audio2img
1.0.0
Este projeto tem como objetivo ajustar um modelo de codificador de áudio wav2vec2bert para gerar incorporações de áudio que podem ser usadas no lugar do codificador de texto de clipe tradicional. Ao integrar incorporações de áudio, podemos aproveitar as propriedades exclusivas dos dados de áudio para desbloquear novas possibilidades para modelos de difusão estáveis .

? Modelo em abraçar o rosto | Caderno de treinamento
O áudio contém uma riqueza de informações que geralmente não são internas, estendendo -se muito além do que normalmente imaginamos. Com o surgimento de modelos de difusão latente e suas impressionantes capacidades generativas, há um interesse crescente em explorar diversas técnicas de condicionamento. A abordagem mais comum envolve o uso de codificadores de texto de clipe (de imagem contrastiva de imagem de imagem) para condicionar o modelo. No entanto, os dados de áudio oferecem uma fonte de informação rica e multifacetada que pode melhorar significativamente o processo de condicionamento.







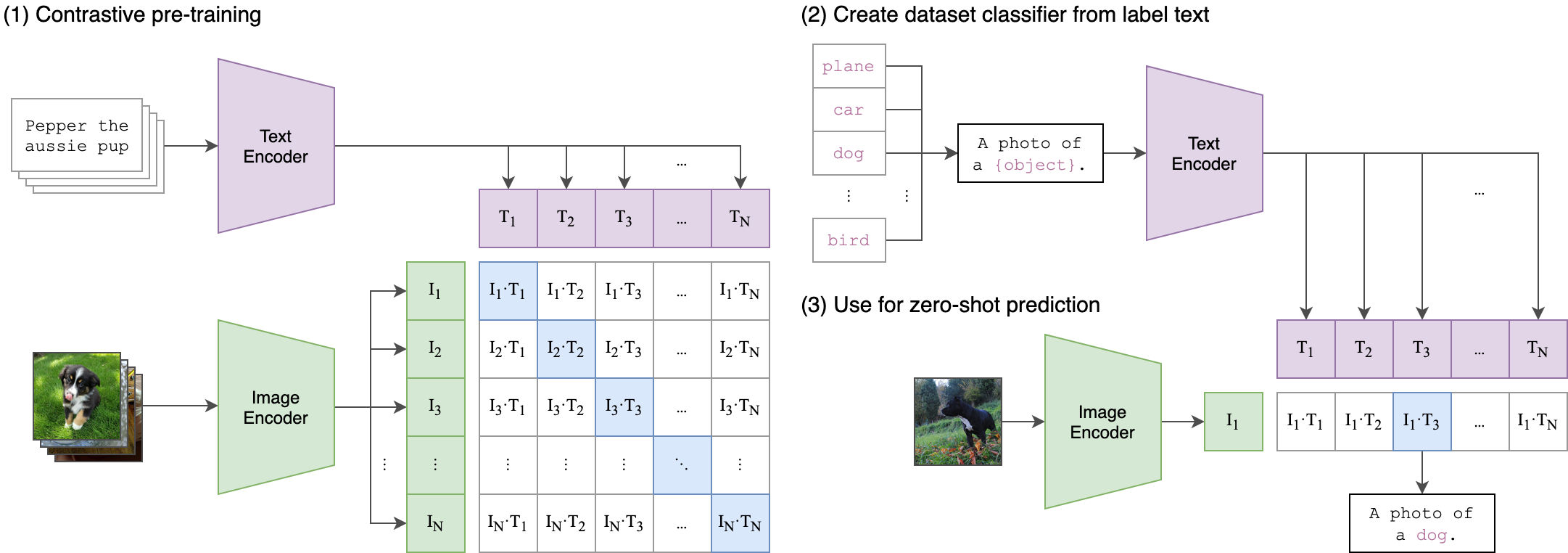
A idéia principal por trás do nosso processo de treinamento é alcançar o alinhamento cruzado entre as incorporações de áudio e texto usando uma arquitetura de dois stream . Isso envolve alavancar o poderoso cliptextmodel para gerar incorporações de texto que servem como rótulos verdadeiros para as incorporações de áudio produzidas pelo nosso modelo WAV2VEC2bert . Aqui está uma explicação detalhada:
Arquitetura de dois fluxo:
- Fluxo de texto: usamos o cliptextmodel para gerar incorporações de texto para determinadas entradas de texto. Essas incorporações capturam informações semânticas ricas e servem como os rótulos da verdade .
- Stream de áudio: nosso modelo wav2vec2bert usa o codificador de recursos convolucionais, seguido de uma rede de transformadores para processar entradas de áudio e gerar incorporações de áudio correspondentes.
Alinhamento de modalidade cruzada:
- Objectif: O objetivo principal do treinamento é alinhar as incorporações de áudio com as incorporações de texto em um espaço de incorporação compartilhado . Isso garante que as entradas de áudio e texto semanticamente semelhantes sejam mapeadas próximas uma da outra.
-Função de perda: alcançamos esse alinhamento usando perda contrastiva , o que incentiva o modelo a aproximar os pares de textos de áudio correspondentes ao mesmo tempo, afastando incorporações de pares que não correspondem.
Isso é semelhante à forma como o modelo de clipe original foi treinado para alinhar pares de texto de imagem. A diferença é que, no modelo de clipe OpenAI , a perda contrastiva foi calculada usando o token [CLS] , enquanto aplicaremos perda contrastiva no nível da sequência .
Esta imagem pode explicar a lógica por trás dessa perda:
A Biblioteca Transformers foi usada para o treinamento. O ponto de verificação "Facebook/W2V-Bert-2.0" foi carregado como modelo inicial pré-traido . A preparação de dados, os detalhes do treinamento e os hiperparâmetros utilizados podem ser encontrados no notebook de trens_me.ipynb :
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB: O tamanho do lote é um hiperparâmetro crucial para sintonizar, pois define quantas amostras negativas são passadas para o modelo.
pip install -r requirements.txtCKPT 1728 ou CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )ou
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )Sinta -se à vontade para usar qualquer variação de difusão estável , controlnet ou modelos similares, desde que utilizem o mesmo codificador de clipe .
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyConstrua e execute diretamente a imagem do Docker:
docker build -t app.py .
docker run -p 7860:7860 app.py Durante o treinamento, observou -se que o conjunto de dados utilizado foi mal anotado e baseado em rótulos genéricos. A utilização de um conjunto de dados mais diversificado e bem-alaborado aumentará o desempenho do modelo.
Além disso, devido a limitações de recursos, foi utilizado um pequeno adaptador de convolução. O uso de um adaptador maior para corresponder ao comprimento da sequência MAX do clipe pode realmente melhorar o desempenho do modelo, pois permite que o modelo capture mais informações.
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


