audio2img
1.0.0
Proyek ini bertujuan untuk menyempurnakan model encoder audio WAV2VEC2BERT untuk menghasilkan embeddings audio yang dapat digunakan sebagai pengganti encoder teks klip tradisional. Dengan mengintegrasikan embeddings audio, kami dapat memanfaatkan sifat unik data audio untuk membuka kunci kemungkinan baru untuk model difusi yang stabil .

? Model pada Wajah Memeluk | Notebook pelatihan
Audio berisi banyak informasi yang sering belum dimanfaatkan, jauh melampaui apa yang biasanya kita bayangkan. Dengan munculnya model difusi laten dan kemampuan generatifnya yang mengesankan, ada minat yang meningkat dalam mengeksplorasi beragam teknik pengkondisian. Pendekatan yang paling umum melibatkan penggunaan encoder teks (citra pra-pelatihan-pelatihan) kontras untuk mengkondisikan model. Namun, data audio menawarkan sumber informasi yang kaya dan beragam yang dapat secara signifikan meningkatkan proses pengkondisian.







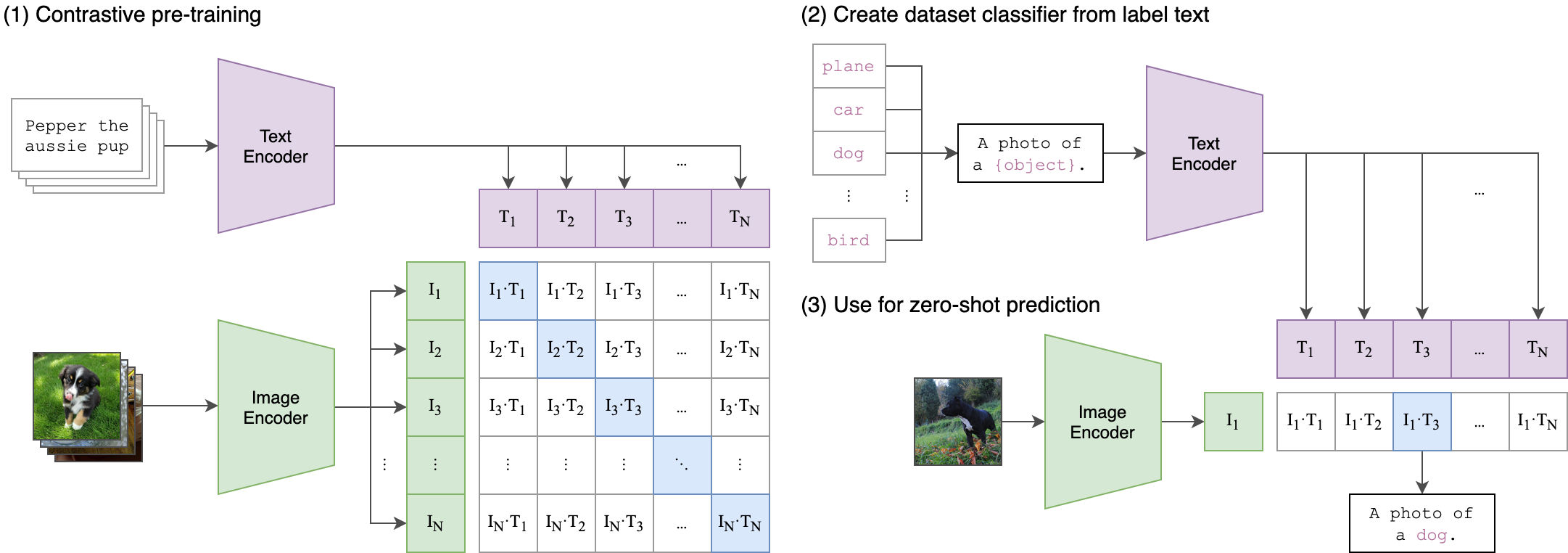
Gagasan inti di balik proses pelatihan kami adalah untuk mencapai penyelarasan lintas-modal antara embedding audio dan teks menggunakan arsitektur dua aliran . Ini melibatkan memanfaatkan cliptextmodel yang kuat untuk menghasilkan embeddings teks yang berfungsi sebagai label sejati untuk embedding audio yang diproduksi oleh model WAV2Vec2Bert kami. Berikut penjelasan terperinci:
Arsitektur Dua Aliran:
- Stream Teks: Kami menggunakan clipTextModel untuk menghasilkan embeddings teks untuk input teks yang diberikan. Embeddings ini menangkap informasi semantik yang kaya dan berfungsi sebagai label kebenaran tanah .
- Audio Stream: Model WAV2VEC2BERT kami menggunakan encoder fitur konvolusional diikuti oleh jaringan transformator untuk memproses input audio dan menghasilkan embeddings audio yang sesuai.
Penyelarasan lintas modalitas:
- Objektif: Tujuan utama dari pelatihan ini adalah untuk menyelaraskan embeddings audio dengan embeddings teks dalam ruang embedding bersama . Ini memastikan bahwa input audio dan teks yang sama secara semantik dipetakan dekat satu sama lain.
-Fungsi Kehilangan: Kami mencapai penyelarasan ini menggunakan kehilangan kontras yang mendorong model untuk membawa embedding pasangan audio-teks yang cocok lebih dekat sambil mendorong embedding pasangan yang tidak cocok.
Ini mirip dengan bagaimana model klip asli dilatih untuk menyelaraskan pasangan teks gambar. Perbedaannya adalah bahwa dalam model klip OpenAI , kehilangan kontras dihitung menggunakan token [CLS] , sementara kami akan menerapkan kehilangan kontras pada tingkat urutan .
Gambar ini dapat menjelaskan logika di balik kerugian ini:
Perpustakaan Transformers digunakan untuk pelatihan. Pos Pemeriksaan "Facebook/W2V-BERT-2.0" dimuat sebagai model awal pretrain . Persiapan data, detail pelatihan, dan hiperparameter yang digunakan dapat ditemukan di notebook train_me.ipynb :
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB: Ukuran batch adalah hiperparameter penting untuk disetujui, karena mendefinisikan berapa banyak sampel negatif yang diteruskan ke model.
pip install -r requirements.txtCKPT 1728 atau CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )atau
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )Jangan ragu untuk menggunakan variasi difusi yang stabil , CONTROLNET , atau model serupa, selama mereka menggunakan encoder klip yang sama.
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyBangun langsung dan jalankan gambar Docker:
docker build -t app.py .
docker run -p 7860:7860 app.py Selama pelatihan, diamati bahwa dataset yang digunakan kurang beranotasi dan diandalkan pada label generik. Memanfaatkan dataset yang lebih beragam dan diuraikan dengan baik akan meningkatkan kinerja model.
Selain itu, karena keterbatasan sumber daya, adaptor konvolusi kecil digunakan. Menggunakan adaptor yang lebih besar untuk mencocokkan panjang urutan maks klip memang dapat meningkatkan kinerja model, karena memungkinkan model untuk menangkap lebih banyak informasi.
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


