トレーニングノートブック
オーディオには、頻繁に未開拓の情報が含まれており、私たちが通常想像するものをはるかに超えて延びています。潜在的な拡散モデルの上昇とその印象的な生成能力により、多様な条件付け技術を探索することに関心が高まっています。最も一般的なアプローチは、モデルを条件付けるためにクリップ(コントラスト言語イメージの事前トレーニング)テキストエンコーダを使用することです。ただし、オーディオデータは、条件付けプロセスを大幅に強化できるリッチで多面的で多面的な情報源を提供します。







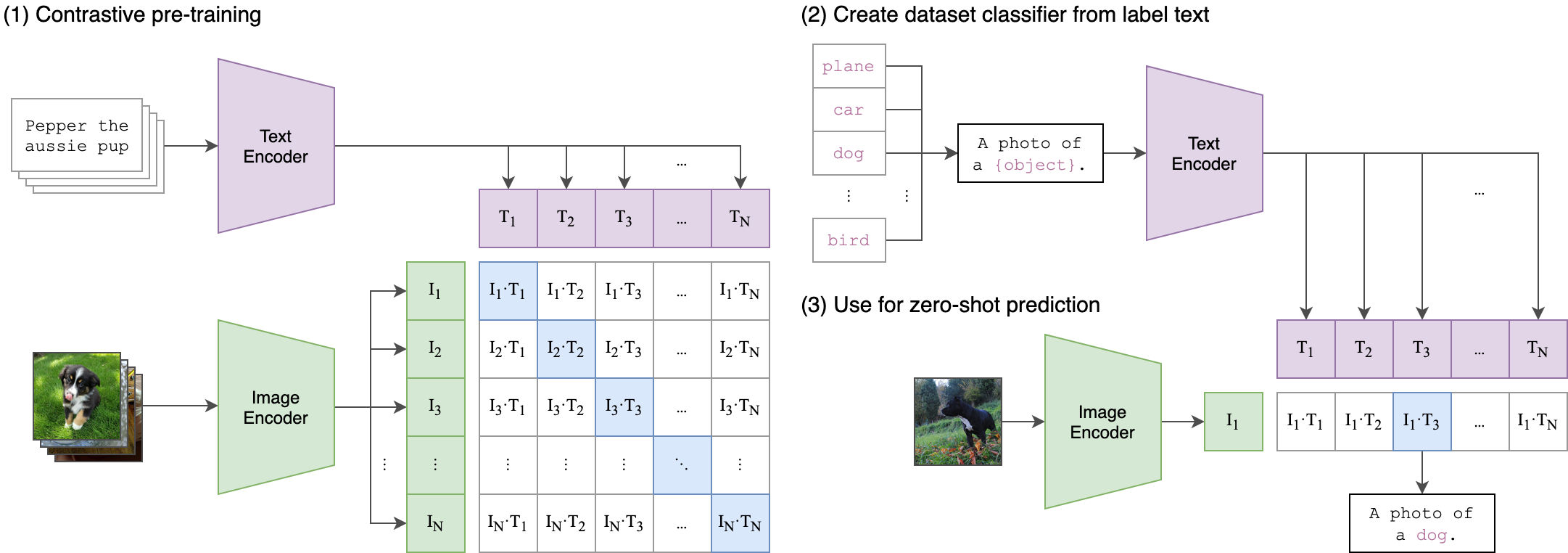
トレーニングプロセスの背後にある核となるアイデアは、2ストリームアーキテクチャを使用して、オーディオとテキストの埋め込みの間のクロスモーダルアラインメントを実現することです。これには、強力なCliptextModelを活用して、 WAV2VEC2BERTモデルによって生成されたオーディオエンミングの真のラベルとして機能するテキスト埋め込みを生成することが含まれます。詳細な説明は次のとおりです。
2ストリームアーキテクチャ:
- テキストストリーム: CliptextModelを使用して、指定されたテキスト入力のテキスト埋め込みを生成します。これらの埋め込みは、豊富なセマンティック情報をキャプチャし、グラウンドトゥルースラベルとして機能します。
- オーディオストリーム: WAV2VEC2BERBERBERBERTモデルは、コンボリューション機能エンコーダーを使用し、その後にトランスネットワークがオーディオ入力を処理し、対応するオーディオエンミングを生成します。
クロスモダリティアライメント:
- 目的:トレーニングの主な目標は、オーディオ埋め込みを共有された埋め込みスペースにテキスト埋め込みに合わせることです。これにより、意味的に類似したオーディオとテキストの入力が互いに近くにマッピングされることが保証されます。
- 損失関数:モデルが一致するオーディオテキストペアの埋め込みを近づけながら、非一致ペアの埋め込みを押し下げることを促すコントラスト損失を使用して、このアラインメントを達成します。
これは、元のクリップモデルが画像テキストペアを整列するようにトレーニングされた方法に似ています。違いは、 OpenAIクリップモデルでは、 [CLS]トークンを使用してコントラスト損失が計算され、シーケンスレベルで対照損失を適用することです。
この画像は、この損失の背後にあるロジックを説明できます。
Transformers Libraryがトレーニングに使用されました。 「Facebook/W2V-Bert-2.0」チェックポイントは、初期の前提型モデルとしてロードされました。データの準備、トレーニングの詳細、および使用されるハイパーパラメーターは、 train_me.ipynbノートブックにあります。
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB:バッチサイズは、モデルに渡される負のサンプルの数を定義するため、チューニングする重要なハイパーパラメーターです。
pip install -r requirements.txtCKPT 1728またはCKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )または
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )同じクリップエンコーダーを使用している限り、安定した拡散、コントロールネット、または同様のモデルのバリエーションを自由に使用してください。
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyDocker画像を直接構築して実行します:
docker build -t app.py .
docker run -p 7860:7860 app.py トレーニング中、使用されたデータセットの注釈が不十分であり、一般的なラベルに依存していることが観察されました。より多様で高く評価されたデータセットを利用すると、モデルのパフォーマンスが向上します。
さらに、リソースの制限により、小さな畳み込みアダプターが使用されました。より大きなアダプターを使用してクリップマックスシーケンスの長さに一致すると、モデルがより多くの情報をキャプチャできるため、モデルのパフォーマンスを実際に改善できます。
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


